随机梯度下降
minibatch-SGD
最简单的更新形式,沿着梯度负方向改变参数,其中dx由小批量数据求得
x += - learning_rate * dx
学习率衰减
- 随步数衰减:经过多少步,衰减为之前得0.9
- 指数衰减:α = α 0 e − k t \alpha = \alpha _ { 0 } e ^ { - k t }α=α0e−kt
- 1/t衰减:α = α 0 / ( 1 + k t ) \alpha = \alpha _ { 0 } / ( 1 + k t )α=α0/(1+kt)
动量(Momentum)更新
基于动量的随机梯度下降的每次更新,不仅取决于当前的梯度,还取决于过去的梯度大小。当当前的梯度于之前不同时,那么真实的参数更新梯度会变小;相反,当当前梯度于之前相同时,真实参数的更新梯度会变大。在迭代后期,动量法会起到减少震荡,增加稳定性的作用。
v t = γ v t − 1 + g t θ t = θ t − 1 − η v t \begin{aligned} v _ { t } & = \gamma v _ { t - 1 } + g _ { t } \\ \theta _ { t } & = \theta _ { t - 1 } - \eta v _ { t } \end{aligned}vtθt=γvt−1+gt=θt−1−ηvt
- v t v_tvt 当前时刻梯度的指数衰减滑动平均
- v t − 1 v_{t-1}vt−1 上一时刻梯度的指数衰减滑动平均
- g t g_tgt 当前时刻的梯度
- γ \gammaγ 动量因子,控制着历史梯度信息对当前时刻梯度指数衰减滑动平均影响的大小
在训练初期,g t g_tgt每次的方向都相同,因此下降速度越快;若g t g_tgt的方向发生改变,则下降速度会减缓。可以计算出v t v_tvt将无限趋近于g t 1 − γ \frac { g _ { t } } { 1 - \gamma }1−γgt,即梯度下降的过程是先加速再匀速。因此在调整参数时,若γ \gammaγ减小,则学习率应该增大。
在cs231n中对这部分描述为:与上述公式相同
# 动量更新
v = mu * v - learning_rate * dx # 与速度融合
x += v # 与位置融合
Nesterov动量更新
如下图所示,普通的动量更新是将动量和当时梯度进行求和而得到最后参数更新梯度。Nesterov动量更新则是先根据动量进行位移,再在该位置计算梯度,如下图所示。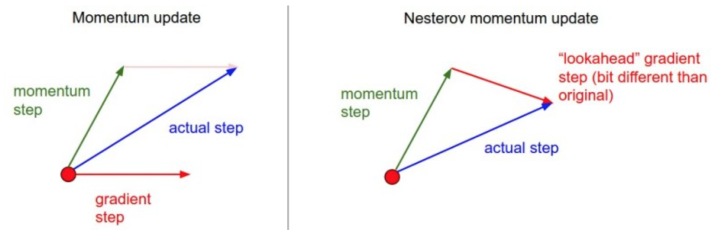
代码如下:
x_ahead = x + mu * v
# 计算dx_ahead(在x_ahead处的梯度,而不是在x处的梯度)
v = mu * v - learning_rate * dx_ahead
x += v
## 也可以改写为
v_prev = v # 存储备份
v = mu * v - learning_rate * dx # 速度更新保持不变
x += -mu * v_prev + (1 + mu) * v # 位置更新变了形式
逐参数适应学习率方法
在之前的随机梯度下降中,不管用不用动量,所有的参数更新都使用相同的学习率。而这部分的方法会对学习率进行逐参数适应,也就是说每个参数的学习率都会不同。
Adagrad
G = G + g ⊙ g { G }= { G } + { g } \odot { g }G=G+g⊙gη = η G + ϵ { \eta } = \frac { \eta } { \sqrt {{ G } + \epsilon } }η=G+ϵηx = x − η g { x } = { x } -{ \eta } { g }x=x−ηg
变量G { G }G的大小和g { g }g是一样的,是对每个参数的梯度的平方和的累加。
- 优点:在迭代的过程中不断自我调整学习率。如果模型中某个参数的梯度一直都很大,那么该参数的学习率就会下降的快一些;反之则相反。
- 缺点:学习率的下降是单调的,随着迭代次数的增加,G越来越大,学习率不断减小。若学习率降得过快,则很难找到最优解。
#首先在计算梯度后,将梯度平方累加
cache += dx**2
#然后根据累加结果对学习率进行微调
learning_rate = learning_rate/ (np.sqrt(cache) + eps)
# 进行参数更新
x += - learning_rate * dx
RMSprop
