【路径规划】基于A星算法的三维路径规划(数字高程数据DEM)的python实现
一、项目简介?
A* 算法是一种启发式算法,主要用于解决在静态路网中寻找最短路径的问题。关于A* 算法在二维平面内的文章比较多,其实只需要将二维的A* 算法稍加修改,就可以实现在三维地理空间内的路径规划。本篇文章将简要介绍A* 算法以及数字高程模型(DEM)的相关知识,并用python实现这一算法。
二、背景知识?
2.1?A* 算法基本原理
2.1.1 启发式算法
A* 算法是一种启发式算法,顾名思义,就是“启发式”地寻找最短路径。相比较于深度优先搜索、广度优先搜索、Dijkstra算法等“非启发”式的算法,其性能更加优越。
A* 算法的核心在于不断更新总耗费函数F ( n ) F(n)F(n)来选取最优的节点:
F ( n ) = g ( n ) + h ( n ) F(n) = g(n)+h(n)F(n)=g(n)+h(n)
其中,g ( n ) g(n)g(n)为耗费值(cost),指的是从起点到当前节点的耗费成本(距离、费用等)
而h ( n ) h(n)h(n)为估计值,也即启发函数(Heuristic),指的是当前节点到终点的估计耗费成本.启发函数是基于经验的,常用的有曼哈顿距离、欧几里得距离等,不同的启发函数的选择对于计算的速度也会产生影响,所以选择合适的启发函数是很重要的.
A* 算法需要维护两个存储队列: open_list和close_list .其中,open_list用来存储待搜索的节点,而close_list用来存储已经搜索完毕的节点.
2.1.2 基本流程
A* 算法的基本流程如下:
- 首先将起点(source_node)放入open_list中,并遍历与起点相邻的节点,将这些节点也放入open_list中.
- 从open_list中取出一个F ( n ) F(n)F(n)最小的节点node_to_open
2.1 遍历node_to_open的八个方向(左,左上,上,右上,…左下)
2.2 如果某个方向上的节点已经在close_list中,则跳过
2.3 如果某个方向上的节点已经在open_list中,则比较 从该方向父节点的父节点(爷爷节点)直接到该方向的距离(grandpa->father->new_position) 和 从该方向的爷爷节点经由父节点再到该方向的距离(grandpa->new_position) 的大小.若前者较小,则设置新节点的父节点为其爷爷节点,并重新计算其耗费值g ( n ) g(n)g(n);否则不改变其父节点.(如图,经由grandpa->father->new_pos需要花费10+10=20单位,而从grandpa->new_pos只需要花费14单位,显然更优的路径是前者.)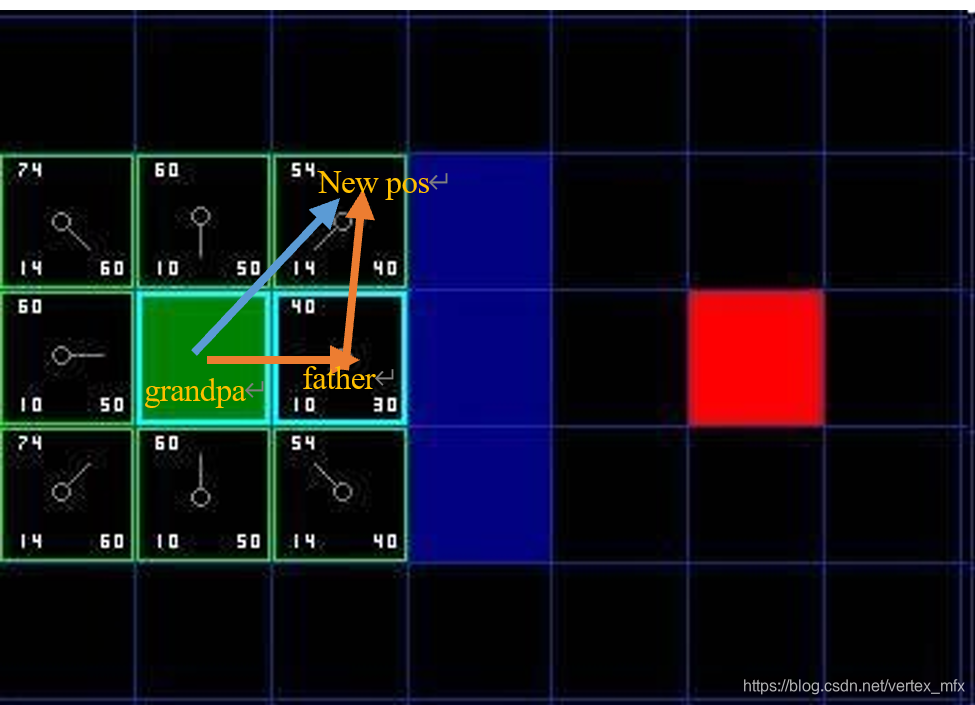
2.4 如果某个方向上的节点既不在open_list中也不在close_list中,则将该节点加入到open_list中并计算其耗费值g ( n ) g(n)g(n)和预测值h ( n ) h(n)h(n).
3.每次从open_list中取出一个F ( n ) F(n)F(n)最小的节点作为下一个节点 node_to_open ,重复上述过程直到达到终点(dest_node)或 open_list为空.
4.从终点向前递归地得到父节点(father_node)的位置,一直到起点为止,此时就得到了最优的路径.
