hadoop生态圈之hive面试(一)
说下为什么要使用Hive?Hive的优缺点?Hive的作用是什么?
问过的一些公司:头条,字节x2,阿里参考答案:
1、为什么要使用Hive?
Hive是Hadoop生态系统中比不可少的一个工具,它提供了一种SQL(结构化查询语言)方言,可以查询存 储在Hadoop分布式文件系统(HDFS)中的数据或其他和Hadoop集成的文件系统,如MapR-FS、Amazon 的S3和像HBase(Hadoop数据仓库)和Cassandra这样的数据库中的数据。
大多数数据仓库应用程序都是使用关系数据库进行实现的,并使用SQL作为查询语言。Hive降低了将这 些应用程序转移到Hadoop系统上的难度。凡是会使用SQL语言的开发人员都可以很轻松的学习并使用 Hive。如果没有Hive,那么这些用户就必须学习新的语言和工具,然后才能应用到生产环境中。另外, 相比其他工具,Hive更便于开发人员将基于SQL的应用程序转移到Hadoop中。如果没有Hive,那么开发 者将面临一个艰巨的挑战,如何将他们的SQL应用程序移植到Hadoop上。
2、Hive优缺点优点
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
- 避免了去写MapReduce,减少开发人员的学习成本。
- Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
- Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点 - Hive的HQL表达能力有限迭代式算法无法表达
数据挖掘方面不擅长,由于MapReduce数据处理流程的限制,效率更高的算法却无法实现。 - Hive的效率比较低
Hive自动生成的MapReduce作业,通常情况下不够智能化Hive调优比较困难,粒度较粗
Hive不是一个完整的数据库。Hadoop以及HDFS的设计本身约束和局限性地限制了Hive所能胜任的工
作。其中最大的限制就是Hive不支持记录级别的更新、插入或者删除操作。但是用户可以通过查询生成 新表或者将查询结果导入到文件中。同时,因为Hadoop是面向批处理的系统,而MapReduce任务
(job)的启动过程需要消耗较长的时间,所以Hive查询延时比较严重。传统数据库中在秒级别可以完成 的查询,在Hive中,即使数据集相对较小,往往也需要执行更长的时间。
3、Hive的作用
Hive是由Facebook开源用于解决海量结构化日志的数据统计工具。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功 能。
Hive的本质是将HQL转化成MapReduce程序
Hive处理的数据存储在HDFS
Hive分析数据底层的实现是MapReduce
执行程序运行在Yarn上
说下Hive是什么?跟数据仓库区别?
可回答:1)说下对Hive的了解;2)介绍下Hive
问过的一些公司:美团,360,字节,大华(2021.07),海康(2021.09) 参考答案:
Hive是由Facebook开源用于解决海量结构化日志的数据统计工具。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功 能。
Hive的本质是将HQL转化成MapReduce程序
Hive处理的数据存储在HDFS
Hive分析数据底层的实现是MapReduce
执行程序运行在Yarn上
数据仓库是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储, 出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、 成本、质量以及控制。
数据仓库存在的意义在于对企业的所有数据进行汇总,为企业各个部门提供统一的, 规范的数据出口。
Hive架构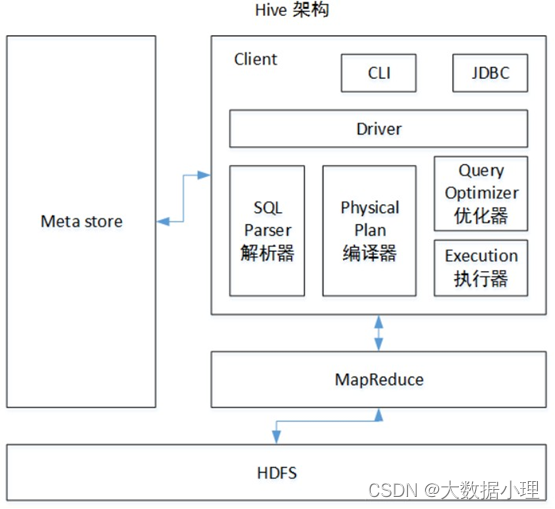
可回答:Hive的基本架构,角色,与HDFS的关系? 问过的一些公司:腾讯微众,好未来,恒生(2021.09) 参考答案:
用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)
元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否 是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
使用HDFS进行存储,使用MapReduce进行计算。
驱动器:Driver
1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成, 比如antlr;
对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。2)编译器(Physical Plan):将AST编译生成逻辑执行计划。3)优化器(Query Optimizer):对逻辑执行计划进行优化。
4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
Hive内部表和外部表的区别?
