ES安装
所用软件下载地址
百度网盘地址
提取码:gnvm
linux
新建文件夹
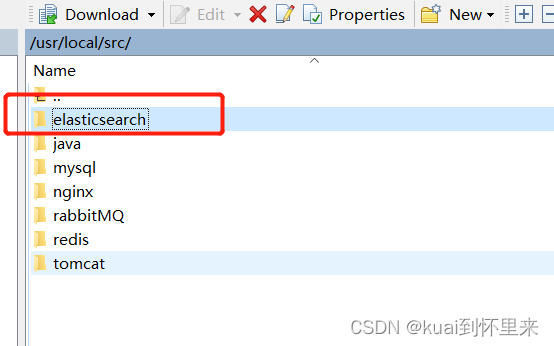
上传压缩包并解压
tar -zxvf elasticsearch-7.4.2-linux-x86_64.tar.gz
配置JDK
需要JDK11 环境,配置自带的jdk
查看jdk路径
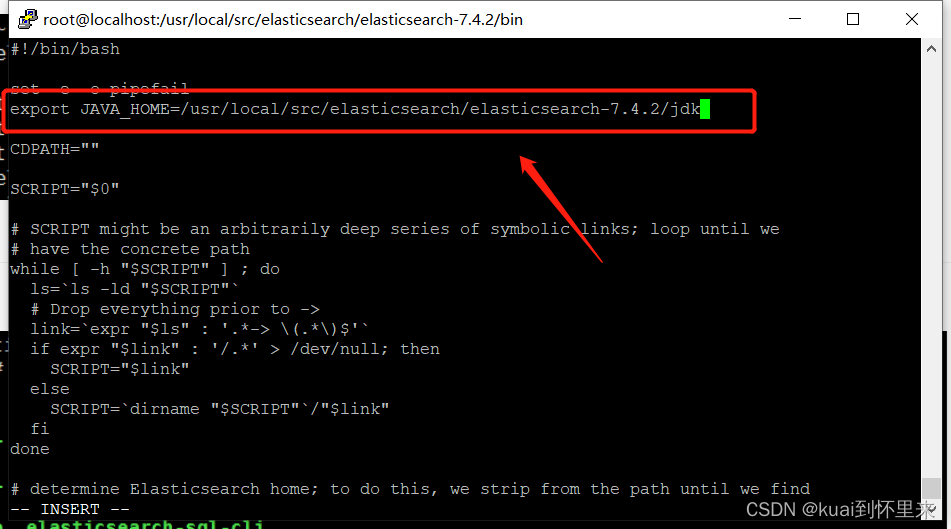
编辑 bin/elasticsearch-env
vi bin/elasticsearch-env
添加:
export JAVA_HOME=/usr/local/src/elasticsearch/elasticsearch-7.4.2/jdk
创建用户和用户组
ES不能有root用户启动
添加用户组
- groupadd 组名
groupadd esgroup
- 添加用户,分配到所属组
useradd 用户名 -g 组名 -p 密码
useradd esuser -g esgroup
- chown 修改目所属的用户和组
chown -R esuser:esgroup /usr/local/src/elasticsearch/elasticsearch-7.4.2

启动配置
切换用户
su esuser
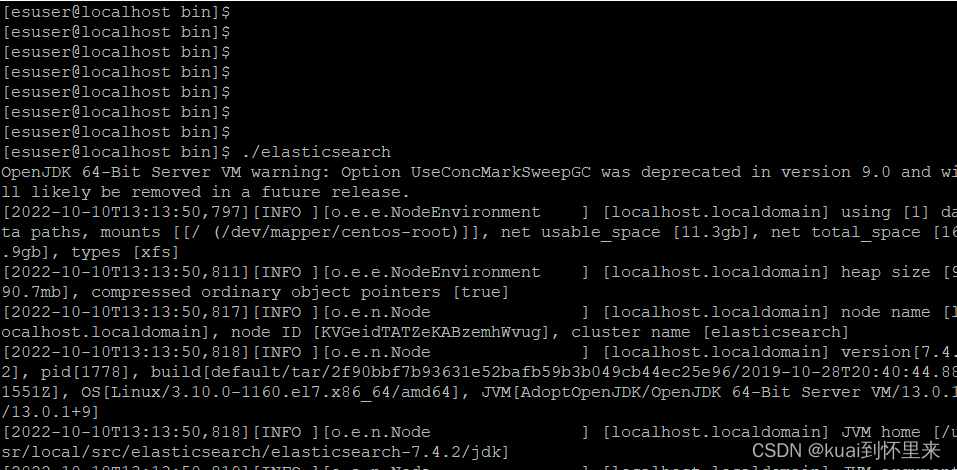
前台启动命令
./elasticsearch
后台启动命令
./elasticsearch -d
查看启动日志
tail -f ../logs/elasticsearch.log
在这里启动后只能linux里访问,并且windows访问不了,所以还需要一下配置
开放端口
系统文件修改
开放9200端口:修改esuser目录下的文件内容,可以使用esuser用户,修改其他系统文件,或者其他系统权限命令,切换成root
修改配置文件,开放端口访问
切换到config目录下
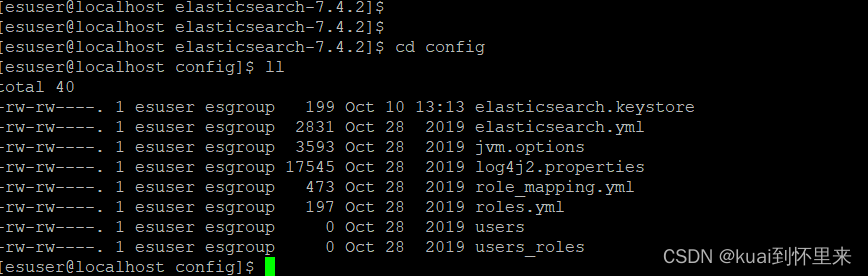
vi elasticsearch.yml
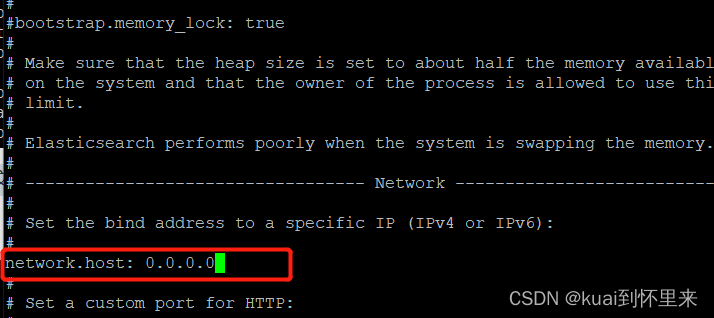
修改完后启动,启动失败