2.2 ?数字高程模型(DEM)
GIS 既可表示要素,也可表示表面。要素是具有明确形状(例如行政管理边界)的地理对象。表面是在其范围内的每个点处都具有值的地理现象。高程是一个常见的示例,然而表面还可以表示温度、化学物质浓度、以及许多其他事项。
表面通常利用栅格数据集进行建模。栅格即像元(也称像素)矩阵,按行和列进行组织并且覆盖世界的某些部分(或者甚至整个世界)。矩阵的每个像元均表示某面积的平方单位,其中包含该面积所在位置的测量结果或估计数值。
ArcGis
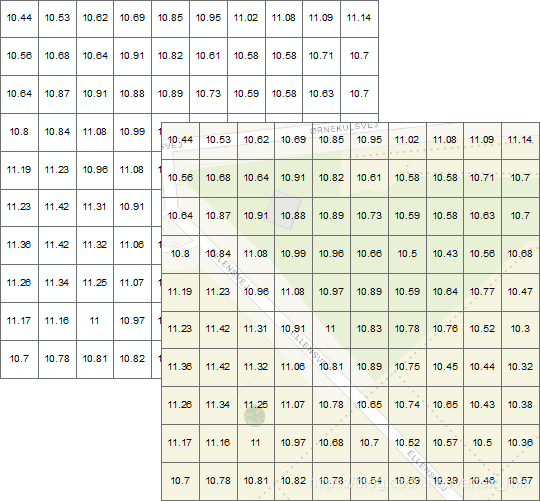
通俗来讲,DEM就是将地球表面看作一个个小方格组成的矩阵,矩阵的数值代表了每个小方格对应地物的高程.
三、动手实现?
简单了解A* 算法的基本原理和数字高程模型DEM之后,让我们来一步一步实现这个算法。
3.1?构建地图类,用于实现地图相关功能
DEM数据
这里展示了一个典型的dem文件,如图,文件中包含了地图的尺寸、左下角的实际坐标位置、栅格尺寸(cellsize,即表示一个栅格代表实际地物是多少米)、缺失值数字(NODATA_VALUE,即数据中缺失值,此处用0来代替。)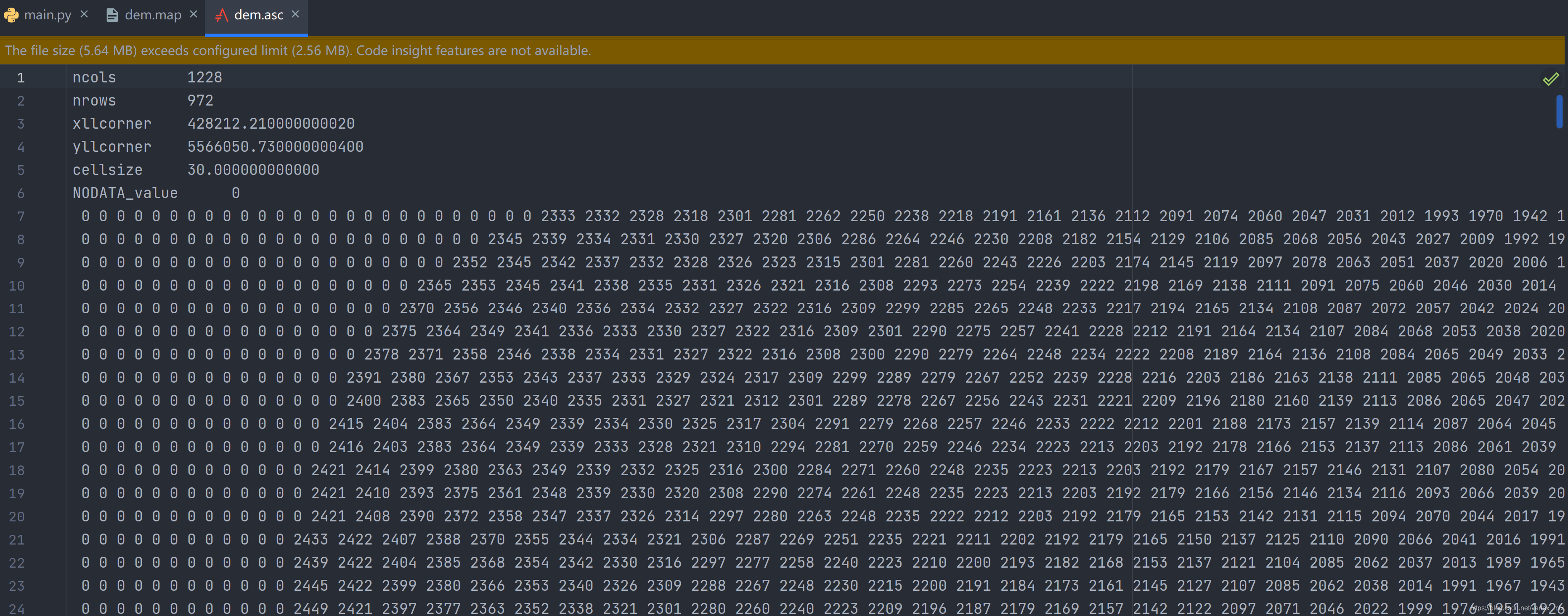
地图类
存储了地图栅格的尺寸、DEM信息等。注意这里用了两个地图栅格矩阵:self.map 和 self.dem_ map .dem_map就是用于存储高程数据的矩阵,而map则是一个与dem_map同样大小的矩阵,这里用全0填充。此处设置这个矩阵的目的,是为了预留出来用于表示地图中可能有的障碍点等其他信息。可以通过的方格用0表示,不可以通过的方格可以用1来表示。
# 地图类,用于加载并存储dem地图
class Map:
def __init__(self):
self.width = 1
self.height = 1
self.map = np.zeros((self.height, self.width), dtype=int)
self.dem_map = None
self.grid_size = 1
