非线性优化-高斯牛顿法
实践slam中介绍的高斯牛顿法,其实非线性优化是门独立的课程,在很多领域都有应用,如机械优化设计、数值分析,最近再回顾一遍。
前言
slam中将求状态估计问题转化为求最大似然估计的问题,接着又将最大似然估计问题转为最小二乘问题。由于函数是非线性函数,这个最小二乘问题可以用优化的思路来求解。其中,高斯牛顿法,就是一种经典的求解优化问题的方法。在刘惟信教授主编的《机械最优化设计》,高斯牛顿法又被叫做最小二乘法。优化问题,最重要的两点就是方向和步长,搞清楚这两点,就抓住了问题的主要矛盾。每次前进一点点,目标函数的值就下降一点,当步长变化很小的时候,再也没法前进时候,就到达了最小值(当然也可能陷入局部的最小值)。
一、什么是高斯-牛顿法?
1.概念
高斯-牛顿法是用去求解无约束问题的优化方法,一般用于求函数平方和的极小值问题,且不必计算二阶偏导数矩阵,收敛速度较快。
当遇到目标函数为:
F ( X ) = ∑ i = 1 m f i 2 ( X ) X ∈ E n ( m ≥ n ) F(X)=\sum_{i=1}^{m}f_i^2(X) \quad X\in E^n \quad (m \geq n)F(X)=i=1∑mfi2(X)X∈En(m≥n)可以Gauss-Newteon求解F ( X ) F(X)F(X)的极小值,不必计算二阶偏导数,而计算一阶偏导数即可求解。若是求解一般的优化问题,需要将目标函数转为平方和的形式。
因为
∂ F ( X ) ∂ x j = 2 ∑ i = 1 m f i ( X ) ∂ f i ( X ) ∂ x j ( j = 1 , 2 , . . . , n ) \frac{\partial F(X)}{\partial x_j} = 2\sum_{i=1}^{m}f_i(X)\frac{\partial f_i(X)}{\partial x_j} \quad (j=1,2,...,n)∂xj∂F(X)=2i=1∑mfi(X)∂xj∂fi(X)(j=1,2,...,n)
展开可写为:
▽ F ( X ) = [ ∂ F ( X ) ∂ x 1 ∂ F ( X ) ∂ x 2 ⋮ ∂ F ( X ) ∂ x n ] = 2 [ ∑ i = 1 m f i ( X ) ∂ f i ( X ) ∂ x 1 ∑ i = 1 m f i ( X ) ∂ f i ( X ) ∂ x 2 ⋮ ∑ i = 1 m f i ( X ) ∂ f i ( X ) ∂ x n ] = 2 [ ∂ f 1 ( X ) ∂ x 1 ∂ f 2 ( X ) ∂ x 1 ⋯ ∂ f m ( X ) ∂ x 1 ∂ f 1 ( X ) ∂ x 2 ∂ f 2 ( X ) ∂ x 2 ⋯ ∂ f m ( X ) ∂ x 2 ⋮ ⋮ ⋮ ⋮ ∂ f 1 ( X ) ∂ x n ∂ f 2 ( X ) ∂ x n ⋯ ∂ f m ( X ) ∂ x n ] [ f 1 ( X ) f 2 ( X ) ⋮ f m ( X ) ] = 2 J ( X ) T f ( X ) . . . ( 1 ) \begin{aligned} \bigtriangledown F(X) =& \left[ \begin{matrix} \frac{\partial F(X)}{\partial x_1} \\ \frac{\partial F(X)}{\partial x_2}\\ \vdots\\ \frac{\partial F(X)}{\partial x_n} \end{matrix} \right] = 2\left[ \begin{matrix} \sum_{i=1}^{m}f_i(X)\frac{\partial f_i(X)}{\partial x_1}\\ \sum_{i=1}^{m}f_i(X)\frac{\partial f_i(X)}{\partial x_2}\\ \vdots\\ \sum_{i=1}^{m}f_i(X)\frac{\partial f_i(X)}{\partial x_n} \end{matrix} \right] \\ =&2\left[ \begin{matrix} \frac{\partial f_1(X)}{\partial x_1} & \frac{\partial f_2(X)}{\partial x_1} & \cdots &\frac{\partial f_m(X)}{\partial x_1} \\ \frac{\partial f_1(X)}{\partial