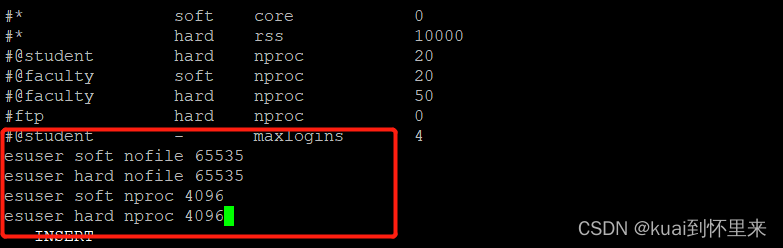
修改系统配置
满足最小启动要求
vi /etc/security/limits.conf
文档末尾添加
esuser soft nofile 65535
esuser hard nofile 65535
esuser soft nproc 4096
esuser hard nproc 4096
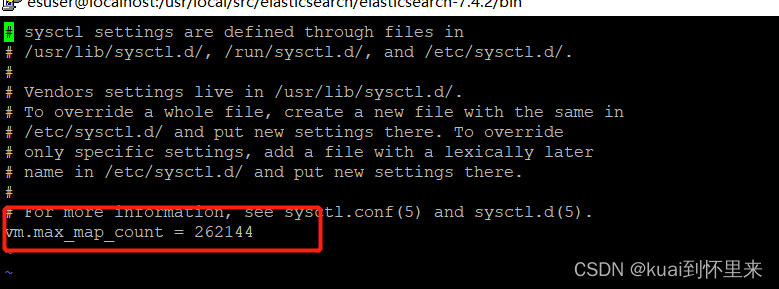
修改虚拟内存
vi /etc/sysctl.conf
在末尾添加:
vm.max_map_count = 262144
刷新配置
sysctl -p

修改集群IP配置
没有用集群,一个节点也要配置一个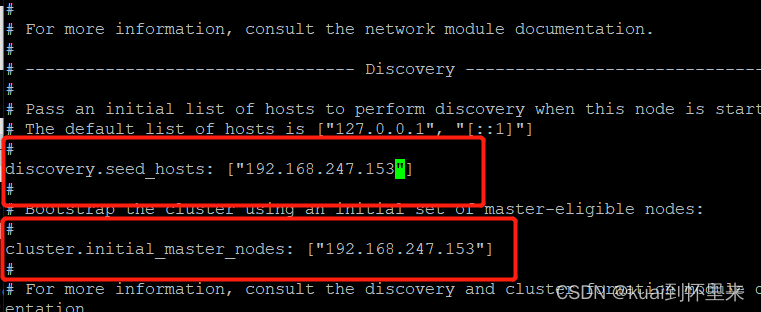
JVM配置
vi ../config/jvm.options
添加
-Xms512m
-Xmx512m
注释 -XX:+UseConcMarkSweepGC
添加
-XX:+UseG1GC
再次启动
切换用户
su esuser
运行启动命令
前台启动
./elasticsearch
后台启动
./elasticsearch -d
开放防火墙端口
ES会占用9200,和9300端口,9200是外部连接通信端口,9300是软件内部通信端口,开放9200就行
firewall-cmd --zone=public --add-port=9200/tcp --permanent
firewall-cmd --reload

测试
shell命令访问
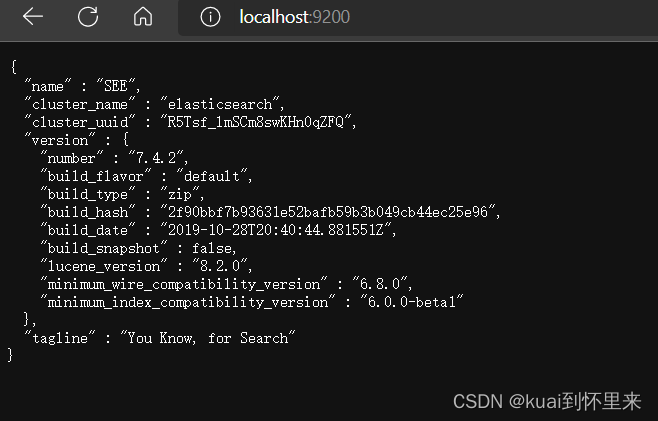
curl http://localhost:9200
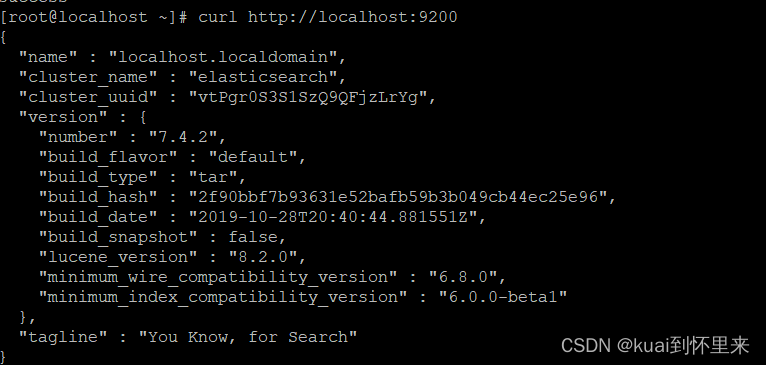
windows浏览器访问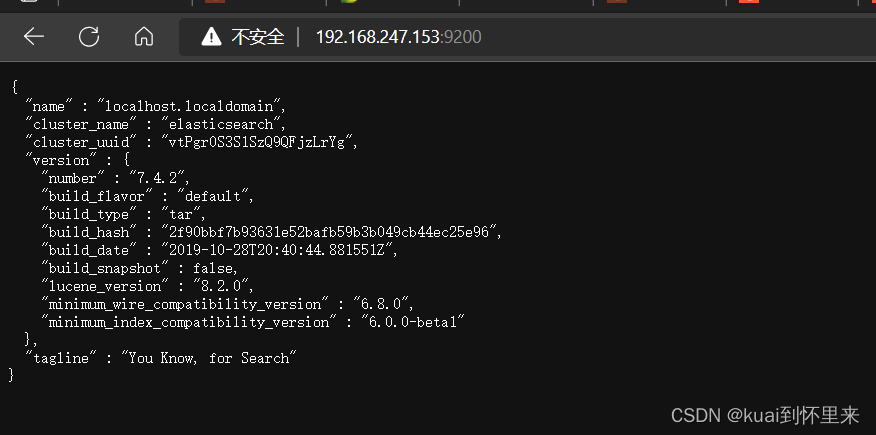
Windows
配置
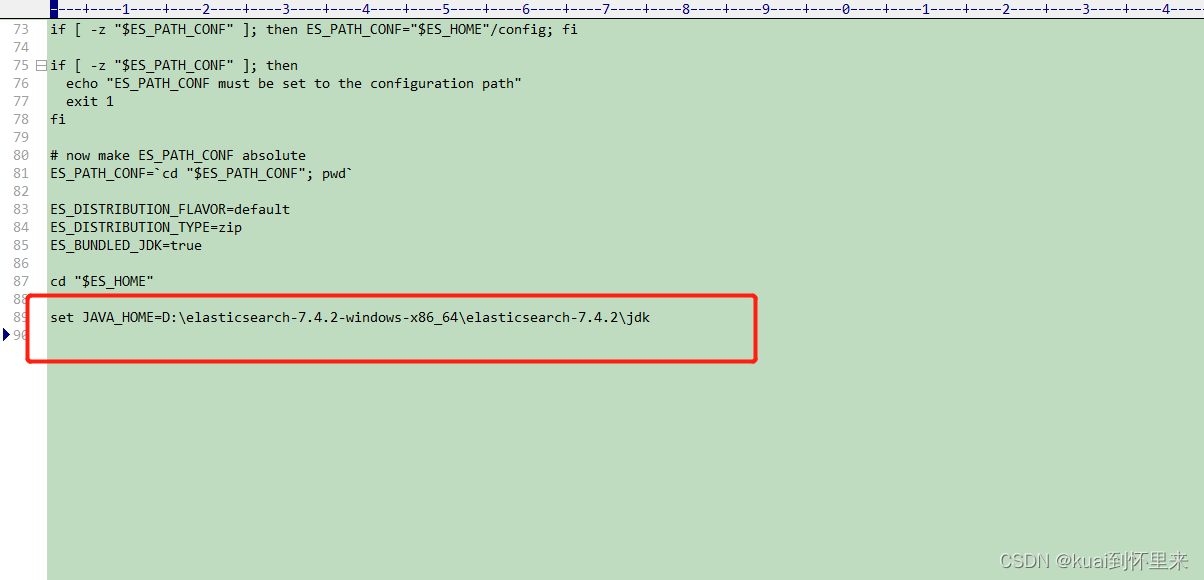
解压 、在elasticsearch-7.4.2\bin 下 elasticsearch-env添加JDK路径
