1. SKNet 论文思维导图
该思维导图使用 MindMaster 软件做出,源文件可以点击链接进行下载。
2. Selective kernel 结构介绍
本节主要介绍这篇论文的核心部分,即 Selective kernel 的相关内容
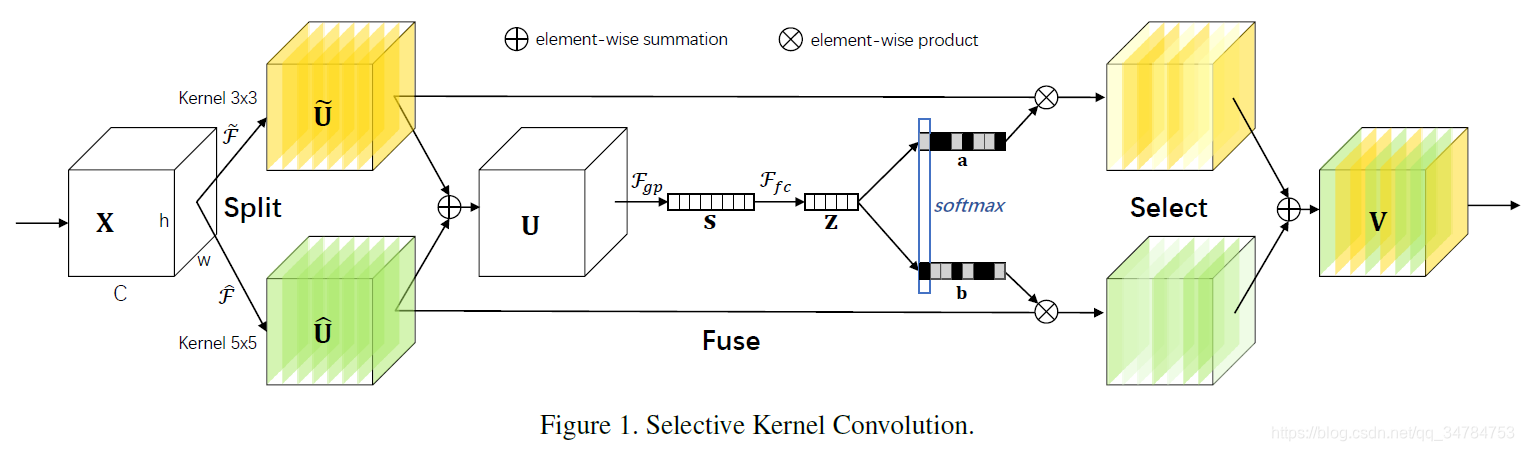
上图给出的是 Selective Kernel Convolution 的示意图,可以看出,此结构主要由三个部分组成,即:
Split:
这部分的主要作用的将原特征分为几个不同的形状大小完全相同的特征,在本文中分为了两部分,分别是 3 ∗ 3 3*33∗3 和 5 ∗ 5 5*55∗5 的卷积。且文中说明,所使用的卷积都是 分组/可分离 卷积的形式。对于 5 ∗ 5 5*55∗5 的卷积,可以采用膨胀因子是 2 的 3 ∗ 3 3*33∗3 的膨胀卷积;
假设在 Split 部分前的特征为 X ∈ R H ′ × W ′ × C ′ X\in\mathbb R^{H'\times W'\times C'}X∈RH′×W′×C′,在本文中经过两个操作生成形状相同的两部分特征,即
F ~ : X → U ~ ∈ R H × W × C \tilde{\mathcal F}:\bold X\to\tilde{\bold U}\in\mathbb R^{H\times W\times C}F~:X→U~∈RH×W×C 和 F ^ : X → U ^ ∈ R H × W × C \hat{\mathcal F}:\bold X\to\hat{\bold U}\in\mathbb R^{H\times W\times C}F^:X→U^∈RH×W×C,其中 F ~ \tilde{\mathcal F}F~ 和 F ^ \hat{\mathcal F}F^ 都是由顺序连接的 分组/可分离卷积构成的。
Fuse:
这部分的基本思想使用门来控制从不同分支流入的多尺度的信息流然后送入到下一层神经元。为了实现这个目标,需要进行如下操作:
各个分支的特征进行元素间的相加:
U = U ~ + U ^ \bold U = \tilde{\bold U}+\hat{\bold U}U=U~+U^然后使用全局平均池化来获得提特征的全局信息,具体操作如下所示:
s c = F g p ( U c ) = 1 H × W ∑ i = 1 H ∑ j = 1 W U c ( i , j ) s_c=\mathcal F_{gp}(\bold U_c)=\frac 1 {H\times W}\sum_{i=1}^H\sum_{j=1}^W\bold U_c(i,j)sc=Fgp(Uc)=H×W1i=1∑Hj=1∑WUc(i,j)然后,生成一个压缩后的特征向量 z ∈ R d × 1 \bold z\in\mathbb R^{d\times1}z∈Rd×1,这部分是通过一个缩减维度的全连接操作完成的,具体如下:
