首先从上至下分析一下shell。 shell程序在其生命周期中会完成三项主要工作。【部分内容直接翻译自参考文献2】
- 初始化(initialize):在此步骤中,典型的shell将读取并执行其配置文件。 配置文件中的配置可以改变shell的各个方面。
- 解释(interpret):接下来,shell从stdin(可以是交互式的,也可以是文件)中读取命令并执行它们。
- 终止(terminate):执行完命令后,外壳程序将执行所有关闭命令,释放所有内存,然后终止。
这些步骤非常普遍,以至于可以应用于许多程序,这里也将以它们为基础。 这个shell非常简单,没有配置文件,也没有任何shutdown命令。 因此,只需要调用循环函数然后终止即可。
int main(int argc, char **argv)
{
// Load config files, if any.
// Run command loop.
lsh_loop();
// Perform any shutdown/cleanup.
return EXIT_SUCCESS;
} 现在经常使用的linux的终端中,也就是在POSIX标准下,命令分为内部命令和外部命令,当命令解释器遇到内部命令的之后,便直接运行内部命令,也就是说,内部命令是我们自己的实现的。而外部命令,当命令解释器遇到外部命令的时候,直接从系统中找到相应的应用程序,然后开启一个子线程来执行该程序。
常见的相应的内部命令:
- exit : 退出该shell程序
- cd : 改变当前的工作目录
- echo : 回显命令后面的字符串
- export : 设置环境变量
- history : 显示历史命令
Shell的基本循环
对于基本程序逻辑:shell在其循环期间会做什么?处理命令的简单方法是三个步骤:
- 读取:从标准输入读取命令。
- 解析:将命令字符串分成程序和参数。
- 执行:运行已解析的命令。
将这些想法转换为lsh_loop()的代码:
void lsh_loop(void)
{
char *line;
char **args;
int status;
do {
printf("> ");
line = lsh_read_line();
args = lsh_split_line(line);
status = lsh_execute(args);
free(line);
free(args);
} while (status);
}让我们来看一下代码。 前几行只是声明。 do-while循环对于检查状态变量更为方便,因为它在检查其值之前执行一次。 在循环中,我们打印提示符,调用函数以读取一行,调用函数以将该行拆分为args,然后执行args。 最后,我们释放之前创建的行和参数。 请注意,我们使用的是lsh_execute()返回的状态变量来确定何时退出。
读入一行
从stdin读取行听起来很简单,但是在C语言中可能会很麻烦。无法提前知道用户将在shell中输入多少文本。 不能简单地分配一个块(block)并希望用户的输入不超过这个块。 相反,需要从一个块开始,如果用户输入超出了块,则需要分配更多空间。 这是C语言中的常见策略,使用它来实现lsh_read_line()。
#define LSH_RL_BUFSIZE 1024
char *lsh_read_line(void)
{
int bufsize = LSH_RL_BUFSIZE;
int position = 0;
char *buffer = malloc(sizeof(char) * bufsize);
int c;
if (!buffer) {
fprintf(stderr, "lsh: allocation errorn");
exit(EXIT_FAILURE);
}
while (1) {
// Read a character
c = getchar();
// If we hit EOF, replace it with a null character and return.
if (c == EOF || c == 'n') {
buffer[position] = '0';
return buffer;
} else {
buffer[position] = c;
}
position++;
// If we have exceeded the buffer, reallocate.
