ARIMA时序序列分析-股价预测
时间序列分析是按照时间顺序的一组数字序列。时间序列分析就是利用这组数列,应用数理统计方法加以处理,以预测未来事物的发展。时间序列分析是定量预测方法之一。
基本原理:
- 拿到一个观测值序列之后,首先判断它的平稳性,通过平稳性检验,判断序列是平稳序列还是非平稳序列。
- 若为非平稳序列,则利用差分变换成平稳序列。
- 对平稳序列,计算相关系数和偏相关系数,确定模型。
- 估计模型参数,并检验其显著性及模型本身的合理性。
- 检验模型拟合的准确性。
- 根据过去行为对将来的发展做出预测。
实验内容:
数据选择
原始序列
可视化展示
fig1 = plt.figure(figsize=(12,8))
x_major_locator=MultipleLocator(120)
plt.plot(date,data)
plt.title("时序图") #添加图标题
plt.xticks(rotation=45) #横坐标旋转45度
plt.xlabel('日期') #添加图的标签(x轴,y轴)
plt.ylabel("收盘价")
ax=plt.gca()
ax.xaxis.set_major_locator(x_major_locator) # 设置X轴显示间隔
plt.savefig('收盘价变化图.jpg')

从上图来看,时序序列波动明显,观测不具备平稳性;
单位根检验
from statsmodels.tsa.stattools import adfuller
ori_adf = adfuller(data) # 单位根检验
adf_out = pd.Series(ori_adf[0:4],index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])
values = []
for i in ori_adf[0:4]:
values.append(i)
for key,value in ori_adf[4].items():
adf_out['Critical Value (%s)' % key] = value
values.append(value)
print(adf_out)
对原始序列进行单位根检验,得出如下结果: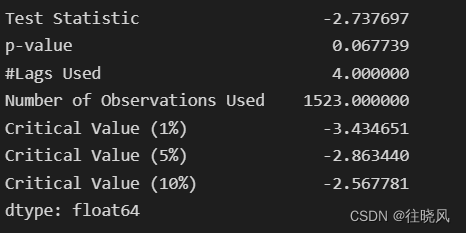
1)T统计量 2)P值,表示t统计量对应的概率值 3)延迟 4)测试次数 5,6,7) 99%,95%,90%置信区间下的临界的ADF检验的值
平稳性验证
- 1)要与5,6,7)的结果比较,如果T统计量小于5,6,7的值,则证明序列平稳(ADF检验的原假设是存在单位根,只要这个统计值是小于1%水平下的数字就可以极显著的拒绝原假设,认为数据平稳。注意,ADF值一般是负的,也有正的,但是它只有小于1%水平下的才能认为是及其显著的拒绝原假设)
- p值要求小于给定的显著水平,p值要小于0.05,等于0是最好的。
从以上两个要求来看均不满足要求,因此序列为不平稳序列;
差分序列
平稳性检验

对差分序列进行平稳性检验: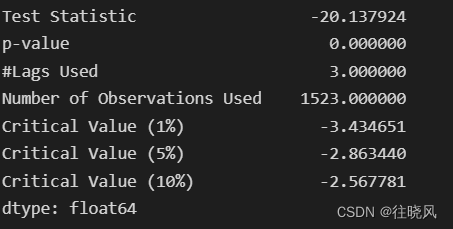
如图所示,差分序列P值与T统计量均满足平稳性要求;
相关性检验
对差分序列进行自相关及偏自相关检验:
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf #自相关图、偏自相关图
def acf_pacf_plot(timeseries,lags,name):
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(12, 4), dpi=100)
plot_acf(timeseries, lags=lags,ax=axes[0])
axes[0].set_title('acf') #设置自相关图标题,也可不设置,采用默认值Autocorrelation
plot_pacf(timeseries,lags=lags,ax=axes[1])
axes[1].set_title('pacf') #设置偏自相关图标题,也可不设置,采用默认值Partial Autocorrelation
plt.savefig("自相关和偏自相关图{}.jpg".format(name))
plt.show()
acf_pacf_plot(data,lags=200,name=1)

由自相关图可知,一阶自相关系数很明显地大于 2 倍标准差范围,自一阶自相关系数后,其余自相关系数都在 2 倍标准差范围以内,我们可以判断自相关图为截尾。
由偏自相关图可知,一阶偏自相关系数很明显地大于 2 倍标准差范围,自一阶偏自相关系数后,其余自相关系数都在 2 倍标准差范围以内,我们可以判断偏自相关图为截尾。
BIC模型定价
由于通过自相关分析和偏自相关分析来判断 ARIMA 的参数存在人为主观性,因此需要通过AIC和BIC准则进行模型定价。
AIC准则全称为全称是最小化信息量准则(Akaike Information Criterion):
AIC = =2 *(模型参数的个数)-2ln(模型的极大似然函数)
AIC准则存在一定的不足之处。当样本容量很大时,在AIC准则中拟合误差提供的信息就要受到样本容量的放大,而参数个数的惩罚因子却和样本容量没关系(一直是2),因此当样本容量很大时,使用AIC准则选择的模型不收敛与真实模型,它通常比真实模型所含的未知参数个数要多。BIC(Bayesian InformationCriterion)贝叶斯信息准则弥补了AIC的不足:
BIC = ln(n) * (模型中参数的个数) - 2ln(模型的极大似然函数值),n是样本容量
import seaborn as sns
from statsmodels.tsa.arima_model import ARIMA
##2参数调优:BIC
pmax=5 # 指定最大阶数
qmax=5 # 指定最大阶数
bic_matrix=[]
for p in range(pmax):
tmp=[]
for q in range(qmax):
try:
tmp.append(ARIMA(resid,order=(p,1,q)).fit().bic)
print("times", "p", p, "q", q)
except:
tmp.append(None)
bic_matrix.append(tmp)
bic_matrix=pd.DataFrame(bic_matrix)
print(bic_matrix)
fig,ax=plt.subplots(figsize=(10,8))
ax=sns.heatmap(bic_matrix,
mask=bic_matrix.isnull(),
ax=ax,
annot=True,
fmt='.2f')
ax.set_title('Bic')
bic_matrix.stack()
p,q=bic_matrix.stack().idxmin() #最小值的索引
print('用BIC方法得到最优的p值是%d,q值是%d'%(p,q))
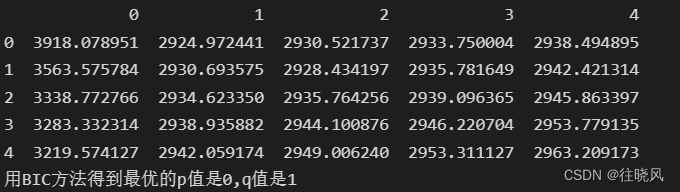
由于经过了一阶差分,因此d=1,p=0,q=1,构建ARIMA(0,1,1)模型;
残差检验
predictions_ARIMA_diff = pd.Series(arima111.fittedvalues, copy=True)
predictions = [i + j for i, j in zip(list(predictions_ARIMA_diff), list(data))]
fig3 = plt.figure(figsize=(12,8))
plt.plot(predictions,label='预测结果')
plt.plot(data.values,label='真实值')
plt.plot(arima111.resid,label='残差')
plt.legend()
plt.xlabel('日期')
plt.ylabel('收盘价')
plt.savefig('残差检验图.jpg')
plt.show()

如图所示,预测结果与真实结果较为拟合。
白噪声检验
from statsmodels.stats.diagnostic import acorr_ljungbox
ljungbox_result = acorr_ljungbox(arima111.resid, lags=3)
print(ljungbox_result)

经过白噪声检验后,p值明显>0.05,接收原假设,说明原始序列独立,纯随机
未来5天收盘价预测
# 输出未来五天的预测结果, 返回预测结果, 标准误差, 和置信区间
forecast, stderr, conf = arima111.forecast(5)
