#等频分箱
def frequencybox(demo, name, new_name, n):
demo["tmp"] = pd.qcut(demo[name],n)
group_by_age_bin = demo.groupby(["tmp"],as_index=True)
df_min_max_bin = pd.DataFrame()#用来记录每个箱体的最大最小值
df_min_max_bin["min_bin"] = group_by_age_bin[name].min()
df_min_max_bin["max_bin"] = group_by_age_bin[name].max()
df_min_max_bin.reset_index(inplace=True)
q = df_min_max_bin["tmp"].values
dicc = {}
for i in range(len(q)):
dicc[str(q[i])] = i+1
demo["tmp"] = demo["tmp"].apply(lambda x: str(x))
if(new_name==name):
demo.drop(name, axis=1, inplace=True)
demo[new_name] = demo["tmp"].map(dicc)
demo.drop("tmp", axis=1, inplace=True)
lm = all_feature.copy()
frequencybox(lm, "客户年龄","客户年龄", 5)
报错:
Bin edges must be unique: array([ 1., 1., 1., 1., 1., 1., 1., 1., 2., 3., 89.]).
You can drop duplicate edges by setting the ‘duplicates’ kwarg
解决方案;
http://www.cocoachina.com/articles/459499
https://stackoverflow.com/questions/20158597/how-to-qcut-with-non-unique-bin-edges
原来
pd.qcut(df, nbins)
变为
pd.qcut(df.rank(method=‘first’), nbins)
支持多列转换,并返回切分表格:
### 导出iv值 特征
iv_feature = tmp_feature.copy()
###等频分箱 NaN不进行分箱 还作为NaN出现
def frequencybox(demo, name_list, new_name_list, n):
# demo : 输入原始df表
# name_list :demo表中原始字段组成list
# new_name_list :希望分箱后特征名称 所组成list name_list[i]可与new_name_list[i]重名
# n: 分桶数
if (len(name_list)!= len(new_name_list)):
print("输入参数数量不一致!!!")
return
result_df = pd.DataFrame()
for i in range(len(name_list)):
df_min_max_bin = pd.DataFrame()#用来记录每个箱体的最大最小值
name = name_list[i]
new_name = new_name_list[i]
demo["tmp"] = pd.qcut(demo[name].rank(method='first'), n)
group_by_age_bin = demo.groupby(["tmp"],as_index=True)
df_min_max_bin["min_bin"] = group_by_age_bin[name].min()
df_min_max_bin["max_bin"] = group_by_age_bin[name].max()
df_min_max_bin["feature_name"] = name
df_min_max_bin.reset_index(inplace=True)
if(len(df_min_max_bin)==0):
result_df = df_min_max_bin
else:
result_df = pd.concat([result_df, df_min_max_bin])
# result_df = result_df.append(df_min_max_bin)
q = df_min_max_bin["tmp"].values
dicc = {}
for i in range(len(q)):
dicc[str(q[i])] = i+1
demo["tmp"] = demo["tmp"].apply(lambda x: str(x))
if(new_name==name):
demo.drop(name, axis=1, inplace=True)
demo[new_name] = demo["tmp"].map(dicc)
demo.drop("tmp", axis=1, inplace=True)
# result_df.drop("index", inplace=True)
result_df.reset_index(inplace=True)
result_df.drop("index", axis =1 , inplace=True)
# result_df = result_df.loc[:,~result_df.columns.isin(["index"])]
return result_df
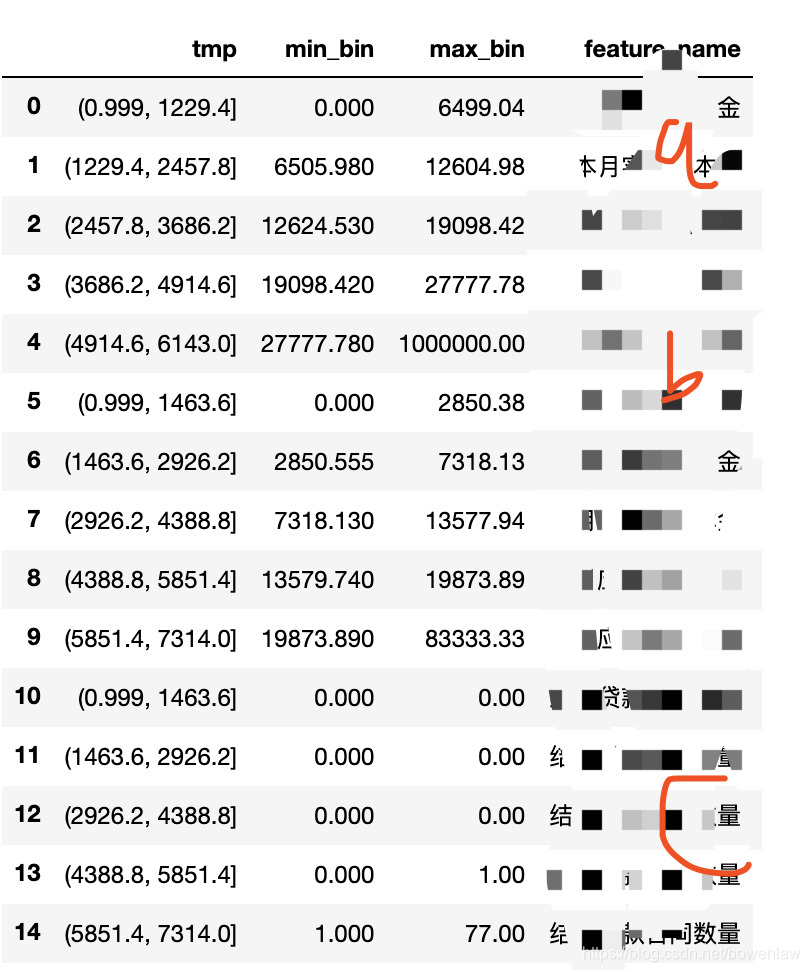
result_df = frequencybox(iv_feature, ["a","b","c"],["a","b","c"], 5)
result_df.head(20)
结果:
升级为增加WoE和IV属性
def frequencybox(demo, name_list, new_name_list, n, sum_label_1, sum_label_0, label_name):
# demo : 输入原始df表
# name_list :demo表中原始字段组成list
# new_name_list :希望分箱后特征名称 所组成list name_list[i]可与new_name_list[i]重名
# n: 分桶数
if (len(name_list)!= len(new_name_list)):
print("输入参数数量不一致!!!")
