- 深度学习基础知识
- Numpy实现神经网络构建和梯度下降算法
- 计算机视觉领域主要方向的原理、实践
- 自然语言处理领域主要方向的原理、实践
- 个性化推荐算法的原理、实践
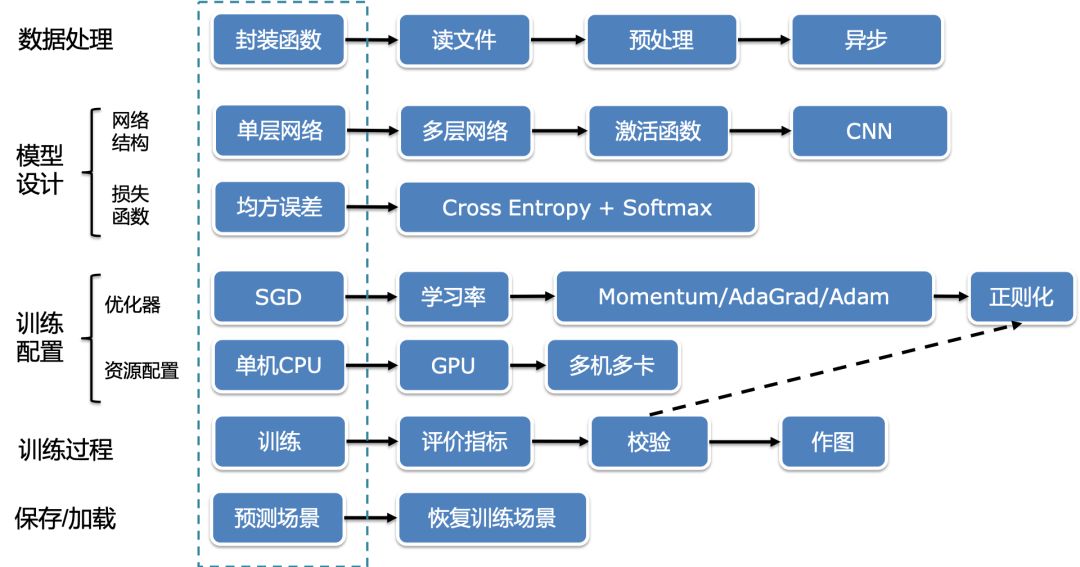
- 数据处理和异步数据读取
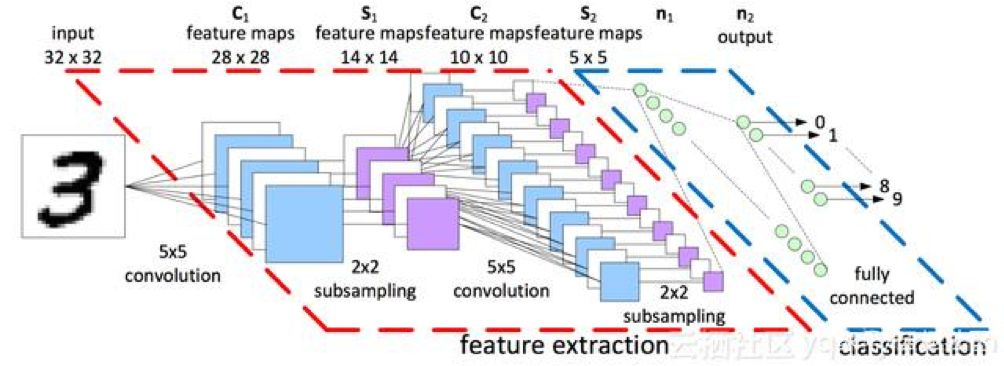
- 网络结构设计及背后思想
- 损失函数介绍及使用方式
- 模型优化算法介绍和选择
- 分布式训练方法及实践
- 模型训练调试与优化
- 训练中断后恢复训练
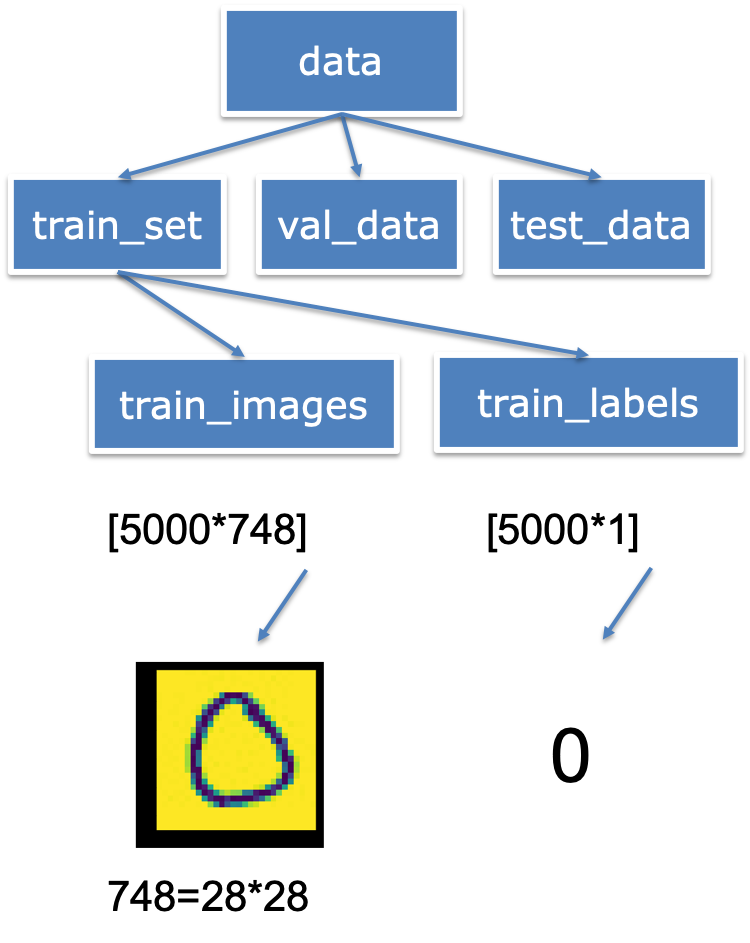
- 从文件中读取到数据;
- 划分数据集为训练集,验证集;
- 构建数据读取器(data_loader)
- 回归任务的损失函数难以在分类任务上取得较好精度。
- loss值较大,训练过程中loss波动明显。
- 物理含义不合理:实数输出和标签相减
- 分类任务本质规律是“在某种特征组合下的分类概率”
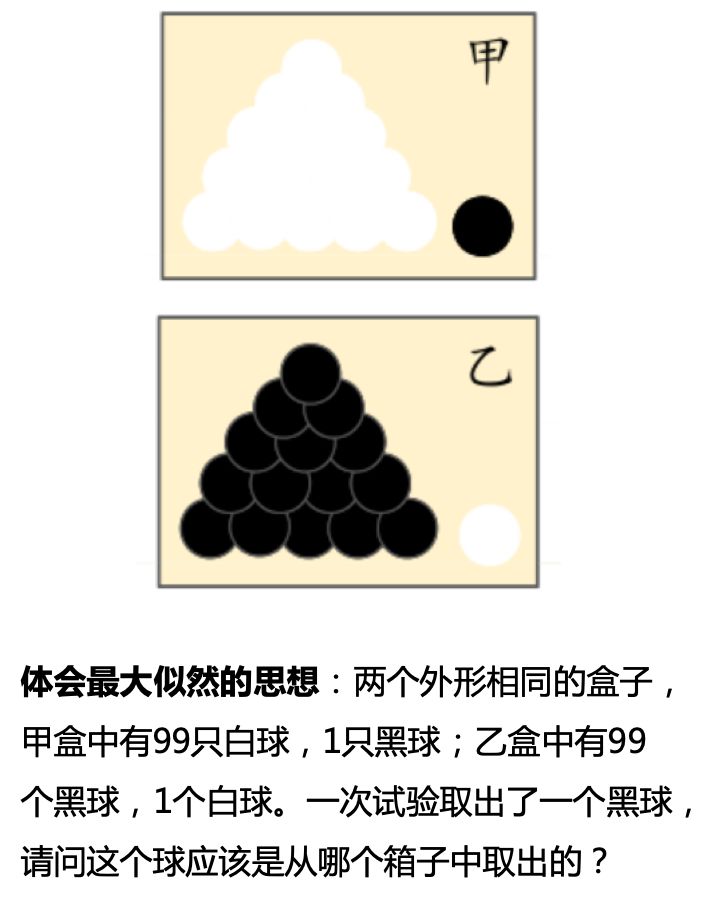
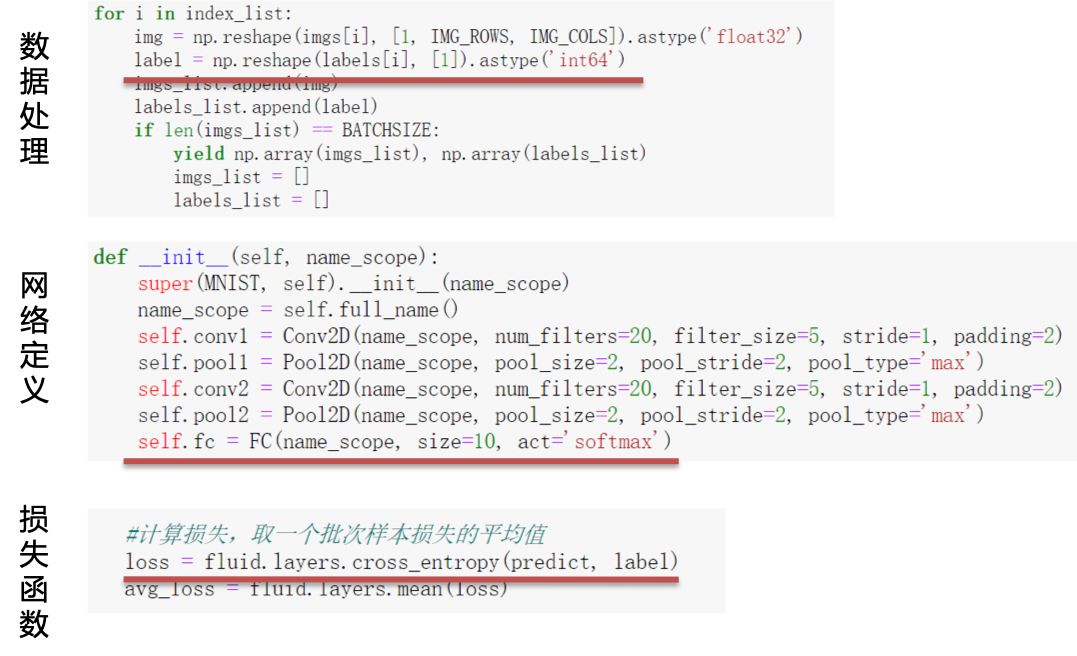
学习率的选择
在深度学习神经网络模型中,学习率代表参数更新幅度的大小。当学习率最优时,模型的有效容量最大。学习率设置和当前深度学习任务有关,合适的学习率往往需要调参经验和大量的实验,总结来说,学习率选取需要注意以下两点:- 学习率不是越小越好。学习率越小,损失函数的变化速度越慢,意味着我们需要花费更长的时间进行收敛。
- 学习率不是越大越好。因为只根据总样本集中的一个批次计算梯度,抽样误差会导致计算出的梯度不是全局最优的方向,且存在波动。同时,在接近最优解时,过大的学习率会导致参数在最优解附近震荡,导致损失难以收敛。
