公众号【离心计划】,掌握一手文章,一起离开地球表面
【RPC系列合集】
前言
这是番外篇的第一篇关于网络IO的小节,本来想直接进入实战,但是为了大家理解还是写篇番外篇来介绍一下网络IO,再过渡到Netty。并提前说明一下番外篇是对我们主线RPC系列的补充,如果读者熟悉网络相关可直接跳过。
IO模型
我们经常听到什么“阻塞IO”、“非阻塞IO”、“异步IO”等等关键词,却常常心里没底,没法正面解释并形成完整的IO体系,其实这些在别人文章中经常出现的这些词就是IO模型中的几种。
网络编程逃离不了IO,IO即Input/Output,就是数据的输入输出,为什么数据的两个动作会产生这么多IO模型呢?可以想象数据的输入像是你在等待派送中的信件,你等待这个信件有什么基本方式呢
一直在邮局等
每隔一段时间去邮局看看有没有信件
出去玩,让工作人员收到你的信件后打电话通知你去邮局拿
出去玩,让工作人员收到你的信件后直接送到你家里
这些行为方式映射到操作系统处理IO数据,也就对应了不同的IO模型类型,总体上我们可以将这些IO模型从两种角度分:阻塞与非阻塞、同步与异步。
阻塞与非阻塞针对的是调用方,阻塞调用就像上面第一种,没拿到数据就线程阻塞并挂起,不占用CPU;非阻塞则像第二种方式,轮询去拿数据,没拿到就返回,下次继续,不阻塞线程。
同步与异步针对的是被调用方,同步调用就是上面的前三种,无论调用方怎么样,被调用方也就是这里的邮局或者工作人员都要给到你数据(有没有信件)才行。而异步调用被调用方不需要返回确切结果,可以理解为返回一个Future,后续可以通过这个Future拿到数据。
上面的分类方法是比较粗略的,事实上在Linux中,我们通常将IO模型分为:
阻塞IO,阻塞IO操作挂起线程,直到有数据才唤醒线程
非阻塞IO,轮询读取缓冲区是否有数据