if (position >= bufsize) {
bufsize += LSH_RL_BUFSIZE;
buffer = realloc(buffer, bufsize);
if (!buffer) {
fprintf(stderr, "lsh: allocation errorn");
exit(EXIT_FAILURE);
}
}
}
}第一部分是很多声明。请注意,这里保留了在所有其余代码之前声明变量的习惯。函数的内容在无限循环中。在循环中,我们读取一个字符(并将其存储为int而不是char,这很重要!EOF是一个整数,而不是一个字符,如果要检查它,则需要使用int。这是C初学者常见的错误)。如果是换行符或EOF,则我们将终止当前字符串并返回空值。否则,我们将字符添加到现有字符串中。
接下来,我们查看下一个字符是否会超出当前缓冲区的大小。如果是这样,我们在继续之前重新分配缓冲区(检查分配错误)。
那些对C库的较新版本非常熟悉的人可能会注意到stdio.h中有一个getline()函数可以完成我们刚刚实现的大部分工作。直到2008年该功能被添加到规范中之前,它一直是C库的GNU扩展,因此大多数现代Unix现在都应该支持这个函数。这里鼓励人们在使用getline之前首先以这种方式进行学习。无论如何,使用getline,该函数变得很简单:
char *lsh_read_line(void)
{
char *line = NULL;
ssize_t bufsize = 0; // have getline allocate a buffer for us
getline(&line, &bufsize, stdin);
return line;
}解析命令行
现在已经实现了lsh_read_line(),并且有一行输入。 现在,我们需要将该行解析为参数列表。 我在这里进行一个明显的简化,将简单地使用空格将参数彼此分开。 因此,命令echo“ this message”不会使用作为单个参数调用echo,而是相当于echo带有两个参数 this和message。
通过这些简化,我们所需要做的就是使用空格作为分隔符来“标记”字符串。 这意味着我们可以使用经典的库函数strtok来为我们做一些麻烦的工作。
#define LSH_TOK_BUFSIZE 64
#define LSH_TOK_DELIM " trna"
char **lsh_split_line(char *line)
{
int bufsize = LSH_TOK_BUFSIZE, position = 0;
char **tokens = malloc(bufsize * sizeof(char*));
char *token;
if (!tokens) {
fprintf(stderr, "lsh: allocation errorn");
exit(EXIT_FAILURE);
}
token = strtok(line, LSH_TOK_DELIM);
while (token != NULL) {
tokens[position] = token;
position++;
if (position >= bufsize) {
bufsize += LSH_TOK_BUFSIZE;
tokens = realloc(tokens, bufsize * sizeof(char*));
if (!tokens) {
fprintf(stderr, "lsh: allocation errorn");
exit(EXIT_FAILURE);
}
}
token = strtok(NULL, LSH_TOK_DELIM);
}
tokens[position] = NULL;
return tokens;
}这段代码看起来与lsh_read_line()类似,那是因为使用了具有缓冲区并动态扩展它的相同策略。这次我们使用以空值终止的指针数组而不是以空值终止的字符数组来实现。
在函数开始时,我们通过调用strtok开始分析。它返回一个指向第一个token的指针。 strtok()实际执行的操作是将指针返回给我们提供的字符串的中间,并将 0字节放在每个token的末尾。我们将每个指针存储在字符指针的数组(缓冲区)中。
最后,如有必要,我们重新分配指针数组。重复该过程,直到strtok不返回任何令牌为止,此时我们以空值终止token列表。
现在,有了token列表之后,我们就可以准备执行一系列需要运行的token,接下来的问题就是,该怎么样执行呢?
Shell如何启动进程
现在是Shell的核心内容。启动新的进程是shell的主要功能。因此,编写shell程序意味着需要准确了解进程的进展以及进程的开始方式。这就是为什么将简短地讨论Unix中的进程。
在Unix上只有两种启动进程的方法。第一个(几乎不算在内)是Init。当Unix计算机启动时,将加载其内核。加载并初始化后,内核仅启动一个进程,称为Init。这个进程将在计算机开启的整个时间范围内运行,并管理加载计算机有用的其余进程。
由于大多数程序不是Init程序,因此,另一种实用的方法来启动进程:fork()系统调用。调用此函数时,操作系统将复制该过程并启动它们的运行。原始进程称为“父进程”,而新进程称为“子进程”。 fork()向子进程返回0,并将其子进程的ID(PID)返回给父进程。从本质上讲,这意味着开始新进程的唯一方法是复制现有进程。
听起来有问题。通常,启动一个新进程的目的不是需要同一个程序的另一个副本,而是想运行另一个程序。这就是exec()系统调用的全部内容。它用一个全新的程序替换了当前正在运行的程序。这意味着,当调用exec时,操作系统将停止调用exec的父进程,加载新程序,并在其位置启动该程序。进程永远不会从exec()调用返回(除非有错误)。
通过这两个系统调用,便可以启动在Unix上运行大多数程序。首先,现有进程将自身分为两个单独的进程。然后,子进程使用exec()将自己替换为新程序。父进程可以继续做其他事情,也可以使用系统调用wait()保持子进程的状态。
以此为背景,以下用于启动程序的代码:
int lsh_launch(char **args)
{
pid_t pid, wpid;
int status;
pid = fork();
if (pid == 0) {
// Child process
if (execvp(args[0], args) == -1) {
perror("lsh");
}
exit(EXIT_FAILURE);
} else if (pid < 0) {
// Error forking
perror("lsh");
} else {