z = F f c ( s ) = δ ( B ( W s ) ) \bold z=\mathcal F_{fc}(\bold s)=\delta(\mathbb{\mathcal B}(\bold W\bold s))z=Ffc(s)=δ(B(Ws))
其中,δ \deltaδ 指的是 ReLU 激活函数,B \mathbb{\mathcal B}B 指的是 BN 操作,W ∈ R d × C \bold W\in\mathbb R^{d\times C}W∈Rd×C,为了研究缩减后的维度 d dd 对最后网络性能的影响,文中使用缩减比例系数 r rr 来进行控制:
d = m a x ( C / r , L ) d=max(C/r,L)d=max(C/r,L)
上式中 L LL 指的是网络中 d dd 能够达到的最小值,通常默认取 32。
Select:
经过上述两步后,得到了一个压缩的单维度的向量,接下来 select 模块的作用就是将这个向量重新分为两个(本文情况)或多个(更多的情况)特征向量,然后分别与相应的 split 之后的特征向量进行相应通道的相乘操作,然后再通过这种加权共同构成输入到下一个神经元的特征向量。
具体的实现方法是利用一个
soft attention across channels的思想,即平滑后的通道间的注意力思想,以此能够让网络有自适应的选择特征的不同尺度信息,它由特征 z \bold zz 生成。具体的,是将 softmax 操作应用于通道方向上,公式如下:
a c = e A c z e A c z + e B c z , b c = e B c z e A c z + e B c z a_c=\frac{e^{\bold A_c\bold z}}{e^{\bold A_c\bold z}+e^{\bold B_c\bold z}},\ \ b_c=\frac{e^{\bold B_c\bold z}}{e^{\bold A_c\bold z}+e^{\bold B_c\bold z}}ac=eAcz+eBczeAcz, bc=eAcz+eBczeBcz
其中 A , B ∈ R C × d \bold A,\bold B\in\mathbb R^{C\times d}A,B∈RC×d,a , b \bold a,\bold ba,b 分别表示 U ~ , U ^ \tilde{\bold U},\hat{\bold U}U~,U^ 的平滑注意力向量。