目录
Hadoop
1.大数据特点:4V




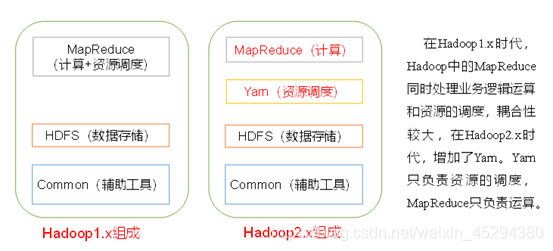
2.Hadoop组成
3.hdfs主从节点

4.搭建集群
一、虚拟机环境准备
(1)克隆虚拟机
(2)修改克隆虚拟机的静态IP
(3)修改主机名
(4)关闭防火墙
(5)创建root用户
(6)配置root用户具有root权限
(7)在/opt目录下创建文件夹:
- 在/opt目录下创建module、software文件夹
- 修改module、software文件夹的所有者(chown root:root module/ software/
(8)安装JDK,如果有低于1.7的版本,先卸载该版本JDK,修改系统环境变量/etc/profile文件中的变量为现在的版本
(9)安装Hadoop,同样修改系统环境变量
二、准备三台虚拟机(一、)
三、编写集群分发脚本xsync
- 在/home/root目录下创建bin目录,并在bin目录下xsync创建文件
- 修改脚本 xsync 具有执行权限
四、集群部署规划

- 配置集群
核心配置文件:core-site.xml
HDFS配置文件:hadoop-env.sh、hdfs-site.xml
YARN配置文件:yarn-env.sh、yarn-site.xml
MapReduce配置文件:mapred-env.sh、mapred-site.xml
/opt/module/hadoop-2.7.2/etc/hadoop/slaves
- 在集群上分发配置好的Hadoop配置文件,并查看文件分发情况
五、集群单点启动
- 如果集群是第一次启动,需要格式化NameNode
- 在第一台主机上启动NameNode
- 在第二、三台主机上分别启动DataNode
六、SSH无密登录配置
- 生成公钥和私钥
- 将公钥拷贝到要免密登录的目标机器上
5.hadoop运行模式
本地模式、伪分布式、完全分布式
6.配置文件
核心配置文件:core-site.xml
HDFS配置文件:hadoop-env.sh、hdfs-site.xml
YARN配置文件:yarn-env.sh、yarn-site.xml
MapReduce配置文件:mapred-env.sh、mapred-site.xml
/opt/module/hadoop-2.7.2/etc/hadoop/slaves
7.NameNode格式化
(1)删除/opt/mudule/hadoop-2.7.2下的data和logs文件夹
(2) 重新格式化NameNode:hdfs namenode -format
8.免密登录SSH
(1)配置ssh
基本语法:ssh 登陆主机IP
- ssh连接时出现Host key verification failed的解决方法:直接输入yes

(2)无密钥配置
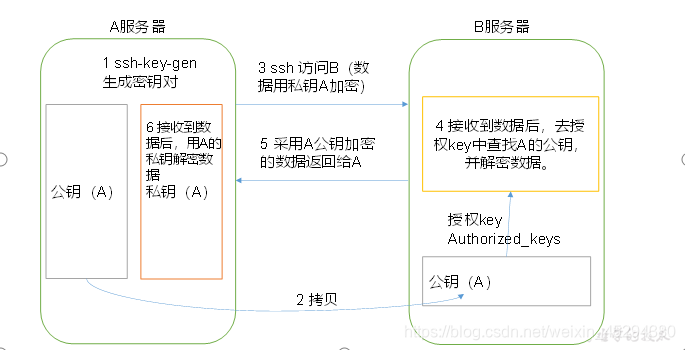
- 生成公钥和私钥:ssh-keygen -t rsa
- 将公钥拷贝到要免密登录的目标机器上:ssh-copy-id IP
(3) ssh文件夹下(~/.ssh)的文件功能解释

