MyCat实现高可用读写分离分库分表
1.mycat 主从复制,读写分离
2.mycat-web mycat可视化界面
3.HAProxy mycat集群
4.HAProxy + Keepalived mycat高可用集群架构
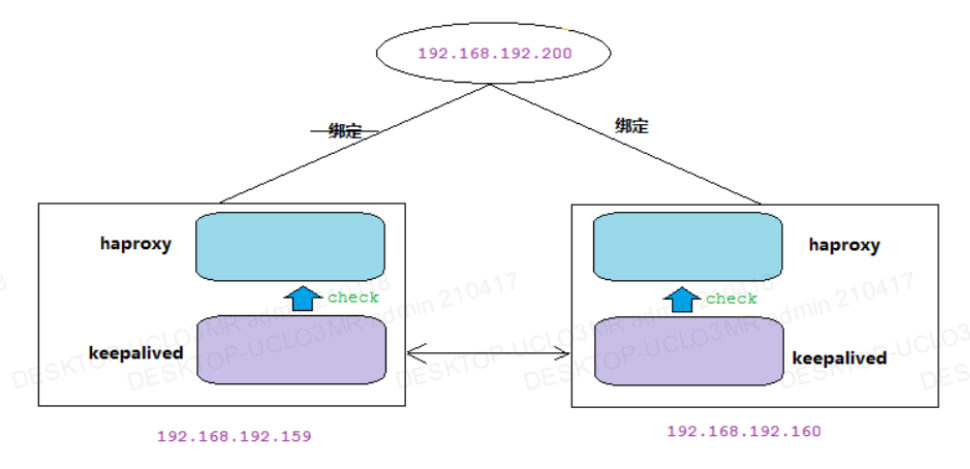
注:Keepalived的作用是抢占vip(虚拟ip)以提供对外服务
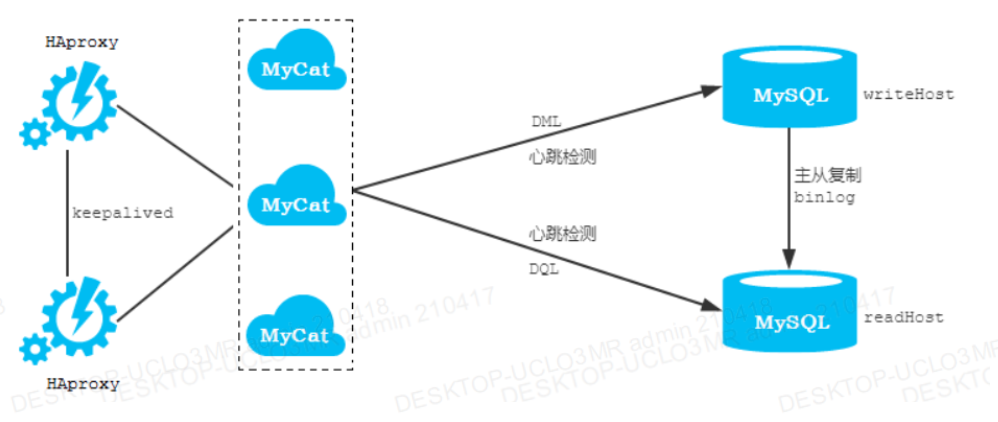
注:MyCat的高可用及负载均衡由HAProxy来实现,而HAProxy的高可用由 Keepalived来实现
1.MyCat的配置文件及其使用
MyCat下载:http://dl.mycat.org.cn/
schema.xml:MyCat的逻辑库、逻辑表以及对应的分片规则、DataNode以及DataSource
server.xml:mycat系统配置信息。例如配置用户名、密码及权限
rule.xml :拆分表的规则
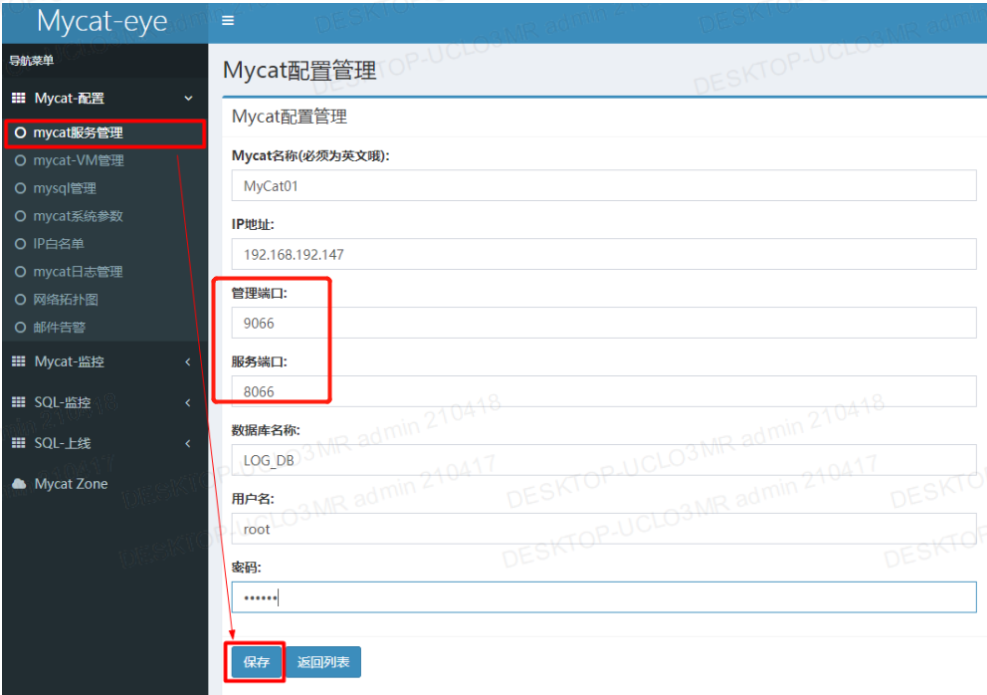
mycat管理端口9066(mycat-web查看mycat会使用) ; 服务端口8066(数据库连接)
1.1 schema.xml配置参数
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 1.schema:定义MyCat实例中的逻辑库 -->
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100">
<!-- 2.auto-sharding-long的分片规则是按ID值的范围进行分片-->
<!-- 1-5000000 为第1片 5000001-10000000 为第2片...-->
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
</schema>
<!-- 3.定义了MyCat中的数据节点,即数据分片 -->