Adagrad的缺点就是学习率的更新是单调下降的,RMSprop使用了滑动平均解决了这个问题,使得学习率既可以增大也可以减小。
G t = γ G t − 1 + ( 1 − γ ) g t ⊙ g t G _ { t } = \gamma G _ { t - 1 } + ( 1 - \gamma ) g _ { t } \odot g _ { t }Gt=γGt−1+(1−γ)gt⊙gtθ t = θ t − 1 − η G t + ϵ ⊙ g t \theta _ { t } = \theta _ { t - 1 } - \frac { \eta } { \sqrt { G _ { t } + \epsilon } } \odot g _ { t }θt=θt−1−Gt+ϵη⊙gt
- G t G _ { t }Gt指梯度平方的滑动平均
- g t g_ { t }gt指当前的梯度
- γ \gammaγ是衰减率,控制着历史梯度信息滑动平均的长度范围,一般取[0.9,0.99,0.999]。
cache = decay_rate * cache + (1 - decay_rate) * dx**2
learning_rate = learning_rate / (np.sqrt(cache) + eps)
x += - learning_rate * dx
Adam
Adam可以看作是动量与RMSprop的结合,使模型不仅可以对学习率进行逐参数优化,而且使用动量来调整参数梯度的方向。
M t = β 1 M t − 1 + ( 1 − β 1 ) g t M _ { t } = \beta _ { 1 } M _ { t - 1 } + \left( 1 - \beta _ { 1 } \right) g _ { t }Mt=β1Mt−1+(1−β1)gtG t = β 2 G t − 1 + ( 1 − β 2 ) g t ⊙ g t G _ { t } = \beta _ { 2 } G _ { t - 1 } + \left( 1 - \beta _ { 2 } \right) g _ { t } \odot g _ { t }Gt=β2Gt−1+(1−β2)gt⊙gtM ^ t : = M t 1 − β 1 t \hat { M } _ { t } : = \frac { M _ { t } } { 1 - \beta _ { 1 } ^ { t } }M^t:=1−β1tMtG ^ t : = G t 1 − β 2 t \hat { G } _ { t } : = \frac { G _ { t } } { 1 - \beta _ { 2 } ^ { t } }G^t:=1−β2tGtθ t = θ t − 1 − η M ^ t G ^ t + ϵ \theta _ { t } = \theta _ { t - 1 } - \frac { \eta \hat { M } _ { t } } { \sqrt { \hat { G } _ { t } + \epsilon } }θt=θt−1−G^t+ϵηM^t
- M t M _ { t }Mt是指经过动量调整后的梯度值,可以看作是梯度的滑动平均,由公式可以看出M t M _ { t }Mt也会受之前梯度的影像
- G t G _ { t }Gt当前梯度平方的滑动平均,与RMSprop一样
- β 1 \beta 1β1β 2 \beta 2β2指两个滑动平均的衰减率
- M ^ t \hat { M } _ { t }M^tG ^ t \hat {G } _ { t }G^t是对之前的偏差修正,减小M t M _ { t }MtG t G _ { t }Gt初始化为0时在迭代初期对它们的衰减滑动平均的影响
t+=1
m = beta1 * m + (1 - beta1) * dw
v = beta2 * v + (1 - beta2) * (dw ** 2)
mb = m/(1-beta1**t)
vb = v/(1-beta2**t)
next_w = w - learning_rate* mb / (np.sqrt(vb) + epsilon)
参考
https://zhuanlan.zhihu.com/p/21798784?refer=intelligentunit
https://blog.csdn.net/mzpmzk/article/details/80100864
https://zhuanlan.zhihu.com/p/22252270