1.股票预测概述
股票预测我分了两大部分,第一个是模型训练,第二个是模型预测,模型训练中我又分成数据读取、特征选择、模型训练三个部分。
- 模型训练
- 数据读取
- 特征选择
- 模型训练
- 模型预测
项目的目录截图如下: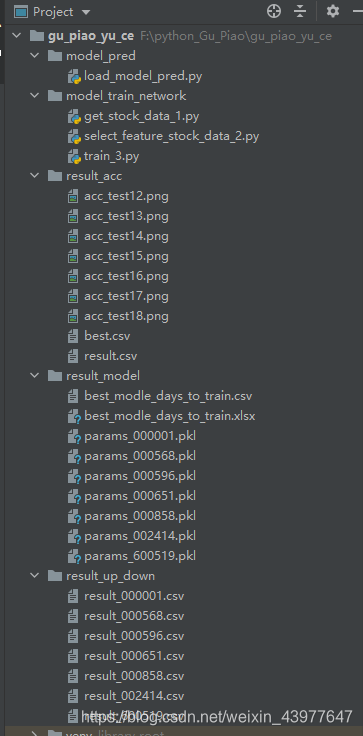
model_pred:存放的是预测执行的代码
model_train_network:存放的是股票的数据获取以及模型构造和训练
result_acc:存放的是训练过程中不同参数所绘制的loss和accuracy随训练次数变化的图像
result_model:存放的是模型训练在test下准确率最高的模型和此时参数的取值
result_up_down:存放的是预测一段时间中股票走势的结果
2.模型训练
2.1数据读取
模型训练: 我的想法是通过股票前n天的数据去预测股票五天之后的涨跌,因为我觉得买股票不应该只看后面一天的股价变化,所以我这里选择了五天之后的股价。
我这里约定
涨:五天之后股价的最小值比五天前股价的最大值要高
跌:五天之后股价的最大值比五天前股价的最小值要低
平:其余的情况
股票数据收集: 这里股票数据收集采用 http://baostock.com/baostock/index.php/
数据处理: 这里选择days_to_train=20,days_to_pred=5,来表示用20天的股票数据来预测第25天的股价涨跌,在数据处理中去掉不需要的数据。
import baostock as bs
import pandas as pd
import numpy as np
def get_data(stock_id='hz.600000', days_to_train=20, days_to_pred=5, start_data='2019-12-15', end_date='2020-12-15'):
# 需要用20天的数据去预测未来五天的数据
# days_to_train = 20
# days_to_pred = 5
# 登陆系统
lg = bs.login()
# 显示登陆返回信息
print('login respond error_code:' + lg.error_code)
print('login respond error_msg:' + lg.error_msg)
# 获取沪深A股历史K线数据
# 参数说明:http://baostock.com/baostock/index.php/Python_API%E6%96%87%E6%A1%A3#.E8.8E.B7.E5.8F.96.E5.8E.86.E5.8F.B2A.E8.82.A1K.E7.BA.BF.E6.95.B0.E6.8D.AE.EF.BC.9Aquery_history_k_data_plus.28.29
rs = bs.query_history_k_data_plus(stock_id,
"date,code,open,high,low,close,preclose,volume,amount,turn,tradestatus,pctChg,peTTM,pbMRQ,psTTM,pcfNcfTTM,isST",
start_date=start_data, end_date=end_date,
frequency="d", adjustflag="1")
print('query_history_k_data_plus respond error_code:' + rs.error_code)
print('query_history_k_data_plus respond error_msg:' + rs.error_msg)
# 打印结果集
data_list = []
while (rs.error_code == '0') & rs.next():
# 获取一条记录,将记录合并在一起
data_list.append(rs.get_row_data())
result = pd.DataFrame(data_list, columns=rs.fields)
# 登出系统
bs.logout()
# 处理结果
columns_all = result.columns
columns_need = columns_all[2:-1]
data_need = result[columns_need]
column_low = 'low'
column_high = 'high'
# labels用于记录股票在五天的时候是涨是跌
# 涨:2
# 平:1
# 跌:0
labels = []
# train_data用于记录上述分类中使用的训练数据
train_data = []
for day in data_need.sort_index(ascending=False).index:
day_pred_low = data_need.loc[day][column_low]
day_pred_high = data_need.loc[day][column_high]
if not (day - days_to_train - days_to_pred + 1 < 0):
day_before_low = data_need.loc[day - days_to_pred][column_low]
day_before_high = data_need.loc[day - days_to_pred][column_high]
if day_pred_low > day_before_high:
labels.append(2)
elif day_pred_high < day_before_low:
labels.append(0)
else:
labels.append(1)
train_data.append(data_need.loc[day - days_to_pred - days_to_train + 1:day - days_to_pred])
return train_data, labels
def get_data_pred(stock_id='hz.600000', days_to_train=20, days_to_pred=5, start_data='2020-10-16', end_date='2020-12-16'):
# 需要用20天的数据去预测未来五天的数据
# days_to_train = 20
# days_to_pred = 5
# 登陆系统
lg = bs.login()
# 显示登陆返回信息
print('login respond error_code:' + lg.error_code)
print('login respond error_msg:' + lg.error_msg)
