目录
3.1.6 Route Reflector 模式(RR)(路由反射)
一、calico 概述
1.1 calico 介绍
Calico 是一套开源的网络和网络安全方案,用于容器、虚拟机、宿主机之前的网络连接,可以用在kubernetes、OpenShift、DockerEE、OpenStrack等PaaS或IaaS平台上。
1.2、calico 的优点
- endpoints组成的网络是单纯的三层网络,报文的流向完全通过路由规则控制,没有overlay等额外开销;
- calico的endpoint可以漂移,并且实现了acl。
1.3、calico的缺点
- 路由的数目与容器数目相同,非常容易超过路由器、三层交换、甚至node的处理能力,从而限制了整个网络的扩张;
- calico的每个node上会设置大量(海量)的iptables规则、路由,运维、排障难度大;
- calico的原理决定了它不可能支持VPC,容器只能从calico设置的网段中获取ip;
- calico目前的实现没有流量控制的功能,会出现少数容器抢占node多数带宽的情况;
- calico的网络规模受到BGP网络规模的限制。
1.4、calico 优势
- 更优的资源利用: 二层网络通讯需要依赖广播消息机制,广播消息的开销与host的数量成指数级增长,calico使用的三层路由方法,则完全抑制了二层广播,减少了资源开销。另外二层网络使用VLAN隔离技术,天生有4096个规格的限制,即便可以使用vxlan解决,单vxlan又带来了隧道开销的新问题,而calico不使用VLAN或者vxlan,资源利用率更高;
- 可扩展性:Calico使用与Internet类似的方案,Internet的网络比任何书籍中心都大,Calico同样天然具有可扩展性;
- 简单更容器调试:没有隧道,workloads之间的路径更短更简单,配置更少,在host上更容器进行debug调试;
- 更少依赖:Calico仅依赖三层路由可达;
- 可适配性:较少的依赖使它能适配所有的VM、Container、白盒或者混合环境场景;
二、Calico结构组成
Calico不使用重叠网络比如flannel和libnetwork重叠网络驱动,它是一个纯三层的方法,使用虚拟路由代替虚拟交换,每一台虚拟路由通过BGP协议传播可达信息(路由)到剩余数据中心;Calico在每一个计算节点利用Linux Kernel实现了一个高效的vRouter来负责数据转发,而每个vRouter通过BGP协议负责把自己上运行的workload的路由信息像整个Calico网络内传播——小规模部署可以直接互联,大规模下可通过指定的BGP route reflector来完成。
2.1 架构
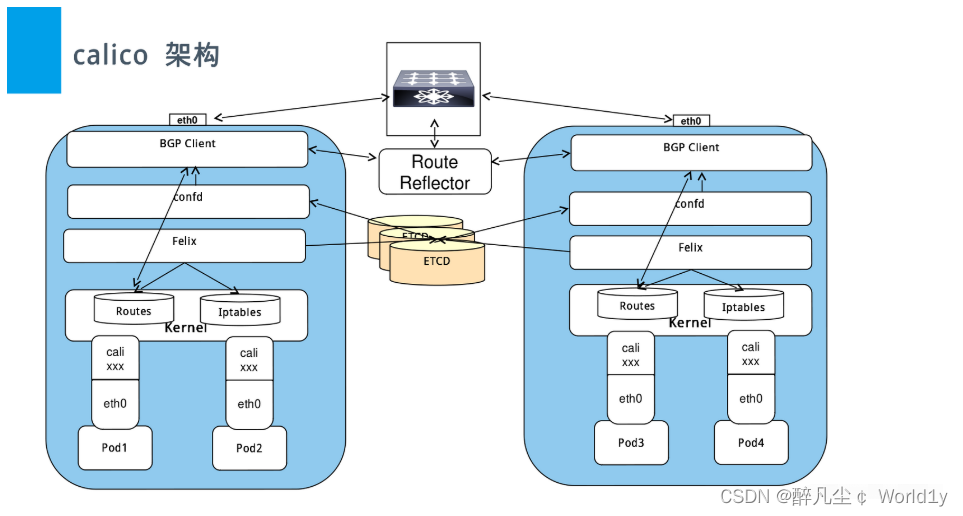
1. Felix:calico的核心组件,运行在每个节点上。主要的功能有接口管理、路由规则、ACL规则和状态报告
接口管理:Felix为内核编写一些接口信息,以便让内核能正确的处理主机endpoint的流量。特别是主机之间的ARP请求和处理ip转发。路由规则:Felix负责主机之间路由信息写到linux内核的FIB(Forwarding Information Base)转发信息库,保证数据包可以在主机之间相互转发。ACL规则:Felix负责将ACL策略写入到linux内核中,保证主机endpoint的为有效流量不能绕过calico的安全措施。状态报告:Felix负责提供关于网络健康状况的数据。特别是,它报告配置主机时出现的错误和问题。这些数据被写入etcd,使其对网络的其他组件和操作人员可见。
2.Etcd:保证数据一致性的数据库,存储集群中节点的所有路由信息。为保证数据的可靠和容错建议至少三个以上etcd节点。