其中 A c ∈ R 1 × d \bold A_c\in \mathbb R^{1\times d}Ac∈R1×d 表示 A \bold AA 的第 c cc 行,a c a_cac 表示 a \bold aa 的第 c cc 个元素值。对于向量 B \bold BB 同理。当仅存在两个分支的时候,可以看到,矩阵 B \bold BB 是多余的,因为有 a c + b c = 1 a_c+b_c=1ac+bc=1,网络最终的特征图 V \bold VV 可以由不同的注意力权重对相应特征进行加权后得到。公式如下所示:
V c = a c ⋅ U ~ c + b c ⋅ U ^ c , a c + b c = 1 \bold V_c=a_c\cdot\tilde{\bold U}_c+b_c\cdot\hat{\bold U}_c,\ \ a_c+b_c=1Vc=ac⋅U~c+bc⋅U^c, ac+bc=1
其中,V = [ V 1 , V 2 , . . . , V C ] , V c ∈ R H × W \bold V=[\bold V_1,\bold V_2,...,\bold V_C],\bold V_c\in\mathbb R^{H\times W}V=[V1,V2,...,VC],Vc∈RH×W。
思考:
- 这部分的 fuse 和 select 部分与 SENet 网络中的 SE block 结构都存在着相似之处,只是 SENet 中仅使用一个分支。
- 在 select 模块中,我个人目前的理解是通过两个矩阵(A , B ∈ R C × d \bold A,\bold B\in\mathbb R^{C\times d}A,B∈RC×d),使用类似于 softmax 的操作,也就是公式 5,但是与平时所使用的 softmax 操作不同的是,这个操作是在 通道方向进行的,也就是对于每个类别,都进行以此 softmax 操作,softmax 输出的个数与类别无关,而与最开始 split 为几个不同尺寸的卷积核相关。在本文中使用的是2,则每个类别出都输出的是2维。同理,如果使用 3 种不同的卷积核,则每个类别输出的均为 3 维。只有这样才能解释为什么使用两种不同的卷积核时会有 a c + b c = 1 a_c+b_c=1ac+bc=1。在使用 3 中卷积核时,同理应该有 a c + b c + c c = 1 a_c+b_c+c_c=1ac+bc+cc=1。
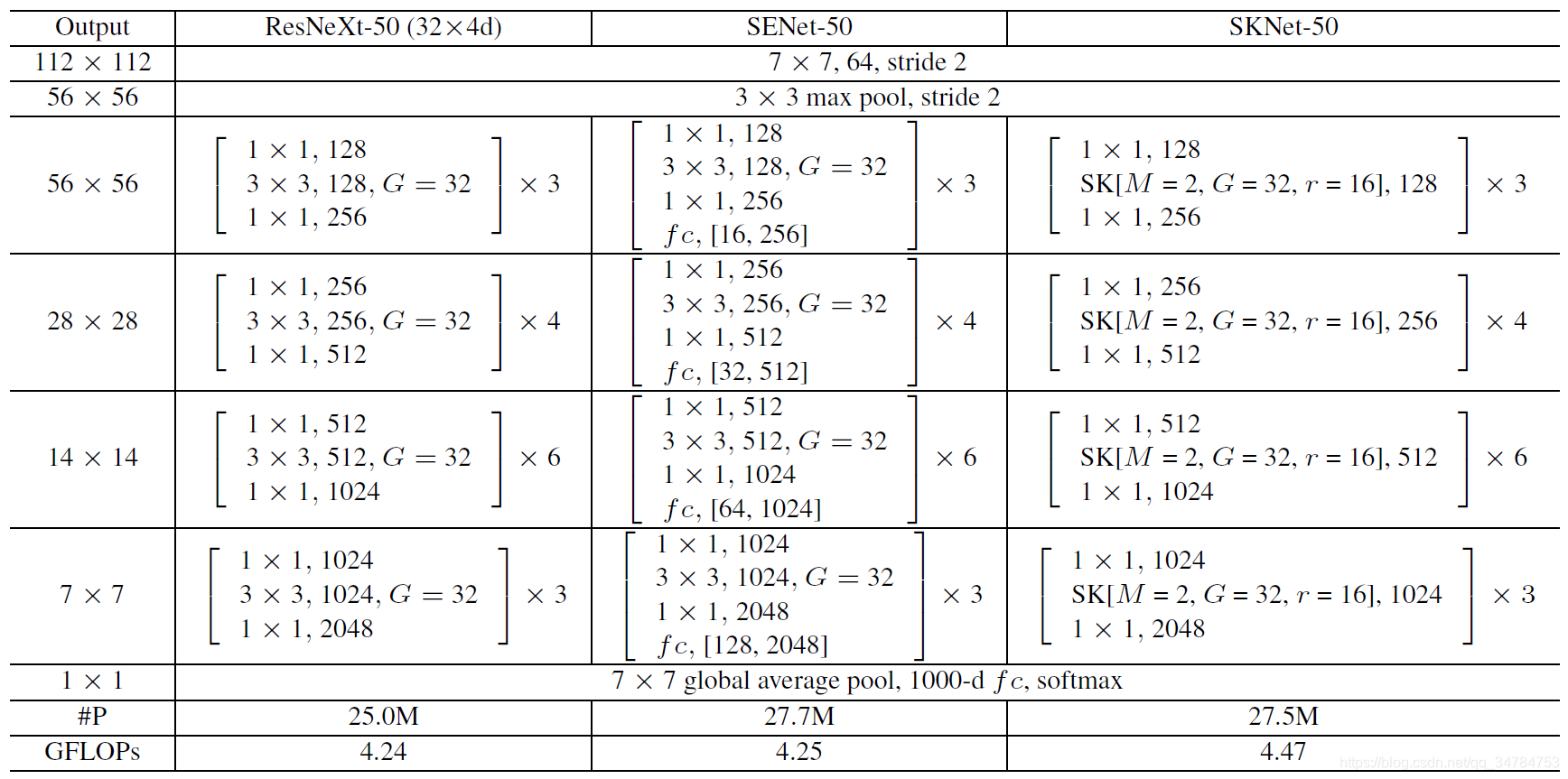
3. SKNet 网络结构
本文中使用的 SKNet 网络的主要结构如下所示:
4. 实验部分
本文的实验部分主要在 ImageNet 2012 数据集和 cifar 数据集上完成,关于这部分内容的分析可以查看作者在知乎上的分析,这里就不再赘述。知乎链接为:SKNet——SENet孪生兄弟篇