set JAVA_HOME=D:\elasticsearch-7.4.2-windows-x86_64\elasticsearch-7.4.2\jdk
启动
访问
elasticsearch-head-master安装
Linux
新建文件夹
上传压缩包
安装node.js
安装之前需要安装node.js
上传node.js 解压
tar -xvf node-v13.14.0-linux-x64.tar.xz
配置环境变量
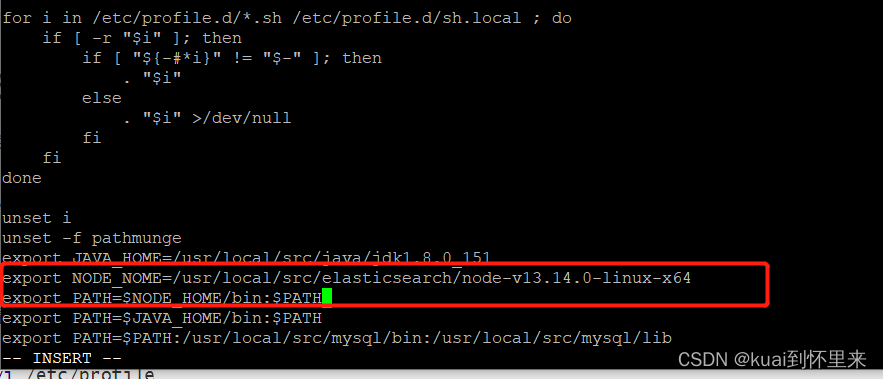
vi /etc/profile
在末尾添加以下配置
export NODE_NOME=/usr/local/src/elasticsearch/node-v13.14.0-linux-x64
export PATH=$NODE_NOME/bin:$PATH
刷新环境变量
source /etc/profile
修改npm下载镜像路径
查看当前计算机的下载地址
npm get registry修改为淘宝npm镜像
npm config set registry http://registry.npm.taobao.org/修改为cnpmjs镜像
npm config set registry http://r.cnpmjs.org/
安装head
解压
unzip elasticsearch-head-master.zip
修改配置文件
windows访问
cd elasticsearch-head-master
vi Gruntfile.js
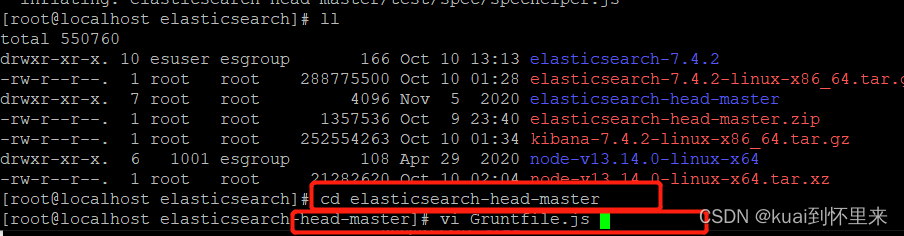
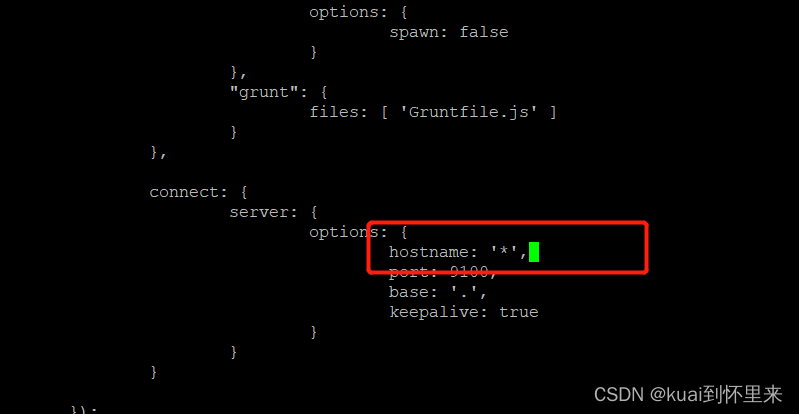
找到位置添加
hostname: ‘*’,
安装项目
npm install
安装出错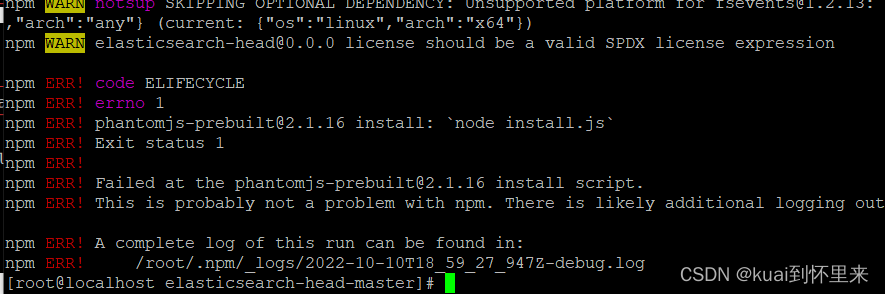
单独安装插件
npm install phantomjs-prebuilt@2.1.16 --ignore-script
再次运行
安装
npm install
运行
#前台
npm run start
#后台
npm run start &

防火墙开放9100端口
