Faster-RCNN
一.背景
最新的物体检测网络依赖于候选框(生成)算法来假设物体位置。最新的进展如SPPnet[1]和Fast R-CNN[2]已经减少了检测网络的时间,(间接)凸显出候选框计算成为算法时间的瓶颈。Faster-RCNN引入了Region Proposal Network (RPN) ,它和检测网络共享整图的卷积特征,这样使得候选框的计算几乎不额外占用时间。RPN是一个全卷积网络,可同时预测物体外接框和每个位置是否为物体的得分。RPN采用端到端的方式进行训练,产生高质量的候选框,进而被Fast R-CNN用来做检测。Faster-RCNN通过共享卷积特征,进一步融合RPN和Fast R-CNN为一个网络——使用最近流行的基于注意力机制的网络技术,RPN单元指引统一后的网络查看的地方。对于很深的VGG-16模型[3],Faster-RCNN的检测系统在GPU上达到5fps(包括所有步骤)的效率,同时实现了VOC2007, 2012和MS COCO数据集上最好的准确率,此时每张图上仅产生300个候选框。在ILSVRC和COCO 2015竞赛中,Faster R-CNN和RPN是几个不同领域中第一名模型的基础。代码已经开源。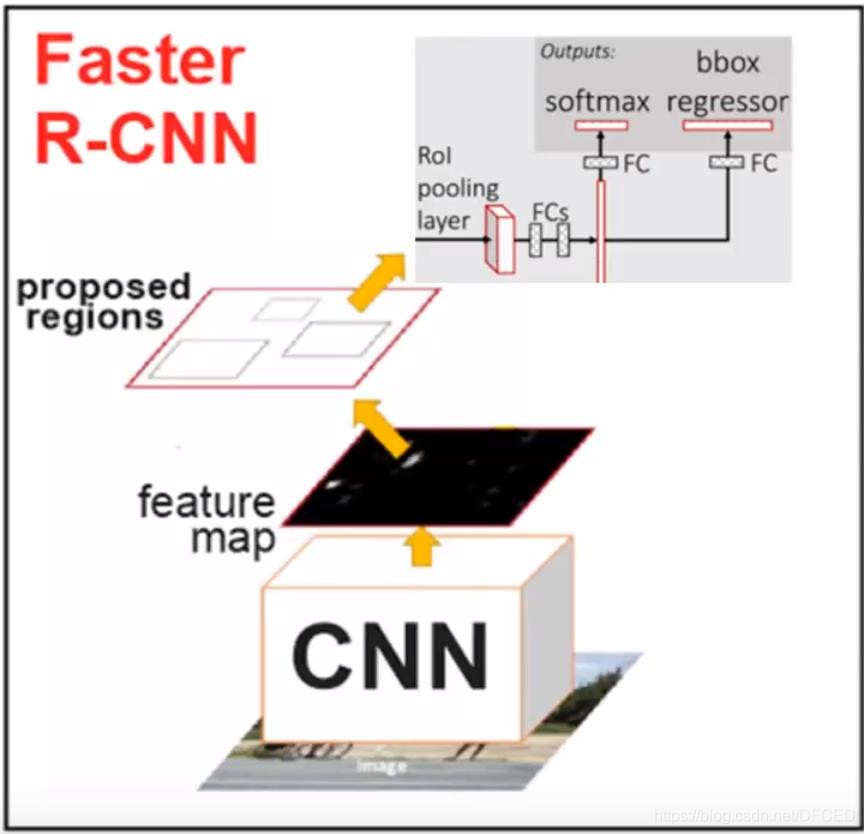
经过R-CNN和Fast RCNN算法的历程,Ross B. Girshick在2016年提出了新的Faster RCNN,在结构上,Faster RCNN已经将特征抽取(feature extraction),proposal提取,bounding box regression(rect refine),classification都整合在了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。
二.Faster-RCNN算法流程