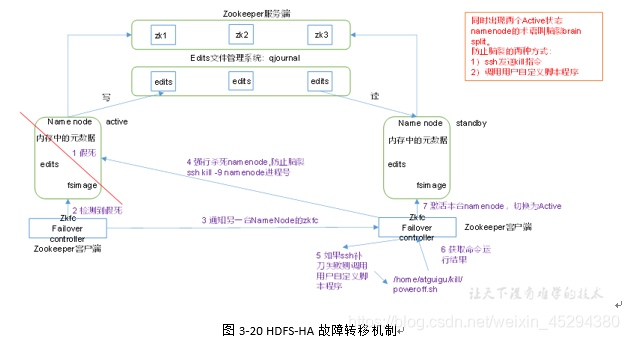
HA(高可用集群)
通过双NameNode消除单点故障,切换工作模式
1.搭建ha集群
一、环境准备
(1)修改IP
(2)修改主机名及主机名和IP地址的映射
(3)关闭防火墙
(4)ssh免密登录
(5)安装JDK,配置环境变量等
二、规划集群

三、配置Zookeeper集群
(1)解压安装zookeeper
(2)在/opt/module/zookeeper-3.4.10/这个目录下创建zkData
(3)重命名/opt/module/zookeeper-3.4.10/conf这个目录下的zoo_sample.cfg为zoo.cfg
(4)配置zoo.cfg文件
(5)在/opt/module/zookeeper-3.4.10/zkData目录下创建一个myid的文件
(6)编辑myid文件
(7)拷贝配置好的zookeeper到其他机器上,并分别修改myid文件中内容为3、4
(8)分别启动zookeeper:bin/zkServer.sh start
(9)查看状态:bin/zkServer.sh status
四、配置HDFS-HA集群
(1)在opt目录下创建一个ha文件夹,并修改所有者:chmod root:root ha
(2)将/opt/module/下的 hadoop-2.7.2拷贝到/opt/ha目录下
(3)配置hadoop-env.sh(JAVA_HOME环境变量)
(4)配置core-site.xml、hdfs-site.xml
(5)拷贝配置好的hadoop环境到其他节点
五、启动HDFS-HA集群
(1)在各个JournalNode节点上,输入以下命令启动journalnode服务:sbin/hadoop-daemon.sh start journalnode
(2)在[nn1]上,对其进行格式化,并启动:①bin/hdfs namenode -format②sbin/hadoop-daemon.sh start namenode
(3)在[nn2]上,同步nn1的元数据信息:bin/hdfs namenode -bootstrapStandby
(4)启动[nn2]:sbin/hadoop-daemon.sh start namenode
(5)查看web页面显示:IP:50070
(6)在[nn1]上,启动所有datanode:sbin/hadoop-daemons.sh start datanode
(7)将[nn1]切换为Active:bin/hdfs haadmin -transitionToActive nn1
(8)查看是否Active:bin/hdfs haadmin -getServiceState nn1
六、配置HDFS-HA自动故障转移
(1)启动
- 关闭所有HDFS服务:sbin/stop-dfs.sh
- 启动Zookeeper集群:bin/zkServer.sh start
- 初始化HA在Zookeeper中状态:bin/hdfs zkfc -formatZK
- 启动HDFS服务:sbin/start-dfs.sh
(2)验证
- 将Active NameNode进程kill:kill -9 namenode的进程id
- 将Active NameNode机器断开网络:service network stop
2.HA作用
- 故障检测:一个namenode宕机后,zookeeper会通知另一个namenode需要出发故障转移
- 现役NameNode选择
- ---健康监测
- ---ZooKeeper会话管理
- ---基于ZooKeeper的选择
HDFS
1.hdfs块大小,原因
(1)默认大小为128M(HAdoop2.x版本中)
(2)原因:
- HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置
- 如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据是会非常慢
2.优缺点
(1)优点:
- 容错性高
- 适合处理大数据
- 可构建在廉价机器上,通过多副本机制,提高可靠性
(2)缺点:
- 不适合低延时数据访问
- 无法高效的对大量小文件进行存储
- 不支持并发写入、文件随即修改
3.默认副本数量
4.黑白名单(谁更严格)
5.shell操作
(1)-help:输出这个命令参数
hadoop fs -help rm(2)-ls: 显示目录信息
hadoop fs -ls /(3)-mkdir:在HDFS上创建目录(-p:多级目录)
hadoop fs -mkdir -p /sanguo/shuguo(4)-moveFromLocal:从本地剪切粘贴到HDFS
[root@hadoop102 hadoop-2.7.2]$ touch kongming.txt
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -moveFromLocal ./kongming.txt /sanguo/shuguo