3. Orchestrator plugin:协调器插件负责允许kubernetes或OpenStack等原生云平台方便管理Calico,可以通过各自的API来配置Calico网络实现无缝集成。如kubernetes的cni网络插件。
4. Bird:BGP客户端,Calico在每个节点上的都会部署一个BGP客户端,它的作用是将Felix的路由信息读入内核,并通过BGP协议在集群中分发。当Felix将路由插入到Linux内核FIB中时,BGP客户端将获取这些路由并将它们分发到部署中的其他节点。这可以确保在部署时有效地路由流量。
5. BGP Router Reflector:大型网络仅仅使用 BGP client 形成 mesh 全网互联的方案就会导致规模限制,所有节点需要 N^2 个连接,为了解决这个规模问题,可以采用 BGP 的 Router Reflector 的方法,使所有 BGP Client 仅与特定 RR 节点互联并做路由同步,从而大大减少连接数。
6. Calicoctl:calico 命令行管理工具。
2.2 名词解释
endpoint: 接入到calico网络中的网卡称为endpoint AS: 网络自治系统,通过BGP协议与其它AS网络交换路由信息 ibgp: AS内部的BGP Speaker,与同一个AS内部的ibgp、ebgp交换路由信息。 ebgp: AS边界的BGP Speaker,与同一个AS内部的ibgp、其它AS的ebgp交换路由信息。 workloadEndpoint: 虚拟机、容器使用的endpoint hostEndpoints: 物理机(node)的地址
实际上,Calico 项目提供的 BGP 网络解决方案,与 Flannel 的 host-gw 模式几乎一样。也就是说,Calico也是基于路由表实现容器数据包转发,但不同于Flannel使用flanneld进程来维护路由信息的做法,而Calico项目使用BGP协议来自动维护整个集群的路由信息。
2.3 组网原理
calico组网的核心原理就是IP路由,每个容器或者虚拟机会分配一个workload-endpoint(wl)。
从nodeA上的容器A内访问nodeB上的容器B时:
+--------------------+ +--------------------+
| +------------+ | | +------------+ |
| | | | | | | |
| | ConA | | | | ConB | |
| | | | | | | |
| +-----+------+ | | +-----+------+ |
| |veth | | |veth |
| wl-A | | wl-B |
| | | | | |
+-------node-A-------+ +-------node-B-------+
| | | |
| | type1. in the same lan | |
| +-------------------------------+ |
| |
| type2. in different network |
| +-------------+ |
| | | |
+-------------+ Routers |-------------+
| |
+-------------+
从ConA中发送给ConB的报文被nodeA的wl-A接收,根据nodeA上的路由规则,
经过各种iptables规则后,转发到nodeB。
如果nodeA和nodeB在同一个二层网段,下一条地址直接就是node-B,
经过二层交换机即可到达。
如果nodeA和nodeB在不同的网段,报文被路由到下一跳,经过三层交换或路由器,
一步步跳转到node-B。核心问题是,nodeA怎样得知下一跳的地址?