# 获取沪深A股历史K线数据
# 参数说明:http://baostock.com/baostock/index.php/Python_API%E6%96%87%E6%A1%A3#.E8.8E.B7.E5.8F.96.E5.8E.86.E5.8F.B2A.E8.82.A1K.E7.BA.BF.E6.95.B0.E6.8D.AE.EF.BC.9Aquery_history_k_data_plus.28.29
rs = bs.query_history_k_data_plus(stock_id,
"date,code,open,high,low,close,preclose,volume,amount,turn,tradestatus,pctChg,peTTM,pbMRQ,psTTM,pcfNcfTTM,isST",
start_date=start_data, end_date=end_date,
frequency="d", adjustflag="1")
print('query_history_k_data_plus respond error_code:' + rs.error_code)
print('query_history_k_data_plus respond error_msg:' + rs.error_msg)
# 打印结果集
data_list = []
while (rs.error_code == '0') & rs.next():
# 获取一条记录,将记录合并在一起
data_list.append(rs.get_row_data())
result = pd.DataFrame(data_list, columns=rs.fields)
# 登出系统
bs.logout()
# 处理结果
columns_all = result.columns
columns_need = columns_all[2:-1]
data_need = result[columns_need]
column_low = 'low'
column_high = 'high'
column_date = 'date'
train_data = []
labels = []
date_list = []
for day in data_need.sort_index(ascending=False).index:
day_pred_low = data_need.loc[day][column_low]
day_pred_high = data_need.loc[day][column_high]
if not (day - days_to_train - days_to_pred + 1 < 0):
day_before_low = data_need.loc[day - days_to_pred][column_low]
day_before_high = data_need.loc[day - days_to_pred][column_high]
if day_pred_low > day_before_high:
labels.append(2)
elif day_pred_high < day_before_low:
labels.append(0)
else:
labels.append(1)
if (day - days_to_train + 1) < 0:
pass
else:
print(day)
train_data.append(data_need.loc[day - days_to_train + 1:day])
date_list.append(result[column_date].loc[day])
labels = np.insert(np.array(labels), 0, np.repeat(-1, 5))
return train_data, labels, date_list
2.2特征提取
这里没有正真的特征提取,我觉得就算提取股价时间序列的什么最大值、最小值、陡度等特征还是不能准确表达股价变化,直接在后面的神经网络中采用LSTM或者是GRU等用于处理时间序列的网络来做特征提取,这里我做的特征提取就是所谓的归一化,这里对时间序列中每一个特征做归一化,即对每一列做归一化。
from sklearn import preprocessing
import numpy as np
from model_train_network.get_stock_data_1 import get_data
def norm_data(data):
data_norm = []
scaler = preprocessing.StandardScaler()
data = np.array(data)
for i in range(data.shape[0]):
data_norm.append(scaler.fit_transform(data[i]))
return data_norm
2.3模型训练
网络部分: 异想天开采用残差和GRU相结合的网络结构
split_data: 分开数据,分成训练的和测试的
train: 训练函数
test: 测试函数
对net.train(),net.eval()的操作说明
同时发现,如果不写这两个程序也可以运行,这是因为这两个方法是针对在网络训练和测试时采用不同方式的情况,比如Batch Normalization 和 Dropout。
训练时是正对每个min-batch的,但是在测试中往往是针对单张图片,即不存在min-batch的概念。由于网络训练完毕后参数都是固定的,因此每个批次的均值和方差都是不变的,因此直接结算所有batch的均值和方差。所有Batch Normalization的训练和测试时的操作不同
在训练中,每个隐层的神经元先乘概率P,然后在进行激活,在测试中,所有的神经元先进行激活,然后每个隐层神经元的输出乘P。
# -*- coding:utf-8 -*-
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torch.nn.init as init
from torch.utils import data
from torchvision import transforms
from sklearn.model_selection import train_test_split
from model_train_network.get_stock_data_1 import get_data
from model_train_network.select_feature_stock_data_2 import norm_data
def weight_init(m):
'''
Usage:
model = Model()
model.apply(weight_init)
'''
if isinstance(m, nn.Conv1d):
init.normal_(m.weight.data)