问过的一些公司:字节,阿里社招,快手,美团x2,蘑菇街x2,祖龙娱乐,作业帮x3,360,小米,竞 技世界,猿辅导,好未来,多益,多益(2021.09),富途,冠群驰聘,大华(2021.07),字节(2021.08)
参考答案:
内部表(managed table):未被external修饰外部表(external table):被external修饰
区别:
- 内部表数据由Hive自身管理,外部表数据由HDFS管理;
- 内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据 的存储位置由自己制定(如果没有LOCATION,Hive将在HDFS上的/user/hive/warehouse文件夹下以外部 表的表名创建一个文件夹,并将属于这个表的数据存放在这里);
- 删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的 文件并不会被删除;
- 对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复
(MSCK REPAIR TABLE table_name;)。
为什么内部表的删除,就会将数据全部删除,而外部表只删除表结构? 为什么用外部表更好?
问过的一些公司:大华参考答案:
外部表和内部表创建表以及删除时的区别
创建表时:创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所 在的路径,不对数据的位置做任何改变。
删除表时:在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
外部表的优点
- 外部表不会加载数据到Hive的默认仓库(挂载数据),减少了数据的传输,同时还能和其他外部表 共享数据。
- 使用外部表,Hive不会修改源数据,不用担心数据损坏或丢失。
- Hive在删除外部表时,删除的只是表结构,而不会删除数据。
Hive建表语句?创建表时使用什么分隔符?
问过的一些公司:作业帮,美团,京东参考答案:
1、建表语句
- CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
- [(col_name data_type [COMMENT col_comment], …)]
- [COMMENT table_comment]
- [PARTITIONED BY (col_name data_type [COMMENT col_comment], …)]
- [CLUSTERED BY (col_name, col_name, …)
- [SORTED BY (col_name [ASC|DESC], …)] INTO num_buckets BUCKETS]
- [ROW FORMAT row_format]
- [STORED AS file_format]
- [LOCATION hdfs_path]
- [TBLPROPERTIES (property_name=property_value, …)]
- [AS select_statement]
字段解释说明 - CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常; 用户可以用
IF NOT EXISTS 选项来忽略这个异常。 - EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实 际数据的路径
(LOCATION),在删除表的时候,内部表的元数据和数据会被一起删除,而外 部表只删除元数据,不删除数据。 - COMMENT:为表和列添加注释。
- PARTITIONED BY:创建分区表
- CLUSTERED BY:创建分桶表
- SORTED BY:不常用,对桶中的一个或多个列另外排序
- ROW FORMAT
- DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
- | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, …)]
用户在建表的时候可以自定义SerDe或者使用自带的SerDe。如果没有指定ROW FORMAT或者ROW FORMAT DELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。
SerDe是Serialize/Deserilize的简称,hive使用Serde进行行对象的序列与反序列化。 - STORED AS:指定存储文件类型 常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、
TEXTFILE(文本)、RCFILE(列式存储格式文件)。
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
- LOCATION:指定表在HDFS上的存储位置。
- AS:后跟查询语句,根据查询结果创建表。
- LIKE:允许用户复制现有的表结构,但是不复制数据。
2、分隔符
我们在建表的时候就指定了导入数据时的分隔符,建表的时候会有三种场景需要考虑: 正常建表(default);
指定特定的特殊符号作为分隔符;
使用多字符作为分隔符。
53 正常建表,采用默认的分隔符
hive 默认的字段分隔符为ascii码的控制符\001,建表的时候用fields terminated by ‘\001’,如果要测试的话, 造数据在vi 打开文件里面,用ctrl+v然后再ctrl+a可以输入这个控制符\001。按顺序,\002的输入方式为ctrl+v,ctrl+b。以此类推。
54 指定特定的特殊符号作为分隔符
1 CREATE TABLE test(id int, name string ,tel string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’LINES TERMINATED BY ‘\n’STORED AS TEXTFILE;
上面使用了’\t’作为了字段分隔符,’\n’作为换行分隔符。如果有特殊需求,自己动手改一下这两个符号 就行了。
3、使用多字符作为分隔符
假设我们使用【##】来作为字段分隔符,【\n】作为换行分隔符,则这里有两个方法: 使用MultiDelimitSerDe的方法来实现:
1 CREATE TABLE test(id int, name string ,tel string) ROW FORMAT SERDE ‘org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe’ WITH SERDEPROPERTIES (“field.delim”=“##”) LINES TERMINATED BY '\n’STORED AS TEXTFILE;
使用RegexSerDe的方法实现:
1 CREAET TABLE test(id int, name string ,tel string) ROW FORMAT SERDE ‘org.apache.hadoop.hive.contrib.serde2.RegexSerDe’ WITH SERDEPROPERTIES (“input.regex” = “^(.)\#\#(.)$”) LINES TERMINATED BY '\n’STORED AS TEXTFILE;
Hive删除语句外部表删除的是什么?