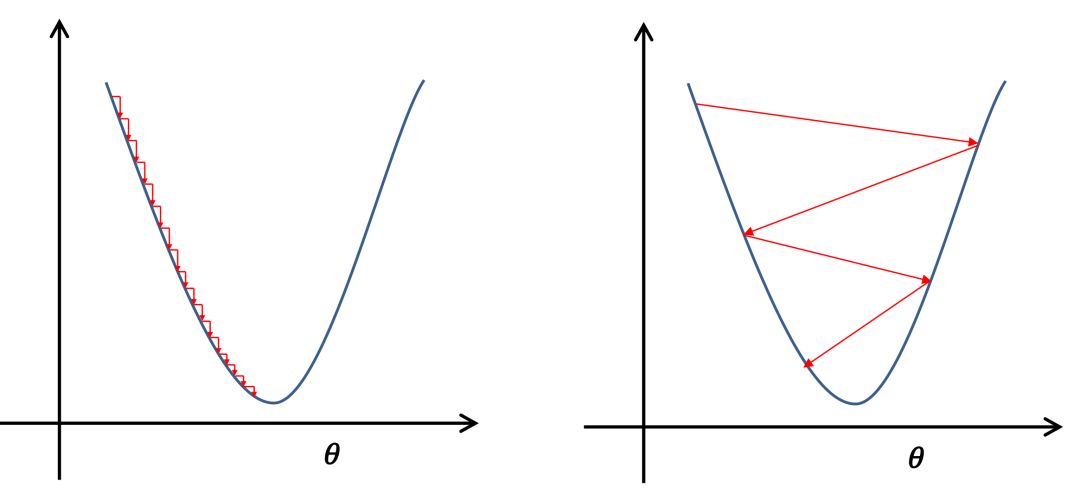
优化器的选择
学习率是优化器的一个参数,虽然参数更新都是采用梯度下降算法,但是不同的梯度下降算法影响着神经网络的收敛效果。当随机梯度下降算法SGD无法满足我们的需求时,可以尝试如下三个思路选取优化器:1、加入“动量”,参数更新的方向更稳定,比如Momentum优化器。每个批次的数据含有抽样误差,导致梯度更新的方向波动较大。如果我们引入物理动量的概念,给梯度下降的过程加入一定的“惯性”累积,就可以减少更新路径上的震荡!即每次更新的梯度由“历史多次梯度的累积方向”和“当次梯度”加权相加得到。
历史多次梯度的累积方向往往是从全局视角更正确的方向,这与“惯性”的物理概念很像,也是为何其起名为“Momentum”的原因。类似不同品牌和材质的篮球有一定的重量差别,街头篮球队中的投手(擅长中远距离投篮)喜欢稍重篮球的比例较高。一个很重要的原因是,重的篮球惯性大,更不容易受到手势的小幅变形或风吹的影响。
2、根据不同参数距离最优解的远近,动态调整学习率,比如AdaGrad优化器。通过调整学习率的实验可以发现:当某个参数的现值距离最优解较远时(表现为梯度的绝对值较大),我们期望参数更新的步长大一些,以便更快收敛到最优解。当某个参数的现值距离最优解较近时(表现为梯度的绝对值较小),我们期望参数的更新步长小一些,以便更精细的逼近最优解。
类似于打高尔夫球,专业运动员第一杆开球时,通常会大力打一个远球,让球尽量落在洞口附近。当第二杆面对离洞口较近的球时,他会更轻柔而细致的推杆,避免将球打飞。
与此类似,参数更新的步长应该随着优化过程逐渐减少,减少的程度与当前梯度的大小有关。根据这个思想编写的优化算法称为“AdaGrad”,Ada是Adaptive的缩写,表示“适应环境而变化”的意思。
