关于爬虫程序的418+403报错。
0.按F12打开“开发者调试页面“
如下图所示:按步骤,选中2页面,选中3操作,开始监控网络活动,然后操作刷新界面,找到4位置,右侧滚动条拉到最上就可以找到,往下拉可以看到一些浏览器访问的信息,我们需要把我们的python程序,伪装成浏览器。
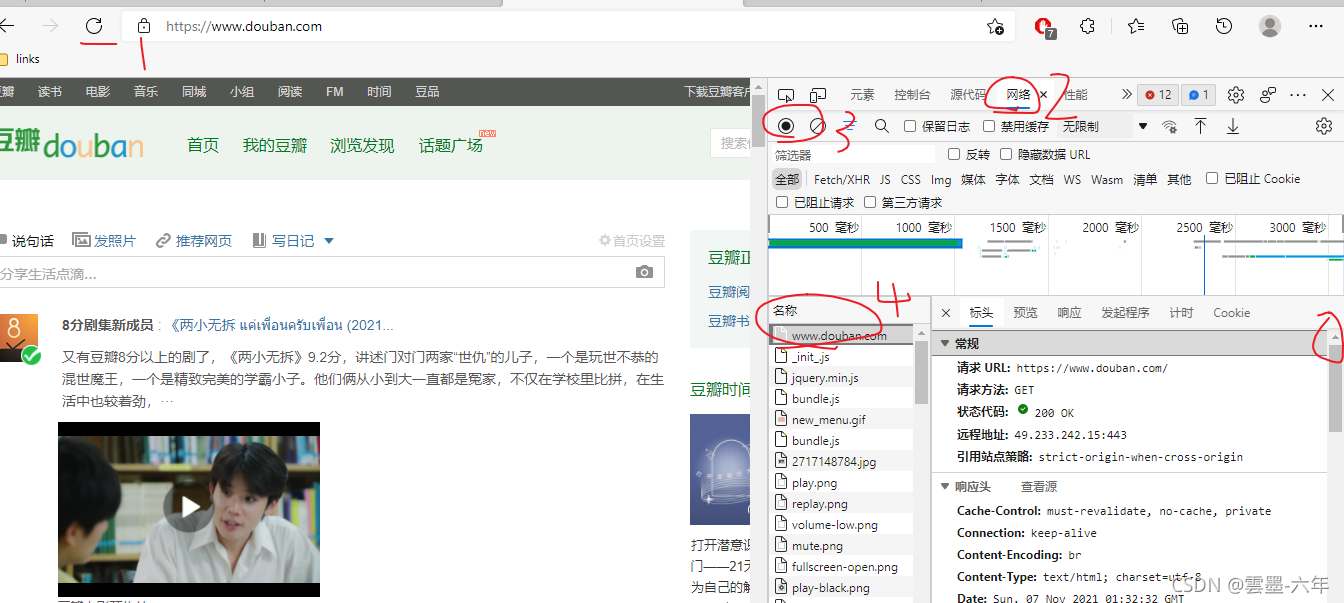
第一个user—agent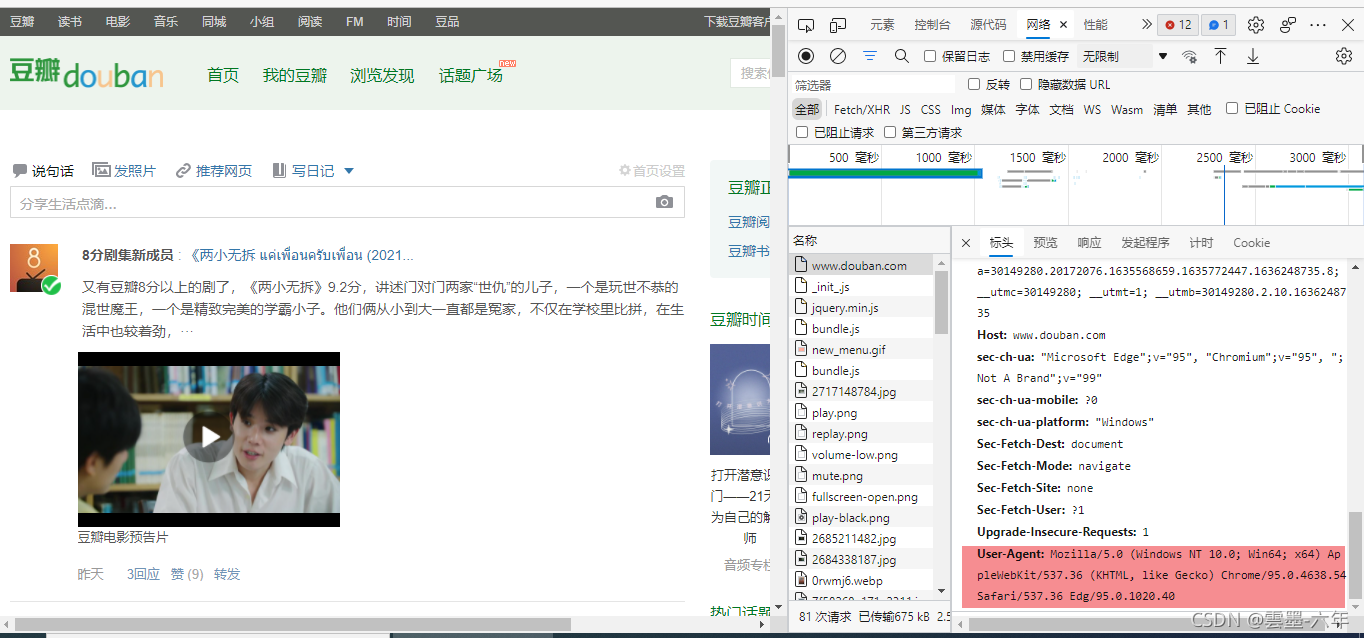
第二个就是cookie信息(简单理解就是我们的登陆信息。)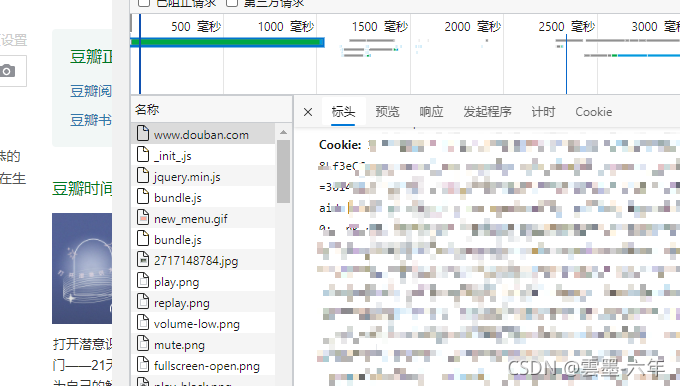
1.在head信息加入 user—agent可以模拟浏览器访问
不加此信息,会报418错误。
长期访问会有403报错。
2.在head中加入cookie信息,然后调用,(为的是模拟我们用户的登陆)
head = {
"User-Agent": "信息",
"cookie": '''cookie信息'''}
祝大家学习顺利。
版权声明:本文为weixin_42710807原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。