目录
1、查询列并进行运算
select 列值(进行加减乘除) from 表名
select age+3,name from t_student;
select age*3,name from t_student;这个特性可以使那些通过计算可以得到的列,就不必进行设计了
create table t_order(
orderno int primary key,
name varchar(20),
price DECIMAL(7,2),
num int
-- total decimal(7,2) -- 这里没有必要再定义总价因为
)
select orderno,name,price,num,price*num total from t_order;
2、聚合函数
SQL 结构化查询语言 也是一种编程语言,所以也有函数 并且有 内置函数(官方) 和自定义函数(程序员)
聚合函数总共有5个:
max(列名):求某列的最大值。
min(列名):求某列的最小值。
sum(列名):求某列的和
avg(列名):求某列的平均值
count(列名):求某列的个数。
-- 求最大的年龄
select max(age) from t_student;
-- 求最小的年龄
select min(age) from t_student;
-- 求年龄的和
select sum(age) from t_student;
-- 求学生的个数.
select count(id) from t_student;
-- 求年龄平局值
select avg(age) from t_student;
count(列名) count(1)表中第1列但是它不能使用distinct去重 count(*)表中所有列 统计记录条数 这三个有啥区别
select count(distinct name),count(2),count(*) from t_student;
3、分组查询
在sql中有个 group by 语句 将某一列相同数据 视为一组 然后进行查询 与聚合函数连用。
-- 求各个地区的人数
select count(*),address from t_student group by address;
-- 查询 各个地区的平均年龄
select avg(age),address from t_student group by address;
可以使用 having 对分组进行条件检索。
查询 平均年龄大于30的地区人数
select address,count(*),avg(age) from t_student group by address having avg(age)>30;
注意: 如果使用了group by 那么select后只能跟分组的条件列和聚合函数
select id,address,count(*),avg(age),max(age) from t_student group by address having max(age)<30;
这种是错误的,因为select后根了id 而id不是分组的条件。4、分页查询
当数据库表数据量比较大 例如: 1000w行数据 如果我们执行 select * from student 此时有可能数据库卡死 -- 拿出1000w数据到内存里,你的内存可能会不够。导致电脑卡死。
如果在java中 有可能使内存直接溢出 所以实际开发中 都是分页查询 (部门查询)
分页使用: limit
select * from student limit 3,5; //从第4条记录开始输出 查询5条
--- 分页:
select * from 表名 limit (n-1)*m,m; -- 查询第n页得m条记录。
-- n表示页码 m:表示每页得条数,
-- 第1页每页显示5条记录:
select * from t_student limit 0,5;
-- 第2页每页显示5条记录:
select * from t_student limit 5,5;
-- 第3页每页显示5条记录:
select * from t_student limit 10,5;5、sql得优先级
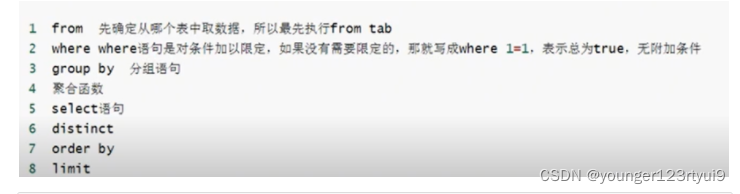
例:select name as n,age as b from student where b>15;
错误原因:因为再执行where时,还没有执行select 所以程序找不到b。