前言
Java中的所有类都继承了Object类,equals()和hashCode()就来自于Object类;我创建了一个Object类的实例,不去重写hashCode方法,直接输出:
Object obj = new Object();
System.out.println(obj.hashCode());
默认的hashCode方法的返回值形式:
这串数字是什么呢?打来源码查看注释;在hashCode方法注释中,调用hashCode方法默认返回的值被称为哈希码值。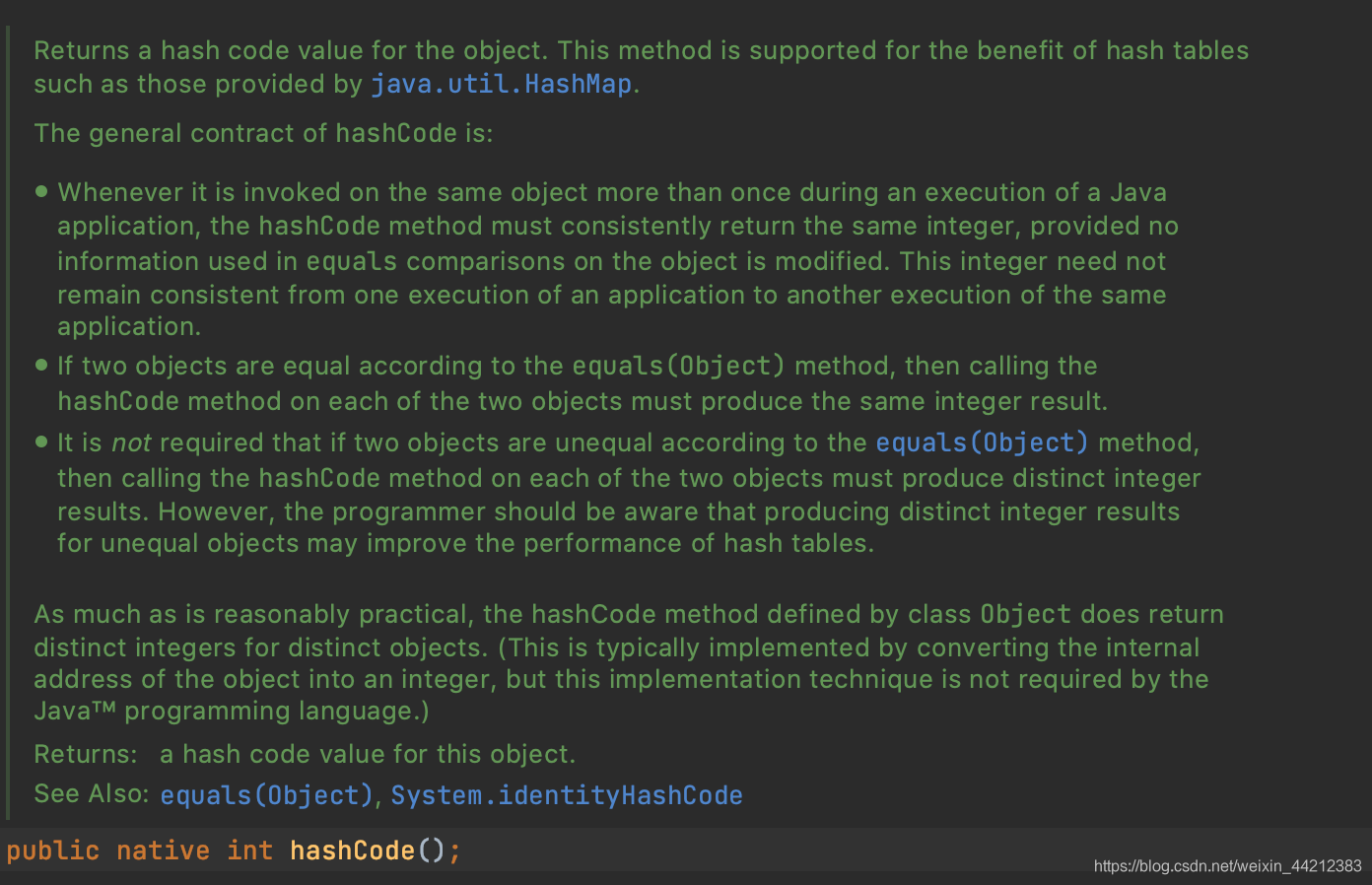
看到有文章说hashCode是通过对象内存地址映射过来的,这个在这里不做深入讨论,hashCode返回的并不一定是对象的(虚拟)内存地址,具体取决于运行时库和JVM的具体实现,但是最终的实现一定是保证在一次执行过程中唯一的。
hashCode()通用规定
- 如果没有修改 equals 方法中用以比较的信息(equals方法默认是用"=="进行比较值或者地址),在应用程序的一次执行过程中对一个对象重复调用 hashCode 方法时,它必须始终返回相同的值。在应用程序的多次执行过程中,每个执行过程在该对象上获取的结果值可以不相同。
- 如果两个对象根据 equals(Object) 方法比较是相等的,那么在两个对象上调用 hashCode 就必须产生的结果是相同的整数。
- 如果两个对象根据 equals(Object) 方法比较并不相等,则不要求在每个对象上调用 hashCode 都必须产生不同的结果。 但是,程序员应该意识到,为不相等的对象生成不同的结果可能会提高散列表(hash tables)的性能。
以Person类为例,有属性id,name,age,如果不重写equals方法和hashCode方法,创建两个Person进行比较,结果肯定是false,因为这个时候比较的是直接比较的对象在堆中的内存地址。
重写了equals方法但是注释掉hashCode方法:
@NoArgsConstructor
@AllArgsConstructor
public class Person {
private String id;
private String name;
private int age;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(id, person.id);
}
// @Override
// public int hashCode() {
// return Objects.hash(id, name, age);
// }
}