3、因为上述两个优化思路是正交的,所以可以将两个思路结合起来,这就是当前广泛应用的Adam算法。 第五节:模型训练及分布式训练 此 前或多或少介绍了如何训练神经网络,但没有涉及分布式训练的内容,这里介绍一下分布式训练的思想,尤其是数据并行的思想,并介绍如何增加三行代码使用飞桨实现多GPU训练。 分布式训练有两种实现模式:模型并行和数据并行。模型并行
模型并行是将一个网络模型拆分为多份,拆分后的模型分到多个设备上(GPU)训练,每个设备的训练数据是相同的。模型并行的方式一般适用于:- 模型架构过大,完整的模型无法放入单个GPU。2012年ImageNet大赛的冠军模型AlexNet是模型并行的典型案例。由于当时GPU内存较小,单个GPU不足以承担AlexNet。研究者将AlexNet拆分为两部分放到两个GPU上并行训练。
- 网络模型的设计结构可以并行化时,采用模型并行的方式。例如在计算机视觉目标检测任务中,一些模型(YOLO9000)的边界框回归和类别预测是独立的,可以将独立的部分分在不同的设备节点上完成分布式训练。
数据并行
数据并行与模型并行不同,数据并行每次读取多份数据,读取到的数据输入给多个设备(GPU)上的模型,每个设备上的模型是完全相同的。数据并行的方式与众人拾柴火焰高的道理类似,如果把训练数据比喻为砖头,把一个设备(GPU)比喻为一个人,那单GPU训练就是一个人在搬砖,多GPU训练就是多个人同时搬砖,每次搬砖的数量倍数增加,效率呈倍数提升。 但是注意到,每个设备的模型是完全相同的,但是输入数据不同,每个设备的模型计算出的梯度是不同的,如果每个设备的梯度更新当前设备的模型就会导致下次训练时,每个模型的参数都不同了,所以我们还需要一个梯度同步机制,保证每个设备的梯度是完全相同的。 数据并行中有一个参数管理服务器(parameter server)收集来自每个设备的梯度更新信息,并计算出一个全局的梯度更新。当参数管理服务器收到来自训练设备的梯度更新请求时,统一更新模型的梯度。 用户只需要对程序进行简单修改,即可实现在多GPU上并行训练。飞桨采用数据并行的实现方式,在训练前,需要配置如下参数:- 1.从环境变量获取设备的ID,并指定给CUDAPlace