- 读取数据
首先对源数据进行处理。此处为了读取方便,仅将源文件中的dem数据复制出来,保存到一个新的文件中,并对原来缺失的数据用平均值进行填充 (计算可得平均值为1449,此处用1500来近似)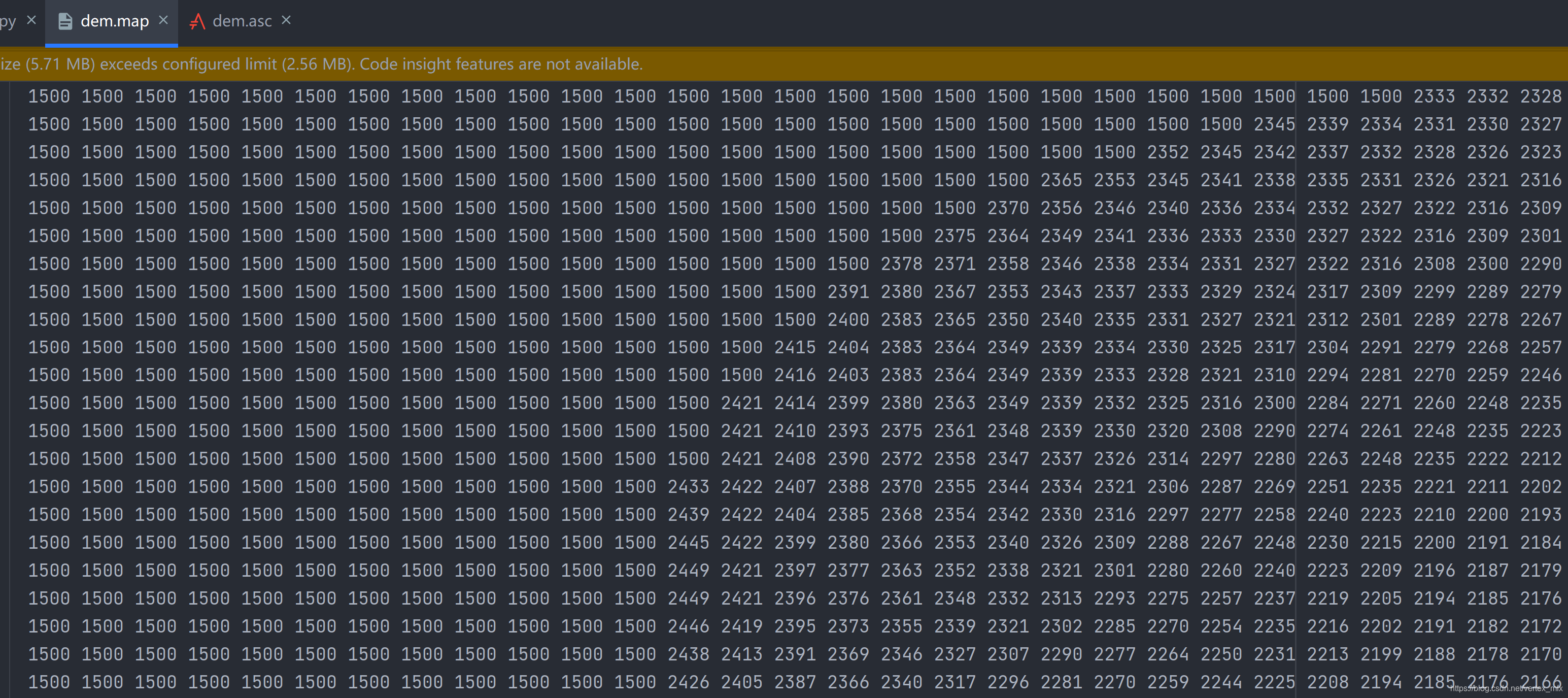
接下来读取数据。
从文件按行读取dem数据。注意,由于地理坐标和数据存储方式之间的差异(如图),需要对读取的高程数据列表进行倒序排列操作。
读取数据的函数
# 从文件读取地图
def read_map(self, file_path, grid_size=1.0):
print('Loading DEM map...')
fin = open(file_path, 'r')
new_map = []
for row in fin.readlines():
heights = [float(point) for point in row.strip().split(' ')]
new_map.append(heights)
new_map.reverse()
# 将地理栅格模型的y轴反转
new_map = np.array(new_map)
print('mean:', new_map.mean())
self.dem_map = new_map
self.height, self.width = new_map.shape
self.grid_size = grid_size
self.map = np.zeros((self.height, self.width), dtype=int)
print(f'DEM map loaded. Width={self.width},height={self.height},grid size={self.grid_size}.')
- 展示地图
用matplotlib库中的等高线图功能,对读取到的地图进行初步的可视化
# 绘制地图以及路径
def draw_map(self, path=None, source=None, dest=None):
print("Drawing map...")