// Parent process
do {
wpid = waitpid(pid, &status, WUNTRACED);
} while (!WIFEXITED(status) && !WIFSIGNALED(status));
}
return 1;
}好的。此函数采用我们先前创建的参数列表。然后,它fork()了该进程,并保存返回值。一旦fork()返回,我们实际上就有两个进程同时运行。子进程将采用第一个if条件(其中pid == 0)。
在子进程中,我们要运行用户给出的命令。因此,我们使用exec系统调用execvp的许多变体之一。 exec的不同变体所做的事情略有不同。有些采用可变数量的字符串参数。其他人则使用字符串列表。还有一些让用户指定运行过程的环境。此特定变体需要一个程序名称和一个字符串参数数组(也称为向量,因此也称为“ v”)(第一个必须是程序名称)。"p"表示我们将提供其名称,而不是提供要运行的程序的完整文件路径,并让操作系统在路径中搜索该程序。
如果exec命令返回-1(或者实际上,如果它真返回了),则表明存在错误。因此,我们使用perror来打印系统的错误消息以及我们的程序名称,以便用户知道错误的来源。然后,退出,以便shell程序可以继续运行。
第二个条件(pid <0)检查fork()是否有错误。如果是这样,则打印错误并继续进行-除了告诉用户并让他们决定是否需要退出之外,没有处理错误。
第三个条件意味着fork()成功执行。这是父进程的处理代码。我们知道子进程将要执行新的任务,因此父进程需要等待子命令完成运行。我们使用waitpid()等待进程状态更改。不幸的是,waitpid()有很多选项。进程可以通过多种方式改变状态,但并非所有方式都意味着进程已经结束。进程可以退出(正常情况下或带有错误代码),也可以被信号杀死。因此,我们使用waitpid()随附的宏来等待,直到退出或终止进程。然后,函数最终返回1,作为调用函数的信号,我们应再次提示输入。
shell内置命令
上面的lsh_loop()函数调用了lsh_execute(),但是之前我们将函数命名为lsh_launch()。这主要是因为,虽然shell执行的大多数命令都是程序,但不是全部。其中一些功能是内置在shell中的。
原因实际上很简单。如果要更改目录,则需要使用函数chdir()。问题是,当前目录是进程的属性。因此,如果您编写了一个名为cd的程序,该程序更改了目录,则它将仅更改其自己的当前目录,然后终止。其父进程的当前目录将保持不变。相反,shell进程本身需要执行chdir(),以便更新其自己的当前目录。然后,当它启动子进程时,它们也将继承该目录。
同样,如果有一个名为exit的程序,它将无法退出调用它的shell。该命令也需要内置到shell中。而且,大多数shell程序都是通过运行配置脚本来配置的,例如〜/ .bashrc。这些脚本使用更改shell程序操作的命令。如果这些命令是在Shell本身中实现的,则它们只能更改Shell的操作【?】。
因此,我们需要向外壳本身添加一些命令。目前添加到shell中的是cd、exit和help。以下是其功能实现:
/*
Function Declarations for builtin shell commands:
*/
int lsh_cd(char **args);
int lsh_help(char **args);
int lsh_exit(char **args);
/*
List of builtin commands, followed by their corresponding functions.
*/
char *builtin_str[] = {
"cd",
"help",
"exit"
};
int (*builtin_func[]) (char **) = {
&lsh_cd,
&lsh_help,
&lsh_exit
};
int lsh_num_builtins() {
return sizeof(builtin_str) / sizeof(char *);
}
/*
Builtin function implementations.
*/
int lsh_cd(char **args)
{
if (args[1] == NULL) {
fprintf(stderr, "lsh: expected argument to "cd"n");
} else {
if (chdir(args[1]) != 0) {
perror("lsh");
}
}
return 1;
}
int lsh_help(char **args)
{
int i;
printf("Stephen Brennan's LSHn");
printf("Type program names and arguments, and hit enter.n");
printf("The following are built in:n");
for (i = 0; i < lsh_num_builtins(); i++) {
printf(" %sn", builtin_str[i]);
}
printf("Use the man command for information on other programs.n");
return 1;
}
int lsh_exit(char **args)
{
return 0;
}该代码分为三部分。第一部分包含函数的前向声明。前向声明是您声明(但未定义)某些内容时可以在定义之前使用它的名称。这样做的原因是因为lsh_help()使用内建数组,并且该数组包含lsh_help()。打破此依赖关系循环的最干净方法是前向声明【?】。
下一部分是内置命令名称的数组,其后是其相应功能的数组。这样一来,将来只需修改这些数组即可添加内置命令,而不用在代码中的某个位置编辑大型“ switch”语句。buildin_func的声明是一个函数指针数组(采用字符串数组并返回一个int)。任何涉及C中函数指针的声明都会变得非常复杂。
最后,实现了每个功能。 lsh_cd()函数首先检查其第二个参数是否存在,如果不存在,则会显示一条错误消息。然后,它调用chdir(),检查错误并返回。帮助功能会打印一条消息以及所有内建程序的名称。退出函数返回0,作为命令循环终止的信号。
整合内建函数和进程
最后一个难题是实现lsh_execute(),该函数将启动内置函数或进程:
int lsh_execute(char **args)
{
int i;
if (args[0] == NULL) {
// An empty command was entered.