x_2} & \frac{\partial f_2(X)}{\partial x_2} & \cdots &\frac{\partial f_m(X)}{\partial x_2}\\ \vdots & \vdots & \vdots & \vdots \\ \frac{\partial f_1(X)}{\partial x_n} & \frac{\partial f_2(X)}{\partial x_n} & \cdots &\frac{\partial f_m(X)}{\partial x_n} \end{matrix} \right] \left[ \begin{matrix} f_1(X)\\ f_2(X)\\ \vdots\\ f_m(X) \end{matrix} \right] \\ =&2J(X)^Tf(X) \quad ...(1) \end{aligned}▽F(X)===⎣⎢⎢⎢⎢⎡∂x1∂F(X)∂x2∂F(X)⋮∂xn∂F(X)⎦⎥⎥⎥⎥⎤=2⎣⎢⎢⎢⎢⎡∑i=1mfi(X)∂x1∂fi(X)∑i=1mfi(X)∂x2∂fi(X)⋮∑i=1mfi(X)∂xn∂fi(X)⎦⎥⎥⎥⎥⎤2⎣⎢⎢⎢⎢⎡∂x1∂f1(X)∂x2∂f1(X)⋮∂xn∂f1(X)∂x1∂f2(X)∂x2∂f2(X)⋮∂xn∂f2(X)⋯⋯⋮⋯∂x1∂fm(X)∂x2∂fm(X)⋮∂xn∂fm(X)⎦⎥⎥⎥⎥⎤⎣⎢⎢⎢⎡f1(X)f2(X)⋮fm(X)⎦⎥⎥⎥⎤2J(X)Tf(X)...(1)
其中,J ( X ) = [ J i j ( X ) ] m × n J(X)=[J_{ij}(X)]_{m\times n}J(X)=[Jij(X)]m×n 为Jacobian matrix,J i , j = ∂ f i ( X ) ∂ x j , i = 1 , . . . , m ; j = 1 , . . . , n J_{i,j} =\frac{\partial f_i(X)}{\partial x_j},i=1,...,m;j=1,...,nJi,j=∂xj∂fi(X),i=1,...,m;j=1,...,n。
将f i ( X ) 在 X = X ( k ) 处 用 T a y l o r 展 开 近 似 为 f_i(X)在X=X^{(k)}处用Taylor展开近似为fi(X)在X=X(k)处用Taylor展开近似为:
f i ( X ) ≈ f i ( X ( k ) ) + [ ▽ f i ( X k ) ] [ X − X ( k ) ] = l i k ( X ) f_i(X)\approx f_i(X^{(k)})+[\bigtriangledown f_i(X^{k})][X-X^{(k)}]=l_i^k(X)fi(X)≈fi(X(k))+[▽fi(Xk)][X−X(k)]=lik(X)
F ( X ) = ∑ i = 1 m f i 2 ( X ) = ∑ i = 1 m [ l i k ( X ) ] = L k ( X ) F(X)=\sum_{i=1}^mf_i^2(X)=\sum_{i=1}^m[l_i^k(X)]=L^k(X)F(X)=i=1∑mfi2(X)=i=1∑m[lik(X)]=Lk(X)
则∂ 2 F ( X ) ∂ x i ∂ x j ≈ ∂ 2 L k ( X ) ∂ x i ∂ x j = 2 ▽ f i ( X k ) ▽ f j ( X k ) = 2 ∑ i = 1 m J r i ( X k ) J r j ( X k ) \frac{\partial^2F(X)}{\partial x_i \partial x_j} \approx \frac{\partial^2L^k(X)}{\partial x_i \partial x_j}=2\bigtriangledown f_i(X^k) \bigtriangledown f_j(X^k)=2\sum_{i=1}^{m}J_{ri}(X^k)J_{rj}(X^k)∂xi∂xj∂2F(X)≈∂xi∂xj∂2Lk(X)=2▽fi(Xk)▽fj(Xk)=2i=1∑mJri(Xk)Jrj(Xk)
▽ 2 F ( X k ) ≈ 2 [ J ( X k ) ] T J ( X k ) . . . ( 2 ) \bigtriangledown^2F(X^k)\approx2[J(X^k)]^TJ(X^k) \quad...(2)▽2F(Xk)≈2[J(Xk)]TJ(Xk)...(2)
将(1)、(2)代入到牛顿法的公式当中