x = np.arange(0, self.width, 1)
y = np.arange(0, self.height, 1)
X, Y = np.meshgrid(x, y)
Z = self.dem_map
plt.contourf(X, Y, Z)
plt.contour(X, Y, Z)
plt.show()
可视化地形图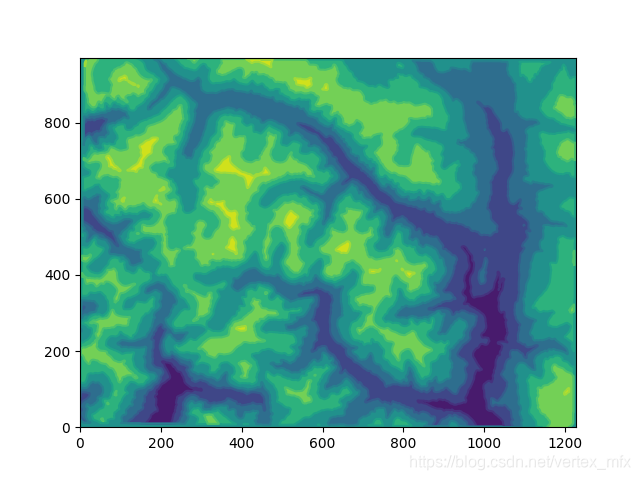
3.2?构建支持算法的存储结构
- open_node:开放节点,用于存储加入到open_list中的节点的信息,包含节点的坐标、耗费值和预测耗费值、父节点等
# 定义节点,储存节点位置,从起点的开销,到终点的估计开销,以及父节点
class OpenNode:
def __init__(self, x, y, cost=0.0, pred=0.0, father=None):
self.x = x
self.y = y
self.cost = cost
self.pred = pred
self.father = father
# 用于返回该点的坐标数组
def get_pos(self):
return self.x, self.y
# 用于得到F(n)的值
def get_F(self):
return self.cost + self.pred
- open_list:开放节点列表,用于存储待搜索的节点的列表。由于每次均要从中取F值最小的节点,所以借鉴了C++中的“最小优先表”的概念,每次入表的节点均按照F值大小排序,使得取出得节点为F值最小。
# 定义最小优先表,每次返回F最小的节点
class MinPriorList:
def __init__(self):
self.list = []
def is_empty(self):
return len(self.list) == 0
def in_list(self, pos):
for i in range(len(self.list) - 1, -1, -1):
if self.list[i].get_pos() == pos:
return True
return False
def del_node(self, pos):
for i in range(len(self.list) - 1, -1, -1):
if self.list[i].get_pos() == pos:
del self.list[i]
return True
return False
# 插入一个节点,并移动该节点使得列表按F(n)降序排列
def push(self, node):
if self.is_empty():
self.list.append(node)
else:
self.list.append(node)
for i in range(len(self.list) - 1, 0, -1):
if self.list[i].get_F() > self.list[i - 1].get_F():
self.list[i], self.list[i - 1] = self.list[i - 1], self.list[i]
# 返回并删除最后一个节点,返回的是F(n)最小的节点
def pop(self):
return self.list.pop()
# 查看最后一个节点
def top(self):
return self.list[-1]
def print_list(self):
print(f'MinPriorList contains {len(self.list)} nodes.')
for i in range(0, len(self.list)):
print(f'({self.list[i].get_pos()},{self.list[i].get_F():.2f})', end=' ')
print()
- close_list:关闭节点列表,用于存储已经搜索过的节点的列表。此处用一个和地图一样大的二位0-1型数组来存储。
self.close_list = np.zeros((self.map.height, self.map.width), dtype=bool)
3.3?计算耗费值g(n)和预测耗费值h(n)
- 计算耗费值g(n).
根据到上一个节点的位置来计算耗费值。此处分两种情况,一种是水平移动,则水平距离为1;另一种是斜向移动,则水平距离为( 2 ) ≈ 1.414 \sqrt(2)\approx1.414(2)≈1.414,再与两点之间的垂直距离利用勾股定理则求出两点之间的耗费距离.
def calc_cost(self, pos, new_pos):
if pos[0] != new_pos[0] and pos[1] != new_pos[1]:
horizon_dist = 1.414 * self.map.grid_size
else:
horizon_dist = 1 * self.map.grid_size
cost = sqrt(
horizon_dist ** 2 + (self.map.dem_map[pos[1], pos[0]] - self.map.dem_map[new_pos[1], new_pos[0]]) ** 2)
# print(f'CALC COST. Pos({pos[0]},{pos[1]})->({new_pos[0]},{new_pos[1]}),cost = {cost:.2f}')
return cost
- 计算预测值h(n).
此处用简化的方法来估计到终点的预测值.先计算该节点到终点的水平距离(horizon_dist),再得到两点之间的高程差,最后计算两点之间的直线距离,作为到终点的耗费估计值.
def calc_pred(self, location):
grid_size = self.map.grid_size
horizon_dist = sqrt(
((location[0] - self.dest[0]) * grid_size) ** 2 + ((location[1] - self.dest[1]) * grid_size) ** 2)
height_dist = abs(self.map.dem_map[location[1], location[0]] - self.map.dem_map[self.dest[1], self.dest[0]])
pred = sqrt(horizon_dist ** 2 + height_dist ** 2)
# print(f'CALC PRED. Pos({location[0]},{location[1]}),pred = {pred:.2f}')
return pred
3.4?从open_list中搜索节点
对应"基本流程"中的第2步,首先从open_list中获取一个f值最小的节点 node_to_open ,再遍历该节点周围的节点(通过 get_new_position() 函数),对于每个周边节点(new_pos),按照流程中的步骤逐一进行判断和操作.最终将该节点加入close_list中.
- 遍历周边节点
# 遍历节点的周边节点
def get_new_position(self, location):
#对应8个方向,也可以根据需要改为4个方向
offsets = [(-1, 0), (0, -1), (1, 0), (0, 1), (-1, -1), (1, -1), (-1, 1), (1, 1)]
pos_list = []
for offset in offsets:
pos = location.get_pos()
new_pos = (pos[0] + offset[0], pos[1] + offset[1])
#此处判断节点是否超出了地图范围
if new_pos[0] < 0 or new_pos[0] > self.map.width or new_pos[1] < 0 or new_pos[1] > self.map.height:
continue
pos_list.append(new_pos)
return pos_list
- 加入open_list的逻辑
def open_new_node(self):
node_to_open = self.open_list.pop()
pos_list = self.get_new_position(node_to_open)
for new_pos in pos_list:
if not self.in_close_list(new_pos):
# 判断新位置是否在open_list中
if self.open_list.in_list(new_pos):
# print(f'NODE IN OPEN LIST.{new_pos}')
# 父节点->new_node->new_pos的花费
grandpa_father_dist = self.calc_cost(node_to_open.get_pos(), new_pos) + node_to_open.cost
# print(f'Direct path:{node_to_open.father.get_pos()}->{node_to_open.get_pos()}->{new_pos},cost={direct_dist:.2f}')
# 父节点->new_pos的花费
grandpa_dist = self.calc_cost(new_pos, node_to_open.father.get_pos())
# print(f'Father path:{node_to_open.father.get_pos()}->{new_pos},cost={father_dist:.2f}')
if grandpa_dist <= grandpa_father_dist:
# print("UPDATED OPEN NODE!")
self.open_list.del_node(new_pos)
new_node = OpenNode(new_pos[0], new_pos[1], grandpa_dist, self.calc_pred(new_pos),
node_to_open.father)
new_node.describe_node()
self.open_list.push(new_node)
else:
new_node = OpenNode(new_pos[0], new_pos[1], self.calc_cost(node_to_open.get_pos(), new_pos),
self.calc_pred(new_pos), node_to_open)
new_node.describe_node()
self.open_list.push(new_node)
# 将搜索过的该节点加入到close_list中
self.close_list[node_to_open.y, node_to_open.x] = True
self.node_searched += 1
3.5?A*算法的主函数逻辑
在经过上述的铺垫之后,我们已经为A* 搜索算法正式开动做好了充分准备.首先,将起点坐标加入open_list列表中,并执行一次对该节点周围节点的搜索。然后,每次从open_list中读取一个F值最小的点,并对该节点周围节点进行搜索。如此循环,直到达到终点或open_list为空结束。
def start_search(self):
print("SEARCH STARTED!")
# 将起点加入到open_list中
start_node = OpenNode(self.source[0], self.source[1], 0, self.calc_pred(self.source), None)
self.open_list.push(start_node)
# 执行一次搜索
self.open_new_node()
# 开始循环搜索
while not self.open_list.is_empty():
node_to_open = self.open_list.top()
if node_to_open.get_pos() == self.dest:
print("SEARCH FINISHED!")
break
self.open_new_node()
if self.node_searched % 100 == 0:
print(f'Searched {self.node_searched} nodes.')
path = []
# 对路径进行溯源
path_iterator = PathIterator(node_to_open)
for pos in path_iterator:
path.append(pos)
# print(f'PATH:{path}')
print(f'MIN COST:{node_to_open.cost}')
# 绘制路径的函数
self.map.draw_map(path=path, source=self.source, dest=self.dest)
3.6?路径的溯源
由于前期在存储路径节点的时候,已经一并存储了其父节点,所以理论上只要从终点开始往前递归就可以得到完整的路径.但是在实际操作的时候我遇到了一个问题,就是超过python的最大递归深度(maximum recursion depth exceeded).通过查找资料,主要有两种解决方案:
- 手动修改最大递归深度.这样可以手动地破除python对最大递归深度的限制,但是也容易导致内存错误等问题,不是很建议采用
- 采用迭代器(Iterrator)来解决.这种方法,是通过构造一个迭代器来实现对父节点的迭代查询.python的迭代器设计的初衷就是为了减少内存的开销,所以采用这种方法来对路径进行溯源.
class PathIterator:
def __init__(self, node):
self.node = node
# 这里是每一步迭代需要进行的操作
def __next__(self):
if self.node.father is not None:
self.node = self.node.father
return self.node.get_pos()
else:
raise StopIteration
# 在类中添加此方法,就可以进行迭代操作.
def __iter__(self):
return self
3.7?绘制路径
3.7.1 二维平面的绘制
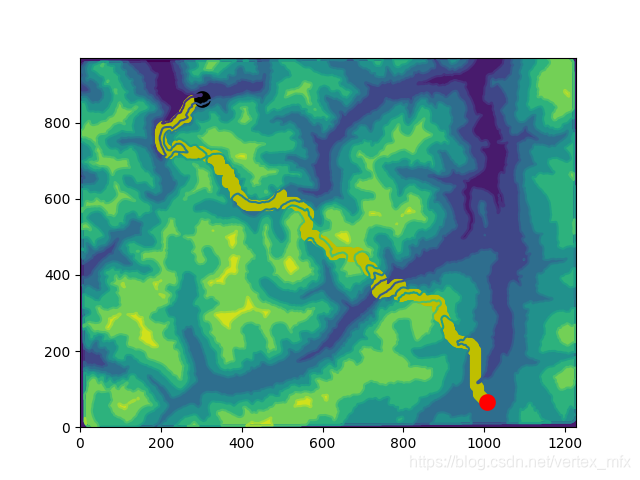
在第一步我们绘制好地图之后,可以在plt中再添加一个图层,用散点图的方式在二维地形图上绘制出路径.
# 绘制地图以及路径
def draw_map(self, path=None, source=None, dest=None):
print("Drawing map...")
x = np.arange(0, self.width, 1)
y = np.arange(0, self.height, 1)
X, Y = np.meshgrid(x, y)
Z = self.dem_map
# 填充等高线图
plt.contourf(X, Y, Z)
plt.contour(X, Y, Z)
if path is not None:
#首先将路径节点列表转置一下,将x坐标和y坐标分别放到一行中
path = np.transpose(path)
print('Path Array:', path)
plt.scatter(path[0], path[1], c='y', linewidths=2)
if source is not None:
# 绘制起点坐标
plt.scatter(source[0], source[1], c='r', linewidths=6)
if dest is not None:
# 绘制终点坐标
plt.scatter(dest[0], dest[1], c='black', linewidths=6)
plt.show()
这样,一个简单的二维路径地形图就做好了: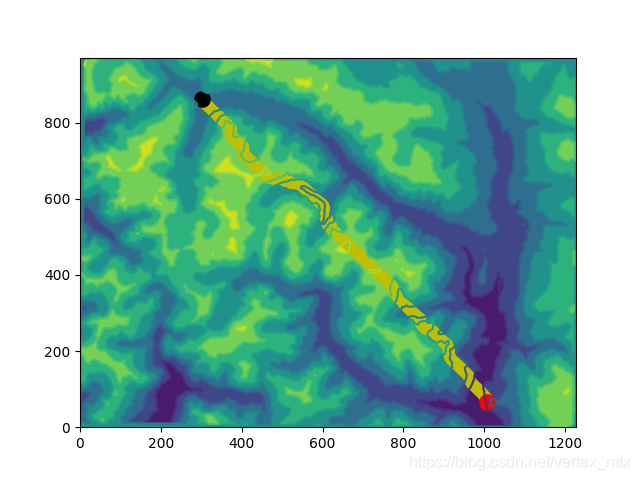
3.7.2三维地形图的绘制
二维地形图虽然可以看出路径的走势,但是仍然不够直观,不能直观地看出路径随地形的起伏.如果能用三维地形图的方式展示地形和路径,岂不是更加直观形象?于是我开始了尝试:
- 用格网(wireframe)来绘图
fig,ax = plt.subplots(subplot_kw=dict(projection='3d'),figsize=(12,10))
# 注意此处要手动设置一下z轴的高度,否则地图的比例会很奇怪
ax.set_zlim(0,9000)
ax.plot_wireframe(X, Y, Z, cmap=plt.cm.gist_earth)
做出来的图形是这样子的:
- 给地形图上色
虽然格网地形图有了一点地形上下起伏的样子,但是和我心目中的地形图的样子还是颇有差异.于是我又找到了一种可以绘制带丰富色彩的地形图的方法:
import matplotlib.pyplot as plt
from matplotlib.colors import LightSource
from matplotlib import cm
ls = LightSource(270,20)
rgb = ls.shade(Z, cmap=cm.gist_earth, vert_exag=0.1, blend_mode='soft')
# 绘制地形图
surf = ax.plot_surface(X, Y, Z, rstride=1, cstride=1, facecolors=rgb,
linewidth=0, antialiased=False, shade=False)

这样看起来是不是有内味了?下面需要做的,就是将路径绘制到地形图上.