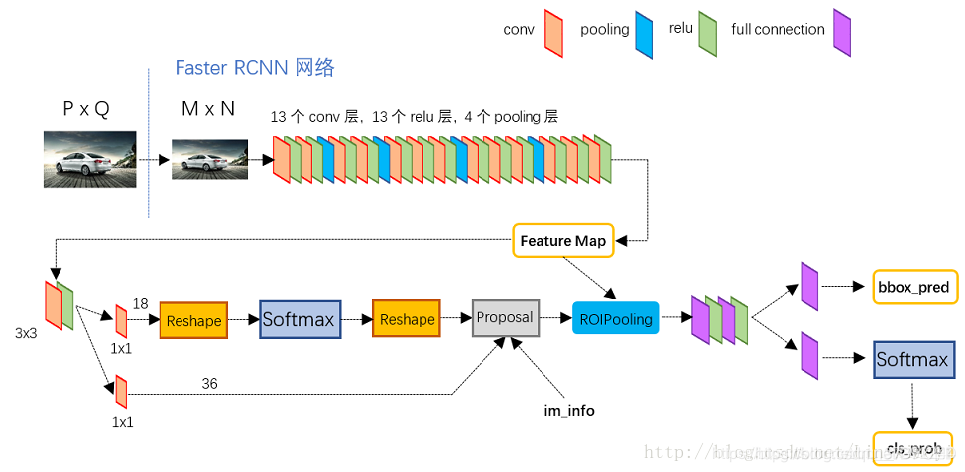
算法步骤
1.Conv layers.作为一种cnn网络目标检测的方法,faster_rcnn首先使用一组基础conv+relu+pooling层提取image的feture map。该feature map被共享用于后续的RPN层和全连接层。
2.Region Proposal Networks.RPN层是faster-rcnn最大的亮点,RPN网络用于生成region proposcals.该层通过softmax判断anchors属于foreground或者background,再利用box regression修正anchors获得精确的propocals(anchors也是作者自己提出来的,后面我们会认真讲)
3.Roi Pooling.该层收集输入的feature map 和 proposcal,综合这些信息提取proposal feature map,送入后续的全连接层判定目标类别。
4.Classification。利用proposal feature map计算proposcal类别,同时再次bounding box regression获得检验框的最终精确地位置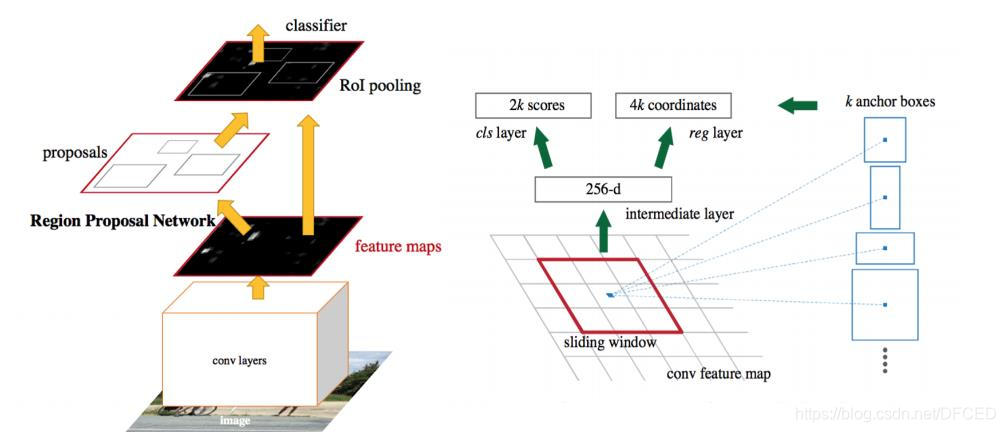
2.1 卷积层(Conv layer)
在input-data层时,作者把原图都reshape成M×N大小的图片
conv layer中包含了conv relu pooling三种层,就VGG16而言,就有13个conv层,13个relu层,4个pooling层。在conv layer中:
1.所有的conv层都是kernel_size=3,pad=1
2.所有的pooling层都是kernel_size=2,stride=2