IO复用模型,一个线程监听多个IO,哪个有数据来了,交给哪个对应的线程处理
信号驱动模型,通过信号量机制,IO线程无需阻塞,数据到达后通过发送信号给IO线程
异步IO,当数据到达后内核线程直接将数据复制到用户空间,IO线程无需主动复制。
我们以读取数据为例,整个数据的输入输出大致经过下面的链路:
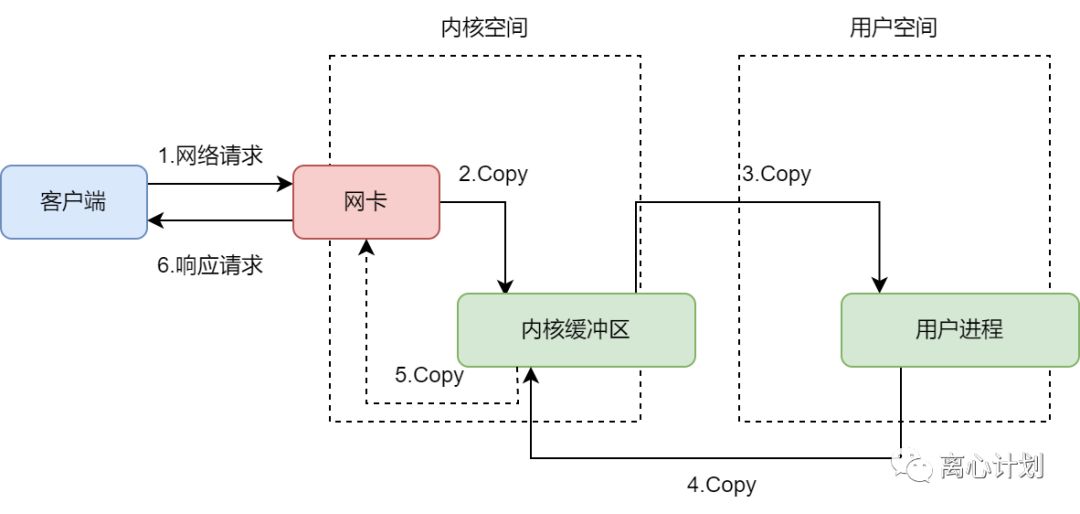
针对用户进程调用read读取网络IO数据的过程,映射到不同IO模型上时,就是这样:

我们发现,除了异步IO,“从内核缓冲区拷贝数据到用户空间”这个动作都是阻塞的,异步IO相当于把吃的放到你嘴巴边上了,都不用你自己来拿,这是基于操作系统的异步接口支持的,下面我们展开讲讲这几种模型。
阻塞IO与非阻塞IO
这两种上面已经讲过了,非阻塞IO解决的是阻塞IO线程挂起导致线程切换的成本,但是也增加了无效空转时间,占用了CPU资源
IO复用模型
IO复用其实解决的是多线程处理导致的经典“C10K”问题,它最大的优势是基于的Reactor线程模型,在IO模型角度看,其实仅仅是多个Socket的IO操作合并到了一个Socket上,并基于事件模型不断处理IO事件,拿上面那信件的比喻,就好像又一百个人要拿信件,如果一百个人都去不断往邮局跑,邮局人都满了,而如果只选出一个代表,每次去邮局看看有没有这一百个人的信件,有哪个人的信件都打电话找哪个人来拿就完事了。
信号驱动模型
信号驱动模型利用了信号量机制,用户线程注册一个对应的信号处理函数,当内核线程感知到数据到来后发送信号给用户线程,用户线程调用对应的处理函数进行数据拷贝并处理。但是信号量机制在TCP上无法应用,由于TCP的事件类型很多,包括连接来了、数据来了、close连接的请求等等,信号量无法准确反映是哪一种事件,所以无法应用;而UDP是无连接协议,所以对应的事件就是数据到来和异步错误,本质上还是因为TCP是面向连接的可靠传输协议,这个“可靠”一定是用了像流控、可靠三次握手与四次挥手等额外机制保证的,这也决定了事件的多样性。
