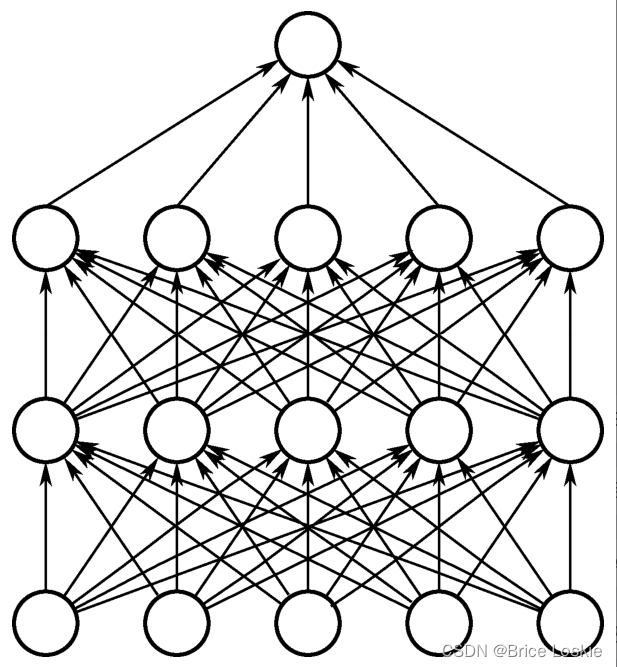
Dropout试图改变网络本身来对网络进行优化。我们先来了解一下它的工作机制,当我们训练一个普通的神经网络时,其结构如下图所示。
Dropout通常是在神经网络隐藏层的部分使用,使用的时候会临时关闭掉一部分的神经元,我们可以通过一个参数来控制神经元被关闭的概率,使用Dropout的神经网络的结构如图
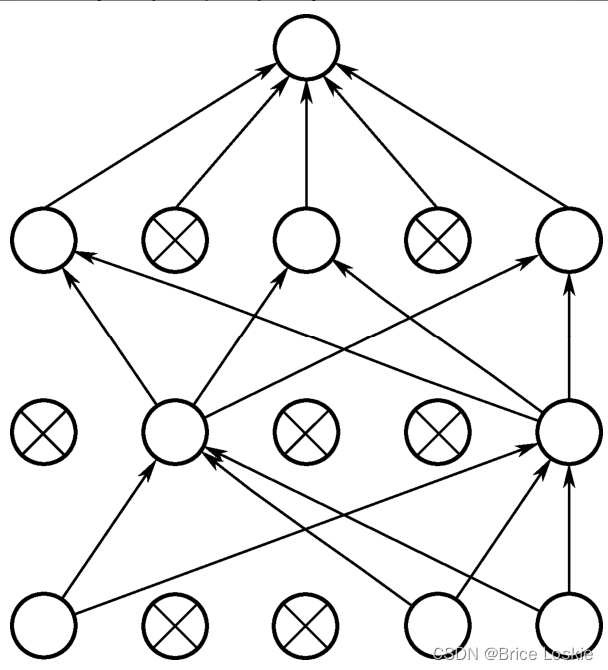
更详细的流程如下:
(1)在模型训练阶段我们可以先给Dropout参数设置一个值,如0.4。意思是大约60%的神经元是工作的,大约40%的神经元是不工作的。
(2)给需要进行Dropout的神经网络层的每一个神经元生成一个0~1的随机数(一般是对隐藏层进行Dropout)。如果神经元的随机数小于0.6,那么该神经元就被设置为工作状态;如果神经元的随机数大于或者等于0.6,那么该神经元就被设置为不工作,不工作的意思就是不参与计算和训练,可以当这个神经元不存在。
(3)设置好一部分神经元工作和一部分神经元不工作之后,我们会发现神经网络的输出值会发生变化。如果隐藏层有一半不工作,那么网络的输出值就会比原来的值要小,因为计算WX+b时,如果W矩阵中有一部分的值变成0,那么最后的计算结果肯定会变小。所以,为了使用Dropout的网络层神经元信号的总和不会发生太大的变化,对于工作的神经元的输出信号还需要除以0.4。
(4)训练阶段重复步骤(1)~(3),每一次都随机选择部分的神经元参与训练。
(5)所有的神经元在测试阶段都参与计算。
Dropout比较适合应用于只有少量数据但是需要训练复杂模型的场景,这类场景在图像领域比较常见,所以Dropout经常用于图像领域。
这里我们可以直观地通过代码来
1.数据划分
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Dropout,Flatten
from tensorflow.keras.layers import Dense,Dropout,Flatten
import numpy as np
#载入数据集
mnist=tf.keras.datasets.mnist
#划分训练集和测试集
(x_train,y_train),(x_test,y_test)=mnist.load_data()
#特征数据归一化
x_train,x_test=x_train/255.0,x_test/255.0
#标签数据转换为独热码
y_train =tf.keras.utils.to_categorical(y_train,num_classes=10)
y_test=tf.keras.utils.to_categorical(y_test,num_classes=10)2.模型训练
#定义模型
model1=Sequential([
Flatten(input_shape=(28,28)),
Dense(units=200,activation='tanh'),
Dropout(0.4),
Dense(units=100,activation='tanh'),
Dropout(0.4),
Dense(units=10,activation='softmax')
])#再定义一个没有使用dropout的模型作为对比
model2=Sequential([
Flatten(input_shape=(28,28)),
Dense(units=200,activation='tanh'),
Dropout(0),
Dense(units=100,activation='tanh'),
Dropout(0),
Dense(units=10,activation='softmax')
])3.模型训练
sgd=SGD(0.2)
model1.compile(optimizer=sgd,loss='categorical_crossentropy',metrics=['accuracy'])
model2.compile(optimizer=sgd,loss='categorical_crossentropy',metrics=['accuracy'])
epochs=500
batch_size=32
result1=model1.fit(x_train,y_train,epochs=epochs,batch_size=batch_size,validation_data=(x_test,y_test))
result2=model1.fit(x_train,y_train,epochs=epochs,batch_size=batch_size,validation_data=(x_test,y_test))4.模型对比
import matplotlib.pyplot as plt
plt.plot(np.arange(epochs),result1.history['val_accuracy'],c='b',label="Dropout")
plt.plot(np.arange(epochs),result2.history['val_accuracy'],c='y',label="FC")
plt.legend()
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()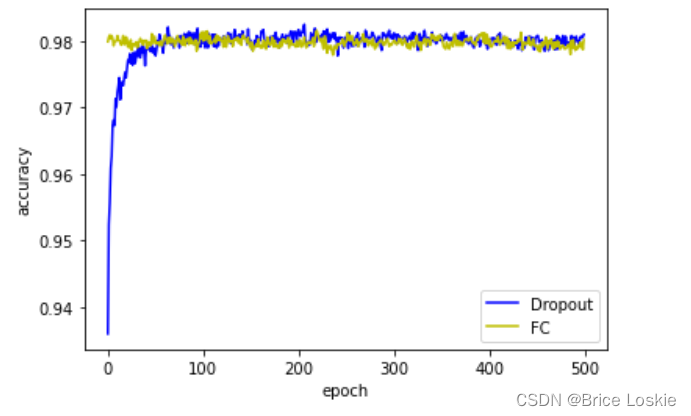
使用Dropout之后,模型的收敛速度会变慢一些,所以需要更多的训练次数才能得到好的结果。由图可知使用了dropout的模型1略好于没有使用dropout的模型2