简介
主页:https://sirwyver.github.io/AutoRF/
AutoRF:学习一种规范化的、以对象为中心的表示,其嵌入描述并分离形状、外观和姿势。(把车这个对象提取出来)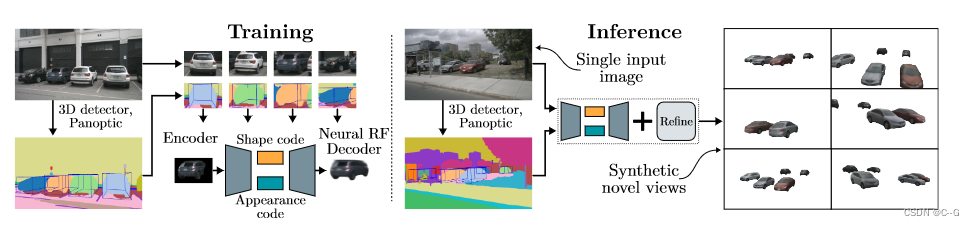
只从单个视图观察对象实例,并且没有使用先验知识。
目标是将场景中出现的每个3D对象编码成一个紧凑的表示形式,这样可以有效地将对象存储到数据库中,并在以后的阶段从不同的视图/上下文重新合成它们
利用预训练的实例或泛视分割算法来识别图像中属于同一物体实例的二维像素,以及预训练的单眼三维物体检测器,以获得物体在三维空间中的姿态先验
训练和测试时,假设为每个图像获取一组带有相关2D掩码的3D边界框,它们代表被检测对象实例和相机标定信息,通过利用关于物体3D边界框的信息,可以将物体表示从实际的物体姿态和比例中分离出来。实际上,获得了一种标准化的、以对象为中心的编码,它被分解为形状和外观组件。
类似于有条件的NeRF模型,形状代码用于约束占用网络,该网络输出给定归一化对象空间中的3D点的密度,外观代码用于约束给定三维点和归一化对象空间中的观看方向的RGB颜色的外观网络
贡献点
- 引入了基于3D对象先验的新型视图合成,仅从单一视图中学习,在野外观察中,对象可能被遮挡,有很大的尺度变异性,并可能遭受图像质量下降。既没有利用同一对象的多个视图,也没有利用大型CAD模型库,也没有建立在特定的、预定义的形状先验之上。
- 成功地利用了机器生成的 3D边界盒和泛视分割掩码,以及不完善的注释来学习隐式对象表示,可以应用于对现实数据的新视图合成。以前的大多数工作都是在合成数据上进行实验,或者要求感兴趣的对象是无遮挡的和图像的主要内容(利用的遮罩除外)。
- 有效地编码感兴趣对象的形状和外观属性,能够在单个镜头中解码为一个新的视图,并可选地在测试时进一步微调。这使得从潜在的领域转移和在不同的数据集上进行修正成为可能,这是迄今为止还没有被证明的。
实现流程
给定一个RGB图像与相应的3D对象边界框和占用掩码,自动编码器学习在单独的代码中编码形状和外观。这些代码使各个解码器重新呈现给定视图的输入图像。
Preliminaries
Image I
给定一个二维图像,其中有多个感兴趣的对象,运行一个三维对象检测器并进行泛视分割,以便为每个对象实例提取一个三维边界框和一个实例掩码
边界框和掩码用来生成被检测对象实例的掩码2D图像 I,以匹配固定的输入分辨率。
3D边界框捕获相机空间中物体的范围、位置和旋转
分割掩模提供关于场景中其他物体可能遮挡的逐像素信息
图 I 中像素 u∈U 的RGB颜色用 I u ∈ R 3 I_u∈R^3Iu∈R3 表示,其中 u 表示其像素集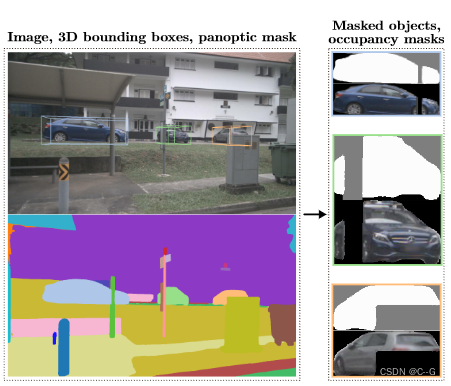
预处理步骤:首先,使用预训练的模型在3D中检测感兴趣的物体,并对图像进行分割。然后,我们裁剪每个对象视图并计算它们的占用掩码(白色:前景,黑色:背景,灰色:未知)。
Normalized Object Coordinate Space O