答案是node之间通过BGP协议交换路由信息。
每个node上运行一个软路由软件bird,并且被设置成BGP Speaker,与其它node通过BGP协议交换路由信息。
可以简单理解为,每一个node都会向其它node通知这样的信息:
我是X.X.X.X,某个IP或者网段在我这里,它们的下一跳地址是我。
通过这种方式每个node知晓了每个workload-endpoint的下一跳地址。
2.4、Calico 工作原理
Calico把每个操作系统的协议栈认为是一个路由器,然后把所有的容器认为是连在这个路由器上的网络终端,在路由器之间跑标准的路由协议——BGP的协议,然后让它们自己去学习这个网络拓扑该如何转发。所以Calico方案其实是一个纯三层的方案,也就是说让每台机器的协议栈的三层去确保两个容器,跨主机容器之间的三层连通性。
对于控制平面,它每个节点上会运行两个主要的程序,一个是Felix,它会监听ECTD中心的存储,从它获取事件,比如说用户在这台机器上加了一个IP,或者是分配了一个容器等。接着会在这台机器上创建出一个容器,并将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。绿色部分是一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,你们路由的时候得到这里来。
由于Calico是一种纯三层的实现,因此可以避免与二层方案相关的数据包封装的操作,中间没有任何的NAT,没有任何的overlay,所以它的转发效率可能是所有方案中最高的,因为它的包直接走原生TCP/IP的协议栈,它的隔离也因为这个栈而变得好做。因为TCP/IP的协议栈提供了一整套的防火墙的规则,所以它可以通过IPTABLES的规则达到比较复杂的隔离逻辑。
三、Calico 网络模式
BGP 边界网关协议(Border Gateway Protocol, BGP):是互联网上一个核心的去中心化自治路由协议。BGP不使用传统的内部网关协议(IGP)的指标。
Route Reflector 模式(RR)(路由反射):Calico 维护的网络在默认是(Node-to-Node Mesh)全互联模式,Calico集群中的节点之间都会相互建立连接,用于路由交换。但是随着集群规模的扩大,mesh模式将形成一个巨大服务网格,连接数成倍增加。这时就需要使用 Route Reflector(路由器反射)模式解决这个问题。
IPIP模式:把 IP 层封装到 IP 层的一个 tunnel。作用其实基本上就相当于一个基于IP层的网桥!一般来说,普通的网桥是基于mac层的,根本不需 IP,而这个 ipip 则是通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来。
3.1、BGP 概述
BGP(border gateway protocol)是外部路由协议(边界网关路由协议),用来在AS之间传递路由信息是一种增强的距离矢量路由协议(应用场景),基本功能是在自治系统间自动交换无环路的路由信息,通过交换带有自治系统号序列属性的路径可达信息,来构造自治系统的拓扑图,从而消除路由环路并实施用户配置的路由策略。
