一.安装BeautifulSoup
1.需要将pip源设置为国内源
阿里源,豆瓣源,网易源等
1.1 windows:
(1) 打开文件资源管理器(windows10需要管理者权限)
(2)地址栏输入%appdata%之后进入到一个文件夹内
(3)在这里面新建一个文件叫做 pip
(4)在pip文件夹里新建一个文件叫 pip.ini,内容如下
[global]
timeout = 6000
index-url = https://mirrors.aliyun.com/pypi/simple/
trusted-host = mirrors.aliyun.com
(6)可以在cmd中输入命令(不用切换路径,会自动安装到python中):pip install bs4也可以在python中导入beautifulsoup4库
(7)bs4在使用时需要安装一个第三方库lxml:pip install lxml
1.2 linux:
(1)cd ~
(2)mkdir ~/.pip
(3)vim ~/.pip/pip.conf
(4)编辑内容和windows一样
二.转化文件
导入命令:from bs4 import BeautifulSoup
使用方法:可以将一个html文档,转化为指定的对象,然后通过对象的方法或属性去查找指定的内容。
1.转化本地文件:
soup = BeautifulSoup(open('本地文件'), 'lxml') # 默认是‘r’只读模式
2.转化网络文件:
soup = BeautifulSoup('字符串类型或者字节类型', 'lxml')
3.测试
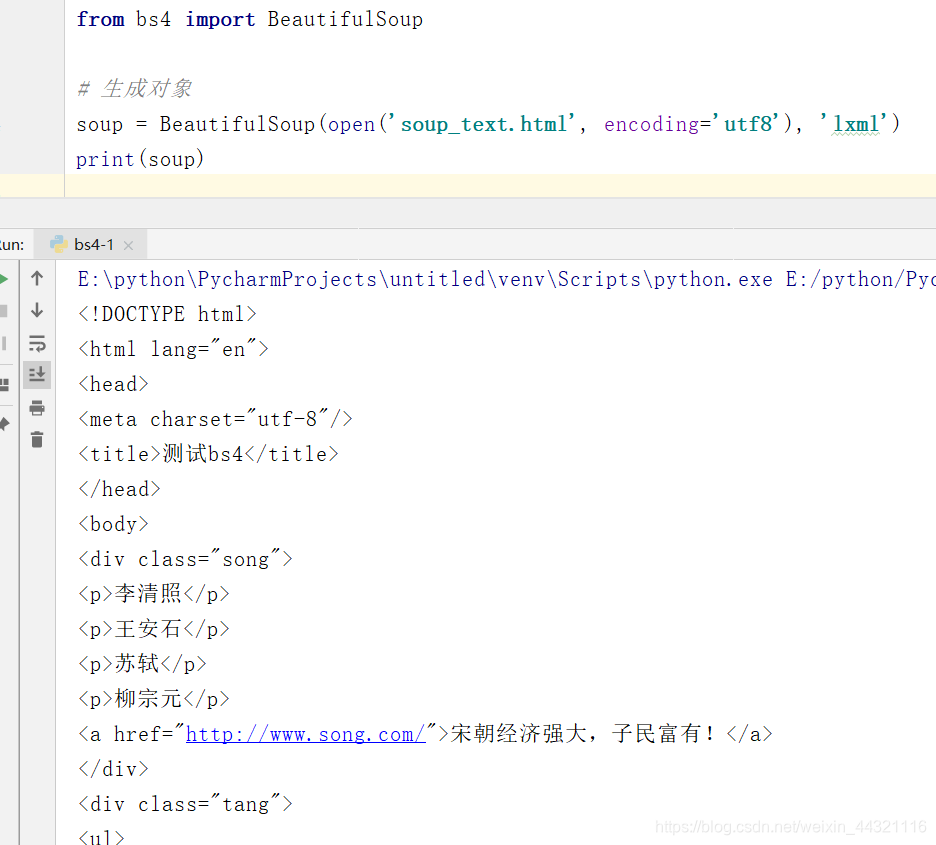
三.简单使用
1.根据标签查找
只能找到第一个标签
1.1案例一
html文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试bs4</title>
</head>
<body>
<div class="song">
<p>李清照</p>
<p>王安石</p>
<p>苏轼</p>
<p>柳宗元</p>
<a href="http://www.song.com/" target="_self">宋朝经济强大,子民富有!</a>
<img src="http://www.baidu.com/image1.jpg" alt="">
</div>
<div class="tang">
<ul>
<li><a href="http://www.baidu.com">
清明时节雨纷纷,路上行人欲断魂。
</a> </li>
<li><a href="http://www.163.com">
床前明月光,疑是地上霜。
</a> </li>
<li><a href="http://www.126.com">
清时明月汉时关,万里长征人未还。
</a> </li>
<li><a href="http://www.hao123.com">
正是江南好风景,落花时节又逢君。
</a> </li>
<li><a href="http://www.sina.com">
清明时节雨纷纷,路上行人欲断魂
</a> </li>
</ul>
</div>
</body>
</html>
python文件:
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
# print(soup)
print(soup.a) # 只能找到第一个a标签