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<!-- 4.定义数据库实例,读写分离配置和心跳语句 -->
<!-- balance 0不开启读写分离;1读写分离...-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="localhost:3306" user="root" assword="123456"></writeHost>
</dataHost>
</mycat:schema>
1.2 server.xml配置参数
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<!--1.系统参数设置-->
<system>
...
<!-- 20210417 设置字符集 -->
<property name="charset">utf8</property>
</system>
<!--2.用户信息设置-->
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">ITCAST</property>
</user>
</mycat:server>
1.3 rule.xml配置参数
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<!-- 1.tableRule配置规则 -->
<!-- 分片的字段为"id",分片规则是"rang-long" -->
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<!-- 2."rang-long"的规则具体映射文件是"autopartition-long.txt" -->
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
</mycat:rule>
1.4 win系统下使用MyCat
## cmd使用管理员打开并安装
mycat.bat install
## 启动mycat服务
mycat.bat start
## 查看mycat的运行状态:
mycat.bat status
## 停止mycat服务
mycat.bat stop
2. MyCat性能监控之MyCat-Web
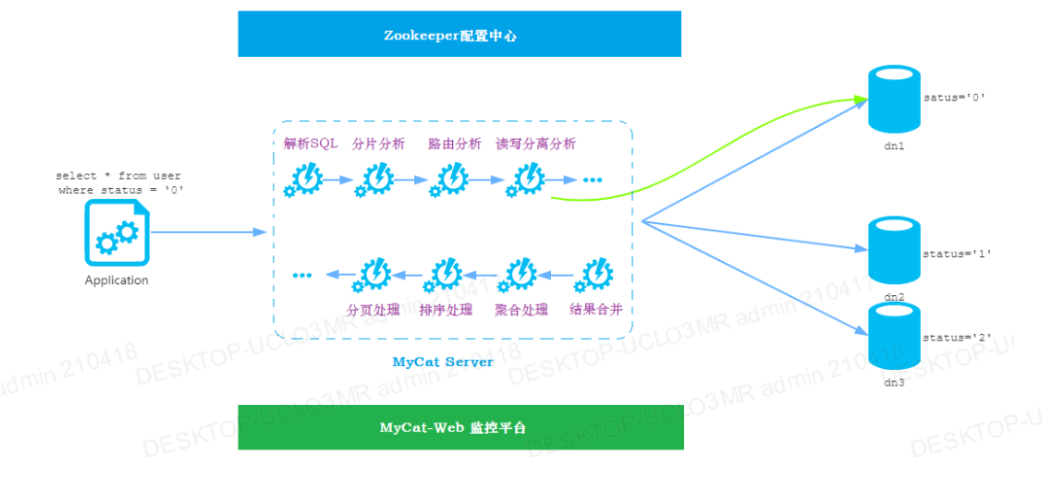
MyCat-Web 引入了ZooKeeper作为配置中心,可以管理多个节点
1.安装zk
2.启动mycat-web
3.http://localhost:8082/mycat
4.配置mycat参数
2.1 MyCat和MyCat-Web的关系图
2.2 MyCat-web管理界面配置mycat参数
3.Mycat的高可用机器架构
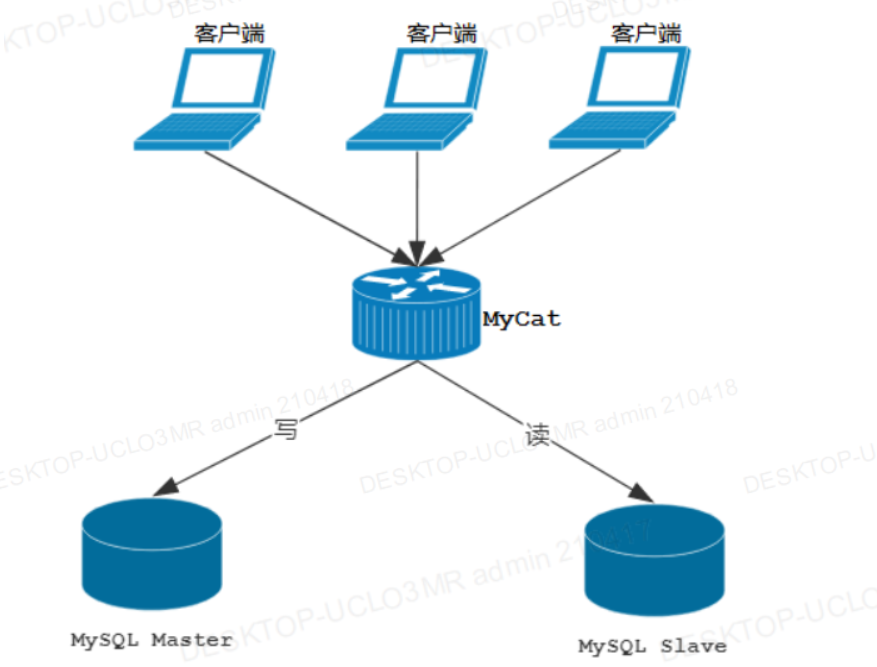
3.1 MycCat一主一从读写分离
①MyCat单机部署
②MyCat集群部署(HAPorxy实现MyCat的高可用)
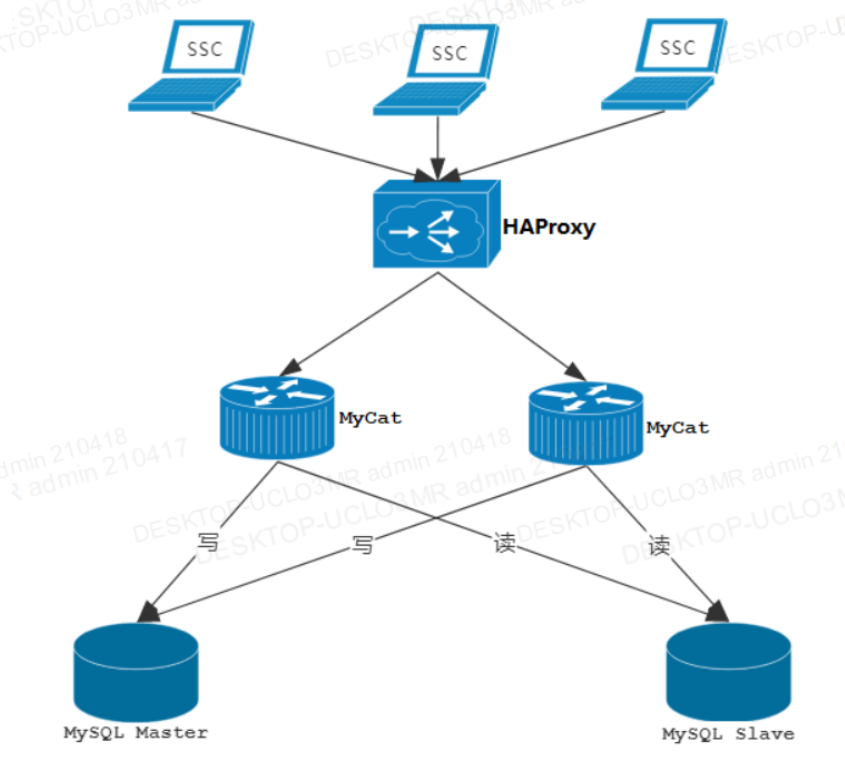
③MyCat高可用集群部署(keepalived实现HAProxy的高可用)
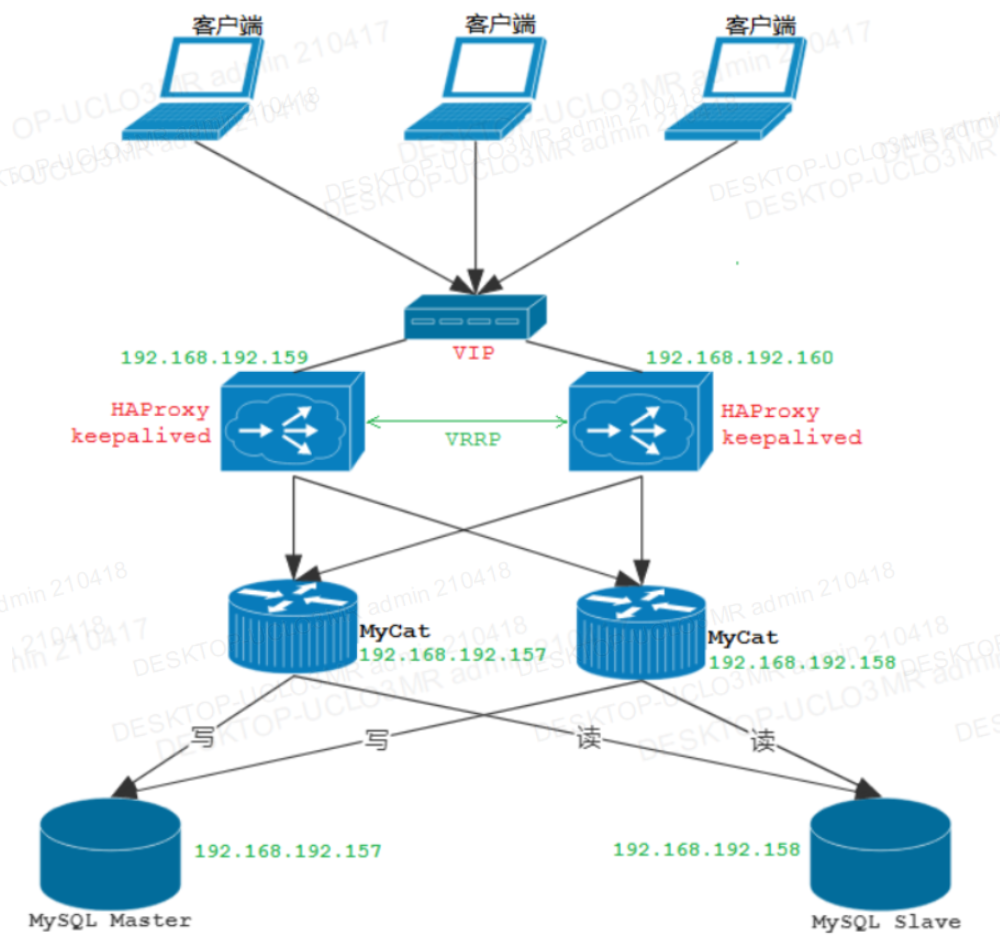
keepalived实现HAProxy的高可用
3.2 双主双从读写分离
①一主一从读写分离
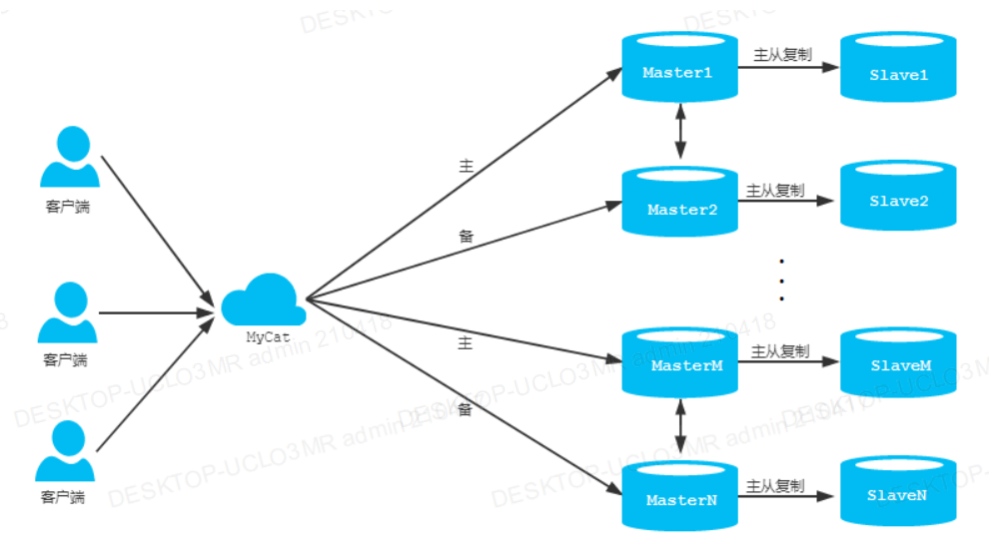
②双主双从读写分离
双主双从:
架构 :m1 -> s1 ; m2 -> s2 ; m1 <-> m2 互为主备
读写分离 :m1写 ; m2,s1,s2读
挂机 :m1挂掉后m2进行写
mycat主从切换问题:
方式1:自动切换:
当M宕机后, 读写S ; 恢复M后, 写S, 读M ;
当S宕机后, 读写M ; 恢复S后, 写M, 读S ;
方式2:基于MySQL主从同步状态的切换