- 带路径的地形图
我们借鉴绘制二维地形图的时候,用散点图的方式将路径图层叠加到地图上——
# 绘制三维路线图
pathT = np.transpose(path)
Xp = pathT[0]
Yp = pathT[1]
Zp = [self.dem_map[pos[1], pos[0]] for pos in path]
ax.plot(Xp,Yp,Zp,c='r')
于是我们得到了这样的一条路径: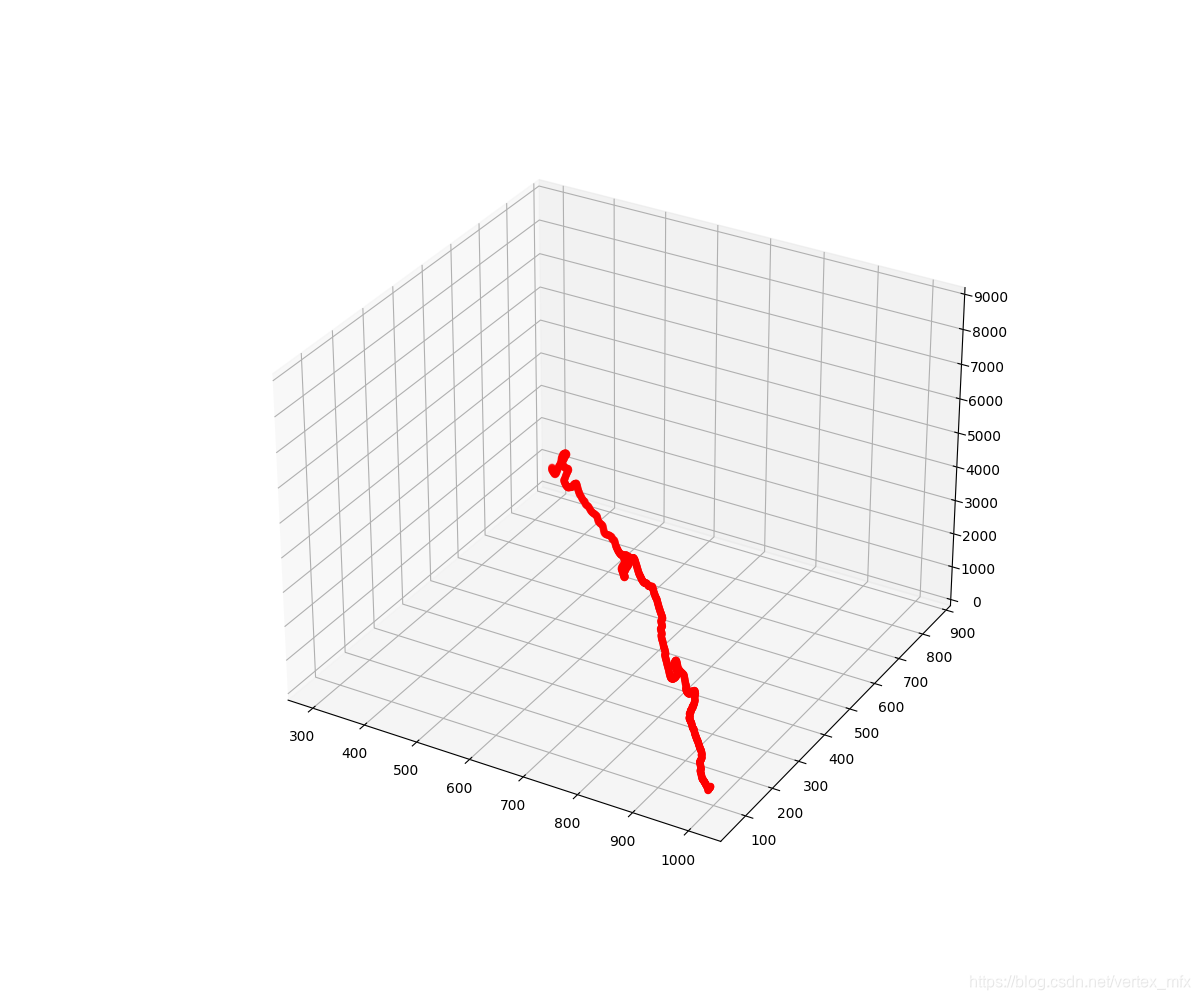
这样看来,路径在三维空间里的走势还挺明显的,似乎只差最后一步,将路径图层和地形图层叠加起来。但是,当我试图这样做时,却发现路径被地形图完全遮挡了。我甚至尝试过将路径整体“抬高”2500米,结果却只能露出最左上角的一点:
Zp = [self.dem_map[pos[1], pos[0]]+2500 for pos in path]