(边界网关协议(BGP),提供自治系统之间无环路的路由信息交换(无环路保证主要通过其AS-PATH实现),BGP是基于策略的路由协议,其策略通过丰富的路径属性(attributes)进行控制。BGP工作在应用层,在传输层采用可靠的TCP作为传输协议(BGP传输路由的邻居关系建立在可靠的TCP会话的基础之上)。在路径传输方式上,BGP类似于距离矢量路由协议。而BGP路由的好坏不是基于距离(多数路由协议选路都是基于带宽的),它的选路基于丰富的路径属性,而这些属性在路由传输时携带,所以我们可以把BGP称为路径矢量路由协议。如果把自治系统浓缩成一个路由器来看待,BGP作为路径矢量路由协议这一特征便不难理解了。除此以外,BGP又具备很多链路状态(LS)路由协议的特征,比如触发式的增量更新机制,宣告路由时携带掩码等。)
实际上,Calico 项目提供的
BGP网络解决方案,与Flannel的host-gw模式几乎一样。也就是说,Calico也是基于路由表实现容器数据包转发,但不同于Flannel使用flanneld进程来维护路由信息的做法,而Calico项目使用BGP协议来自动维护整个集群的路由信息。
3.1.1 BGP两种模式
全互联模式(node-to-node mesh)
全互联模式 每一个BGP Speaker都需要和其他BGP Speaker建立BGP连接,这样BGP连接总数就是N^2,如果数量过大会消耗大量连接。如果集群数量超过100台官方不建议使用此种模式。
RR模式 中会指定一个或多个BGP Speaker为RouterReflection,它与网络中其他Speaker建立连接,每个Speaker只要与Router Reflection建立BGP就可以获得全网的路由信息。在calico中可以通过Global Peer实现RR模式。
3.1.2 Calico BGP 概述
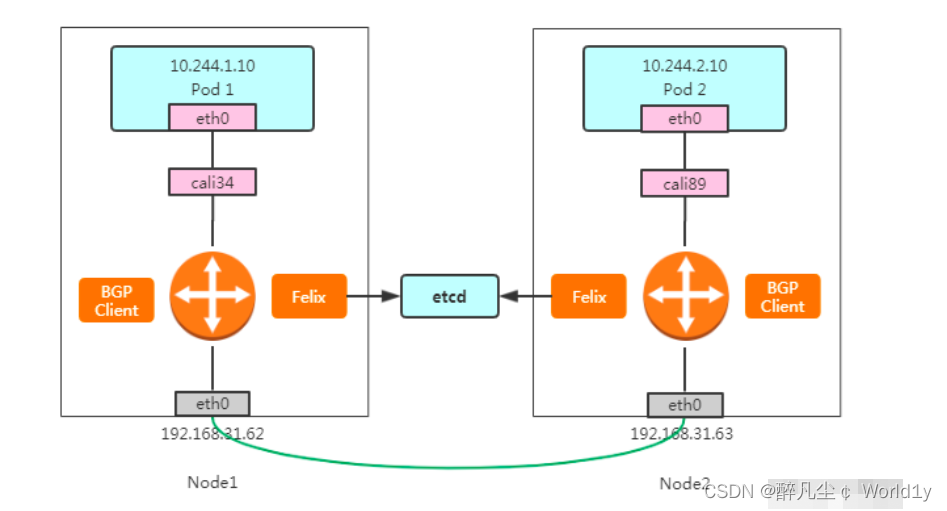
3.1.3 BGP 是怎么工作的?
这个也是跨节点之间的通信,与flannel类似,其实这张图相比于flannel,通过一个路由器来路由,flannel.1 就相比于vxlan模式去掉,所以会发现这里是没有网桥存在,完全就是通过路由来实现,这个数据包也是先从veth设备对另一口发出,到达宿主机上的cali开头的虚拟网卡上,到达这一头也就到达了宿主机上的网络协议栈,另外就是当创建一个pod时帮你先起一个infra containers的容器,调用calico的二进制帮你去配置容器的网络,然后会根据路由表决定这个数据包到底发送到哪里去,可以从ip route看到路由表信息,这里显示是目的cni分配的子网络和目的宿主机的网络,当进行跨主机通信的时候之间转发到下一跳地址走宿主机的eth0网卡出去,也就是一个直接的静态路由,这个下一跳就跟host-gw的形式一样,和host-gw最大的区别是calico使用BGP路由交换,而host-gw是使用自己的路由交换,BGP这个方案比较成熟,在大型网络中用的也比较多,所以要比flannel的方式好,而这些路由信息都是由BGP client传输。
3.1.4 为什么叫边界网关协议呢?