(5)-appendToFile:追加一个文件到已经存在的文件末尾
[root@hadoop102 hadoop-2.7.2]$ touch liubei.txt
[root@hadoop102 hadoop-2.7.2]$ vi liubei.txt
输入
san gu mao lu
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt
(6)-cat:显示文件内容
root@hadoop102 hadoop-2.7.2]$ hadoop fs -cat /sanguo/shuguo/kongming.txt(7)-chgrp 、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -chmod 666 /sanguo/shuguo/kongming.txt
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -chown root:root /sanguo/shuguo/kongming.txt
(8)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -copyFromLocal README.txt /(9)-copyToLocal:从HDFS拷贝到本地
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -copyToLocal /sanguo/shuguo/kongming.txt ./(10)-cp :从HDFS的一个路径拷贝到HDFS的另一个路径
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -cp /sanguo/shuguo/kongming.txt /zhuge.txt(11)-mv:在HDFS目录中移动文件
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -mv /zhuge.txt /sanguo/shuguo/(12)-get:等同于copyToLocal,就是从HDFS下载文件到本地
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -get /sanguo/shuguo/kongming.txt ./(13)-getmerge:合并下载多个文件,比如HDFS的目录 /user/root/test下有多个文件:log.1, log.2,log.3,...
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -getmerge /user/root/test/* ./zaiyiqi.txt(14)-put:等同于copyFromLocal
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -put ./zaiyiqi.txt /user/root/test/(15)-tail:显示一个文件的末尾
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -tail /sanguo/shuguo/kongming.txt(16)-rm:删除文件或文件夹
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -rm /user/root/test/jinlian2.txt(17)-rmdir:删除空目录
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -mkdir /test
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -rmdir /test
(18)-du统计文件夹的大小信息
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -du -s -h /user/root/test
2.7 K /user/root/test
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -du -h /user/root/test
1.3 K /user/root/test/README.txt
15 /user/root/test/jinlian.txt
1.4 K /user/root/test/zaiyiqi.txt
(19)-setrep:设置HDFS中文件的副本数量
[root@hadoop102 hadoop-2.7.2]$ hadoop fs -setrep 10 /sanguo/shuguo/kongming.txtMapReduce
1.mapreduce进程