所以,一个MxN大小的矩阵经过conv_layers固定变为(M/16)x(N/16)!这样conv_layers生成的featuure map中都可以和原图对应起来。最后得到51x39x256
如图所示卷积操作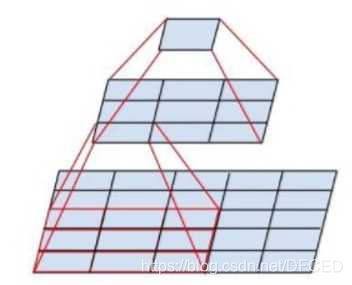
2.2 区域建议网络(Region Proposal Networks)
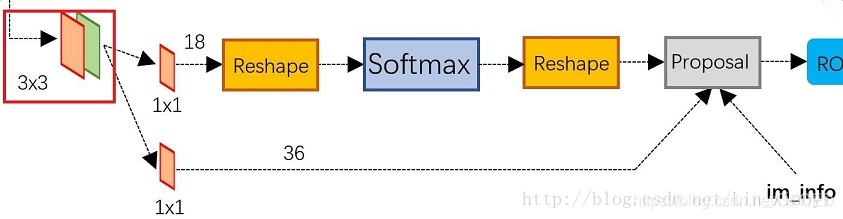
RPN以一张任意大小的图片作为输入,输出一组矩形object proposals,每一个带有一个objectness score。Faster-RCNN使用全连接网络(full convelutional network)对这一过程进行建模,由于最终目的是与一个Fast R-CNN对象检测网络共享计算,假定两个网络共享一组卷积网络。其使用了Zeiler and Fergus(ZF)模型(带5层可共享的卷积层)和Simonyan and Zisserman (VGG-16)模型(带13层可共享的卷积层)。
通过在最后一层共享卷积层输出的卷积feature map上滑动一个小网络(窗口)来生成region proposals。这个小网络将输入卷积feature map的nn spacial window作为输入。每个滑窗映射到低维特征(ZF为256维,VGG为512维,后面跟着ReLU)。这个特征被送入到两个全连接层——box-regreesion层(reg)和一个box-classification层(cls)。n=3,注意输入图片的有效接受域(ZF为171个像素点,VGG为228个像素点)。这个迷你网络如下图所示。由于迷你网络是以滑窗的方式来进行的,全连接层是通过所有空间位置来共享的。这个架构通过nn卷积层后面跟着两个1*1卷积层(分别为reg和cls)实现的。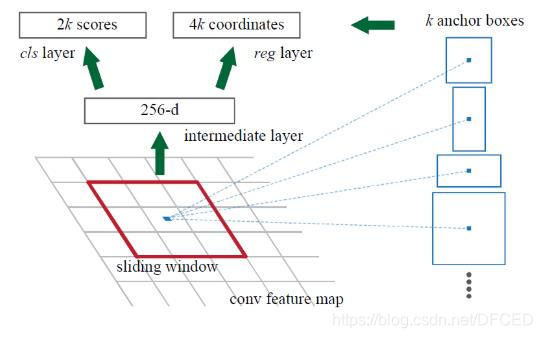
何为anchor?
