1. 伪随机
查看 python 标准库random的文档, 第一行是
该模块为各种分布实现了伪随机数生成器
random模块本质上是用数据的算法来实现的, 生成的数据看似随机, 但依然是可重现的。
1.1 seed, getstate, setstate
通过指定初始化随机数, random.seed 可以使后续生成的随机数具有确定性.
In [1]: import random
In [2]: random.seed(100)
In [3]: [random.random() for _ in range(3)]
Out[3]: [0.1456692551041303, 0.45492700451402135, 0.7707838056590222]
In [4]: random.seed(100)
In [5]: [random.random() for _ in range(3)]
Out[5]: [0.1456692551041303, 0.45492700451402135, 0.7707838056590222]
从以上代码可以看到, 在In [4]这行代码将seed重置为100后, 后续再次调用random.random()时, 和第一次产生的数据是完全相同的
除了指定seed, random模块还提供了2个方法 getstate(), setstate() 来捕获和恢复生成器当前内部状态的对象.
In [6]: st = random.getstate()
In [7]: [random.random() for _ in range(3)]
Out[7]: [0.705513226934028, 0.7319589730332557, 0.43351443489540376]
In [8]: random.setstate(st)
In [9]: [random.random() for _ in range(3)]
Out[9]: [0.705513226934028, 0.7319589730332557, 0.43351443489540376]2. random中的常用方法
2.1 随机字节 randbytes
randbytes接收1个参数, 用于返回指定长度的随机字节数据
In [10]: random.randbytes(2)
Out[10]: b'\x80d'
In [11]: random.randbytes(4)
Out[11]: b'\xc7np\xfc'2.2 随机整数 randint, randrange, getrandbits
randint(start, end)接受 2 个参数 返回闭区间 [ start, end ] 中的一个数.
In [1]: import random
In [2]: {random.randint(1, 10) for _ in range(100)}
Out[2]: {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}随机取值100次, 将结果转换为一个集合, 可以看到, 数据范围为 [1, 10]
randrange(start, end, step), 等效于choice(range(start, stop, step)), 从指定起止坐标和步长的列表中随机取一个数据, 数据区间左开右比 [ start, end )
# randrange 返回右开区间的数据
In [3]: {random.randrange(1, 10) for _ in range(100)}
Out[3]: {1, 2, 3, 4, 5, 6, 7, 8, 9}
# randrange 可以省略start的值, 默认使用0
In [4]: {random.randrange(10) for _ in range(100)}
Out[4]: {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
# randrange 指定步长
In [5]: {random.randrange(1, 10, step=3) for _ in range(100)}
Out[5]: {1, 4, 7}getrandbits(k), 返回一个2进制k位能表达的数据大小中的随机一个数据. 数据范围 [0, 2^k ]
# getrandbits 返回0-2^4之间的数据
In [6]: {random.getrandbits(4) for _ in range(100)}
Out[6]: {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15}2.3 随机序列 choice, choices, shuffle, sample
choice(seq), 从非空序列seq中随机返回一个值
In [7]: data = ['A', 'B', 'C', 'D', 'E', 'F']
In [8]: random.choice(data)
Out[8]: 'D'
In [9]: random.choice(data)
Out[9]: 'E'sample(seq, k), 从非空序列seq中随机取k个元素, 返回一个列表, 数据不可以重复.
In [10]: random.sample(data, 2)
Out[10]: ['E', 'B']
In [11]: random.sample(data, 4)
Out[11]: ['D', 'E', 'A', 'F']
shuffle(seq), 将seq数据原地打乱顺序
In [12]: data = ['A', 'B', 'C', 'D', 'E', 'F']
In [13]: random.shuffle(data)
In [14]: data
Out[14]: ['F', 'D', 'C', 'A', 'B', 'E']choices(seq, weights=None , * , cum_weights=None , k=1), 从非空序列seq中随机取k个元素, 返回一个列表, 数据可以重复, weights和cum_weights字段为对应位置数据的权重和相对权重, 如果指定权重, 权重列表需要和seq长度一致.