异步IO模型
异步IO模型上面也看到了,最大区别在于内核线程帮助用户线程做掉了数据拷贝到用户空间的工作,这也是区别去同步的标志信号驱动的区别在于异步IO模型是通知用户线程IO完成,而信号驱动告诉线程数据准备好了,终究是少了拷贝这一步。
线程模型
线程模型指的是具体处理IO的线程要怎么搭配工作,这也是从操作系统处理IO事件的角度划分的,上面的IO模型分为同步和异步两大种,而线程模型也随着这两种IO模型的实现方式分为了Reactor模型和Proactor模型分别处理同步IO和异步IO。
那么在此之前我们从传统的单线程阻塞IO看看会有什么问题
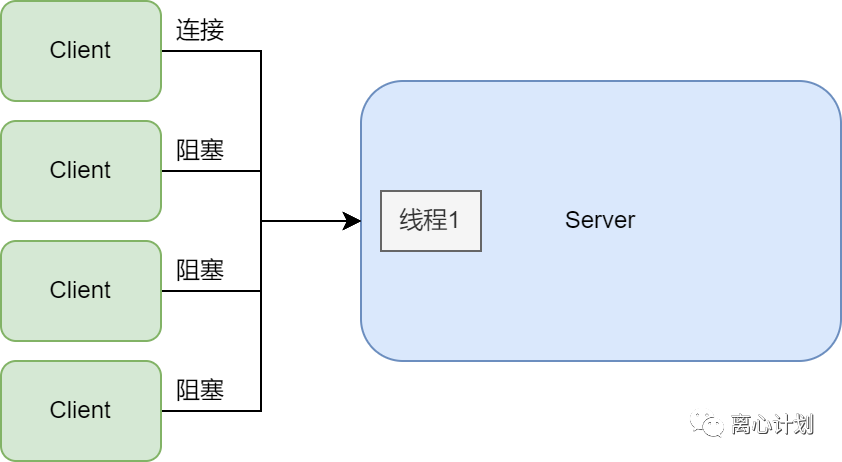
单线程阻塞模型就只有一个线程处理,那么只能有一个连接处理用户请求,这是非常差的一种模型。
所以我们自然地想到使用多个线程来处理用户请求
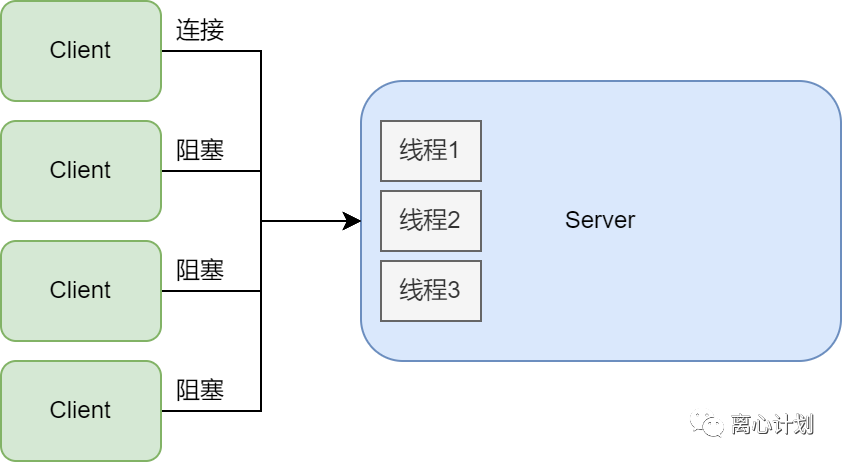
通常使用线程池处理连接,为了不过度使用线程资源,但是线程池虽然做到了最大程度地复用,但是线程依旧是一种成本很高的方式,Linux中可以将线程直接理解为进程,线程池线程数量太少依旧解决不了大量用户请求,太大则又会导致CPU的过载。
因此,IO复用模型解决的就是大量线程开销问题,以Select为例,将所有的连接socket绑定到一个线程上,这个线程做的事情就是不断去检查挂在自己身上的socket有没有数据进来,在有数据之前select是阻塞的,有了数据就通知工作线程来去拿数据。整理来说,将多线程的阻塞变为归纳到一个线程的阻塞叫做IO复用,处理该线程上所有IO事件到分发工作线程处理叫做Reactor。