这个时候创建如图两个Person对象进行比较,结果肯定是true,因为我们重写了equals方法,此时两个Person对象比较的时候比较的是id这个属性,它们的id都是“303”,此时我们认为id一样的两个对象逻辑上就是一样的。一岁的硬糖和两岁的硬糖逻辑上是一样的,不同的只是年龄不一样,位置变了。
public static void main(String[] args) {
Person person1 = new Person("303","硬糖",1);
Person person2 = new Person("303","硬糖",2);
System.out.println(person1.equals(person2));
}
这样看来我们虽然违反了规定二,但是好像只重写equals方法不重写hashCode方法也不会有什么问题,我们继续往下看:
我们想把这两个对象存储到Set(不可重复)中,这个时候就会出现问题了!
Set set = new HashSet<Person>();
set.add(person1);
set.add(person2);
set.forEach((person) -> {System.out.println(person);});
Set是无序不可重复的,即存入的对象不会按照存入顺序进行存储且对象不能重复,重复会覆盖,我们认为person1和person2在逻辑上是相等的,所以最终存入的结果应该只存在一个对象在Set中,然鹅我们遍历出来的结果是:
这河里吗?明明两个对象比较是相等的,但是却在Set中都存入了;原因是因为存入Set时,底层是HashMap,也就是基于hash的存储方式,存储在hash表的下标计算结果首先是和对象的hashCode()返回值直接相关。
当我们向HashSet集合中添加元素时,首先 HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据该hashCode值决定该对象在HashSet中的存储位置。因为我们并未重写Person的该方法,所以两个通过new创建的对象的hashCode()返回值自然也是不一样的。它们的hashCode()方法返回值不相等,HashSet将会把它们存储在不同位置,也就添加成功。如果冲突了再调用equals方法进一步判断是否相等,相等就覆盖,不等再散列到其它地址。这里也存在一个效率问题!
很明显上面代码已经违反了hashCode()的通用约定,并且不能正常使用集合以及其它基于hash的容器,所以我们在重写equals方法的同时必须重写hashCode方法,那么我们怎么来进行重写呢?严格按照通用约定!