return 1;
}
for (i = 0; i < lsh_num_builtins(); i++) {
if (strcmp(args[0], builtin_str[i]) == 0) {
return (*builtin_func[i])(args);
}
}
return lsh_launch(args);
}以上代码主要就是检查命令是否等于内置函数,如果是,则运行内置函数。 如果不是内置命令,则它将调用lsh_launch()启动进程。 注意的是,如果用户输入的是空字符串或仅是空格,则args可能仅包含NULL。 因此,我们需要在开始时检查这种情况。
关于getopt
shell中获取参数可以直接使用$1、$2等形式来获取,但这种方式有明显的限制:每个参数的位置是固定的。比如如果在设计上$1是ip地址$2是端口,那在执行时就必须第一个参数是ip第二个参数是端口而不能反过来。getopt命令以及函数可以让参数使用更灵活。这里主要讨论的是getopt函数。
getopt()函数定义在头文件 #include <unistd.h>中。
定义:int getopt(int argc, char * const argv[], const char * optstring);
说明:getopt()用来分析命令行参数。
1、参数argc 和argv 是由main()传递的参数个数和内容。
2、参数optstring 则代表欲处理的选项字符串。
getopt()会返回在argv 中下一个的选项字母,此字母会对应参数optstring 中的字母。看起来相当之不好理解,看一下代码:
#include <stdio.h>
#include <unistd.h>
int main(int argc, char **argv)
{
int ch;
opterr = 0;
while((ch = getopt(argc, argv, "a:bcde")) != -1)
switch(ch)
{
case 'a':
printf("option a:'%s'n", optarg); break;
case 'b':
printf("option b :bn"); break;
case 'c':
printf("option c :cn"); break;
default:
printf("other option :%cn", ch);
}
printf("optopt +%cn", optopt);
}以上代码的运行结果是:
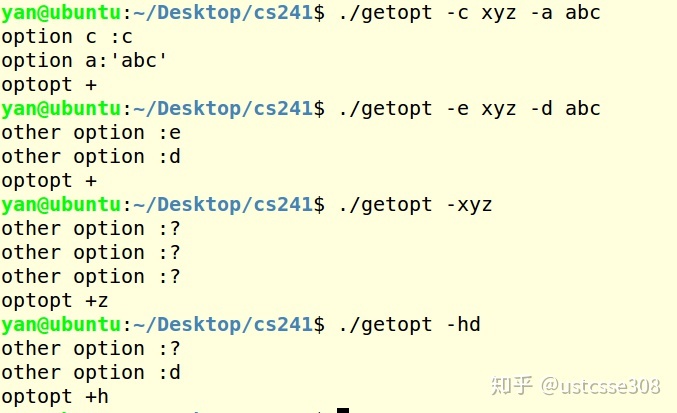
这里如何理解呢?