每个对象实例都有一个相关的3D边界框 β,它在相机空间中标识一个矩形长方体,描述相关对象的姿态和范围,同时每个3D边界框都可以被转换、旋转和缩放成一个单位立方体,将包含在三维边界框 β 中的三维点可以通过微分同构映射到(居中)单位立方体 O : = [ − 1 / 2 , 1 / 2 ] 3 O:=[−1/2,1/ 2]^3O:=[−1/2,1/2]3,称为归一化对象坐标空间(NOCS),因此,将点从相机空间映射到NOCS
Object-Centric Camera γ
每个描绘3D场景的图像 I 都有一个相关联的相机,用 ρ 表示,摄像机 ρ 将像素 u∈U 映射到摄像机空间中的 unit-speed 射线,由 ρ u : R + → R 3 ρ_u: R_+→R^3ρu:R+→R3 表示,其中 ρ u ( t ) ρ_u(t)ρu(t) 给出了时刻 t 时沿射线的3D点。通过利用给定物体的边界框 β,可以将摄像机空间中的每条射线 ρ u ρ_uρu 映射到NOCS,产生以物体为中心的射线 γ u γ_uγu,γ u γ_uγu 是重新映射射线 β ◦ ρ u β◦ρ_uβ◦ρu 的单位速度再参数化。称 γ 为给定物体的以物体为中心的照相机
Occupancy Mask Y
使用泛视分割产生一个与物体的图像 I 相关联的二维占用掩模 Y,占用掩码 Y 为每个像素 u∈U 提供一个类标签 Y u ∈ { + 1 , 0 , 1 } Y_u∈\{+ 1,0,1\}Yu∈{+1,0,1}。前景像素,即属于对象实例掩码的像素,被分配为标签+1,背景像素,即没有遮挡感兴趣的对象的像素,被分配为标签−1。无法确定是否遮挡对象的像素被分配为标签0。
如果一个像素属于不遮挡感兴趣的对象的语义类别(例如,对于汽车,我们有天空、道路、人行道等),那么它就被分配为背景标签
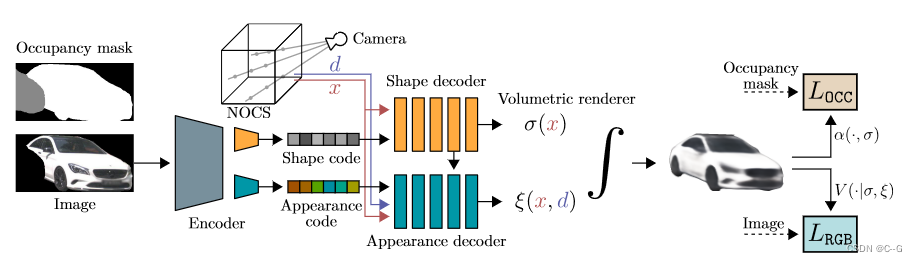
Architecture Overview
input (I, γ, Y )
输入数据为:将检测到的物体的图像 I ,利用物体的三维包围盒信息得到的NOCS中对应的摄像机 γ,利用全景分割得到的占用掩码 Y
Shape and Appearance Encoder Φ E Φ_EΦE
编码器 Φ E Φ_EΦE包括一个CNN特征提取器,将描述给定目标的输入图像 I 的特征提取,输出馈送给两个并行头的中间特征,分别负责编码为形状码 ϕ S \phi_SϕS 和外观码 ϕ A \phi_AϕA,即 ( ϕ S , ϕ A ) : = Φ E ( I ) (\phi_S,\phi_A):= Φ_E(I)(ϕS,ϕA):=ΦE(I)
Shape Decoder Ψ S Ψ_SΨS
形状码 ϕ S \phi_SϕS 被输入到一个解码器网络 Ψ S Ψ_SΨS,该解码器网络隐式输出一个占用网络 σ,即 σ := Ψ S ( ϕ S ) Ψ_S(\phi_S)ΨS(ϕS)。该占用网络σ: O → R + O→R_+O→R+ 输出给定 3D点 x∈O 在NOCS中的密度
Appearance Decoder Ψ A Ψ_AΨA
与形状解码器相反,外观解码器 Ψ A Ψ_AΨA 接受形状和外观代码的输入,并隐式输出一个图形网络 ξ,ξ := Ψ A ( ϕ A , ϕ S ) Ψ_A(\phi_A,\phi_S)ΨA(ϕA,ϕS),图形网络 ξ: O × S 2 → R 3 O×S^2→R^3O×S2→R3 输出给定3D点 x∈O 和单位3D球体 S 2 S^2S2 上的观看方向 d 的RGB颜色