和 flannel host-gw 工作模式基本上一样,BGP是一个边界路由器,主要是在每个自治系统的最边界与其他自治系统的传输规则,而这些节点之间组成的BGP网络是一个全网通的网络,这个网络就称为一个 BGP Peer。
启动文件放在 /opt/cni/bin 目录下,/etc/cni/net.d 目录下记录子网的相关配置信息。
$ cat /etc/cni/net.d/10-calico.conflist
{
"name": "k8s-pod-network",
"cniVersion": "0.3.0",
"plugins": [
{
"type": "calico",
"log_level": "info",
"etcd_endpoints": "https://10.10.0.174:2379",
"etcd_key_file": "/etc/cni/net.d/calico-tls/etcd-key",
"etcd_cert_file": "/etc/cni/net.d/calico-tls/etcd-cert",
"etcd_ca_cert_file": "/etc/cni/net.d/calico-tls/etcd-ca",
"mtu": 1440,
"ipam": {
"type": "calico-ipam"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "portmap",
"snat": true,
"capabilities": {"portMappings": true}
}
]
}
3.1.5 Pod 1 访问 Pod 2 流程如下
1、数据包从 Pod1 出到达Veth Pair另一端(宿主机上,以cali前缀开头)
2、宿主机根据路由规则,将数据包转发给下一跳(网关)
3、到达 Node2,根据路由规则将数据包转发给 cali 设备,从而到达 Pod2。
其中,这里最核心的 下一跳 路由规则,就是由 Calico 的 Felix 进程负责维护的。这些路由规则信息,则是通过 BGP Client 中 BIRD 组件,使用 BGP 协议来传输。
不难发现,Calico 项目实际上将集群里的所有节点,都当作是边界路由器来处理,它们一起组成了一个全连通的网络,互相之间通过 BGP 协议交换路由规则。这些节点,我们称为 BGP Peer。
而 Flannel host-gw 和 Calico 的唯一不一样的地方就是当数据包下一跳到达node2节点容器时发生变化,并且出数据包也发生变化,知道它是从veth的设备流出,容器里面的数据包到达宿主机上,这个数据包到达node2之后,它又根据一个特殊的路由规则,这个会记录目的通信地址的cni网络,然后通过cali设备进去容器,这个就跟网线一样,数据包通过这个网线发到容器中,这也是一个二层的网络互通才能实现。
3.1.6 Route Reflector 模式(RR)(路由反射)
设置方法请参考官方链接 https://docs.projectcalico.org/master/networking/bgp
Calico 维护的网络在默认是 (Node-to-Node Mesh)全互联模式,Calico集群中的节点之间都会相互建立连接,用于路由交换。但是随着集群规模的扩大,mesh模式将形成一个巨大服务网格,连接数成倍增加。这时就需要使用 Route Reflector(路由器反射)模式解决这个问题。确定一个或多个Calico节点充当路由反射器,让其他节点从这个RR节点获取路由信息。