if m.bias is not None:
init.normal_(m.bias.data)
elif isinstance(m, nn.Conv2d):
init.xavier_normal_(m.weight.data)
if m.bias is not None:
init.normal_(m.bias.data)
elif isinstance(m, nn.Conv3d):
init.xavier_normal_(m.weight.data)
if m.bias is not None:
init.normal_(m.bias.data)
elif isinstance(m, nn.ConvTranspose1d):
init.normal_(m.weight.data)
if m.bias is not None:
init.normal_(m.bias.data)
elif isinstance(m, nn.ConvTranspose2d):
init.xavier_normal_(m.weight.data)
if m.bias is not None:
init.normal_(m.bias.data)
elif isinstance(m, nn.ConvTranspose3d):
init.xavier_normal_(m.weight.data)
if m.bias is not None:
init.normal_(m.bias.data)
elif isinstance(m, nn.BatchNorm1d):
m.weight.data.fill_(1)
m.bias.data.zero_()
# init.normal_(m.weight.data, mean=1, std=0.02)
# init.constant_(m.bias.data, 0)
elif isinstance(m, nn.BatchNorm2d):
init.normal_(m.weight.data, mean=1, std=0.02)
init.constant_(m.bias.data, 0)
elif isinstance(m, nn.BatchNorm3d):
init.normal_(m.weight.data, mean=1, std=0.02)
init.constant_(m.bias.data, 0)
elif isinstance(m, nn.Linear):
init.xavier_normal_(m.weight.data)
init.normal_(m.bias.data)
elif isinstance(m, nn.LSTM):
for param in m.parameters():
if len(param.shape) >= 2:
init.orthogonal_(param.data)
else:
init.normal_(param.data)
elif isinstance(m, nn.LSTMCell):
for param in m.parameters():
if len(param.shape) >= 2:
init.orthogonal_(param.data)
else:
init.normal_(param.data)
elif isinstance(m, nn.GRU):
for param in m.parameters():
if len(param.shape) >= 2:
init.orthogonal_(param.data)
else:
init.normal_(param.data)
elif isinstance(m, nn.GRUCell):
for param in m.parameters():
if len(param.shape) >= 2:
init.orthogonal_(param.data)
else:
init.normal_(param.data)
# ------------------------------------
# input_dim:输入的特征维度
# output_dim:输出的特征维度
# drop_out:丢掉RNN层的比例
# n_layers:纵向排列层数
# ------------------------------------
class GRUNet(nn.Module):
def __init__(self, input_dim, output_dim, drop_out, n_layers=None):
super(GRUNet, self).__init__()
# seq_len: 输入序列时间分布上的长度
if n_layers is None:
n_layers = 2
self.gru = nn.GRU(input_dim, output_dim, n_layers, dropout=drop_out if n_layers != 1 else 0, batch_first=True)
self.norm = nn.BatchNorm1d(output_dim)
self.relu = nn.ReLU()
def forward(self, x):
output, hidden = self.gru(x)
output = output.permute(0, 2, 1).contiguous()
x = self.norm(output)
x = x.permute(0, 2, 1).contiguous()
x = self.relu(x)
# print(x.size())
return x
# ---------------------------------------------------#
# 内部堆叠的残差块
# ---------------------------------------------------#
class Resblock(nn.Module):
def __init__(self, input_dim, drop_out, n_layers=None, hidden_dim=None):
super(Resblock, self).__init__()
if n_layers is None:
n_layers = [1, 3]
if hidden_dim is None:
hidden_dim = [input_dim * 2, input_dim * 4]
# self.resblock_1 = GRUNet(input_dim, hidden_dim[0], drop_out if n_layers[0] != 1 else 0, n_layers[0])
# self.resblock_2 = GRUNet(hidden_dim[0], hidden_dim[1], drop_out if n_layers[0] != 1 else 0, n_layers[1])
self.resblock = nn.Sequential(
