Python数据科学手册
3.Pandas数据处理
3.1 安装并使用Pandas
5.机器学习
机器学习的本质就是,借助数学模型理解数据
5.1 什么是机器学习
5.1.1 机器学习的分类
- 有监督学习:对数据的若干特征与若干标签(类型)之间的关联性进行建模的过程
- 分类:标签为离散值的有监督学习
- 回归:标签为连续值的有监督学习
- 无监督学习:对不带任何标签的数据特征进行建模,通常被看成是一种“让数据自己介绍自己”的过程。
- 聚类:检测、识别数据显著组别的模型
- 降维:从高维数据中检测、识别低维数据结构的模型
- 半监督学习:介于有监督学习与无监督学习之间。半监督学习方法通常可以在数据标签不完整时使用。
5.1.2 机器学习应用的定性示例
- 分类:预测离散标签

一个训练有素的分类算法只要具备足够好的特征(通常是成千上万个词或短语),就能非常高效地进行分类 - 回归:预测连续标签

- 聚类:为无标签数据添加标签

- 降维:推断无标签数据的结构

5.2 Scikit-Learn简介
5.2.1 Scikit-Learn的数据表示
数据表

将矩阵的行称为样本(samples),行数记为 n_samples
矩阵的列称为特征(features),列数记为 n_features特征矩阵
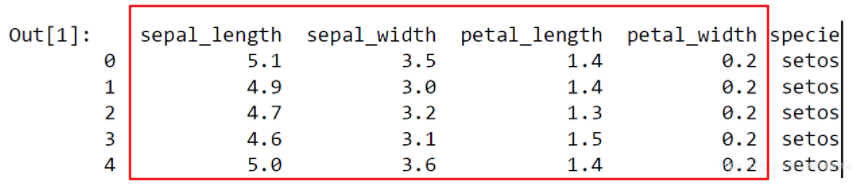
特征矩阵通常被简记为变量 X。它是维度为 [n_samples,n_features] 的二维矩阵
样本(即每一行)通常是指数据集中的每个对象。
特征(即每一列)通常是指每个样本都具有的某种量化观测值。目标数组
目标数组通常简记为 y,一般是一维数组,其长度就是样本总数n_samples,可以是连续的数值类型,也可以是离散的类型 / 标签。
目标数组的特征通常是我们希望从数据中预测的量化结果;借用统计学的术语,y 就是因变量。
5.2.2 Scikit-Learn的评估器API
| Scikit-Learn的API设计原则 | |
|---|---|
| 统一性 | 所有对象使用共同接口连接一组方法和统一的文档。 |
| 内省 | 所有参数值都是公共属性。 |
| 限制对象层级 | 只有算法可以用 Python 类表示。数据集都用标准数据类型(NumPy 数组、Pandas DataFrame、SciPy 稀疏矩阵)表示,参数名称用标准的 Python 字符串。 |
| 函数组合 | 许多机器学习任务都可以用一串基本算法实现,Scikit-Learn 尽力支持这种可能。 |
| 明智的默认值 | 当模型需要用户设置参数时,Scikit-Learn 预先定义适当的默认值。 |
API基础知识
Scikit-Learn 评估器 API 的常用步骤:
(1) 通过从 Scikit-Learn 中导入适当的评估器类,选择模型类。
(2) 用合适的数值对模型类进行实例化,配置模型超参数(hyperparameter)。
(3) 整理数据,通过前面介绍的方法获取特征矩阵和目标数组。
(4) 调用模型实例的 fit() 方法对数据进行拟合。
(5) 对新数据应用模型:
在有监督学习模型中,通常使用 predict() 方法预测新数据的标签;
在无监督学习模型中,通常使用 transform() 或 predict()方法转换或推断数据的性质。有监督学习示例:简单线性回归
版权声明:本文为adamlay原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。