firewall-cmd --zone=public --add-port=9100/tcp --permanent
firewall-cmd --reload
windows访问
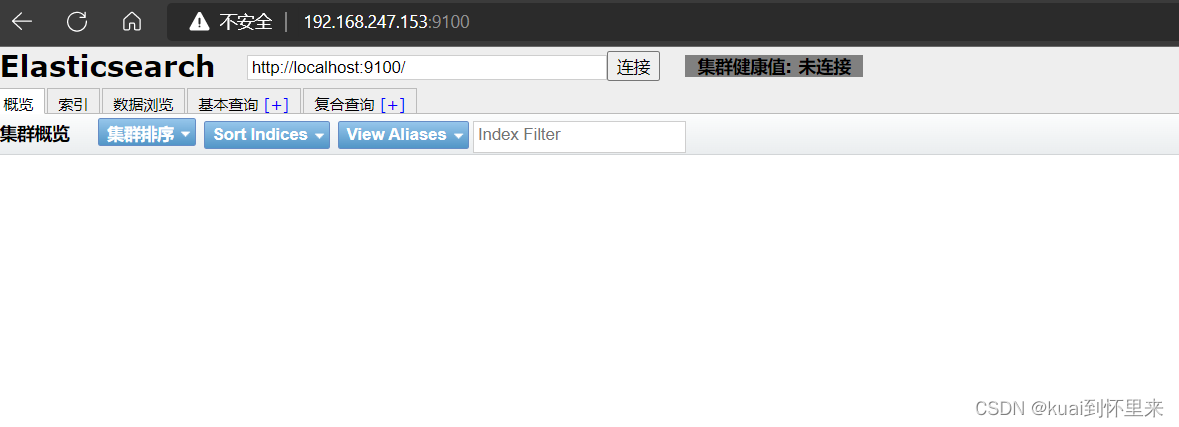
配置ES运行跨域访问
cd /usr/local/src/elasticsearch/elasticsearch-7.4.2/config
vi elasticsearch.yml
文件末尾添加
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
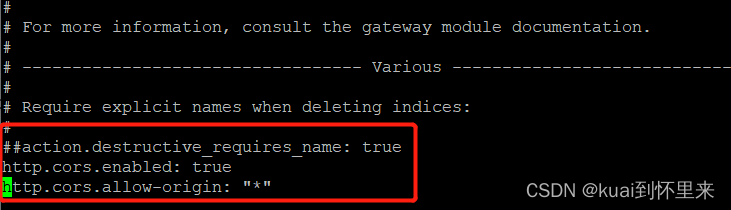
重启elasticsearch
启动运行项目 npm run start连接
出现以下说明配置成功!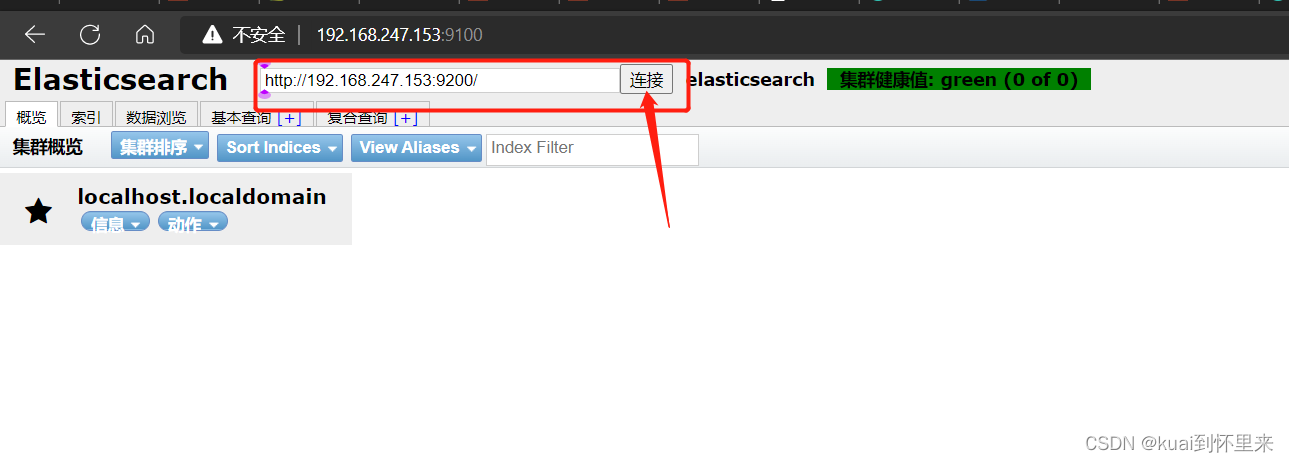
Windows安装
解压
npm install
npm run start
ES配置跨域
使用Chorm浏览器Head插件
Kinaba安装
Linux
上传文件解压
解压
tar -zxvf kibana-7.4.2-linux-x86_64.tar.gz
修改配置
cd kibana-7.4.2-linux-x86_64
vi config/kibana.yml
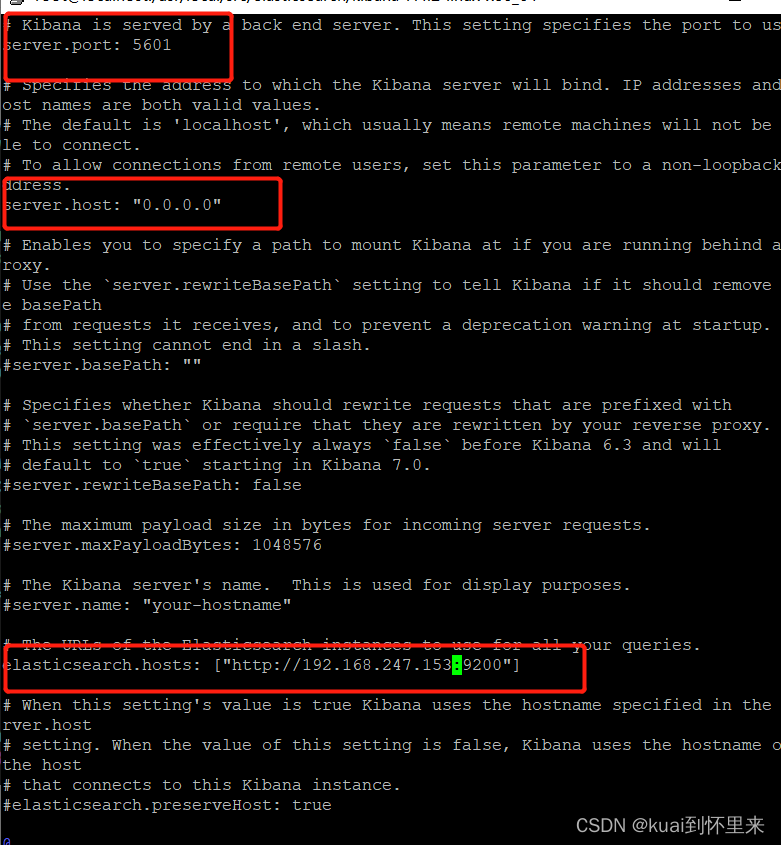
开放端口5601
firewall-cmd --zone=public --add-port=5621/tcp --permanent
firewall-cmd --reload
启动
后台启动 nohup 命令名 &
nohup ./bin/kibana --allow-root &
测试
windows访问
windows
解压运行
中文分词器安装
linux
上传
上传到elasticsearch的安装目录下的plugins文件夹中,新建ik文件夹将压缩放进去解压
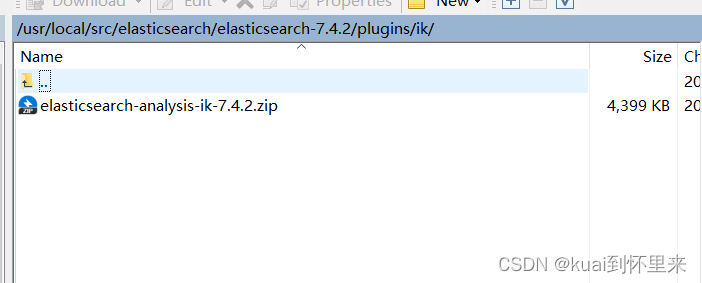
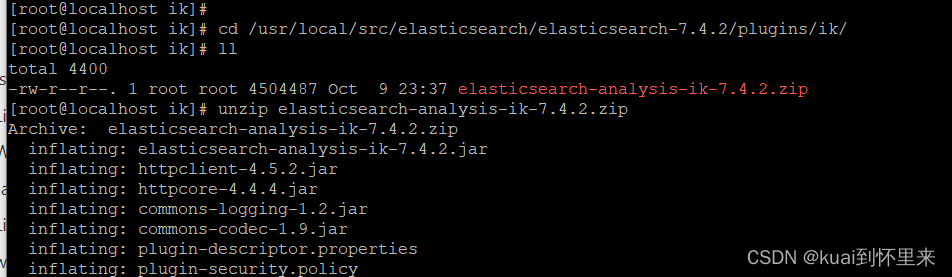
解压