GRUNet(input_dim, hidden_dim[0], drop_out if n_layers[0] != 1 else 0, n_layers[0]),
GRUNet(hidden_dim[0], hidden_dim[1], drop_out if n_layers[0] != 1 else 0, n_layers[1])
)
if input_dim != hidden_dim[1]:
self.unify = GRUNet(input_dim, hidden_dim[1], drop_out if n_layers[0] != 1 else 0)
else:
# 通道数相同,无需做变换,在forward中identity = x
self.unify = None
self.relu = nn.ReLU()
def forward(self, x):
identity = x
x = self.resblock(x)
# print('----------------------')
# print(x.size())
if self.unify is not None:
identity = self.unify(identity)
x += identity
x = self.relu(x)
return x
# ---------------------------------------------------#
# 多个堆叠的残差块
# ---------------------------------------------------#
class Resblocks_body(torch.nn.Module):
def __init__(self, block, features_dim, first_output_dim, drop_out):
super(Resblocks_body, self).__init__()
# 初始卷积层核池化层
self.first = GRUNet(features_dim, first_output_dim, drop_out)
self.layer1 = self.make_layer(block, first_output_dim, drop_out, hidden_dim=[32, 64], block_num=1)
# 第2、3、4层,通道数*2,图片尺寸/2
self.layer2 = self.make_layer(block, 64, drop_out, hidden_dim=[128, 64], block_num=3)
self.layer3 = self.make_layer(block, 64, drop_out, hidden_dim=[128, 256], block_num=1)
self.layer4 = self.make_layer(block, 256, drop_out, hidden_dim=[512, 256], block_num=3)
self.dropout = nn.Dropout(0.5, inplace=True)
self.linear1 = nn.Linear(256, 32)
self.linear2 = nn.Linear(32, 3)
self.softmax = nn.Softmax(dim=1)
def make_layer(self, block, input_dim, drop_out, hidden_dim, block_num, n_layers=None):
layers = []
# 每一层的其他block,通道数不变,图片尺寸不变
for i in range(block_num):
layers.append(block(input_dim, drop_out, n_layers, hidden_dim))
return nn.Sequential(*layers)
def forward(self, x):
x = self.first(x)
# print(x.shape)
x = self.layer1(x)
# print(x.shape)
x = self.layer2(x)
# print('layer2', x.shape)
x = self.layer3(x)
# # print('layer3',x.shape)
# x = self.layer4(x)
# print('layer4',x.shape)
x = self.dropout(x)
# print('dropout', x.shape)
# 仅仅获取 time seq 维度中的最后一个向量
# the last of time_seq
x = x[:, -1, :]
x = self.linear1(x)
# print('linear1', x.shape)
x = self.linear2(x)
# print('linear2', x.shape)
x = self.softmax(x)
# print('softmax', x.shape)
return x
# 理解GRU网络结果https://blog.csdn.net/qq_27825451/article/details/99691258
class GRUNetV2(torch.nn.Module):
def __init__(self, input_dim, hidden_size, out_size, drop_out, n_layers=1):
super(GRUNetV2, self).__init__()
# self.batch_size = batch_size
self.hidden_size = hidden_size
self.n_layers = n_layers
self.out_size = out_size
self.drop_out = drop_out
# 这里指定了BATCH FIRST,所以输入时BATCH应该在第一维度
self.gru = torch.nn.Sequential(
torch.nn.GRU(input_dim, hidden_size, n_layers, dropout=drop_out, batch_first=True),
)
self.relu = torch.nn.ReLU(inplace=True)
# 加了一个线性层,全连接
self.fc1 = torch.nn.Linear(hidden_size, 32)
# 加入了第二个全连接层
self.fc2 = torch.nn.Linear(32, out_size)
self.softmax = torch.nn.Softmax(dim=1)
def forward(self, x):
# x的格式(batch,seq,feature)
output, hidden = self.gru(x)