return
result_df = pd.DataFrame()
for i in range(len(name_list)):
df_min_max_bin = pd.DataFrame()#用来记录每个箱体的最大最小值
name = name_list[i]
new_name = new_name_list[i]
demo["tmp"] = pd.qcut(demo[name].rank(method='first'), n)
group_by_age_bin = demo.groupby(["tmp"],as_index=True)
df_min_max_bin["min"] = group_by_age_bin[name].min()
df_min_max_bin["max"] = group_by_age_bin[name].max()
df_min_max_bin["feature_name"] = name
df_min_max_bin.reset_index(inplace=True)
df_min_max_bin["valueFrom"] = df_min_max_bin["min"]
df_min_max_bin["valueTo"] = df_min_max_bin["max"]
df_min_max_bin["count"] = -100
df_min_max_bin["nums_label_1"] = -10
df_min_max_bin["nums_label_0"] = -10
for i in range(0,len(df_min_max_bin)):
if (i==len(df_min_max_bin)-1):
df_min_max_bin.loc[i, "valueTo"] = df_min_max_bin.loc[i, "max"] + 0.01
else:
if(i!=0):
df_min_max_bin.loc[i, "valueFrom"] = df_min_max_bin.loc[i-1, "valueTo"]
mmin = df_min_max_bin.loc[i, "valueFrom"]
mmax = df_min_max_bin.loc[i, "valueTo"]
tmp_de = demo[(demo[name]>=mmin) & (demo[name]<mmax)]
print("第"+str(i)+"个分箱数量为:"+ str(len(tmp_de)))
df_min_max_bin.loc[i, "count"] = len(tmp_de)
df_min_max_bin.loc[i, "nums_label_1"] = len(tmp_de[tmp_de[label_name]==1])
df_min_max_bin.loc[i, "nums_label_0"] = len(tmp_de[tmp_de[label_name]==0])
df_min_max_bin.loc[i, "min"] = tmp_de[name].min()
df_min_max_bin.loc[i, "max"] = tmp_de[name].max()
df_min_max_bin = df_min_max_bin[~(df_min_max_bin['valueFrom']>df_min_max_bin["valueTo"])]
for x in ["tmp","min", "max", "valueFrom", "valueTo"]:
df_min_max_bin[x] = df_min_max_bin[x].apply(lambda x: str(x))
sum_nonull = df_min_max_bin["count"].sum()
sum_count = sum_label_1 + sum_label_0
if sum_nonull < sum_count:
null_demo = demo[demo[name].isnull()]
# null_label_1 = null_demo[label_name].value_counts()[1]
# null_label_0 = null_demo[label_name].value_counts()[0]
null_label_1 = len(null_demo[null_demo[label_name]==1])
null_label_0 = len(null_demo[null_demo[label_name]==0])
sum_null = sum_count-sum_nonull
ha_dic = {"tmp":"null", "min":"null", "max":"null", "feature_name":name,
"valueFrom":"null", "valueTo":"null", "count":sum_null,
"nums_label_1":null_label_1, "nums_label_0":null_label_0}
haha = pd.DataFrame(data = ha_dic,index = [0])
haha["tmp"] = haha["tmp"].astype('category')
df_min_max_bin= pd.concat([df_min_max_bin,haha])
df_min_max_bin["ok1"] = ((df_min_max_bin["nums_label_1"]+1)/sum_label_1)/((df_min_max_bin["nums_label_0"]+1)/sum_label_0)
df_min_max_bin["WoE"] = np.log(df_min_max_bin["ok1"])
df_min_max_bin["ok2"] = ((df_min_max_bin["nums_label_1"]+1)/sum_label_1)-((df_min_max_bin["nums_label_0"]+1)/sum_label_0)
df_min_max_bin["IV"] = df_min_max_bin["ok2"]*df_min_max_bin["WoE"]
df_min_max_bin["IVs"] = df_min_max_bin["IV"].sum()
if(len(df_min_max_bin)==0):
result_df = df_min_max_bin
else:
result_df = pd.concat([result_df, df_min_max_bin])
q = df_min_max_bin["tmp"].values
dicc = {}
for i in range(len(q)):
dicc[str(q[i])] = i+1
demo["tmp"] = demo["tmp"].apply(lambda x: str(x))
if(new_name==name):
demo.drop(name, axis=1, inplace=True)
demo[new_name] = demo["tmp"].map(dicc)
demo.drop("tmp", axis=1, inplace=True)
result_df.reset_index(inplace=True)
result_df.drop("index", axis =1 , inplace=True)
res_columns = ["feature_name", "valueFrom", "valueTo", "max", "min", "count", "WoE", "IV", "IVs"]
result_df = result_df[res_columns]
return result_df
版权声明:本文为bowenlaw原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。