unzip elasticsearch-analysis-ik-7.4.2.zip
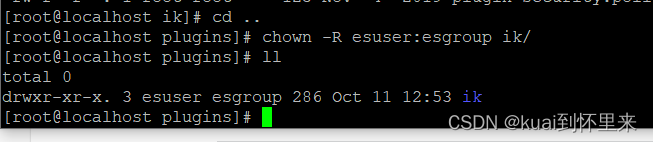
赋权
给解压后的文件夹赋权限
chown -R esuser:esgroup ik/
windows
在elasticsearch的安装目录下找到plugins文件夹,新建ik文件夹将压缩放进去解压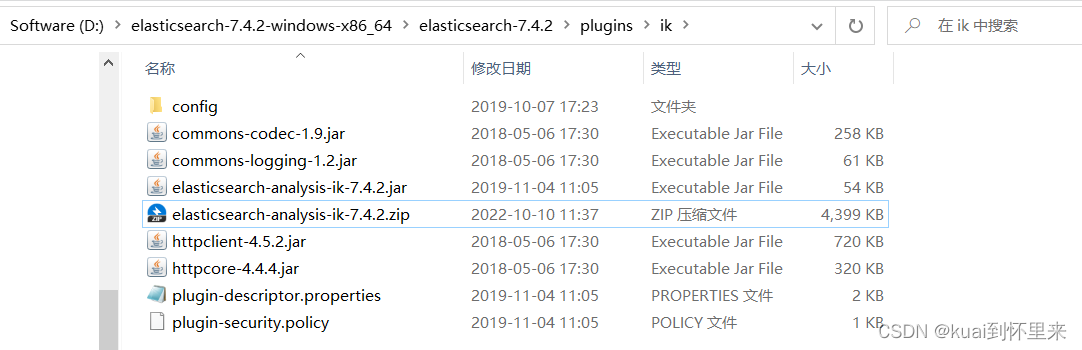
测试:
项目中,创建索引,创建mapping。导入数据
- 创建索引
- 创建mapping
- 导入数据
如果先导入数据后创建mapping,分词器将不生效!!!
#创建索引
PUT /index
# 创建映射:指定字段的分词规则
# 给要分词查询的content列,创建分词规则
# type 字段类型
# analyzer 创建索引使用的分词器
# search_analyzer 执行搜索时使用的分词器
POST /index/_mapping
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
#添加数据,自定义主键
#重复执行,就是修改
POST /index/_doc/1
{
"sid":"1",
"content":"test"
}
POST /index/_doc/2
{
"sid":"2",
"content":"数据"
}
POST /index/_doc/3
{
"sid":"3",
"content":"数据结构与算法"
}
POST /index/_doc/4
{
"sid":"4",
"content":"Java编码技术"
}
POST /index/_doc/5
{
"sid":"5",
"content":"你不知道的JavaScript"
}
# 查询
POST /index/_search
{
"query" : { "match" : { "content" : "数据" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
自定义字典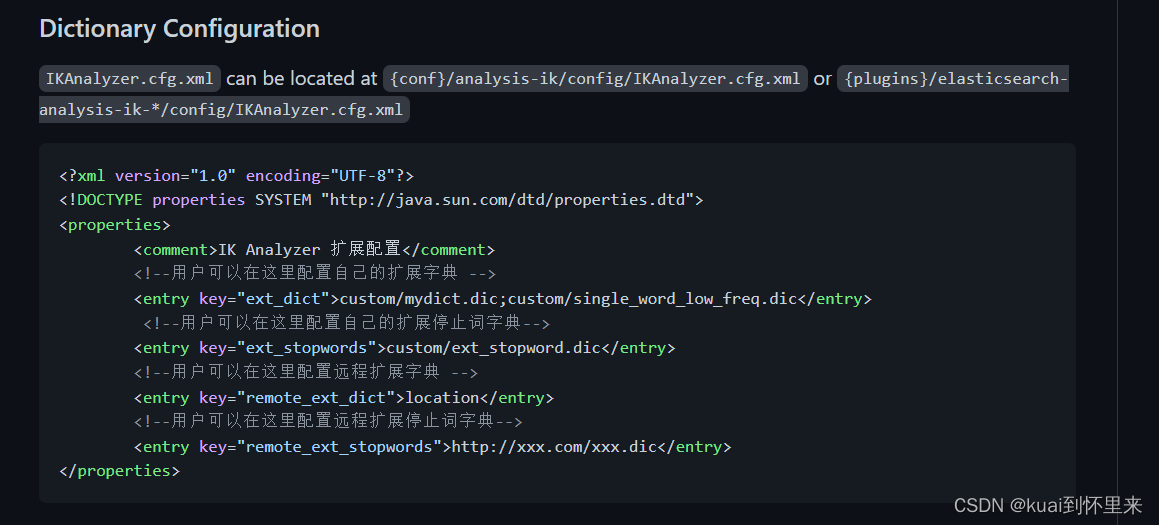
其他配置请移步GitHub!