1.2案例二
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
# print(soup)
print(soup.div) # 只能找到第一个div标签

2.获取属性
1.1案例一
方法一:
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.a["href"])

方法二:
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.a.attrs['href'])

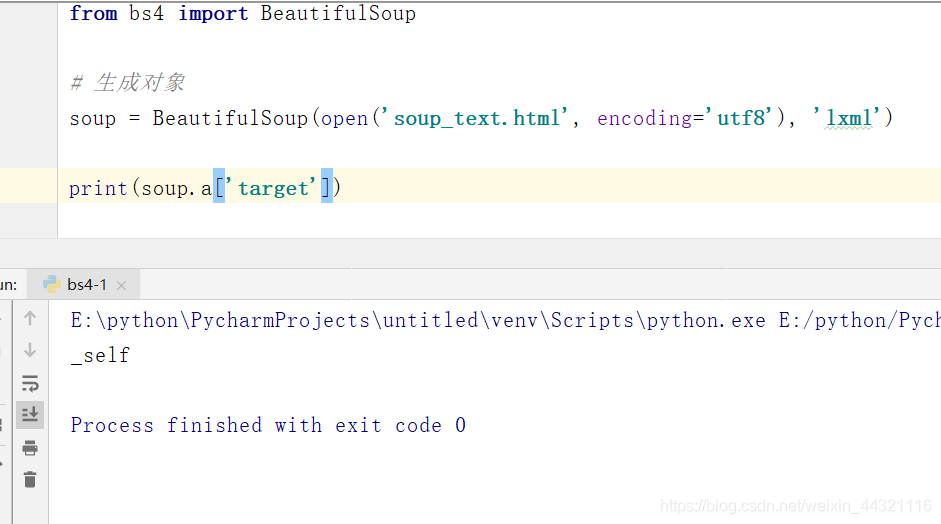
1.2案例二
方法一:
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.a["target"])
方法二:
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.a.attrs['target'])

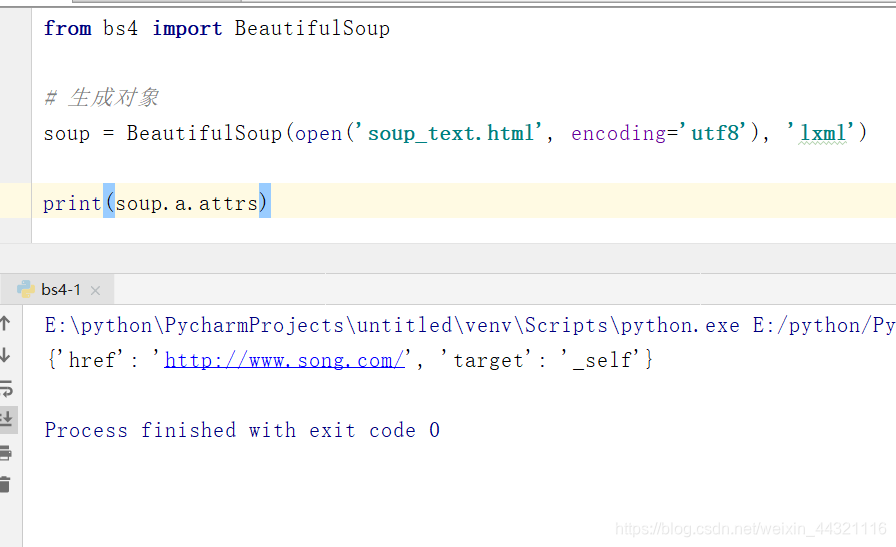
1.3案例三
获取第一个a标签里的所有属性
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.a.attrs)
3.获取内容
1.1案例一
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.a.text)

1.2案例二
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.a.string)

1.3案例三
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.a.get_text())

1.4案例四(如果标签里还包含其他标签,string则获取不到任何内容)
html文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试bs4</title>
</head>
<body>
<div>
大白兔奶糖
<p>徐福记酥糖</p>
<p>德芙巧克力</p>
金丝猴软糖
</div>
</body>
</html>
python文件:
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.div.text)
print(soup.div.string)
print(soup.div.get_text())