Volume Renderer V
占用网络 σ 和外观网络 ξ 在NOCS中形成一个代表对象的辐射场,通过渲染以物体为中心的射线 γ u γ_uγu 来计算与 u 相关的颜色。只对感兴趣的物体建模感兴趣,以物体为中心的光线被限制在与 o 相交的点上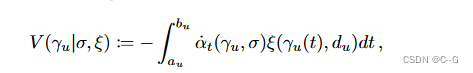
其中[ a u , b u ] [a_u, b_u][au,bu] 是 γ u γ_uγu 与O相交的 time-window,d u ∈ S 2 d_u∈S^2du∈S2是 γ u γ_uγu的unit velocity
a ^ t \hat{a}_ta^t表示累积透过率沿射线 γ u γ_uγu 在 [ a u , t ] [a_u, t][au,t] 的范围内的time derivative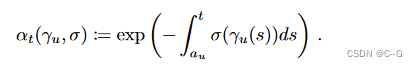
体积渲染器 V 中的积分可以通过利用沿光线的采样点用求积规则求解
Training
损失函数包括光度损失和占用损失,给定的训练示例 Ω = (I, γ, Y)提供了损失,包括图像 I、占用掩模 Y 和以对象为中心的摄像机 γ
假设对象的亮度场 (σ, ξ) 已经从 I 中使用编码器Φ E Φ_EΦE和解码器Ψ S Ψ_SΨS和Ψ A Ψ_AΨA计算出来,通过 Θ 表示体系结构中涉及的所有可学习参数
Photometric Loss L R G B L_{RGB}LRGB
光度损失项类似于自动编码器损失,因为它迫使模型在使用 Φ E Φ_EΦE 将其编码为形状和外观代码,使用 Ψ S Ψ_SΨS 和 Ψ A Ψ_AΨA 将其解码为物体亮度场,最后使用体积渲染器 V 渲染之后,适合给定的输入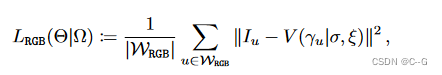
W⊂U 仅包含前景像素,以物体为中心的射线 γ u γ_uγu 与 O 相交的 Y u = + 1 Y_u = +1Yu=+1
Occupancy Loss L O C C L_{OCC}LOCC
使用泛视分割来推断一个像素是前景、背景还是未知像素,该信息编码在占用掩模 Y 中,用于直接监督体绘制方程 V 的累积透射率分量 α,事实上,α ( γ u , σ ) : = α b u ( γ u , σ ) α(γ_u, σ):= α_{b_u} (γ_u, σ)α(γu,σ):=αbu(γu,σ)表示物体不与射线 γ u γ_uγu 相交的概率,或者换句话说,u 可能是一个背景像素,类似地,1 − α ( γ u , σ ) 1−α(γ_u, σ)1−α(γu,σ) 是 u 成为前景像素的概率,直接对累积透过率进行分类损失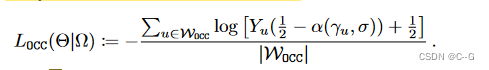
W O C C ⊂ U W_{OCC}⊂UWOCC⊂U 仅包含前景或背景像素,即 Y u ≠ 0 Y_u \neq0Yu=0,射线γ u γ_uγu 与O相交。
Final Loss L
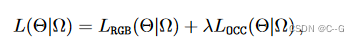
占用损失由超参数 λ≥0 调制
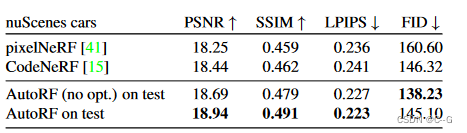
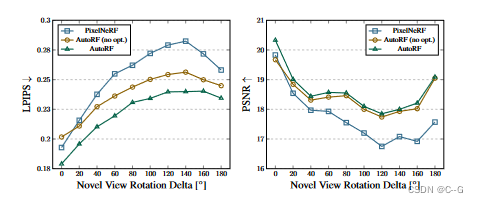
效果