grep命令详解
通用正则表达式解析器(grep,General Regular Expression Parser),打印符合某个特征的行。
使用实例:
查找指定进程:``ps -ef | grep md`

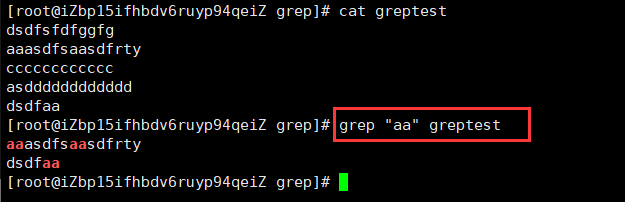
在指定文件中查找有关键字的行:``grep “aa” greptest`
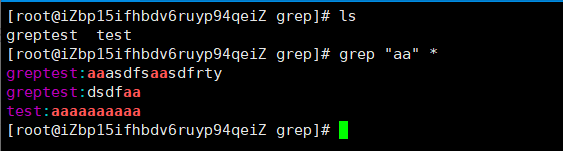
在多个文件中查找有关键字的行:``grep “aa” *`*表示该路径下的匹配零个或多个文件
管道符:
|命令1|命令2:命令1的正确执行结果作为明令2的操作对象。grep "aa" * |grep "ty"
参数使用
-c:计算符合样式的列数。grep -c “aa” \*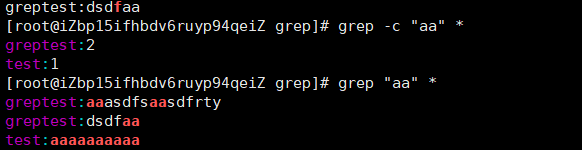
-A 显示行数:显示符合范本样式的那一列之外,并显示该行之后的内容(行数)。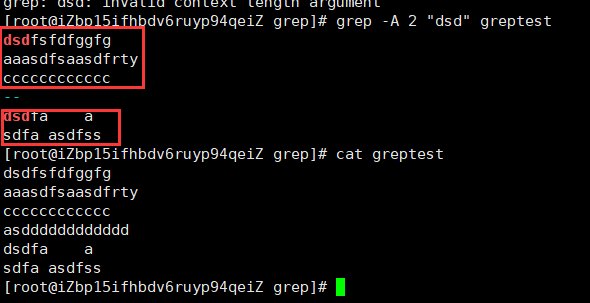
-B 显示行数:显示符合范本样式的那一列之外,并显示该行之前的内容(行数)。
-C 显示行数:显示符合范本样式的那一列之外,并显示该行之前后的内容(行数)。
-R:递归的对目录下的所有文件(包括子目录)进行 grep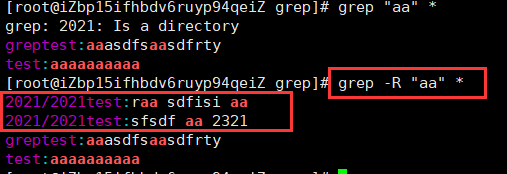
-i:忽略大小写-h:取消每个输出行前缀,即匹配查询模式的文件名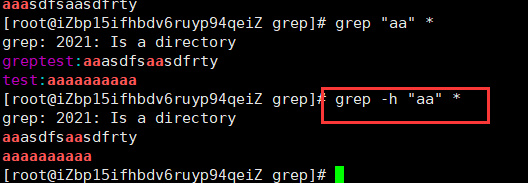
-l:只列出匹配行的文件名,而不输出真正的匹配行
grep默认支持通配符。正则表达式就是一些字符是有特殊含义的。
限定符 描述 实例 ^ 指向一行的开头 
$ 指向一行的结尾 
. 单个字符 
[ ] [0-9]字母集合,[0-9a-z]表示字母与数字集合,在这里边的^表示的不是一行开头而是非,[^0-9]非数字字符 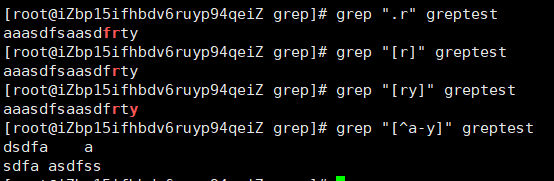
\< 锚定单词的开始(实际上是:匹配字符之前的空格) 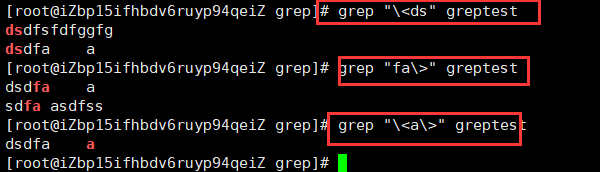
\> 锚定单词的结束(实际上是:匹配字符之前的空格) \b 等价于 \< 和 \> 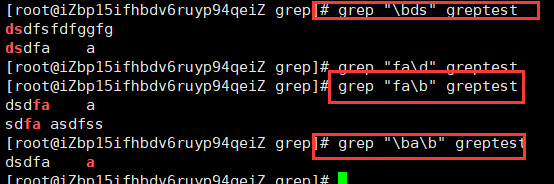
* 匹配前面的子表达式零次或多次。 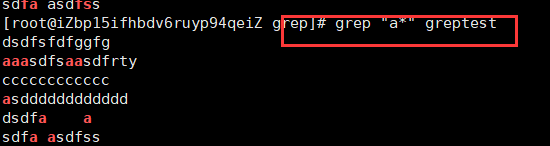
-E:扩展正则表达式,当默认的表达是不够用时,就要使用扩展正则表达式限定符 描述 实例 ? 匹配前面的子表达式,最多一次。 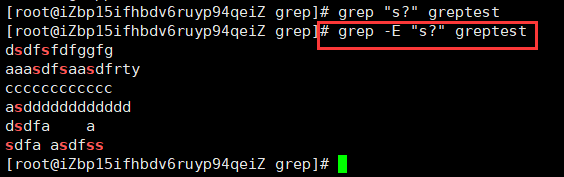
+ 匹配前面的子表达式一次或多次。 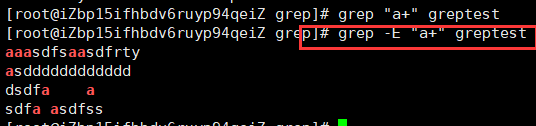
{N} 匹配前面的子表达式 N 次。 
{N,} 匹配前面的子表达式 N 次到多次。 {N,M} 匹配前面的子表达式 N 到 M 次,至少 N 次至多 M 次。
终端分页阅读器
有些文件非常长,无法在一屏的空间内显示完全。所以在查看这种文件时,我们需要分页显示。这时我们就可以使用 more ,less most 命令。
more 命令详解
- 空格键:查看下一屏; b键:查看上一屏
- 回车键:往下滚动一行;不支持向上滚动一行
- /字符串:向下搜索"字符串" 不支持向上搜索
- n键:匹配下一个关键字;不支持向上匹配
- q 键:退出。
缺点不能高亮查询,只能向下查询,不支持向上滚动一行
从指定行开始显示: more 默认是从第一行开始显示。但有时我们可能想直接从 100 行开始看,其实只需加一个
+50即可。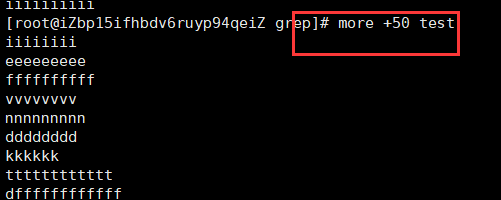
more 命令默认是整屏显示,如果我们一次只想查看几行,要怎么操作?只需加一个
-N选项即可,N 就是你想要查看的行数。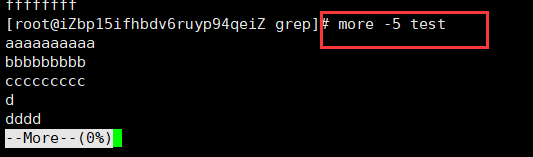
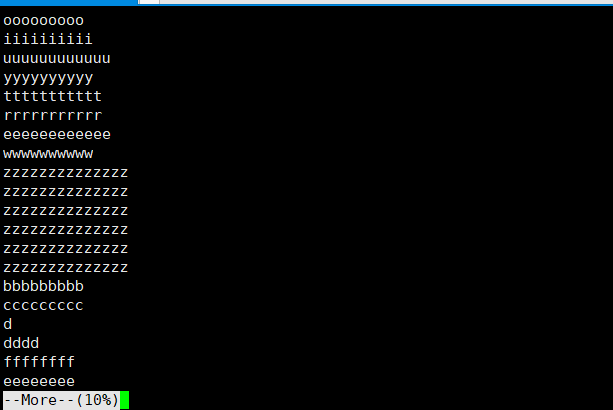
终端里一共显示了 20 行。默认按下空格键是其内容后继续显示20行,如果我们想要每次按下空格键在另一个页面20行,我们只需加上 -c 选项。

+/pattern 从文件中查找第一个出现字符串的行,并从该处前两行开始显示输出。
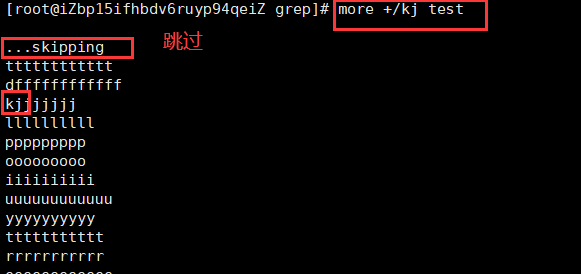
也可以在该模式下
 。按/pattern,可以在文本中寻找下一个相匹配的模式(pattern)。再按n匹配下一个模式。 不支持向上查找
。按/pattern,可以在文本中寻找下一个相匹配的模式(pattern)。再按n匹配下一个模式。 不支持向上查找
less 命令详解
- 空格键:查看下一屏; b键:查看上一屏 d键: 向后翻半页 u键: 向前翻半页
- 回车键:往下滚动一行; 上下键:向上下滚动一行
- /字符串:向下搜索"字符串" ?字符串:向上搜索"字符串"
- n键:匹配下一个关键字; N键:匹配上一个关键字
- q 键:退出。
相比较比more 命令,
less可以在整个文件中任意阅读(支持向上滚动一行)。- 支持向上查询(N)(?)
- less退出后shell不会留下刚显示的内容,而more退出后会在shell上留下刚显示的内容
- 会高亮显示
注意:如果您使用less查看一个小文件,您将在顶部看到空的空白行。不要慌。文件中没有多余的行。只是less命令命令的显示方式而已。
"less -e" 当文件显示结束后,自动离开,无需输入"q"
“less -f” 强迫打开特殊文件,例如外围设备代号、目录和二进制文件
"less -m" 显示类似more命令的百分比
“less -N” 显示每行的行号
“less -s” 将连续的空行合并成一行显示
“less -S” 行信息过长时,将超出部分舍弃
如果需要向下搜索,输入(
/字符串):按n键:跳转到下一个匹配的字符串,按N键:跳转到上一个匹配的字符串/linux如果需要向上搜索,输入(
?字符串):按n键:跳转到下一个匹配的字符串,按N键:跳转到上一个匹配的字符串?linux直接定位到某个位置!
#直接定位到第100行 less + 100g xx . log # 定位到最后一行 less + GG xx . log只需要按
v键,就会将正在阅读的文件在默认编辑器中打开,然后就可以对文件进行各种编辑操作了。
WC命令详解
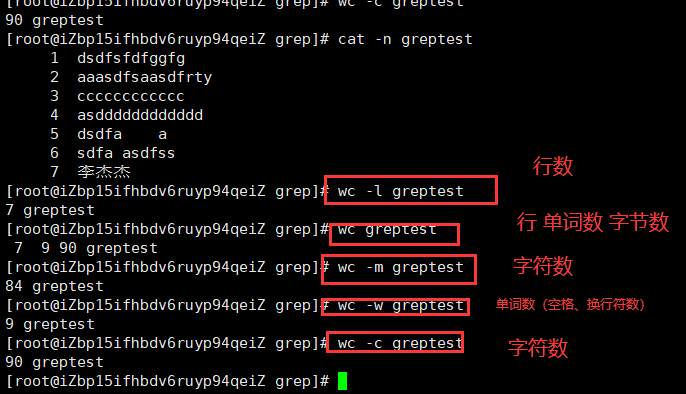
wc(Word Count):统计指定文件中的字节数、字数、行数,并将统计结果显示输出
-c统计字节数。-l统计行数。-m统计字符数。这个标志不能与 -c 标志一起使用。-w统计字数。一个字被定义为由空白、跳格或换行字符分隔的字符串。
sort命令详解
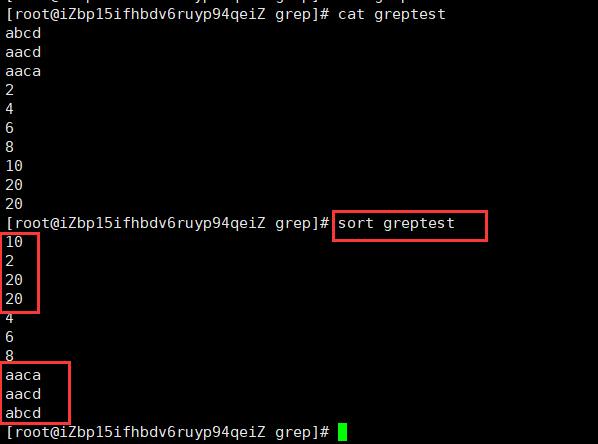
sort将文件的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较(相同则比较下一个字符),最后将他们按升序输出。
这里可以看到10在2的前面,这是因为比较的是1<2,而不是比较10>2
-n表示按数字进行排序,默认是按ASCII码排序。可以看到不再是一个一个字符的比较了,而是把它当成一个整体来比较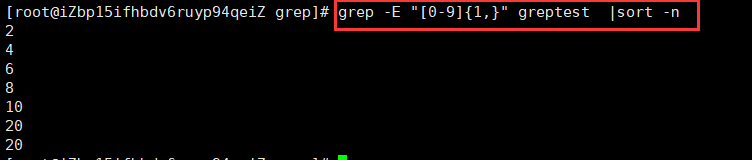
-u输出行中去除重复行。可以看到两个20只留下了一个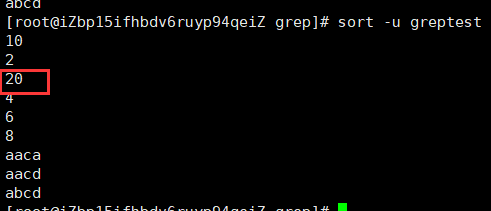
-r表示降序,默认是升序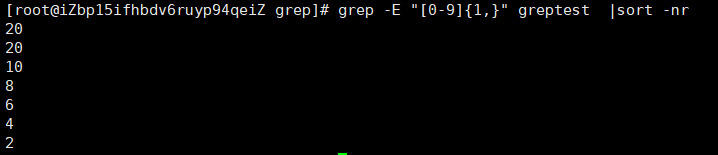
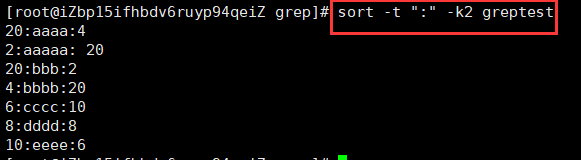
-t使用符合将一行分为几个小块,-k使用第几个小块进行比较,默认是第一个小块。-t和-k一般都是搭配使用的。-k2,表示第二块,-k3,表示第三块,以此类推 -kn,表示第n块使用第二块字母排序
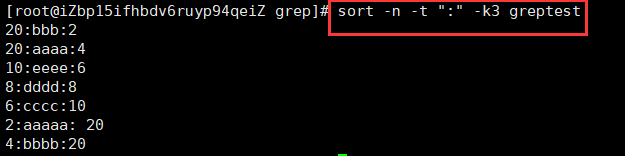
使用第三块数字排序
其他的sort常用选项
-f会将小写字母都转换为大写字母来进行比较,亦即忽略大小写-c会检查文件是否已排好序,如果乱序,则输出第一个乱序的行的相关信息,最后返回1-C会检查文件是否已排好序,如果乱序,不输出内容,仅返回1-M会以月份来排序,比如JAN小于FEB等等-b会忽略每一行前面的所有空白部分,从第一个可见字符开始比较。