在BGP中可以通过calicoctl node status看到启动是 node-to-node mesh 网格的形式,这种形式是一个全互联的模式,默认的BGP在k8s的每个节点担任了一个BGP的一个喇叭,一直吆喝着扩散到其他节点,随着集群节点的数量的增加,那么上百台节点就要构建上百台链接,就是全互联的方式,都要来回建立连接来保证网络的互通性,那么增加一个节点就要成倍的增加这种链接保证网络的互通性,这样的话就会使用大量的网络消耗,所以这时就需要使用Route reflector,也就是找几个大的节点,让他们去这个大的节点建立连接,也叫RR,也就是公司的员工没有微信群的时候,找每个人沟通都很麻烦,那么建个群,里面的人都能收到,所以要找节点或着多个节点充当路由反射器,建议至少是2到3个,一个做备用,一个在维护的时候不影响其他的使用。
3.2、IPIP 模式概述
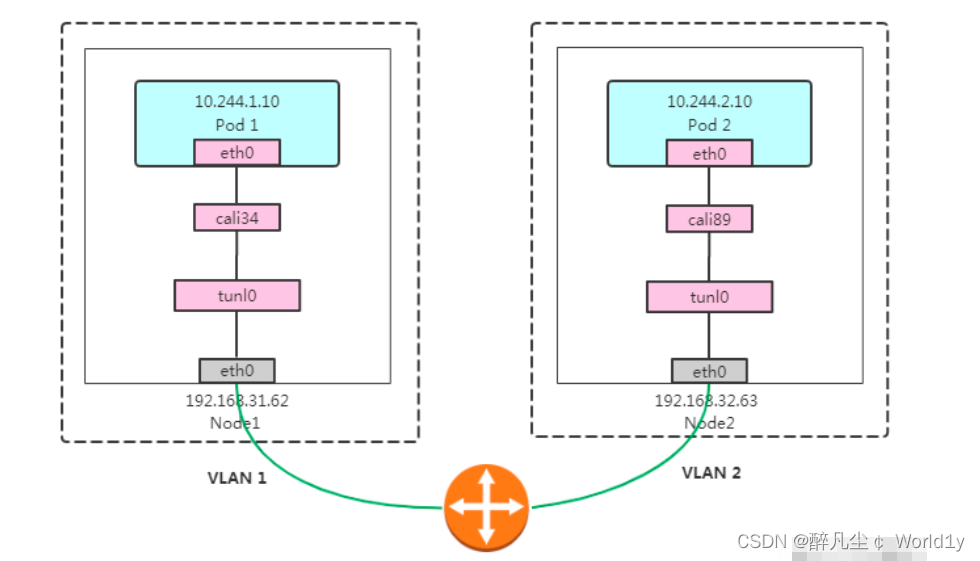
IPIP 是linux内核的驱动程序,可以对数据包进行隧道,上图可以看到两个不同的网络 vlan1 和 vlan2。基于现有的以太网将原始包中的原始IP进行一次封装,通过tunl0解包,这个tunl0类似于ipip模块,和Flannel vxlan的veth很类似。
3.2.1 Pod1 访问 Pod2 流程如下:
1、数据包从 Pod1 出到达Veth Pair另一端(宿主机上,以cali前缀开头)。
2、进入IP隧道设备(tunl0),由Linux内核IPIP驱动封装,把源容器ip换成源宿主机ip,目的容器ip换成目的主机ip,这样就封装成 Node1 到 Node2 的数据包。
此时包的类型:
原始IP包:
源IP:10.244.1.10
目的IP:10.244.2.10TCP:
源IP: 192.168.31.62
目的iP:192.168.32.63
3、数据包经过路由器三层转发到 Node2。
4、Node2 收到数据包后,网络协议栈会使用IPIP驱动进行解包,从中拿到原始IP包。
5、然后根据路由规则,将数据包转发给cali设备,从而到达 Pod2。
3.3 Calico 优势 与 劣势
优势
- 没有封包和解包过程,完全基于两端宿主机的路由表进行转发
- 可以配合使用
Network Policy做 pod 和 pod 之前的访问控制
劣势
- 要求宿主机处于同一个2层网络下,也就是连在一台交换机上
- 路由的数目与容器数目相同,非常容易超过路由器、三层交换、甚至node的处理能力,从而限制了整个网络的扩张。(可以使用大规模方式解决)
- 每个node上会设置大量(海量)的iptables规则、路由,运维、排障难度大。
- 原理决定了它不可能支持VPC,容器只能从calico设置的网段中获取ip。
3.4 两种网络的对比
IPIP网络:
- 流量:tunl0 设备封装数据,形成隧道,承载流量。
- 适用网络类型:适用于互相访问的pod不在同一个网段中,跨网段访问的场景。外层封装的ip能够解决跨网段的路由问题。
- 效率:流量需要tunl0设备封装,效率略低
BGP网络:
- 流量:使用路由信息导向流量
- 适用网络类型:适用于互相访问的pod在同一个网段,适用于大型网络。
- 效率:原生hostGW,效率高
总结:
| IPIP | BGP | |
| 流量 | tunl0封装数据,形成隧道,承载流量 | 路由信息导向流量 |
| 适用场景 | Pod跨网段互访 | Pod同网段互访,适合大型网络 |
| 效率 | 需要tunl0设备封装,效率略低 | 原生hostGW, 效率高 |
| 类型 | overlay | underlay |