MyCat检测到主从数据同步延迟,会自动切换到拥有最新数据的MySQL服务器
双主双从架构
3.3 MyCat分库分表架构图
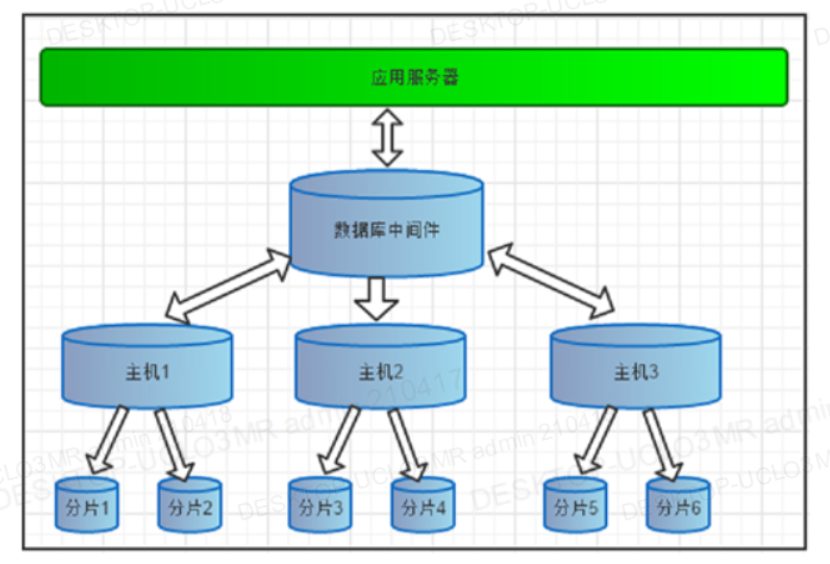
4. 项目实战之MyCat的分库分表
4.1 系统架构
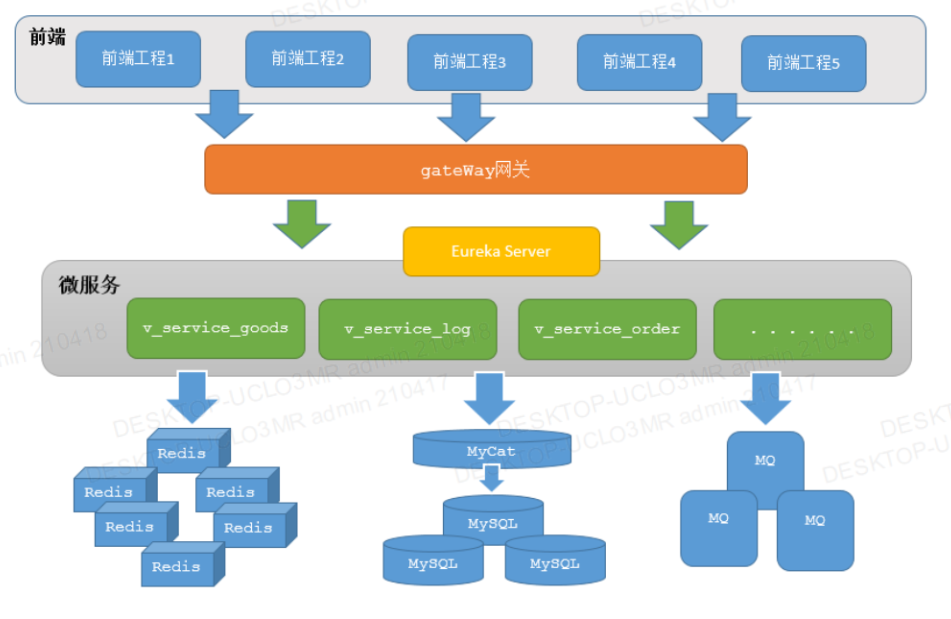
4.2 三大微服务功能及其微服务模块
3大系统功能介绍
1.商品管理:①添加商品 ②查询商品
2.订单管理:①下订单 ②查询订单
3.日志管理:①日志记录 ②日志查询
微服务模块介绍
spring-boot-starter-parent
|- v_parent --------------------> 父工程, 统一管理依赖版本
|- v_common ----------------> 通用工程, 存放通用的工具类及组件
|- v_model -----------------> 实体类
|- v_eureka ----------------> 注册中心
|- v_feign_api -------------> feign远程调用的客户端接口
|- v_gateway ---------------> 网关工程
|- v_manage_web ------------> 模拟前端工程
|- v_service_goods ---------> 商品微服务
|- v_service_log -----------> 日志微服务
|- v_service_order ---------> 订单微服务
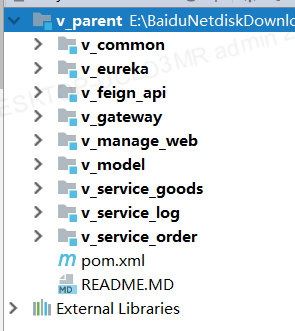
4.3 分库分表
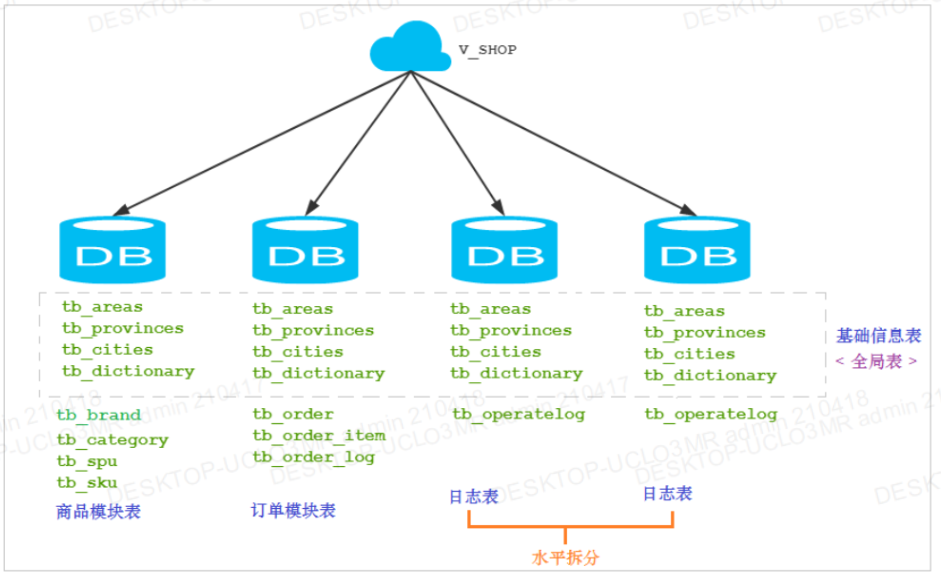
垂直拆分:同一块业务的数据库表拆分到同一个数据库服务中
1.全局表
1.1 省份表 tb_provinces
1.2市表 tb_cities
1.3 区县表 tb_areas
1.4 字典表 tb_dictionary