单Reactor单线程
指的就是单个阻塞监听连接线程,单个工作线程。优点在于模型简单,缺点也很明显,工作线程只有一个无法发挥多核优势,且工作线程除了网络IO,还可能有其他阻塞操作,影响其他请求执行。
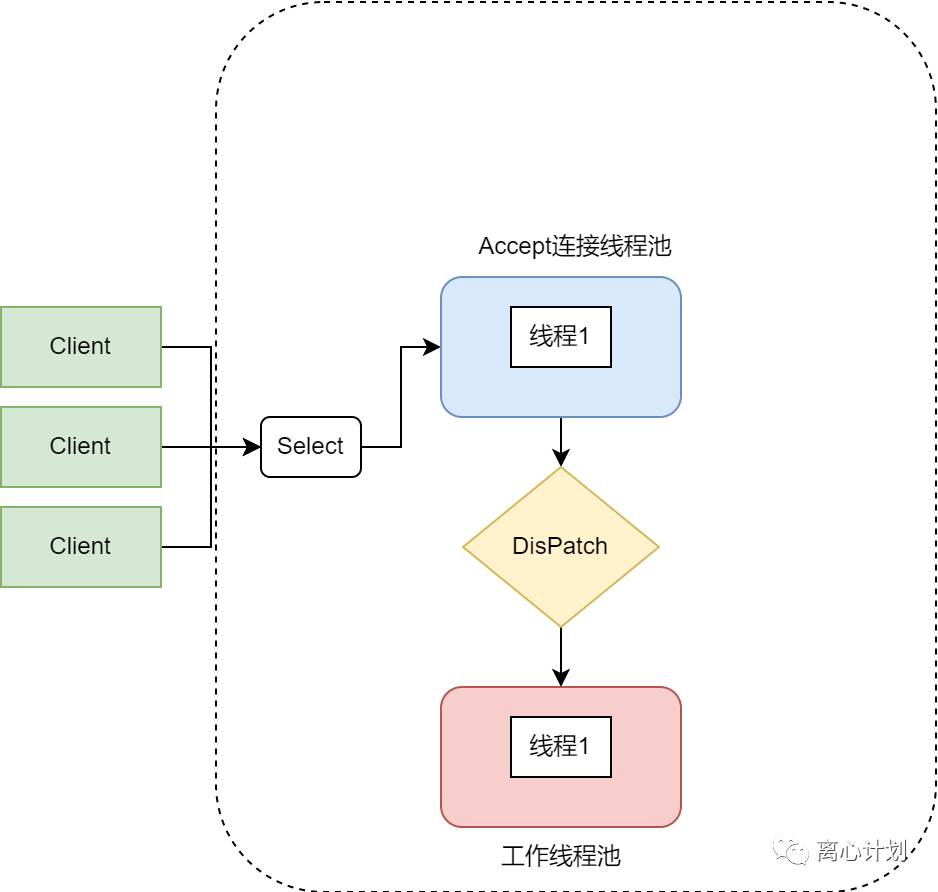
单Reactor多线程
单个监听线程多个工作线程,优点在于发挥了多核CPU性能,缺点在于处理连接与响应IO事件的线程只有一个,高并发下处理会有瓶颈。

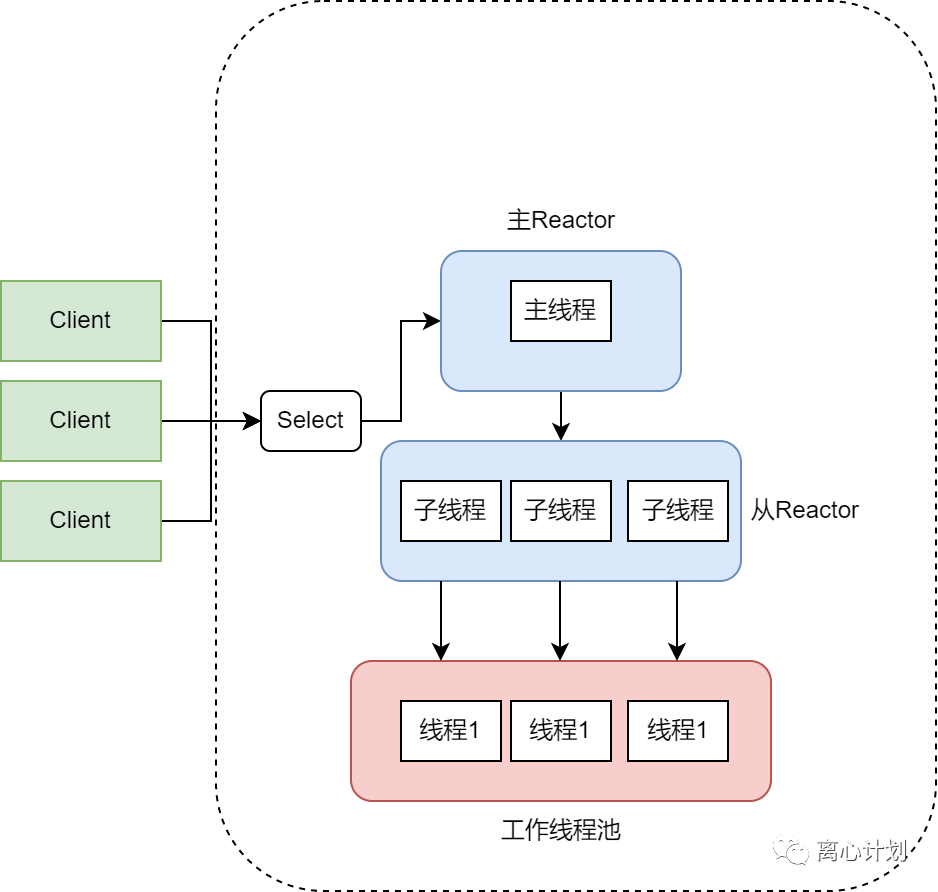
主从Reactor多线程
不单单只是增加了连接线程池的数量,而且形成了主从关系,主线程指负责注册连接并分配子线程关联对应socket,由子线程监听事件并分发给工作线程。优点在于分工明确,主线程不会因为高并发而有单线程问题。
Proactor模型
Reactor模型属于同步模型,因为最后处理读写操作的是工作线程。而Proactor是异步模型,由内核线程处理完读写的IO操作后才通知工作线程去处理后续流程,主要分为这几步:
用户线程创建Proactor初始化环境,并创建Handler用于完成IO后的操作
用户线程创建Proactor,通过AcynOptProcessor注册Handler和Proactor到内核
AcynOptProcessor完成IO操作后通知Proactor并回调用户空间的Handler(内核态到用户态的切换)

小结
这一小节介绍了一下IO模型和线程模型,大家应该对于网络IO是怎么处理的有了一个大概的了解,后面我们的Netty将上面的动作封装的很好,我们开箱即用,大家感兴趣可以去了解下各种服务器是用了什么IO模型和线程模型比如Nginx、Tomcat等。