device_id = fluid.dygraph.parallel.Env().dev_id place = fluid.CUDAPlace(device_id)- 2.对定义的网络做预处理,设置为并行模式
strategy = fluid.dygraph.parallel.prepare_context() ## 新增 model = MNIST("mnist") model = fluid.dygraph.parallel.DataParallel(model, strategy) ## 新增- 3.定义多GPU训练的reader,将每批次的数据平分到每个GPU上
valid_loader = paddle.batch(paddle.dataset.mnist.test(), batch_size=16, drop_last=true) valid_loader = fluid.contrib.reader.distributed_batch_reader(valid_loader)- 4.收集每批次训练数据的loss,并聚合参数的梯度
avg_loss = mnist.scale_loss(avg_loss) ## 新增 avg_loss.backward() mnist.apply_collective_grads() ## 新增- 计算分类准确率,观测模型训练效果。交叉熵损失函数只能作为优化目标,无法直接准确衡量模型的训练效果。准确率可以直接衡量训练效果,但由于其离散性质,不适合做为损失函数优化神经网络。
- 检查模型训练过程,识别潜在问题。如果模型的损失或者评估指标表现异常,我们通常需要打印模型每一层的输入和输出来定位问题,分析每一层的内容来获取错误的原因。
- 加入校验或测试,更好评价模型效果。理想的模型训练结果是在训练集和验证集上均有较高的准确率,如果训练集上的准确率高于验证集,说明网络训练程度不够;如果验证集的准确率高于训练集,可能是发生了过拟合现象。通过在优化目标中加入正则化项的办法,可以解决过拟合的问题。
- 加入正则化项,避免模型过拟合。
- 可视化分析。用户不仅可以通过打印或使用matplotlib库作图,飞桨还集成了更专业的第三方绘图库tb-paddle,提供便捷的可视化分析。
# 保存模型参数和优化器的参数 fluid.save_dygraph(model.state_dict(), './checkpoint/mnist_epoch{}'.format(epoch_id)) fluid.save_dygraph(optimizer.state_dict(), './checkpoint/mnist_epoch{}'.format(epoch_id)) # 加载模型参数到模型中 params_dict, opt_dict = fluid.load_dygraph(params_path) model = MNIST("mnist") model.load_dict(params_dict) # 使用Adam优化器,并加载保存的Adam优化器相关参数 optimizer = fluid.optimizer.AdamOptimizer(learning_rate=lr) optimizer.set_dict(opt_dict)JVM生态报告:Spring、Maven与IDEA主导市场
谷歌申请新OS商标“Pigweed”,与Fuchsia相关
Container Linux将退役,让位Fedora CoreOS
Linus亲手优化内核管道代码,make性能大幅提升
又一个“千年虫”问题!Linux Kernel 5.6已着手应对