In [15]: data = ['A', 'B', 'C', 'D', 'E', 'F']
In [16]: random.sample(data, k=8)
---------------------------------------------------------------------------
ValueError: Sample larger than population or is negative
In [17]: random.choices(data, k=8)
Out[17]: ['E', 'A', 'D', 'F', 'F', 'E', 'A', 'C']从以上代码可以看到, choices与sample的最大不同是, choices获取的数据可以重复, 这样可以生成长度比原数据还要大的列表.
下面为了便于理解choices函数中的权重参数的使用, 需要使用collections.Counter来更直观的统计随机取的数据的个数.
In [18]: Counter(random.choices(data, k=600))
Out[18]: Counter({'F': 114, 'A': 97, 'C': 103, 'B': 92, 'E': 105, 'D': 89})可以看到, 默认所有数据权重一致, 所以choices取600个数据, ABCDEF每个数据大概是100次左右.
下面我们指定权重weights字段
In [19]: Counter(random.choices(data, weights=[0, 0, 10, 10, 20, 20], k=600))
Out[19]: Counter({'E': 189, 'F': 209, 'C': 104, 'D': 98})可以看到, 指定了weithts =[0, 0, 10, 10, 20, 20]之后, 字符AB因为对应的权重为0, 所以结果中1次都没有出现, 字符C D E F 按照配的权重按照 1 : 1 : 2 : 2的比例出现
还可以使用 cum_weights 参数。它代表交换权重。cum_weights与weights的换算关系为
cum_weights[0] = weights[0]
cum_weights[n] = sum(weights[:n-1])
如 weights = [5,10,20,30,35] 对应的
cum_weights = [5,15,35,65,100]
In [20]: Counter(random.choices(data, cum_weights=[0, 0, 10, 20, 40, 60], k=600))
Out[20]: Counter({'C': 101, 'F': 204, 'E': 198, 'D': 97})将cum_weights=[0, 0, 10, 20, 40, 60] 可以达到和之前使用weithts =[0, 0, 10, 10, 20, 20], 相同的效果.
?一个常用的使用场景?
生成指定长度的随机字符串
In [1]: import random
In [2]: import string
In [3]: ''.join(random.choices(string.ascii_letters+string.punctuation, k=10))
Out[3]: 'ZmoA,u*{"~'
In [4]: ''.join(random.choices(string.ascii_letters+string.punctuation, k=10))
Out[4]: 'U";}vc\\Fl&'3. 其他分布方法
如果按照概率分布生成一系列数据, random内置提供了一系列分布函数的随机数方法
| 函数 | 说明 |
| random() | 返回范围 [0.0, 1.0) 中的下一个随机浮点数 |
| uniform(a, b) | 返回[min(a, b), max(a, b)] 范围内的一个随机浮点数 |
| triangular(low, high, mode) | 具有这些边界之间的指定模式的对称分布 |
以triangular为例
import random
import matplotlib.pyplot as plt
# store the random numbers in a list
nums = []
low = 10
high = 100
mode = 20
for i in range(10000):
temp = random.triangular(low, high, mode)
nums.append(temp)
# plotting a graph
plt.hist(nums, bins = 200)
plt.show()输出: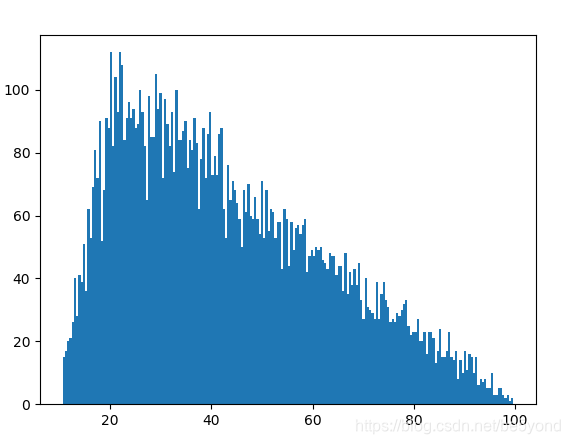
另外还有 正态分布normalvariate, 高斯分布 gauss等, 本文不再介绍了.
总结:
① Python 的随机是伪随机, 可以通过seed和getstate来获取当前随机的种子状态
② 基本的随机数据方法
- 字节: randbytes
- 整数: randint, randrange
- 序列: choice, sample, choices
③ 内置的概率数据分布模型