X ( k + 1 ) = X k − H ( X k ) − 1 ▽ F ( X k ) X^{(k+1)}=X^k-H(X^k)^{-1}\bigtriangledown F(X^k)X(k+1)=Xk−H(Xk)−1▽F(Xk)
得X ( k + 1 ) = X k − [ J ( X k ) T J ( X k ) ] − 1 J ( X k ) T f ( X ) X^{(k+1)}=X^k-[J(X^k)^TJ(X^k)]^{-1}J(X^k)^Tf(X)X(k+1)=Xk−[J(Xk)TJ(Xk)]−1J(Xk)Tf(X)
从这也可以看出为什么Guass_Newton法叫做最小二乘法。
将求逆这项放到左边,可得:
[ J ( X k ) T J ( X k ) ] △ X = J ( X k ) T f ( X ) [J(X^k)^TJ(X^k)]\triangle X=J(X^k)^Tf(X) \\[J(Xk)TJ(Xk)]△X=J(Xk)Tf(X)
类似A x = b Ax=bAx=b,是一个典型的最小二乘问题,也可以看出A AA的性质对求解方程非常关键。
因此步长为△ X = J ( X k ) T f ( X ) \triangle X= J(X^k)^Tf(X)△X=J(Xk)Tf(X),方向为− [ J ( X k ) T J ( X k ) ] − 1 -[J(X^k)^TJ(X^k)]^{-1}−[J(Xk)TJ(Xk)]−1。
视觉SLAM十四讲中的推导更简单明了一点。如果增量矩阵H ( X k ) − 1 H(X^k)^{-1}H(Xk)−1不可逆,将导致算法不收敛。
2.算法流程
这里给出的是修正Gauss-Newton法的流程。
- 给定初始点X ( 0 ) X^{(0)}X(0)和收敛精度ε \varepsilonε
- 令k=0,求当前的雅可比矩阵J ( X ( k ) ) J(X^{(k)})J(X(k))
- 求步长S ( k ) = − [ J ( X ( k ) ) T J ( X ( k ) ) ] − 1 J ( X ( k ) ) T f ( X ) S^{(k)}=-[J(X^{(k)})^TJ(X^{(k)})]^{-1}J(X^{(k)})^Tf(X)S(k)=−[J(X(k))TJ(X(k))]−1J(X(k))Tf(X)
- 进行一维探索求最优步长α ( k ) \alpha^{(k)}α(k),求新点X ( k + 1 ) = X ( k ) + α ( k ) S ( k ) X^{(k+1)}=X^{(k)}+\alpha^{(k)}S^{(k)}X(k+1)=X(k)+α(k)S(k)
使得m i n F ( X ( k ) + α S ( k ) ) = F ( X ( k ) + α ( k ) S ( k ) ) minF(X^{(k)}+\alpha S^{(k)})=F(X^{(k)}+\alpha^{(k)}S^{(k)})minF(X(k)+αS(k))=F(X(k)+α(k)S(k)) - 若∣ ∣ X ( k + 1 ) − X ( k ) ∣ ∣ ⩽ ε ||X^{(k+1)}-X^{(k)}|| \leqslant \varepsilon∣∣X(k+1)−X(k)∣∣⩽ε,则停止计算,否则回到2
二、代码案例
1.问题描述
假设带拟合的曲线方程形式为:
y = exp ( a x 2 + b x + c ) y=\exp(ax^2+bx+c)y=exp(ax2+bx+c)
用y = exp ( a x 2 + b x + c ) + w y=\exp(ax^2+bx+c)+wy=exp(ax2+bx+c)+w,引入高斯噪声来生成N个观测的数据点,根据这些点求曲线的参数a , b , c a,b,ca,b,c。
那么,该问题转化求解下面的优化目标
m i n F ( X ) = m i n 1 2 ∑ i = 1 N ∣ ∣ y i − exp ( a x i 2 + b x i + c ) ∣ ∣ 2 minF(X)=min\frac{1}{2}\sum_{i=1}^N||y_i-\exp(ax_i^2+bx_i+c)||^2minF(X)=min21i=1∑N∣∣yi−exp(axi2+bxi+c)∣∣2
优化变量为a , b , c a,b,ca,b,c。
3.代码实现
代码如下:
#include <iostream>
#include <opencv2/opencv.hpp>
#include <chrono>
#include <Eigen/Core>
#include <Eigen/Dense>
