我们的第一个程序是直接用urllib.urlopen()直接打开网页,这个程序简单又快捷,简直不能再好了。美中不足的就是这个程序太粗糙了,如果我们用fiddler检查一下我们的请求头,就会看见这个
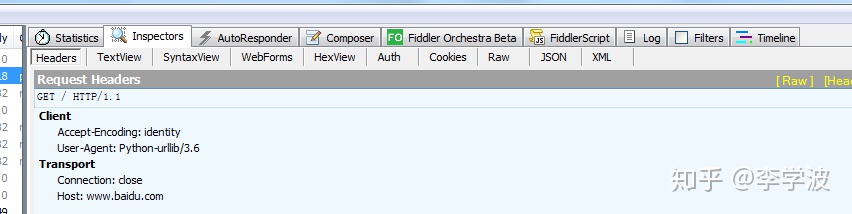
仔细看一下我们发现User-Agent后面是Python-urllib/3.6,这就相当于告诉服务器:我是一个python程序,我正在爬取你的信息。这可不行,既然我们要用程序模拟浏览器那么就要模仿的像一点,这个时候我们就要构建一个请求体(功能强大的requests模块已经把这个过程封装好了,还有其他一些基础功能它也直接封装了,所以对于requests模块是人见人爱,赞一个!),伪装一下我们的请求头,告诉服务器:其实我是一个浏览器。
过程如下:
#引入模块
#注意:Python 升级到 2.7.9 之后引入了一个新特性,当使用urllib.urlopen打开一个 https 链接时,会验证一次 SSL 证书。而当目标网站使用的是自签名的证书时就会抛出异常。我们全局取消证书验证importssl
ssl._create_default_https_context = ssl._create_unverified_contextimporturllib.request#我们就用喜闻乐见的妹子图实验一把
url='https://www.mzitu.com/xinggan/'#找一个请求头,写成如下格式
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36'
}#构建一个请求体
request=urllib.request.Request(url=url,headers=headers)#发送请求,获取响应
response=urllib.request.urlopen(request)
print(response.read().decode())
我们已经获取到了妹子图的起始网页信息,先别着急流鼻血,我们现在只是获取了网页信息,后面的功能比如解析网页获取图片,保存图片,翻页等等还没有搞好。后面再来。