在feature map上的每个特征点预测多个region proposals。具体作法是:把每个特征点映射回原图的感受野的中心点当成一个基准点,然后围绕这个基准点选取k个不同scale、aspect ratio的anchor。论文中3个scale(三种面积{ 128^2, 256^2,
521^2),3个aspect ratio({1:1,1:2,2:1})。虽然 anchors 是基于卷积特征图定义的,但最终的 anchos 是相对于原始图片的。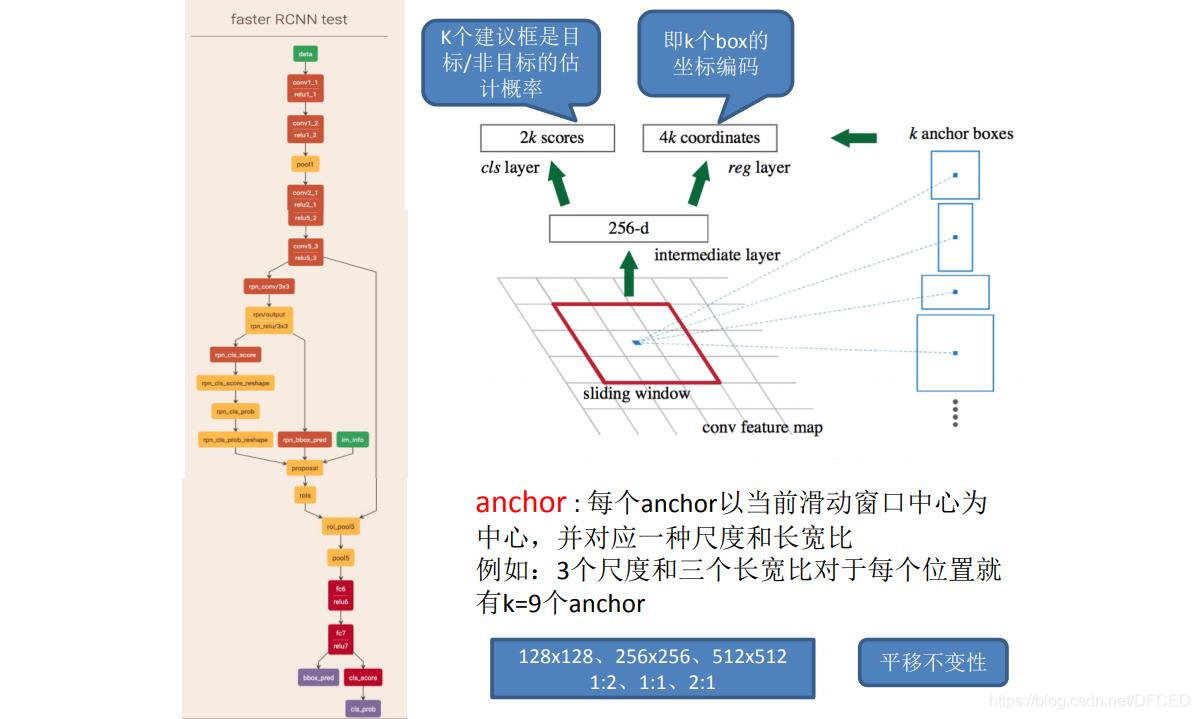
平移不变anchor(Translation-Invariant Anchors)
这种方法的一大主要特征是平移不变性(translation invariant),而类似于MultiBox之类的方法使用K-means来生成800个anchor,不具有平移不变性。
同时平移不变性降低了模型的大小。MultiBox有(4+1)*800维的全连接输出层,论文中的方法在k=9时仅有(4+2)*9维卷积输出层。因此,这种方法的参数远远少于MultiBox的参数。
多尺度anchor作为回归引用
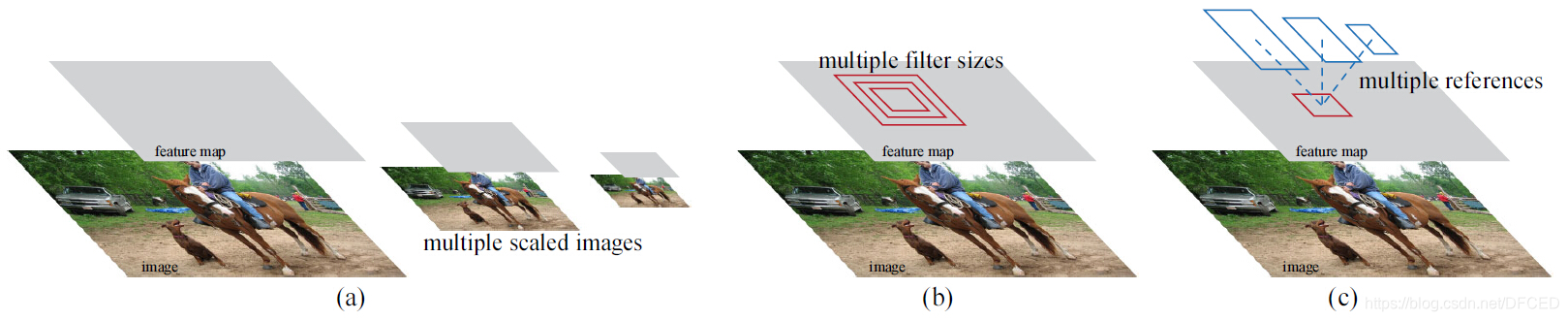
作者对anchor的设计使用了一种新颖的机制来处理多尺度(以及长宽比)。上图展示了两种流行的多尺度预测(multi-scale prediction)方法。一种是基于图像/特征金字塔(image/feature pyramid)。这种方法将图像resize到多种尺度,然后为针对于一种尺度计算feature map或者深度卷积特征(deep convelotional feature),有效但是耗时。第二种方法是在feature map上使用多尺度(和/或长宽比)的滑窗。例如,DPM分别使用不同大小的filter来训练不同长宽比的模型。若这种方法用来解决多尺度问题,可以认为是“filter金字塔(pyramid of filters)”。第二种方法通常与第一种方法一起使用。