using namespace std;
using namespace Eigen;
int main(){
double ar=1.0, br=2.0, cr=1.0;//真实参数值
double ae=2.0, be=-1.0,ce=6.0;//估计参数值
int N=100;
double w_sigma=1.0; //噪声干扰值
double inv_sigma=1.0/w_sigma;
cv::RNG rng;
//生成数据点,用两个向量来存储
vector<double> x_data, y_data;
for(int i=0;i<N;i++){
double x=i/100.0;
x_data.push_back(x);
y_data.push_back(exp(ar*x*x+br*x+cr)+rng.gaussian(w_sigma*w_sigma));
}
//Gauss_Newton迭代
int iterations = 100;//最大迭代次数
double cost = 0, lastcost = 0;
chrono::steady_clock::time_point start_t1 = chrono::steady_clock::now();
for(int i;i<iterations;i++){
//初始化海森矩阵
Matrix3d H = Matrix3d::Zero();
Vector3d b = Vector3d::Zero();
cost = 0;
//每迭代一次要计算100个点
for(int j=0;j<N;j++){
double xi = x_data[j],yi = y_data[j];
double error = yi - exp(ae*xi*xi+be*xi+ce);
Vector3d J;
//初始化雅可比矩阵
J[0] = -xi*xi*exp(ae*xi*xi+be*xi+ce);
J[1] = -xi*exp(ae*xi*xi+be*xi+ce);
J[2] = -exp(ae*xi*xi+be*xi+ce);
H += J*J.transpose();//3*3
b += -error*J; //代码定义的J为列向量,公式中定义为行向量
cost += error*error;//目标函数值
}
//求步长,通过解线形方程Hx=b
Vector3d dx = H.ldlt().solve(b);//LDLT分解方法
if (isnan(dx[0])){
cout << "result is nan!" << endl;
break;
}
//如果目标函数不再减小就停止
if(i>0 && cost >=lastcost)
{
cout << "cost: " << cost << ">=last cost: " << lastcost << ", break." << endl;
break;
}
//更新变量,上一时刻的值+变量
ae += dx[0];
be += dx[1];
ce += dx[2];
lastcost = cost;
cout << "total cost: "<<cost<<", \t\t update: "<<dx.transpose()<<
"\t\t estimated params: "<< ae<<","<<be<<","<<ce<<endl;
}
chrono::steady_clock::time_point t2 = chrono::steady_clock::now();
chrono::duration<double> time_used = chrono::duration_cast<chrono::duration<double>>(t2-t1);
cout<<"solve time cost = "<< time_used.count() << " seconds. "<<endl;
cout<<"estimated abc = "<< ae << ", " <<be << ", " << ce <<endl;
return 0;
}
结果如下,每次运行消耗的时间会有一定的差异,大约在9ms左右,其实并不是很快。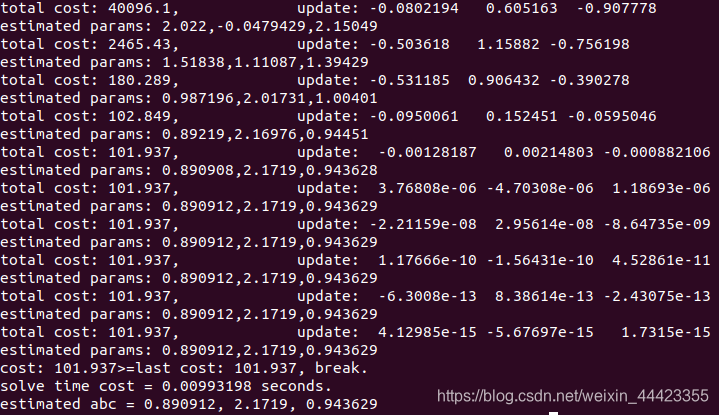
总结
非线性优化是一门经典课程,在slam中用于后端的优化。后端优化就是根据回环检测的信息和里程计推算的位姿,对地图和轨迹进行矫正。具体有待实践。
参考文献
[1]视觉slam十四讲-从理论到实践
[2]机械最优化设计