output = self.relu(output)
# output是所有隐藏层的状态,hidden是最后一层隐藏层的状态
output = self.fc1(output)
output = self.fc2(output)
output = self.softmax(output)
# 仅仅获取 time seq 维度中的最后一个向量
# the last of time_seq
output = output[:, -1, :]
return output
# feature_dim = 14
# hidden_size = 64
# output_dim = 3
# num_layers = 3
# drop_out_gru = 0.3
#
# # hyper parameters
# BATCH_SIZE = 8 # batch_size
# LEARNING_RATE = 0.001 # learning_rate
# EPOCH = 600 # epochs
feature_dim = 14
drop_out = 0.3
# hyper parameters
BATCH_SIZE = 8 # batch_size
LEARNING_RATE = 1e-3 # learning_rate
EPOCH = 600 # epochs
net = Resblocks_body(Resblock, features_dim=feature_dim, first_output_dim=32, drop_out=drop_out)
# net = GRUNetV2(feature_dim, hidden_size, output_dim, drop_out_gru, num_layers)
net = net.to('cpu')
net = net.double()
print(net)
optimizer = torch.optim.Adam(net.parameters(), lr=LEARNING_RATE, betas=(0.8, 0.8),weight_decay=0.001)
loss_func = torch.nn.CrossEntropyLoss()
transform = transforms.Compose([
transforms.ToTensor(),
])
def split_data(X, y):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=3)
X_train = torch.tensor(X_train)
X_test = torch.tensor(X_test)
y_train = torch.tensor(y_train)
y_test = torch.tensor(y_test)
torch_train_dataset = data.TensorDataset(X_train, y_train)
torch_test_dataset = data.TensorDataset(X_test, y_test)
trainloader = data.DataLoader(
dataset=torch_train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
# num_workers=2
)
testloader = data.DataLoader(
dataset=torch_test_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
# num_workers=2
)
return trainloader, testloader
train_loss = []
train_acc = []
# Training
def train(epoch, trainloader):
global train_acc, train_loss
print('\n train Epoch: %d' % epoch)
net.train()
train_loss_tmp = 0
train_loss_avg = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(trainloader):
# print(batch_idx)
inputs, targets = inputs.to('cpu'), targets.to('cpu')
optimizer.zero_grad()
outputs = net(inputs)
# print(outputs)
loss = loss_func(outputs, targets)
loss.backward()
optimizer.step()
train_loss_tmp += loss.item()
_, predicted = torch.max(outputs, 1)
# print(predicted)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
train_loss_avg = train_loss_tmp / (batch_idx + 1)
print(batch_idx, len(trainloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (train_loss_avg, 100. * correct / total, correct, total))
train_loss.append(train_loss_avg)
train_acc.append(100. * correct / total)
print('\n -----train Epoch Over: %d------\n' % epoch)
print(len(trainloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (train_loss_avg, 100. * correct / total, correct, total))
test_acc = []
test_loss = []
best_acc = 0
best_acc_tmp = 0
def test(epoch, testloader):
print('\n test Epoch: %d' % epoch)
global test_acc, test_loss, best_acc_tmp
net.eval()
test_loss_tmp = 0
test_loss_avg = 0
correct = 0
total = 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(testloader):