还是以Person类为例,我们来重写它的hashCode方法:
@Override
public int hashCode() {
return this.age;
}
我们可以通过age来进行比较吗?好像也不能,age属性并不能保证唯一,两个Person对象可能age一样,这个时候hashCode()会返回同样的值,存入Set会不会出现问题呢,好的我比较直接,我继续再创建一个对象person3:
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(id, person.id);
}
@Override
public int hashCode() {
return this.age;
}
在添加之后的结果:
Person person1 = new Person("303","硬糖",1);
Person person2 = new Person("303","硬糖",2);
Person person3 = new Person("505","硬糖",2);
Set set = new HashSet<Person>();
set.add(person1);
set.add(person2);
set.add(person3);
set.forEach((person) -> {System.out.println(person);});

也许会疑惑明明hashCode()返回值相同,为什么还是存入重复了,Set并没有将Person2和Person3判断为相等,这是因为Set的判断重复方式不仅基于hashCode(),还基于equals(),如果hashCode()返回值一样会继续使用equals方法判断是否返回true,但是如果equals()返回true,即使hashCode()不一致,最后认为两个比较的对象一致。在集合中的重复判断时,只有hashCode()返回整数值一致且equals()判断返回true才判断为两个对象重复!所以重写equals()必须同时重写hashCode(),否则可能会造成集合使用异常。
规范第三条提到的散列表性能主要是和其所使用的hash函数直接相关,一般不直接取决于hashCode(),以HashMap为例,其hash()的返回值是key的hashCode()返回值的高十六位和低十六位进行了异或运算。一个好的 hash 方法趋向于为不相等的实例生成不相等的哈希码。理想情况下,hash 方法为集合中不相等的实例均匀地分配 int 范围内的哈希码。实现这种理想情况可能是困难的。 幸运的是,要获得一个合理的近似的方式并不难。
Effective Java中提出一个简单的方式:
声明一个 int 类型的变量 result,并将其初始化为对象中第一个重要属性
c的哈希码,如下面步骤 2.a 中所计算的那样。(重要的属性是影响比较相等的领域。)对于对象中剩余的重要属性
f,请执行以下操作:
a. 比较属性f与属性c的 int 类型的哈希码:– i. 如果这个属性是基本类型的,使用
Type.hashCode(f)方法计算,其中Type类是对应属性f基本类型的包装类。
– ii. 如果该属性是一个对象引用,并且该类的 equals 方法通过递归调用 equals 来比较该属性,并递归地调用 hashCode 方法。 如果需要更复杂的比较,则计算此字段的“范式(“canonical representation)”,并在范式上调用 hashCode。 如果该字段的值为空,则使用 0(也可以使用其他常数,但通常来使用 0 表示)。
– iii. 如果属性f是一个数组,把它看作每个重要的元素都是一个独立的属性。 也就是说,通过递归地应用这些规则计算每个重要元素的哈希码,并且将每个步骤 2.b 的值合并。 如果数组没有重要的元素,则使用一个常量,最好不要为 0。如果所有元素都很重要,则使用Arrays.hashCode方法。b. 将步骤 2.a 中属性 c 计算出的哈希码合并为如下结果:
result = 31 * result + c;返回 result 值。
当写完 hashCode 方法后,考虑是否逻辑相等的实例有相同的哈希码。 编写单元测试来验证你的直觉。如果相同的实例有不相等的哈希码,找出原因并解决问题。
可以从哈希码计算中排除派生属性(derived fields)。换句话说,如果一个属性的值可以根据参与计算的其他属性值计算出来,那么可以忽略这样的属性。您必须排除在 equals 比较中没有使用的任何属性,否则可能会违反 hashCode 约定的第二条。
不要试图从哈希码计算中排除重要的属性来提高性能。 由此产生的哈希函数可能运行得更快,但其质量较差可能会降低哈希表的性能,使其无法使用。 具体来说,哈希函数可能会遇到大量不同的实例,这些实例主要在你忽略的区域中有所不同。 如果发生这种情况,哈希函数将把所有这些实例映射到少许哈希码上,而应该以线性时间运行的程序将会运行平方级的时间。
这不仅仅是一个理论问题。 在 Java 2 之前,String 类哈希函数在整个字符串中最多使用 16 个字符,从第一个字符开始,在整个字符串中均匀地选取。 对于大量的带有层次名称的集合(如 URL),此功能正好显示了前面描述的病态行为。
不要为 hashCode 返回的值提供详细的规范,因此客户端不能合理地依赖它; 你可以改变它的灵活性。 Java 类库中的许多类(例如 String 和 Integer)都将 hashCode 方法返回的确切值指定为实例值的函数。 这不是一个好主意,而是一个我们不得不忍受的错误:它妨碍了在未来版本中改进哈希函数的能力。 如果未指定细节并在散列函数中发现缺陷,或者发现了更好的哈希函数,则可以在后续版本中对其进行更改。
总结
回到这篇文章要讨论的问题:为什么重写 equals 方法时同时也要重写 hashcode 方法?
- 在使用集合等相关基于散列表的容器时可能会出现预期之外的结果
- 在使用集合的时候可以提高散列性能
总之,每次重写 equals 方法时都必须重写 hashCode 方法,否则程序将无法正常运行。你的 hashCode 方法必须遵从 Object 类指定的常规约定,并且必须执行合理的工作,将不相等的哈希码分配给不相等的实例。
后记
虽然 Object 是一个具体的类,但它主要是为继承而设计的。它的所有非 final 方法(equals、hashCode、toString、clone 和 finalize)都有清晰的通用约定( general contracts),因为它们被设计为被子类重写。任何类要重写这些方法时,都有义务去遵从它们的通用约定;如果不这样做,将会阻止其他依赖于约定的类 (例如 HashMap 和 HashSet) 与此类一起正常工作。
写完了总觉得有地方不对,先下班了过段时间忘掉了再来看!
"=="比较的是值(Java中只有值传递),hashCode()返回值不一定和地址有关,好像Oracle JDK的实现中它俩没关系。