这是原本的图像,路径完全被遮挡了(彩色地形图也是一样,有没有路径的彩色地形图看上去并没有半点不同,为了显示二者关系采用了格网地图)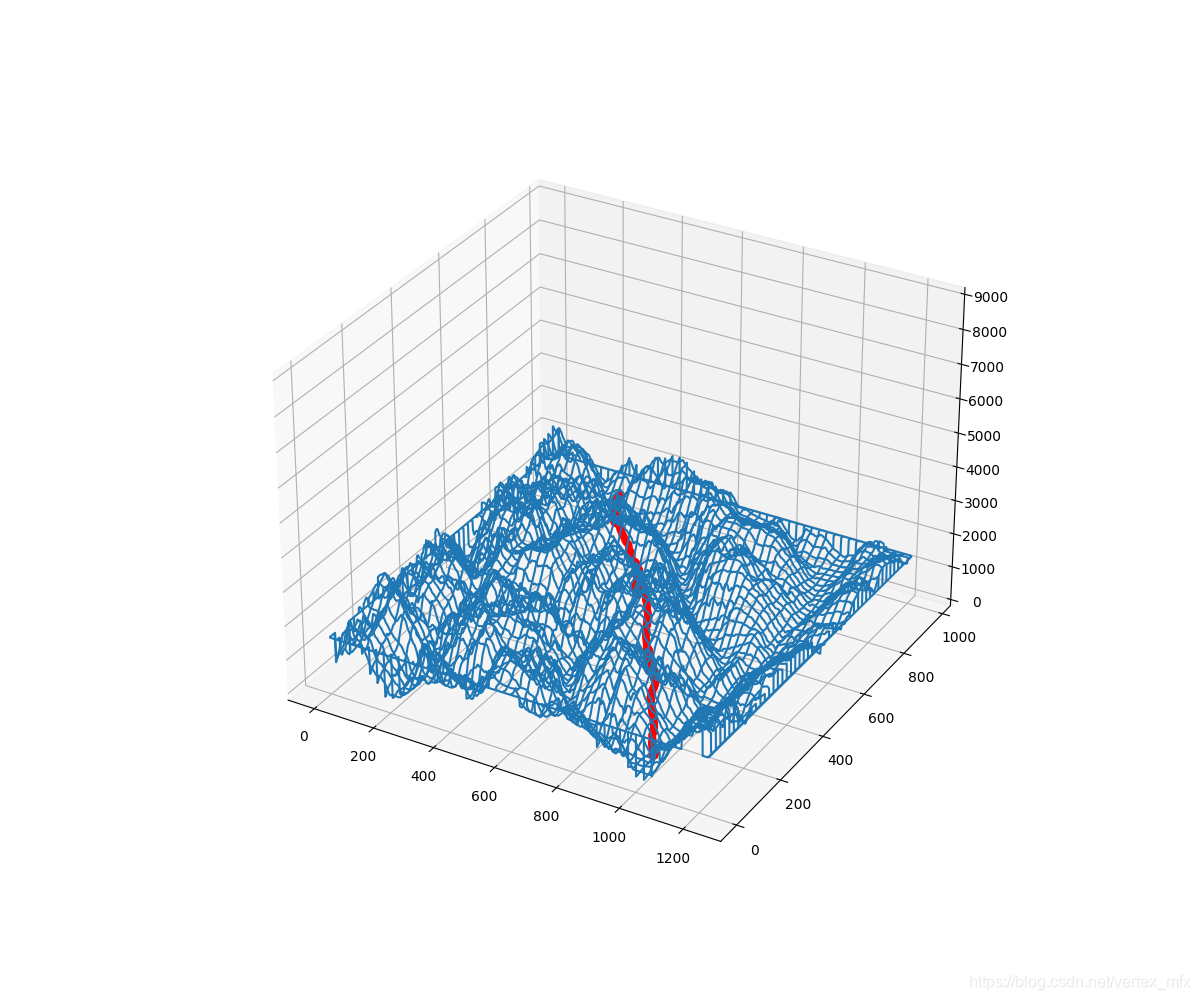
这是将路径“抬高”后的地图。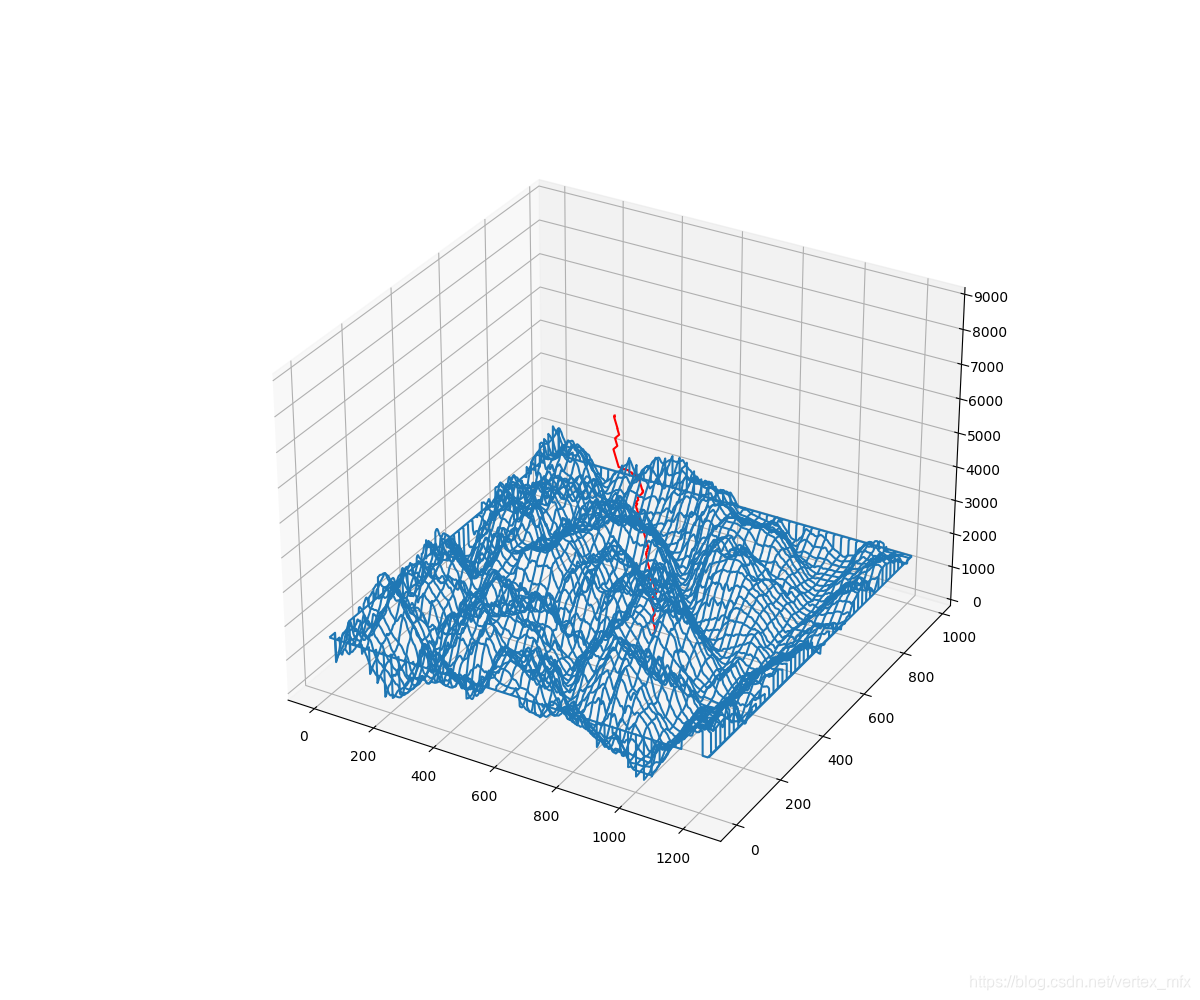
可以看出,只有左上角一点点是露出来的,其余全部被覆盖在格网下面,尝试过更改格网、路径渲染的先后顺序也没有办法···所以如果有读者有解决方案的话,欢迎在评论区讨论交流!!
四、扩展实验?
上述分析过程的到的结果,发现路径近似一条直线,地形起伏对路径的影响不是很明显。如果人为加大地形的起伏程度,路径的弯曲程度是否也会受到影响呢?
在给定的参数中,cellsize被设为了30,也就是说,每一个栅格代表实际长度30米。通过修改cellsize的值,就可以实现人为改变地形陡峭程度。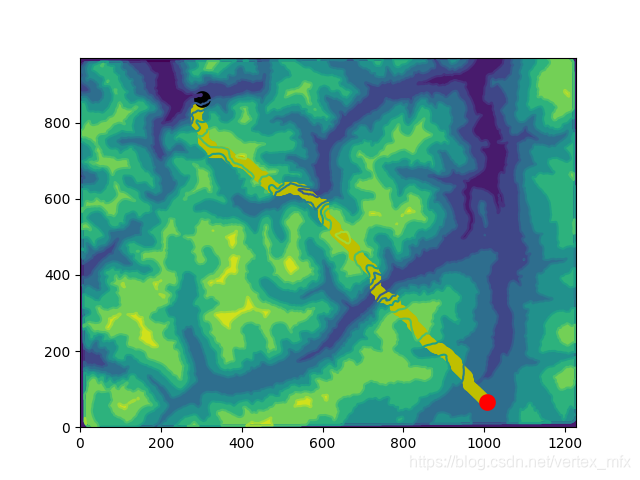