Logstash安装
linux
上传
解压
unzip logstash-7.4.2.zip
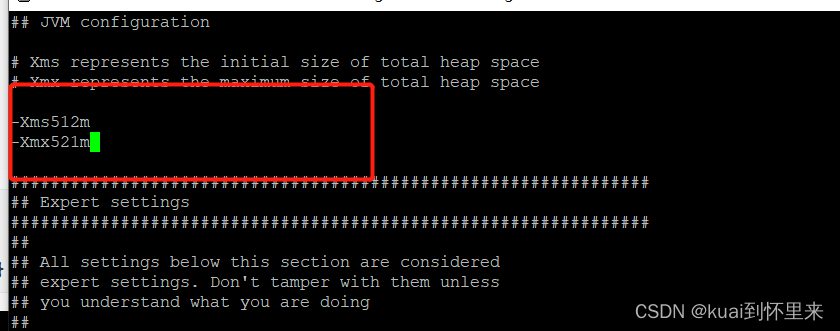
修改参数
cd logstash-7.4.2/config/
vi jvm.options
将原来的1g 改为了512m,可以根据实际情况调整
测试
# Windows必须是"",
logstash -e "input{stdin{}} output{stdout{}}"
# Linux可以''
./logstash -e "input{stdin{}} output{stdout{}}"
启动成功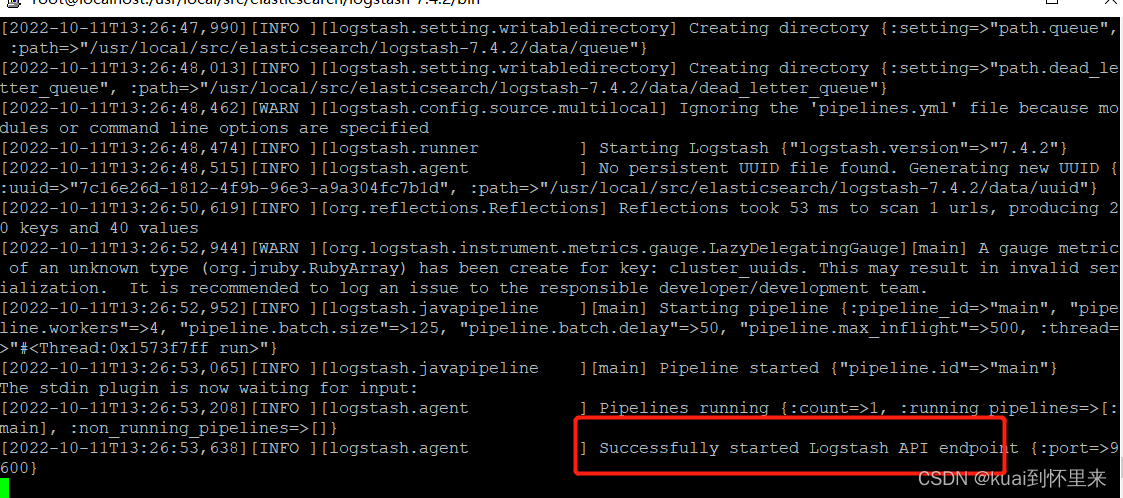
输入aaa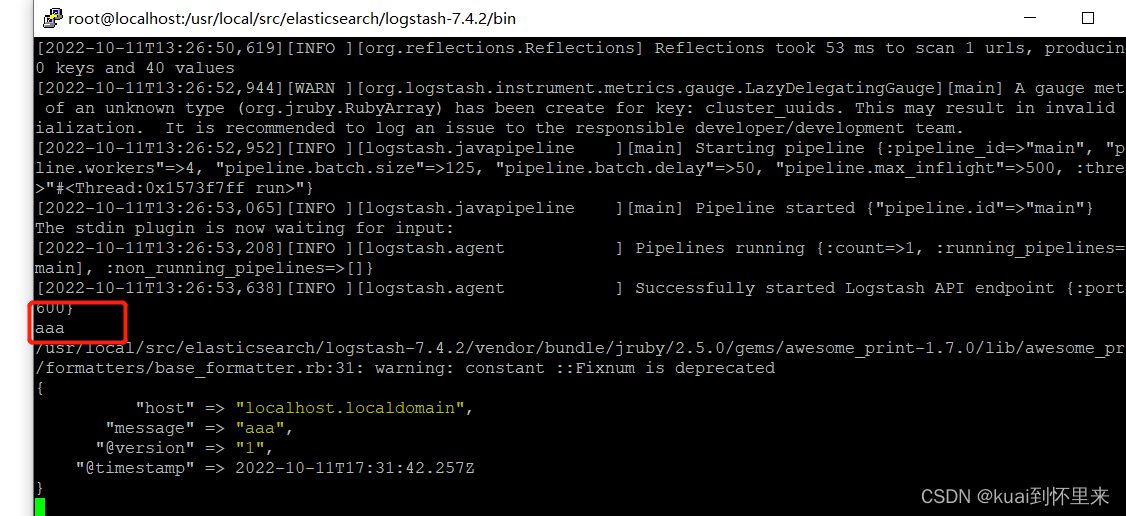
将数据库表中的数据导入
添加mysqljdbc驱动jar包
logstash-7.4.2\logstash-core\lib\jars
根据mysql版本选择对应版本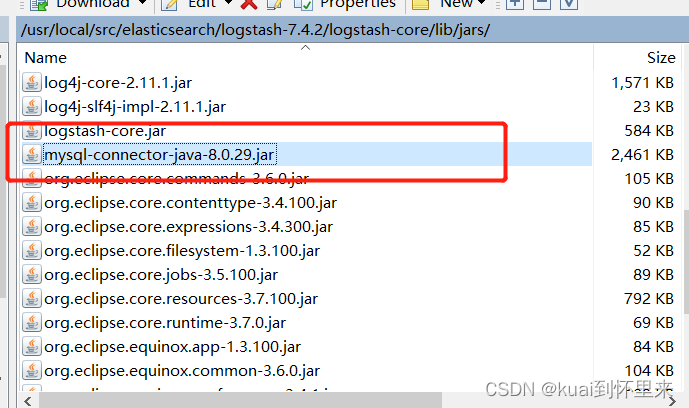
配置文件以下以windows为列:
导入单个表数据,新建配置文件 user.conf
input {
stdin {
}
jdbc {
jdbc_connection_string => "jdbc:mysql://localhost:3306/rbac"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_user => "root"
jdbc_password => "root"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#要执行的sql文件
#statement_filepath => "/usr/local/src/elasticsearch/logstash-7.4.2/config/customer.sql"
statement_filepath => "D:\logstash-7.4.2\logstash-7.4.2\config\emp.sql"
#statement => "select from "
#定时字段各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
}
}
output {
elasticsearch {
#ESIP地址与端口
#hosts => "localhost:9200"
hosts => ["localhost:9200"]
#ES索引名称
index => "rbac"
#文档_id, %{cid}意思是取查询出来的cid的值,并将其映射到es的_id字段中
document_id => "%{id}"
}
stdout {
# JSON格式输出
codec => json_lines
}
}
新建sql文件, emp.sql
SELECT * FROM oa_emp;
将文件放入config文件夹中
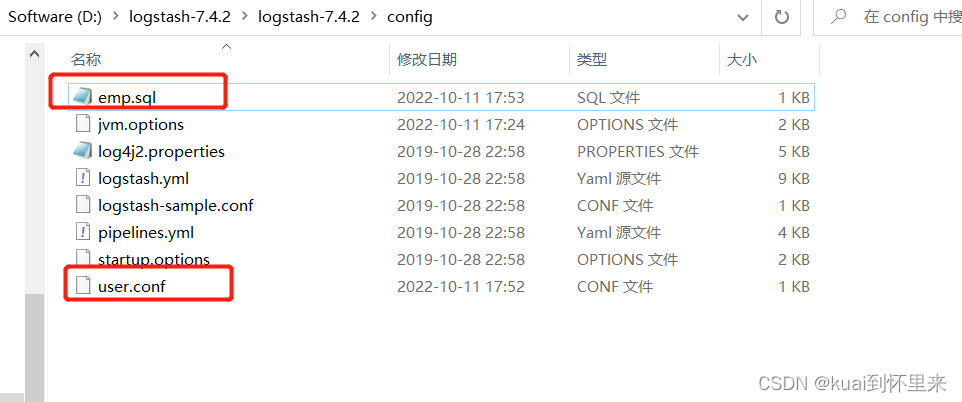
检查配置文件
logstash -f D:\logstash-7.4.2\logstash-7.4.2\config\user.conf -f
启动
logstash -f D:\logstash-7.4.2\logstash-7.4.2\config\user.conf
出现以下界面就说明成功,并且也建立了索引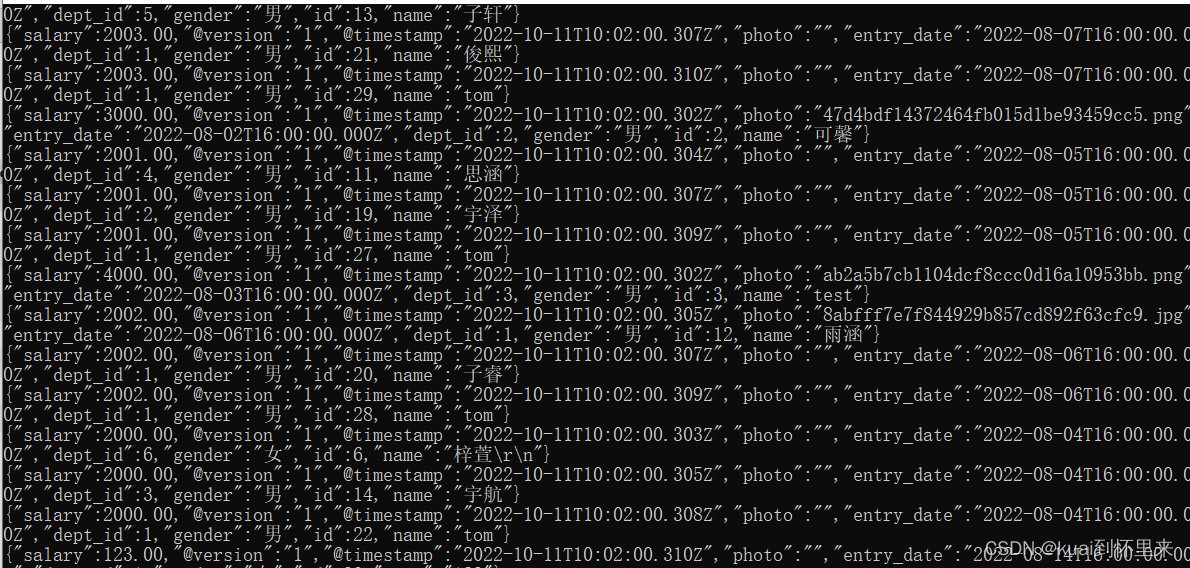
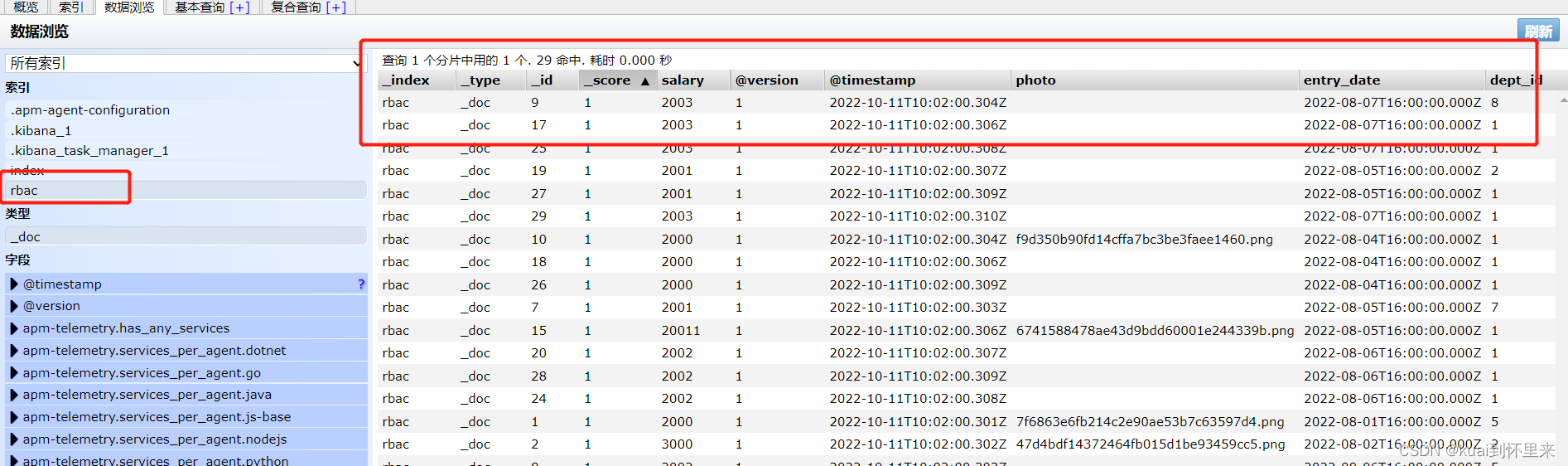
测试中文分词器
#删除原来的索引
DELETE /rbac
#创建索引
PUT /rbac
#创建分词映射
POST /rbac/_mapping
{
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
重启 Logstash
logstash -f D:\logstash-7.4.2\logstash-7.4.2\config\user.conf
测试
# 查询
POST /rbac/_search
{