inputs, targets = inputs.to('cpu'), targets.to('cpu')
outputs = net(inputs)
loss = loss_func(outputs, targets)
test_loss_tmp += loss.item()
_, predicted = torch.max(outputs, 1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
test_loss_avg = test_loss_tmp / (batch_idx + 1)
print(batch_idx, len(testloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (test_loss_avg, 100. * correct / total, correct, total))
test_loss.append(test_loss_avg)
test_acc.append(100. * correct / total)
best_acc_tmp = max(test_acc)
print('\n -----test Epoch Over: %d------\n' % epoch)
print(len(testloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (test_loss_avg, 100. * correct / total, correct, total))
if __name__ == '__main__':
for j in [15, 16, 17]:
train_loss = []
train_acc = []
test_acc = []
test_loss = []
data_colums = ['train_acc', 'train_loss', 'test_acc', 'test_loss']
data_train, labels = get_data('sz.000651', j, 5)
data_train = norm_data(data_train)
train_loader, test_loader = split_data(data_train, labels)
for i in range(EPOCH):
train(i, train_loader)
test(i, test_loader)
data_result = np.stack((train_acc, train_loss, test_acc, test_loss), axis=1)
# print(data_result)
if i == 0:
data_result = pd.Series(data_result.squeeze(), index=data_colums)
else:
data_result = pd.DataFrame(data_result, columns=data_colums)
data_result.to_csv('../result_acc/result.csv')
if best_acc_tmp > best_acc:
best_acc = best_acc_tmp
data_best = pd.Series((best_acc, j))
data_best.to_csv('../result_acc/best.csv')
torch.save(net.state_dict(), '../result_model/params_000651.pkl')
result_modle_days_to_train = pd.read_csv('../result_model/best_modle_days_to_train.csv', dtype=str)
# print('---------------result_modle_days_to_train-----------------')
if '000651' not in np.array(result_modle_days_to_train['stock_id']):
data_to_add = pd.Series(['000651', j], index=['stock_id', 'days_to_train'])
result_modle_days_to_train = result_modle_days_to_train.append(data_to_add, ignore_index=True)
else:
result_modle_days_to_train.loc[result_modle_days_to_train[result_modle_days_to_train[
'stock_id'] == '000651'].index, 'days_to_train'] = j
result_modle_days_to_train.to_csv('../result_model/best_modle_days_to_train.csv', index=None)
# print('---------------result_modle_days_to_train-----------------')
# Data for plotting
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
t = np.arange(EPOCH)
fig, ax = plt.subplots()
ax.plot(t, train_acc, t, test_acc)
ax.set(xlabel='训练次数', ylabel='准确性%',
title='训练准确性')
fig.savefig("../result_acc/acc_test" + str(j) + ".png")
# plt.show()
3.模型预测
模型预测中选择从今天开始到n天之前的股票数据(包含40组股票数据),刚好也可以看看前一段时间预测的准确性。
import re
import pandas as pd
import numpy as np
import datetime
import calendar
import torch
from model_train_network.train_3 import GRUNetV2, Resblock, Resblocks_body
from model_train_network.get_stock_data_1 import get_data
from model_train_network.get_stock_data_1 import get_data_pred
from model_train_network.select_feature_stock_data_2 import norm_data