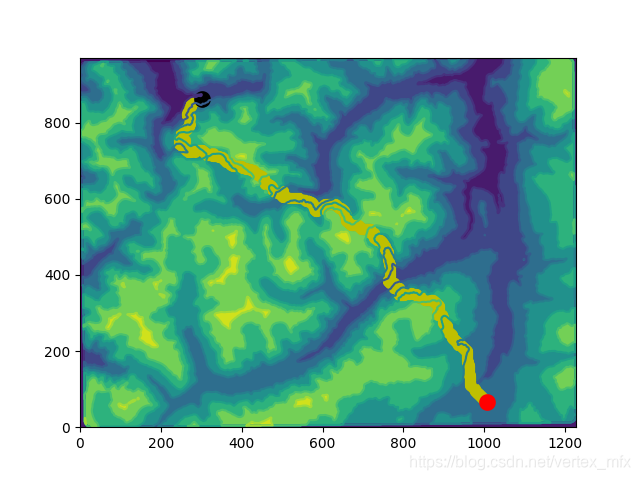
五、总结与致谢?
这是我的第一篇CSDN技术博客,写作用了两天时间,内容源于前段时间做的一个小项目。在写作过程中,参考了KillerAery1 、Arvid Y 2和 虾神daxialu3的部分思路和解决方案,在此向这三位博主表示感谢。在今后我也会将自己做过的一些有趣的小项目整理、分享出来,所以,欢迎点赞收藏加关注啦?
5.29 更新
最近收到好多读者评论要源代码,就把下载链接贴在这里供大家学习分享:
http://vertex.tpddns.cn:81/nextcloud/index.php/s/xyRJZSBAsGLgRDT(个人服务器可能不稳定,无法下载请联系博主)
密码:hit_block
拿走代码别忘了留下三连~