4.find(找到符合的第一个)
1.1案例一
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
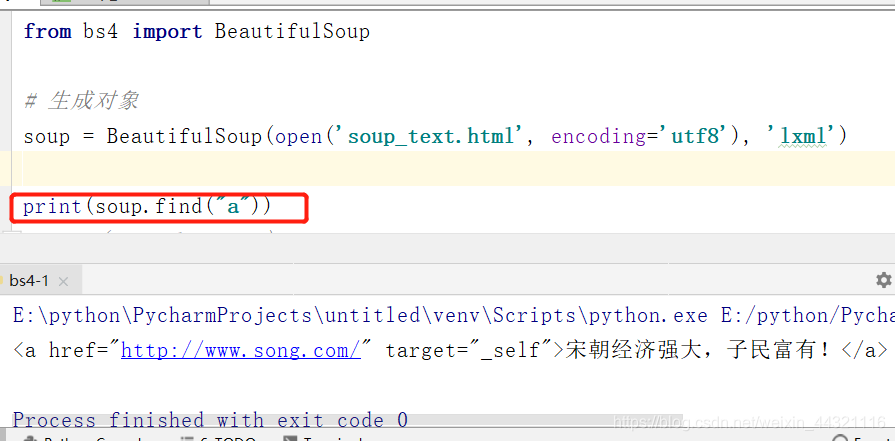
print(soup.find("a"))
1.2案例二
html文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试bs4</title>
</head>
<body>
<div class="tang">
<ul>
<li><a href="http://www.baidu.com" title="qing">
清明时节雨纷纷,路上行人欲断魂。
</a> </li>
<li><a href="http://www.163.com" title="qin">
床前明月光,疑是地上霜。
</a> </li>
<li><a href="http://www.126.com" alt="qi">
清时明月汉时关,万里长征人未还。
</a> </li>
<li><a href="http://www.hao123.com">
正是江南好风景,落花时节又逢君。
</a> </li>
<li><a href="http://www.sina.com">
清明时节雨纷纷,路上行人欲断魂
</a> </li>
</ul>
</div>
</body>
</html>
python文件:
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.find("a", title="qin"))

1.3注意事项(class的特殊查找)

要想使用必须要加‘_’:
html文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试bs4</title>
</head>
<body>
<div class="tang">
<ul>
<li><a href="http://www.baidu.com" title="qing">
清明时节雨纷纷,路上行人欲断魂。
</a> </li>
<li><a href="http://www.163.com" title="qin">
床前明月光,疑是地上霜。
</a> </li>
<li><a href="http://www.126.com" alt="qi">
清时明月汉时关,万里长征人未还。
</a> </li>
<li><a href="http://www.hao123.com" class="jun">
正是江南好风景,落花时节又逢君。
</a> </li>
<li><a href="http://www.sina.com" id="hun">
清明时节雨纷纷,路上行人欲断魂
</a> </li>
</ul>
</div>
</body>
</html>
python文件:
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.find("a",class_="jun"))

1.4案例三(都只能找到匹配的第一个内容)
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
div = soup.find("div", class_="song")
print(div.find('a', class_='jun'))

5.find_all
1.1案例一
python文件:
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.find_all('a'))

1.2案例二
python文件:
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
div = soup.find('div', class_='tang')
print(div.find_all('a'))

1.3案例三
html文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试bs4</title>
</head>
<div class="tang">
<ul>
<li><a href="http://www.baidu.com" title="qing">
清明时节雨纷纷,路上行人欲断魂。
</a> </li>
<li><a href="http://www.163.com" title="qin">
床前明月光,疑是地上霜。
</a> </li>
<li><a href="http://www.126.com" alt="qi">
清时明月汉时关,万里长征人未还。
</a> </li>
<li><a href="http://www.hao123.com" class="jun">
正是江南好风景,落花时节又逢君。
</a> </li>
</a> </li>
<li><a href="http://www.hao.com" class="jun">
杜甫
</a> </li></a> </li>
<li><a href="http://www.hao1.com" class="jun">
李白
</a> </li></a> </li>
<li><a href="http://www.hao12.com" class="jun">
杜牧
</a> </li>
<li><b>小红</b></li>
<li><i>小明</i></li>
<li><a href="http://www.sina.com" id="hun">
清明时节雨纷纷,路上行人欲断魂
</a> </li>
</ul>
</div>
</body>
</html>
python文件:
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
div = soup.find('div', class_='tang')
print(div.find_all(['a', 'b']))

1.4案例四
python文件:
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.find_all('a', limit=2))

6.select(根据选择器选取指定内容)
1.1常用的选择器
标签选择器(a),类选择器(.dudu),id选择器(#lala),组合选择器(a, .dudu, #lala, .meme),层级选择器(div.dudu#lala.meme.xixi 表示下面好多级和 div>p>a>.lala 只能是下面一级 ),伪类选择器(不常用),属性选择器 (input[name=‘lala’])
1.2案例一(层级选择器,返回的都是列表)
python文件:
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.select('.tang > ul > li > a'))

1.3案例二(层级选择器)
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.select('.tang > ul > li > a')[2])

1.4案例三(id选择器)
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.select('#hun'))

1.5案例四
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.select('#hun')[0].text)

1.6案例五
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
print(soup.select('#hun')[0]['href'])

1.7案例六(通过普通对象调用)
from bs4 import BeautifulSoup
# 生成对象
soup = BeautifulSoup(open('soup_text.html', encoding='utf8'), 'lxml')
div = soup.find('div',class_='tang')
print(div.select('.jun'))

版权声明:本文为weixin_44321116原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。