#
# feature_dim = 14
# hidden_size = 64
# output_dim = 3
# num_layers = 3
# drop_out_gru = 0.3
#
# # hyper parameters
# BATCH_SIZE = 8 # batch_size
# LEARNING_RATE = 0.001 # learning_rate
# EPOCH = 600 # epochs
#
# net = GRUNetV2(feature_dim, hidden_size, output_dim, drop_out_gru, num_layers)
feature_dim = 14
drop_out = 0.3
# hyper parameters
BATCH_SIZE = 8 # batch_size
LEARNING_RATE = 1e-3 # learning_rate
EPOCH = 600 # epochs
net = Resblocks_body(Resblock, features_dim=feature_dim, first_output_dim=32, drop_out=drop_out)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_dict = net.state_dict()
pretrained_dict = torch.load('../result_model/params_600519.pkl', map_location=device)
pretrained_dict = {k: v for k, v in pretrained_dict.items() if np.shape(model_dict[k]) == np.shape(v)}
model_dict.update(pretrained_dict)
net.load_state_dict(pretrained_dict)
net.eval()
net = net.to('cpu')
net = net.double()
print(net)
# --------------------------------------- #
# num:产生股票数据的天数
# 产生用于生成股票的起止日期
# --------------------------------------- #
def date_func(num=40):
date_time = datetime.datetime.now()
year = date_time.year
month = date_time.month
day = date_time.day
date_list = []
while True:
if day >= 1:
date_tuple_tmp = (str(year), str(month), str(day))
connect_1 = ''
connect_2 = '-'
date = connect_1.join(date_tuple_tmp)
date_list_style = connect_2.join(date_tuple_tmp)
# 0表示周一,2表示周二,...,6表示周日
week = datetime.datetime.strptime(date_list_style, "%Y-%m-%d").weekday()
if week in [0, 1, 2, 3, 4]:
date_list.append(date_list_style)
num -= 1
if num == 0:
date_tuple_prev = (str(year), str(month), str(day))
break
day -= 1
elif day == 0:
month -= 1
if month == 0:
year -= 1
month = 12
if month in [1, 3, 5, 7, 8, 10, 12]:
day = 31
elif month in [4, 6, 9, 11]:
day = 30
else:
check_year = calendar.isleap(year)
if check_year:
day = 29
else:
day = 28
return date_list
# --------------------------------------- #
# stock_id:预测股票的代码
# --------------------------------------- #
def model_pred(stock_id, days_to_train):
num = 40
date_list = date_func(num)
start_data = date_list[-1]
end_data = date_list[0]
data_train, labels, date_seq = get_data_pred(stock_id, days_to_train, 5, start_data=start_data, end_date=end_data)
print('-------股票实际涨跌数据如下-------')
print(labels)
print('-------------日期序列--------------')
print(date_seq)
data_train = norm_data(data_train)
inputs = torch.tensor(data_train)
outputs = net(inputs)
_, predicted = torch.max(outputs, 1)
labels = torch.Tensor(labels)
print('-------预测数据如下-------')
print(predicted)
total = labels.shape[0]
correct = predicted.eq(labels).sum().item()
print(100. * correct / (total - 5), '(%d/%d)' % (correct, (total - 5)))
print('--------------------')
predicted = np.append(predicted.numpy(), 100. * correct / (total - 5))
date_seq.append('correct')
pd.Series(predicted, index=date_seq).to_csv(
'../result_up_down/result_' + str(re.findall(r'\d+', stock_id)[0]) + '.csv')
if __name__ == '__main__':
model_pred('sH.600519', 16)