"query" : { "match" : { "name" : "编码" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"name" : {}
}
}
}
数据库中的数据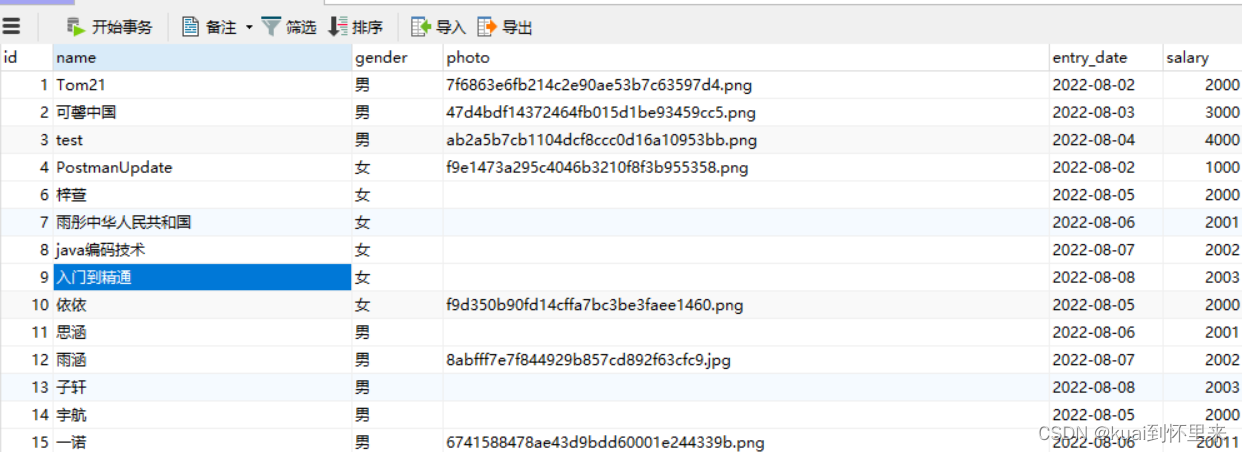
查询结果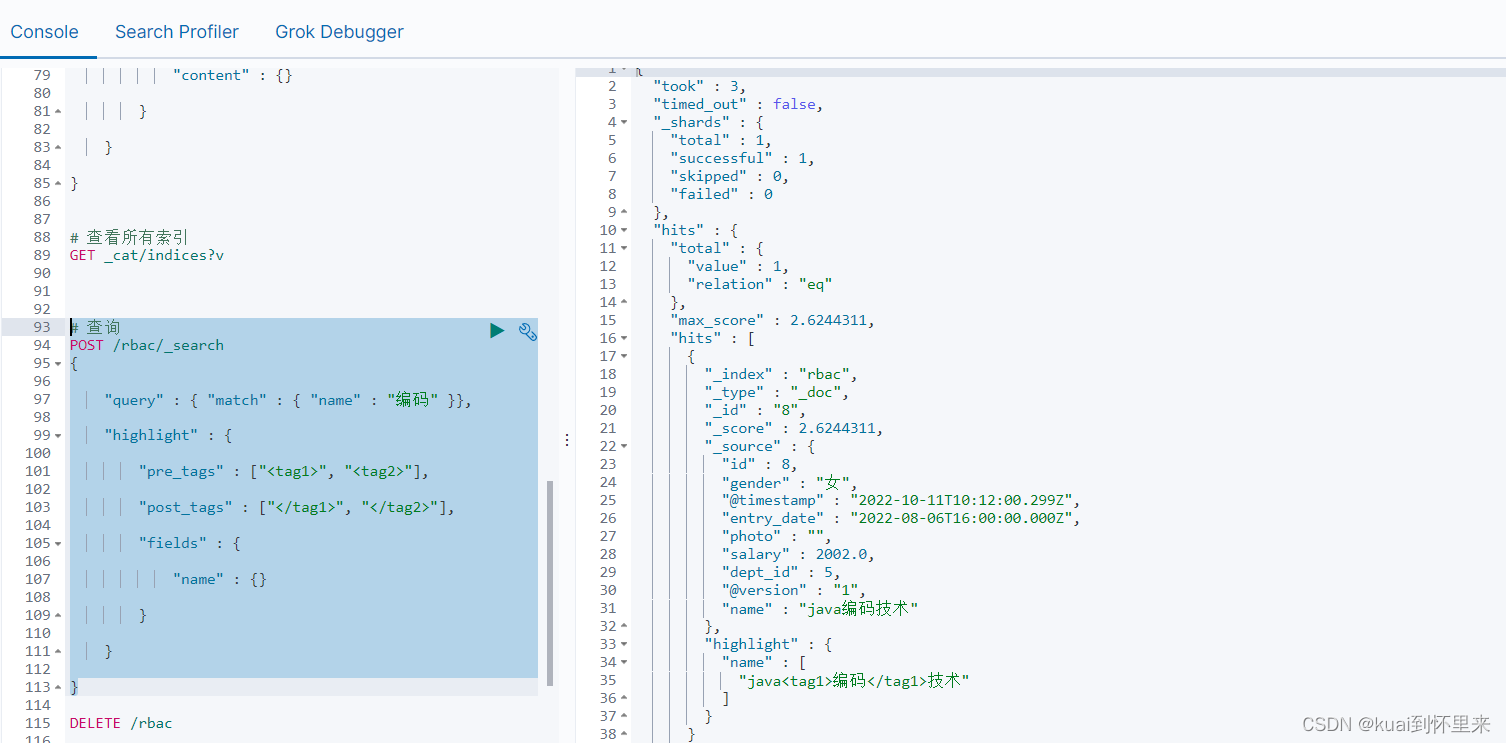
以上是单个表,想导入多个表需要修改配置文件,编写SQL,SQL语句可以有多份
input {
stdin {
}
jdbc {
jdbc_connection_string => "jdbc:mysql://192.168.2.164:3306/customers"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_user => "root"
jdbc_password => "123"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#要执行的sql文件
statement_filepath => "/usr/local/src/elasticsearch/logstash-7.4.2/config/customer.sql"
#statement => "select from "
#定时字段各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
type => "customer"
}
jdbc {
jdbc_connection_string => "jdbc:mysql://192.168.2.164:3306/customers"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_user => "root"
jdbc_password => "123"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#要执行的sql文件
#statement_filepath => "/usr/local/src/elasticsearch/logstash-7.4.2/config/customer.sql"
statement => "select * from province"
#定时字段各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
type => "province"
}
}
output {
if[type] == "customer"{
elasticsearch {
#ESIP地址与端口
#hosts => "localhost:9200"
hosts => ["localhost:9200"]
#ES索引名称
index => "customer"
#文档_id, %{cid}意思是取查询出来的cid的值,并将其映射到es的_id字段中
document_id => "%{cid}"
}
}
if[type] == "province"{
elasticsearch {
#ESIP地址与端口
#hosts => "localhost:9200"
hosts => ["localhost:9200"]
#ES索引名称
index => "province"
#文档_id, %{cid}意思是取查询出来的cid的值,并将其映射到es的_id字段中
document_id => "%{pid}"
}
}
stdout {
# JSON格式输出
codec => json_lines
}
}
windows
与linux一样,见linux安装步骤
elasticsearch常用指令
索引
# 添加索引
PUT /test1
# 查看索引
GET /test1
# 删除索引
DELETE /test1
# 创建索引,指定分片和副本
PUT /test
{
"settings" : {
"index" : {
"number_of_shards" : "1",
"number_of_replicas" : "0"
}
}
}
# 查看所有索引
GET _cat/indices?v
文档操作
# 添加索引
PUT /test1
# 查看索引
GET /test1
# 删除索引
DELETE /test1