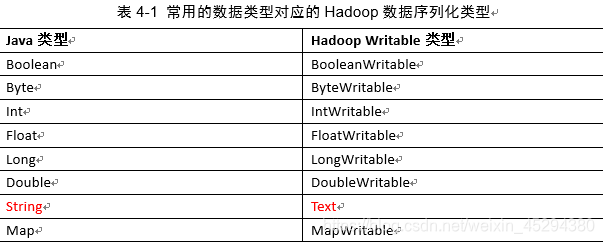
2.序列化 text
![]()
3.mapreduce的编程规范
用户编写的程序分成三个部分:Mapper、Reducer和Driver。


4.mapreduce框架
5.切片大小 ,原因
(1)默认大小为128M
(2)原因:
切片只是对数据块进行切割,块大小默认为128M,切大切小都会存在跨节点切片的情况
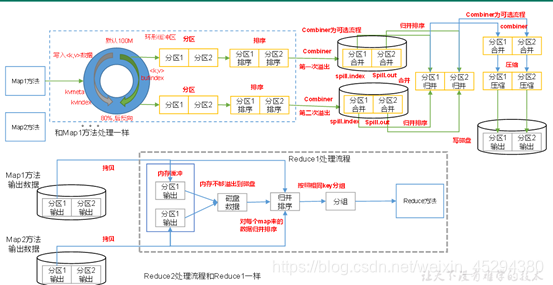
6.Shuffle
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle
Yarn
1.yarn节点
ResourceManager、NodeManager
2.资源调度器
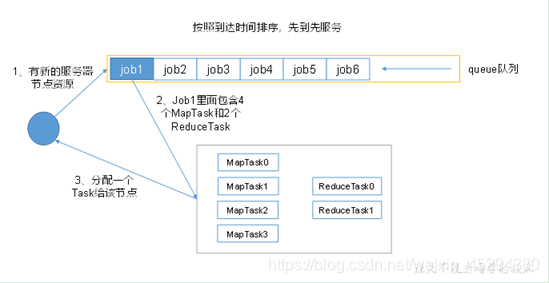
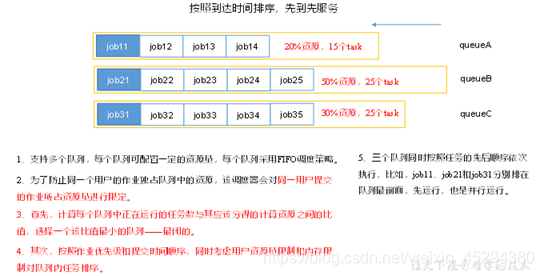
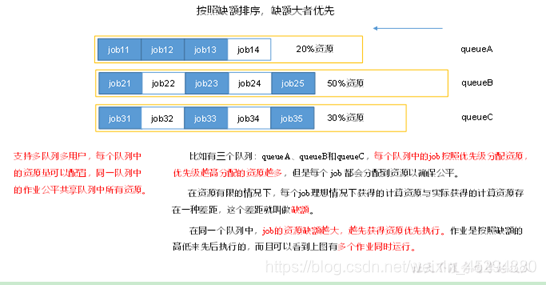
FIFO、Capacity Scheduler和Fair Scheduler
(1)先进先出调度器(FIFO)
(2)容量调度器(Capacity Scheduler)
(3)公平调度器(Fair Scheduler)
Zookeeper
1.zookeeper选举机制
半数选举:集群中半数以上机器存活,集群可用。所以Zookeeper适合安装奇数台服务器。与myid有关
2.zookeeper端口号
2181
Flume
1.流式架构
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单
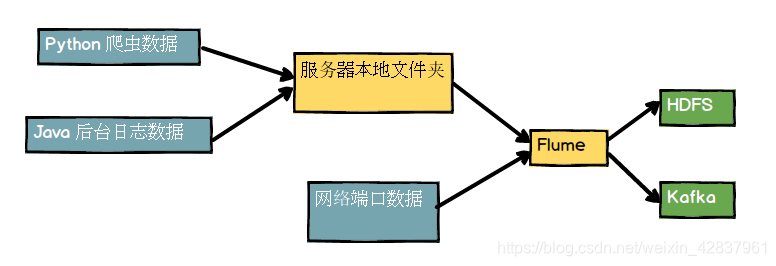
2.agent
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的
Agent 主要有三个组成部分,Source、Channel、Sink
(1)Sink
Sink 不断地轮询 Channel 中的事件且批量移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 组件的目的地包括 hdfs、logger、avro、thrif、file、HBase、solr、自定义
(2)Channel
Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和 Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个 Sink 的读取操作
Flume 常用的 Channel:Memory Channel 和 File Channel
(3)Event
传输单元,Flume数据传输的基本单元,以Event的形式将数据从源头送至目的地。Event由Header和Body两部分组成,Header用来存放该event的一些属性,为K-V结构,Body用来存放该条数据,形式为字节数组
Kafka
1.topic
Topic :可以理解为一个队列,生产者和消费者面向的都是一个topic
Spark
1.算子
2.rdd
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据(计算)抽象。代码中是一个抽象类,它代表一个不可变、可分区、里面的元素可并行计算的集合。
3.rdd,datafream,dateset三者关系

1. RDD是最基础的数据类型,在向上转换时,需要添加必要的信息;
转DataFrame:需要添加结构信息并加上列名 toDF("id","name")
转DataSet:需要添加类型信息,写样例类 map(x=>{Emp(x)}).toDS()
2. DataFrame在向上转换时,本身包含结构信息,只添加类型信息即可;
转DataSet:先写样例类,as[Emp]
转RDD:df.rdd
3. DataSet作为最上层的抽象,转换其他对象直接可以往下转;
转DataFrame:ds.toDF
转RDD:ds.rdd
RDD与DF/DS转换都需要引入(import spark.implicits)
Tez
1.作用/优点
- 优点:Tez可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。
- 作用: