因为我已经有基础了,所以直接从DataStream直接开始学习,但是还是从简单到难,一步步来吧,加油!
1,我们从github下载源码,在本地idea的展示为:

2,我们全局ctrl+alt+R 搜索关键字 DataStream,如下图的结构展示:

3,选中DataStream,然后ctrl+H 查看这个类的子类,我们发现

4,通过idea的 UML显示图显示这个类DataStream的UML图:

5,与DataStream同级的Stream有:
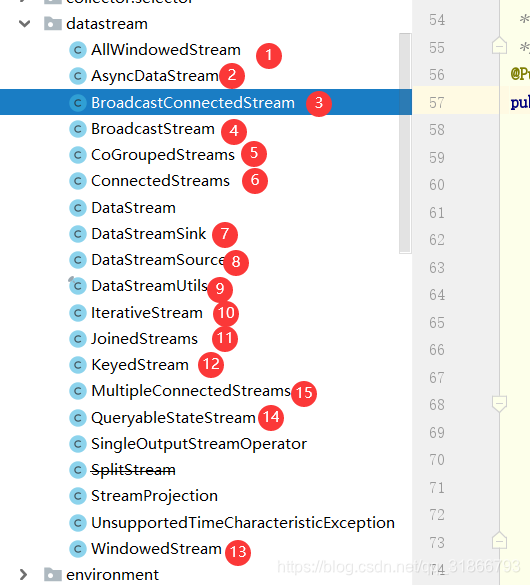
这里不可能每个都分析,拿几个简单的分析一下:
1)
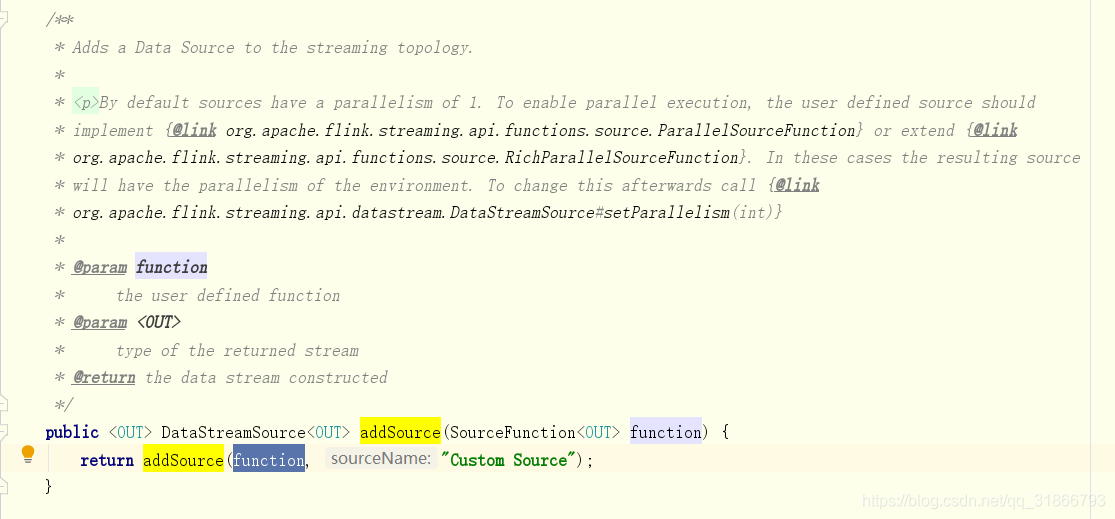
DataStreamSource 是 dataStream的起点:
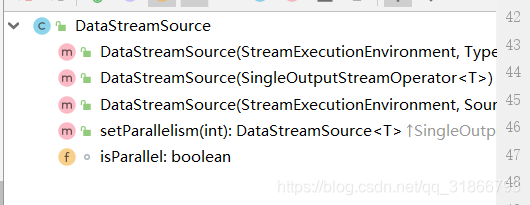
DataStreamSource 是由
StreamExecutionEnvironment.addSource(SourceFunction)创建
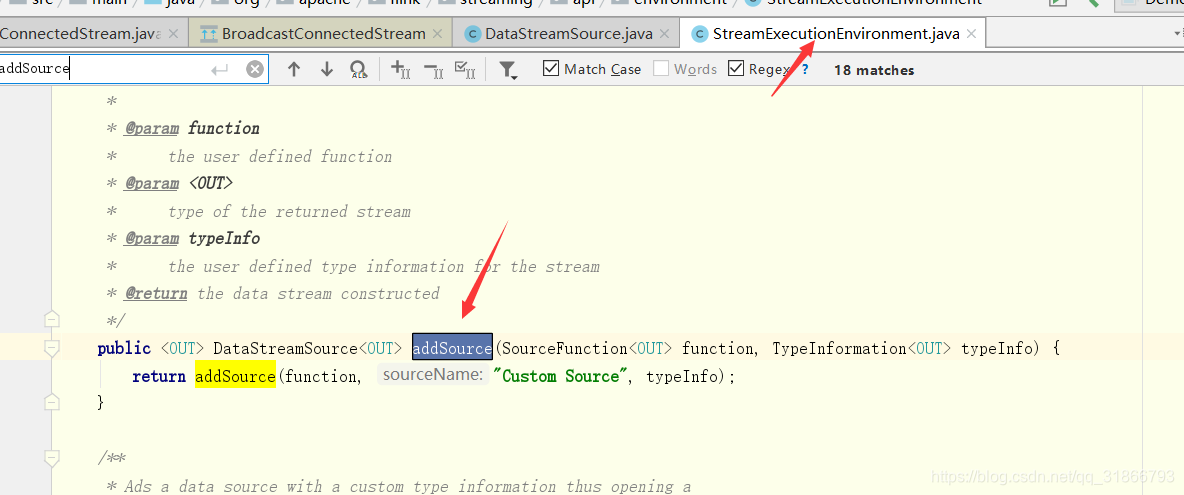
2)DataStreamSink
DataStreamSink是由DataStream.addSink(function)创建:
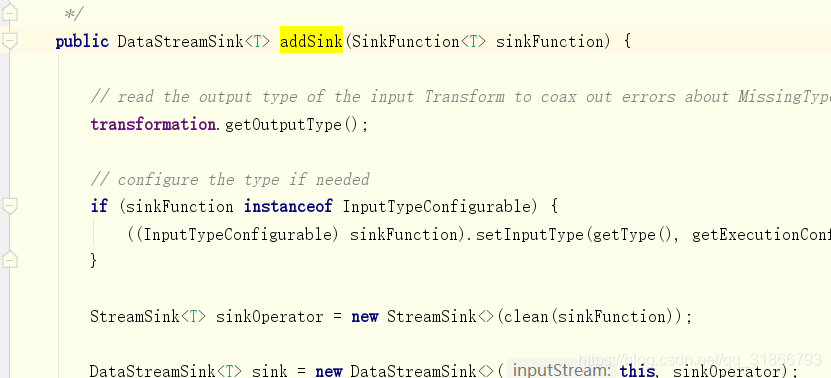
所以很清晰的链路就出来了
StreamExecutionEnvironment 创建了DataStreamSource
DataStreamSource 转成 DataStream。
DataStream 输出 为 DataStreamSink。
思想就是,数据源--->处理----> 输出
所以流处理流程就是明白三点思想,大同小异: 数据源是什么source,怎么处理(中间环节),输出源是什么sink。
3)剩余的stream都得自己去看看官网的使用方式,开发肯定会用到的,不懂的可以一个个百度
ConnectedStreams
AsyncDataStream 异步流(比如redis)
JoinedStreams
KeyedStream
WindowedStream
6,下面要讲一讲StreamExecutionEnvironment
1)从内存读取数据

案例:
传入是一个数组类型,后面是转出list,所以可以读取数组跟list数据转出DataStream

2)从文件读取数据
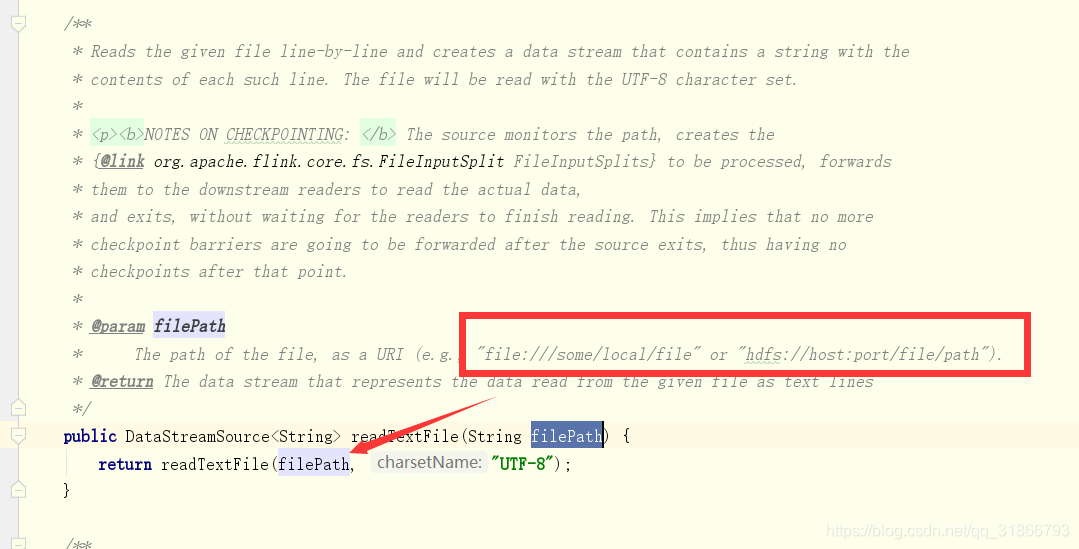
读取本地文件或者hdfs文件:
3)socket接入数据,这个是新手肯定会接触的。


4)自定义读取
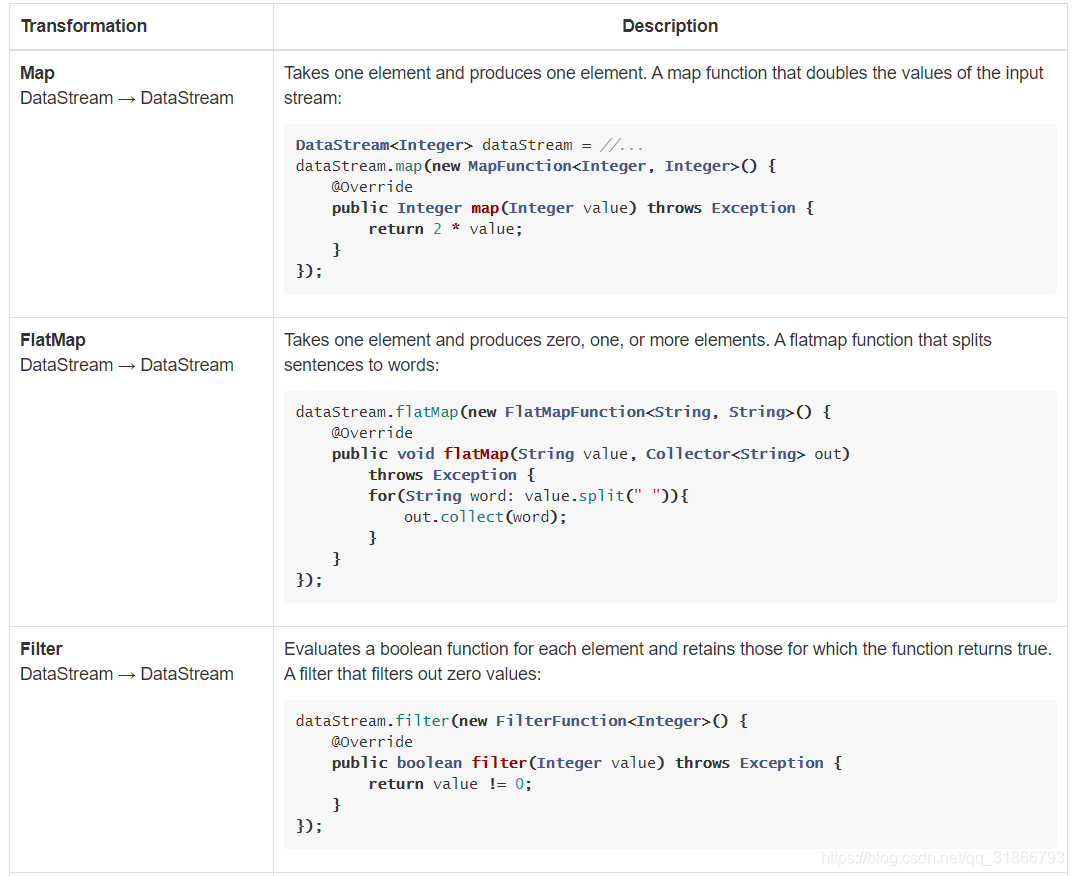
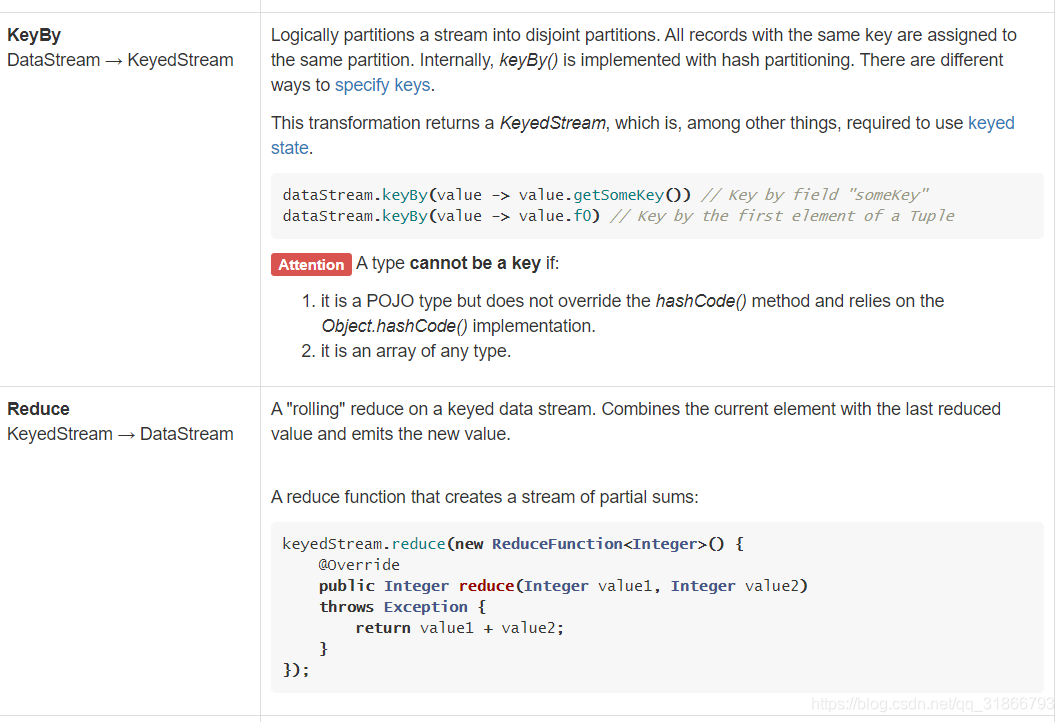
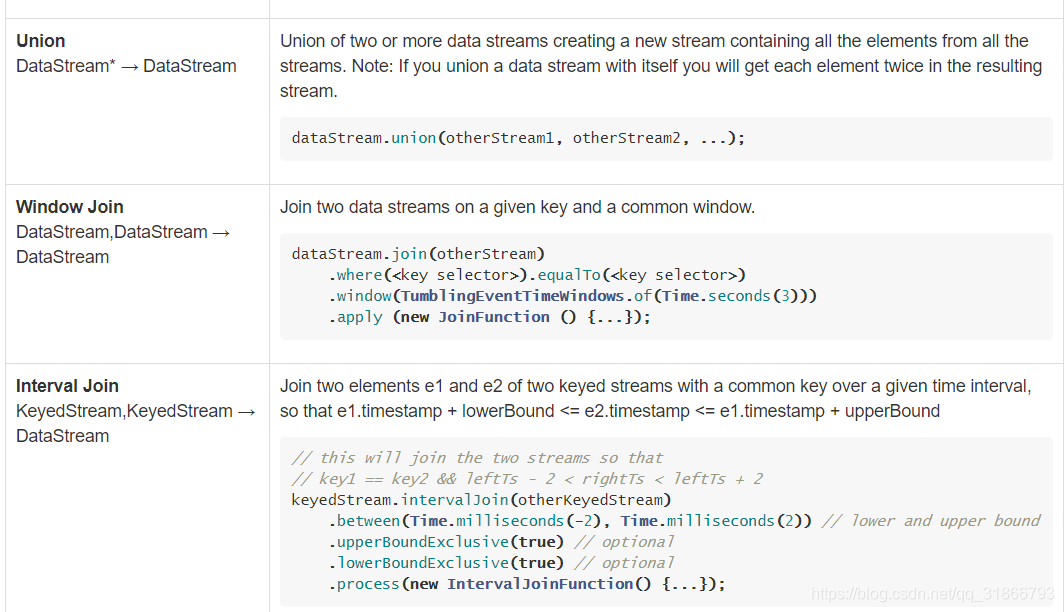
7,算子转换处理
参考官网地址:
https://ci.apache.org/projects/flink/flink-docs-release-1.11/zh/dev/stream/operators/
我只截取了部分的算子,实际已经看到API很清晰。
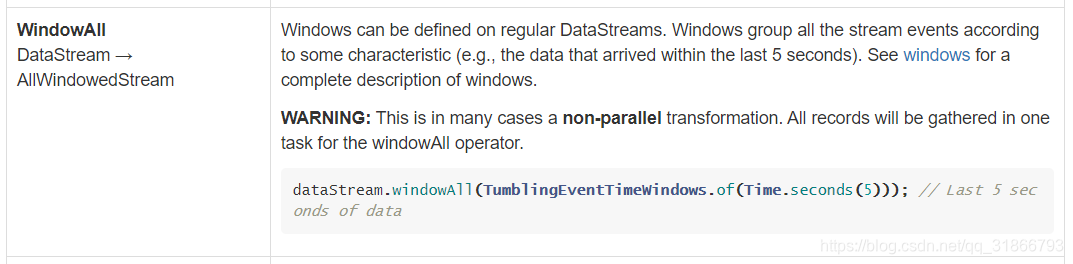
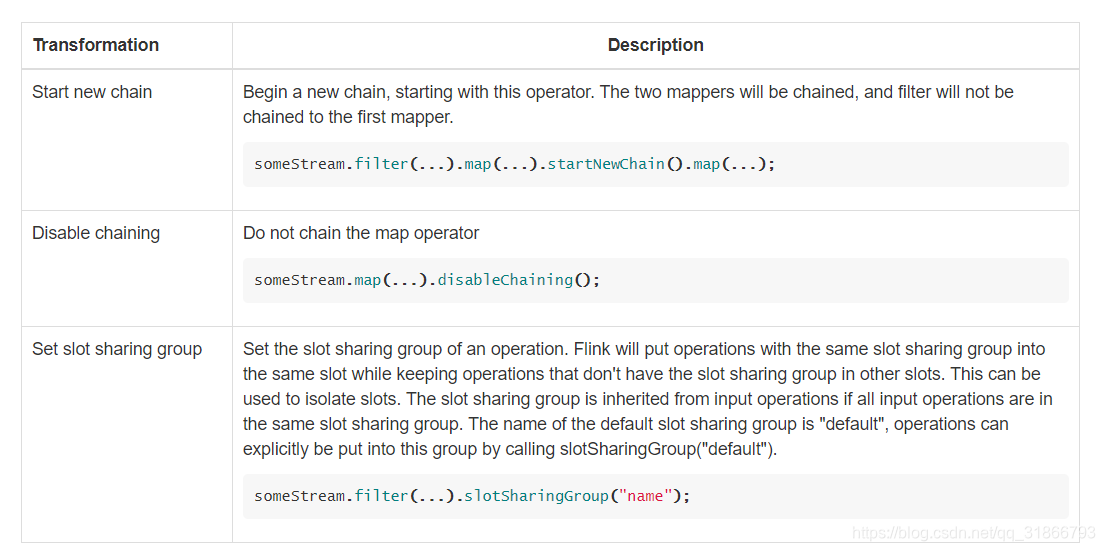
后面要注意,这个对打撒拆分算子在在slots上的分布有关系。
Task chaining and resource groups
任务链与资源分组