作者基于anchor的方法建立了一个anchor的金字塔(pyramid of anchors),更加高效。我们的方法对与多尺度和多长宽比的anchor box相关联的bounding boxes进行分类和回归。他仅仅依赖于单一尺度的图片和feature map,并且使用单一大小的filter(feature map上的滑窗)。
2.3 Roi Pooling
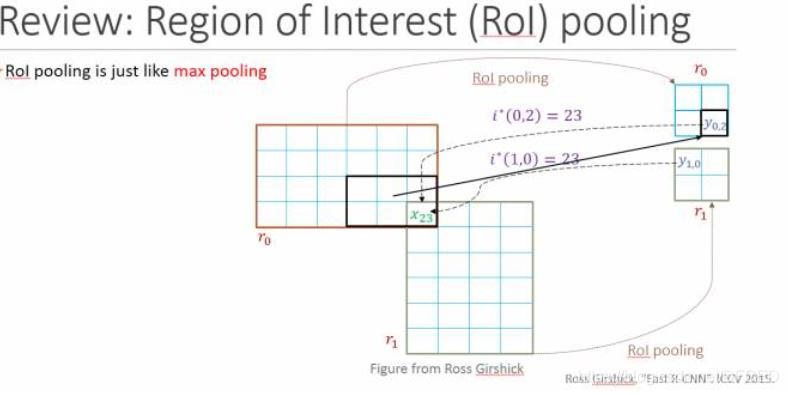
ROI pooling层能实现training和testing的显著加速,并提高检测accuracy。该层有两个输入:
- 从具有多个卷积核池化的深度网络中获得的固定大小的feature maps;
- 一个表示所有ROI的N*5的矩阵,其中N表示ROI的数目。第一列表示图像index,其余四列表示其余的左上角和右下角坐标;
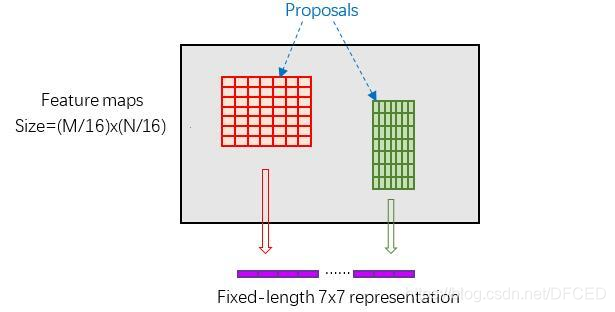
ROI pooling具体操作如下:
(1)根据输入image,将ROI映射到feature map对应位置;
(2)将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
(3)对每个sections进行max pooling操作;
这样我们就可以从不同大小的方框得到固定大小的相应 的feature maps。值得一提的是,输出的feature maps的大小不取决于ROI和卷积feature maps大小。ROI pooling 最大的好处就在于极大地提高了处理速度。
2.4 Classification
classification部分利用已经获得的proposal featuer map,通过full connect层与softmax计算每个proposal具体属于哪个类别(如车,人等),输出cls_prob概率向量;同时再次利用Bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。classification部分网络结构如下: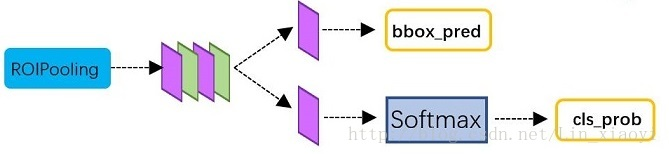
(图片来自网络)
从RIO Pooling获取到7*7=49大小的proposal feature maps后,送入后续的网络,可以看到做了如下2件事:
1:通过全连接层和softmax对proposal进行分类,这实际上已经是识别的范畴了
2:再次对proposals进行bounding box regression,获取更高精度的rect box
2.5 损失函数
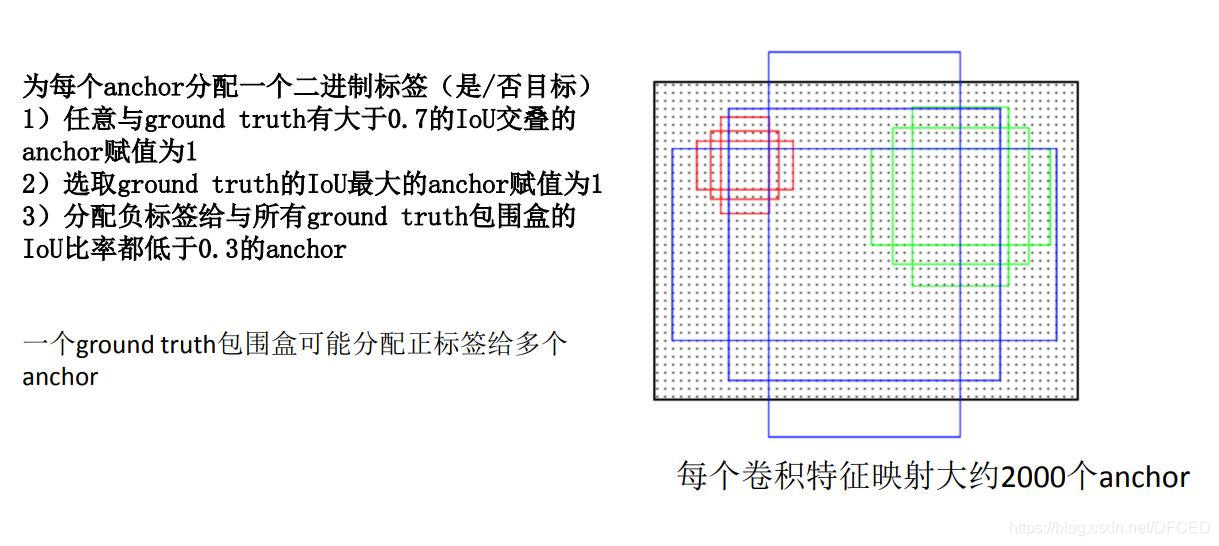
为了训练RPNs,我们为每个anchor设定了一个二值分类标签(是一个object或者不是)。我们给以下两类anchor标定一个正标签(positive label):(i)与ground-truth box有最高Intersection-over-Union (IoU)的anchor;(ii)与任意ground-truth box的IoU重叠超过0.7的anchor。并且给与所有ground-truth boxes的IoU比例小于0.3的非正anchor标定一个负标签(negative label)。
损失函数定义为: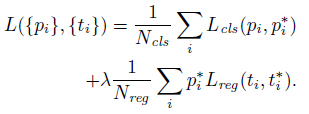
其中,i为一个anchor在一个mini-batch中的下标,pi是anchor i为一个object的预测可能性。如果这个anchor是positive的,则ground-truth标签pi为1,否则为0。ti表示预测bounding box的4个参数化坐标,ti是这个positive anchor对应的ground-truth box。分类的损失(classification loss)Lcls是一个二值分类器(是object或者不是)的softmax loss。回归损失(regression loss),其中R是Fast R-CNN中定义的robust ross function (smooth L1)。piLreg表示回归损失只有在positive anchor(pi=1)的时候才会被激活。cls与reg层的输出分别包含{pi}和{ti}。
这里还有一个平衡参数λ来权衡Ncls和Nreg。cls term标准化为mini-batch的大小(Ncls256),reg term标准化为anchor位置的数目(Nreg~2400)。默认λ=10。