# 创建索引,指定分片和副本
PUT /test
{
"settings" : {
"index" : {
"number_of_shards" : "1",
"number_of_replicas" : "0"
}
}
}
# 查看所有索引
GET _cat/indices?v
#添加数据,系统自动生产主键
#可以重复执行,生成新的主键,新添加数据,
POST /test/_doc/
{
"sid":"3",
"sname":"bbb"
}
#添加数据,自定义主键
#重复执行,就是修改
POST /test/_doc/4
{
"sid":"4",
"sname":"cccc",
"age":"11"
}
# PUT有幂等性检查,必须指定主键
#重复执行,就是修改
PUT /test/_doc/5
{
"sid":"5",
"sname":"555"
}
#添加数据,不能重复执行
POST /test/_create/6
{
"sid":"6",
"sname":"666"
}
#添加数据,不能重复执行
PUT /test/_create/7
{
"sid":"7",
"sname":"777"
}
# 可以自定义Type名字,一个Index只能有一个,不推荐
PUT test1
POST /test1/t1/1
{
"sid":"1",
"sname":"111"
}
DELETE test1
#查看数据
GET /test/_doc/1
GET /test/_doc/9Bv7xIMBwpvweq10UVG6
#删除数据
DELETE /test/_doc/9Bv7xIMBwpvweq10UVG6
#查询全部
GET /test/_search
查询
#查询全部
GET /test/_search
GET /test/_search
{
"query": {
"match_all": {}
}
}
# 查询指定字段的值
GET /test/_search
{
"query": {
"match": {
"age": "9"
}
}
}
# 多列匹配
GET /test/_search
{
"query": {
"multi_match": {
"query": "1",
"fields": ["sid","sname","age"]
}
}
}
# 分页
GET /test/_search
{
"query": {
"match_all": {}
},
"from": "2",
"size": "2"
}
# must
GET /test/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"age": "9"
}
}
]
}
}
}
# must and
GET /test/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"age": "9"
}
},
{
"match": {
"sname": "1xxx"
}
}
]
}
}
}
# should or
GET /test/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"age": "9"
}
},
{
"match": {
"sname": "bbb"
}
}
]
}
}
}
# 范围查询
GET /test/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"sname": "aaa"
}
}
],
"filter": {
"range": {
"age": {
"gte": 12
}
}
}
}
}
}
# 高亮显示
GET /test/_search
{
"query": {
"match": {
"sname": "aaa"
}
},
"highlight": {
"fields": {
"sname":{}
}
}
}
# 自定义标签
GET /test/_search
{
"query": {
"match": {
"sname": "aaa"
}
},
"highlight": {
"pre_tags": "<font color='red'>",
"post_tags": "</font>",
"fields": {
"sname":{}
}
}
}