2.商品模块表(数据库v_goods) --> ip1
2.1 品牌表 tb_brand
2.2 商品SPU表 tb_spu
2.3 商品SKU表 tb_sku
2.4 商品分类表 tb_category
3.订单模块表(数据库v_order) --> ip2
3.1 订单表 tb_order
3.2 订单明细表 tb_order_item
3.3 订单日志表 tb_order_log
4.日志表(水平分库 数据库v_log) --> ip3 ip4
操作日志表 tb_operatelog
分库分表图
4.4 启动项目及其业务配置文件
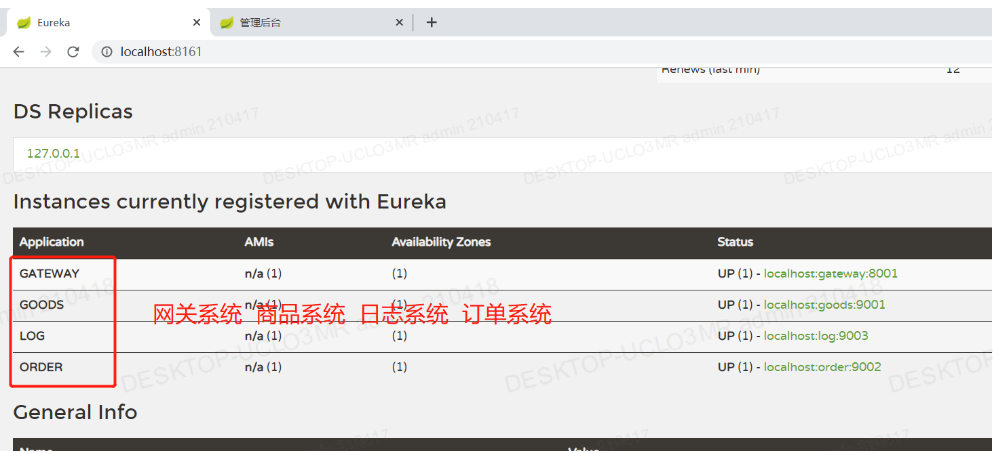
1.eureka注册中心:http://localhost:8161/
2.前端界面http://localhost:8080/
①Eureka注册中心
②application.yml配置文件
server:
port: 9003
spring:
application:
name: log
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:8066/V_SHOP?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: 123456
main:
allow-bean-definition-overriding: true #当遇到同样名字的时候,是否允许覆盖注册
eureka:
client:
fetch-registry: true
register-with-eureka: true
service-url:
defaultZone: http://127.0.0.1:8161/eureka
instance:
prefer-ip-address: true
③MyCat配置文件
schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--1.逻辑表和逻辑库设置-->