这里"a:bcde"就是optstring,就是可能出现的选项参数;也即可能出现-a, -b, -c, -d, -e等选项;如果是其他的,则不认识。另一方面,a后有:,意味着,a可以有参数。其他的选项后没有:或者::,则不接收参数。而且a的参数保存在optarg中。
从上面的例子中也可以看出,getopt的容错能力还是很强的。
上面的代码虽然简单,也有一些细节需要进一步讨论,譬如opterr,optopt。
变量:int opterr
如果此变量的值非零,则如果getopt遇到未知的选项字符或缺少必需参数的选项,则会将错误消息输出到标准错误流。这是默认行为。如果将此变量设置为零,则getopt不会打印任何消息,但仍返回字符?表示错误。
上面的代码中,opterr就设置为0,所以缺少额外的错误信息打印。如果修改代码,将opterr设置为1或者不管它,可以打印出不少的错误信息。
变量:int optopt
当getopt遇到未知的选项字符或缺少必需参数的选项时,它将在该变量中存储该选项字符。可以使用它来提供自己的诊断消息。
变量:int optind
该变量由getopt设置为要处理的argv数组下一个元素的索引。一旦getopt找到所有选项参数,就可以使用此变量来确定其余非选项参数的开始位置。该变量的初始值为1。
变量:char * optarg
对于接受参数的那些选项,由getopt将该变量设置为指向选项参数的值。
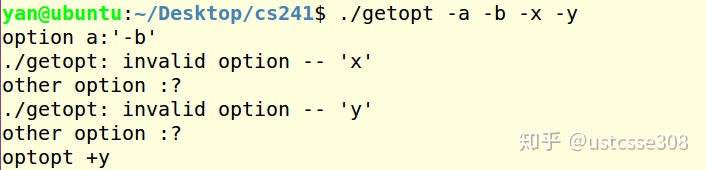
可以看出,在上面的例子中,-b被处理为-a的参数;同时汇报-x和-y识别不了。
继续讨论下细节:选项字符后可以跟一个冒号(':'),以表示它接受必需的参数。如果选项字符后跟两个冒号('::'),则其参数为可选;这是一个GNU扩展。
getopt具有三种处理非选项argv元素之后的选项的方法。特殊参数“--”在所有情况下都会强制结束选项扫描。
- 缺省是在扫描argv时对其内容进行置换,以便最终所有非选项都在末尾,使得可以以任何顺序给出选项。
- 如果options参数字符串以连字符('-')开头,则会对其进行特殊处理。它允许返回非选项参数,就像它们与选项字符“ 1”相关联一样。
- POSIX要求以下行为:第一个非选项停止选项处理。通过设置环境变量POSIXLY_CORRECT或以加号('+')开头的选项参数字符串来选择此模式。
getopt函数返回下一个命令行选项的选项字符。当没有更多选项参数可用时,它将返回-1。可能还有更多的非选择参数。必须将外部变量optind与argc参数进行比较以进行检查。
如果选项具有参数,则getopt通过将其存储在变量optarg中来返回参数。通常不需要复制optarg字符串,因为它是指向原始argv数组的指针,而不是指向可能会被覆盖的静态区域的指针。
如果getopt在argv中找到未包含在选项中的选项字符,或者缺少选项参数,它将返回“?”并将外部变量optopt设置为实际的选项字符。如果选项的第一个字符是冒号(':'),则getopt返回':'而不是'?'表示缺少选项参数。此外,如果外部变量opterr为非零(默认值),则getopt将显示一条错误消息。
再看一个例子:
#include <ctype.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int
main (int argc, char **argv)
{
int aflag = 0;
int bflag = 0;
char *cvalue = NULL;
int index;
int c;
opterr = 0;
while ((c = getopt (argc, argv, "abc:")) != -1)
switch (c)
{
case 'a':
aflag = 1;
break;
case 'b':
bflag = 1;
break;
case 'c':
cvalue = optarg;
break;
case '?':
if (optopt == 'c')
fprintf (stderr, "Option -%c requires an argument.n", optopt);
else if (isprint (optopt))
fprintf (stderr, "Unknown option `-%c'.n", optopt);
else
fprintf (stderr,
"Unknown option character `x%x'.n",
optopt);
return 1;
default:
abort ();
}
printf ("aflag = %d, bflag = %d, cvalue = %sn",
aflag, bflag, cvalue);
for (index = optind; index < argc; index++)
printf ("Non-option argument %sn", argv[index]);
return 0;
}测试一下:
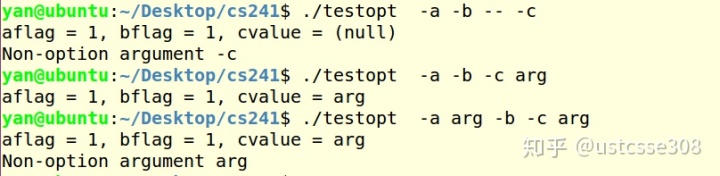
以及

其中isprint是判断是否是可打印字符,如果是,就打印出来,直接返回;optind保存在argv的后面,可以通过for循环打印。
如果在代码中将return 1改为break,则也可以打印出Optind所指示的信息。

文献4动用了词法分析来做shell,厉害了。
参考:
- https://www.cnblogs.com/wuyuegb2312/p/3399566.html
- https://brennan.io/2015/01/16/write-a-shell-in-c/
- https://www.geeksforgeeks.org/making-linux-shell-c/
- https://www.cs.purdue.edu/homes/grr/SystemsProgrammingBook/Book/Chapter5-WritingYourOwnShell.pdf
- https://www.gnu.org/software/libc/manual/html_node/Using-Getopt.html#Using-Getopt
- http://c.biancheng.net/cpp/html/379.html