对于bounding box的回归,应用了以下4个坐标的参数化:
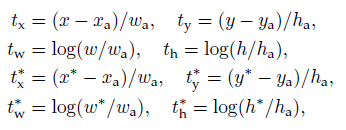
x、y、w、h表示box中心的坐标以及它的宽度和高度。变量x、xa和x*分别针对于预测的box、anchor boxhe ground-truth box(y、w、h也是一样的)。可以认为是从一个anchor box到一个附近的ground-truth box的bouding box回归。
通过一种不同的方式来获取bounding-box回归。在feature map上,用于回归的feature具有相同的空间大小(3×3)。为了解决变化大小的问题,让其学习k个bouding box回归量。每个回归量对应一个尺度和一个长宽比,并且k个回归量并没有共享权值。因此,尽管feature是固定的大小,仍能预测不同大小的box。
三. Faster-RCNN 的训练
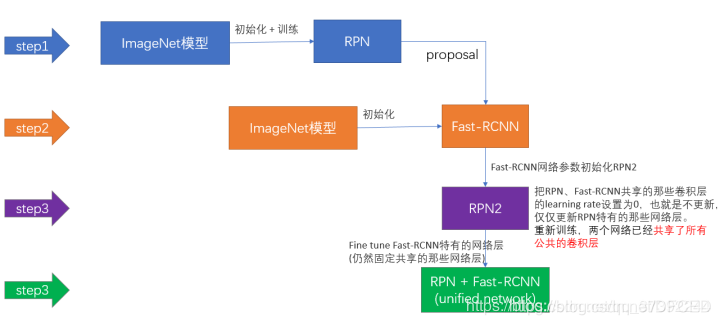
(图片来自网络)
第一步:用ImageNet模型初始化,独立训练一个RPN网络;
第二步:仍然用ImageNet模型初始化,但是使用上一步RPN网络产生的proposal作为输入,训练一个Fast-RCNN网络,至此,两个网络每一层的参数完全不共享;
第三步:使用第二步的Fast-RCNN网络参数初始化一个新的RPN网络,但是把RPN、Fast-RCNN共享的那些卷积层的learning rate设置为0,也就是不更新,仅仅更新RPN特有的那些网络层,重新训练,此时,两个网络已经共享了所有公共的卷积层;
第四步:仍然固定共享的那些网络层,把Fast-RCNN特有的网络层也加入进来,形成一个unified network,继续训练,fine tune Fast-RCNN特有的网络层,此时,该网络已经实现我们设想的目标,即网络内部预测proposal并实现检测的功能。
三.Faster-RCNN 的不足-----YOLO算法的出现
1、 还是无法达到实时检测目标;
2、 获取region proposal,再对每个proposal分类计算量还是比较大。