<schema name="V_SHOP" checkSQLschema="false" sqlMaxLimit="100">
<!--全局表-->
<table name="tb_areas" dataNode="dn1,dn2,dn3,dn4" primaryKey="areaid" type="global"/>
<table name="tb_provinces" dataNode="dn1,dn2,dn3,dn4" primaryKey="provinceid" type="global"/>
<table name="tb_cities" dataNode="dn1,dn2,dn3,dn4" primaryKey="cityid" type="global"/>
<table name="tb_dictionary" dataNode="dn1,dn2,dn3,dn4" primaryKey="id" type="global"/>
<!--v_goods商品模块-->
<table name="tb_brand" dataNode="dn1" primaryKey="id" />
<table name="tb_category" dataNode="dn1" primaryKey="id" />
<table name="tb_sku" dataNode="dn1" primaryKey="id" />
<table name="tb_spu" dataNode="dn1" primaryKey="id" />
<!--v_order订单模块-->
<table name="tb_order" dataNode="dn2" primaryKey="id" />
<table name="tb_order_item" dataNode="dn2" primaryKey="id" />
<table name="tb_order_log" dataNode="dn2" primaryKey="id" />
<!--v_log日志模块-->
<!--分表规则采用hash一致"log-sharding-by-murmur"规则-->
<table name="tb_operatelog" dataNode="dn3,dn4" primaryKey="id" rule="log-sharding-by-murmur"/>
</schema>
<!--2.实际数据节点映射关系-->
<dataNode name="dn1" dataHost="host1" database="v_goods" />
<dataNode name="dn2" dataHost="host2" database="v_order" />
<dataNode name="dn3" dataHost="host3" database="v_log" />
<dataNode name="dn4" dataHost="host4" database="v_log" />
<!--3.实际数据节点设置-->
<!--下面只是有的节点进行分表,并没有进行读写分离-->
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
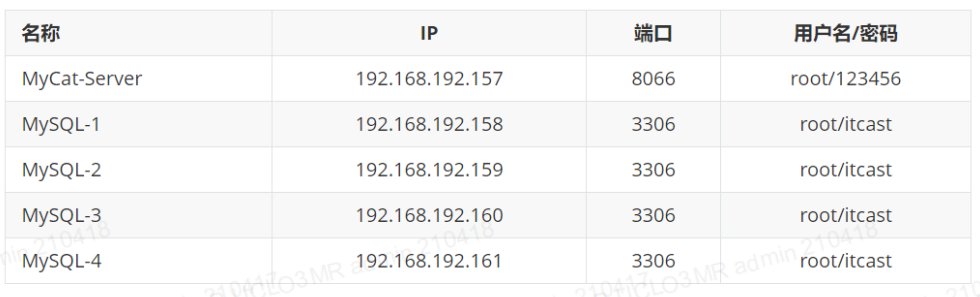
<!--上面说的ip1就是指"192.168.192.158",下面同理不再赘述-->
<writeHost host="hostM1" url="192.168.192.158:3306" user="root" password="itcast"> </writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.192.159:3306" user="root" password="itcast"></writeHost>
</dataHost>
<dataHost name="host3" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM3" url="192.168.192.160:3306" user="root" password="itcast"></writeHost>
</dataHost>
<dataHost name="host4" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM4" url="192.168.192.161:3306" user="root" password="itcast"></writeHost>
</dataHost>
</mycat:schema>
server.xml配置文件
<user name="root" defaultAccount="true">
<property name="schemas">V_SHOP</property>
<property name="password">123456</property>
</user>
rule.xml配置文件
<!--一致性hash算法 2个库-->
<tableRule name="log-sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>log-murmur</algorithm>
</rule>
</tableRule>
<function name="log-murmur" class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property>
<property name="count">2</property>
<property name="virtualBucketTimes">160</property>
</function>
版权声明:本文为weixin_45450428原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。