问过的一些公司:作业帮参考答案:
外部表只删除元数据,不删除数据
Hive数据倾斜以及解决方案
可回答:1)Hive使用过程中遇到了什么问题?2)两张大表的join怎么执行的;综合去回答,不要太死 板
问过的一些公司:字节,字节(2021.07)-(2021.08)x2,美团x7,阿里云x2,快手x3,小米,有赞x2,腾 讯,顺丰x2,携程x2,东软集团,多益,多益(2021.09),抖音,一点咨询,作业帮,东方头条,网易,
好未来,端点数据(2021.07),58同城(2021.08),海康(2021.08),阿里蚂蚁(2021.08),兴业数金(2021.09), 有赞(2021.09),京东(2021.09),唯品会(2021.10),联想(2021.10)
参考答案:
1、什么是数据倾斜
数据倾斜主要表现在,map/reduce程序执行时,reduce节点大部分执行完毕,但是有一个或者几个reduce节点运行很慢,导致整个程序的处理时间很长,这是因为某一个key的条数比其他key多很多(有时 是百倍或者千倍之多),这条Key所在的reduce节点所处理的数据量比其他节点就大很多,从而导致某几 个节点迟迟运行不完。
2、数据倾斜的原因一些操作:
关键词 情形 后果
Join 其中一个表较小,但是
key集中 分发到某一个或几个Reduce上的数据远高于平均值
大表与大表,但是分桶的判断字段0值或空值过多 这些空值都由一个
reduce处理,灰常慢
group by group by 维度过小,某值的数量过多 处理某值的reduce灰常耗时
Count Distinct 某特殊值过多 处理此特殊值的reduce耗时
原因:
key分布不均匀
业务数据本身的特性建表时考虑不周
某些SQL语句本身就有数据倾斜
现象:
任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce 子任务未完成。因为其处理的数据量和其他reduce差异过大。
单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
3、数据倾斜的解决方案
- 参数调节
1 hive.map.aggr = true
Map 端部分聚合,相当于Combiner
1 hive.groupby.skewindata=true
有数据倾斜的时候进行负载均衡,当选项设定为true,生成的查询计划会有两个MR Job。第一个MR Job 中,Map 的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key 被分布到同一个Reduce中),最后完成最终的聚合操作。
55 SQL语句调节
如何join:
关于驱动表的选取,选用join key分布最均匀的表作为驱动表,做好列裁剪和filter操作,以达到两表做join的时候,数据量相对变小的效果。
大小表Join:
使用map join让小的维度表(1000条以下的记录条数)先进内存。在map端完成reduce。大表Join大表:
把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处 理后并不影响最终结果。
count distinct大量相同特殊值:
count distinct时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
group by维度过小:
采用sum() group by的方式来替换count(distinct)完成计算。特殊情况特殊处理:
在业务逻辑优化效果的不大情况下,有些时候是可以将倾斜的数据单独拿出来处理。最后union回去。
4、典型的业务场景
空值产生的数据倾斜
场景:如日志中,常会有信息丢失的问题,比如日志中的 user_id,如果取其中的 user_id 和 用户表中的
user_id 关联,会碰到数据倾斜的问题。
解决方法一:user_id为空的不参与关联select * from log a
join users b
on a.user_id is not null
and a.user_id = b.user_id
union all
select * from log a
where a.user_id is null;
解决方法二:赋与空值分新的key值select *
from log a
left outer join users b
on case when a.user_id is null then concat(‘hive’,rand() ) else a.user_id end = b.user_id;
结论:
方法2比方法1效率更好,不但io少了,而且作业数也少了。解决方法一中log读取两次,jobs是2。解决 方法二job数是1。这个优化适合无效id (比如 -99 , ’’, null 等) 产生的倾斜问题。把空值的key变成一个字符串加上随机数,就能把倾斜的数据分到不同的reduce上,解决数据倾斜问题。
56 不同数据类型关联产生数据倾斜
场景:用户表中user_id字段为int,log表中user_id字段既有string类型也有int类型。当按照user_id进行两 个表的Join操作时,默认的Hash操作会按int型的id来进行分配,这样会导致所有string类型id的记录都分 配到一个Reducer中。
解决方法:把数字类型转换成字符串类型select * from users a
left outer join logs b
on a.usr_id = cast(b.user_id as string);
57 小表不小不大,怎么用 map join 解决倾斜问题
使用map join解决小表(记录数少)关联大表的数据倾斜问题,这个方法使用的频率非常高,但如果小表很大,大到map join会出现bug或异常,这时就需要特别的处理。
例子:select * from log a
left outer join users b
on a.user_id = b.user_id;
users表有600w+的记录,把users分发到所有的map上也是个不小的开销,而且map join不支持这么大的小表。如果用普通的join,又会碰到数据倾斜的问题。
解决方法:select /+mapjoin(x)/* from log a
left outer join (
select /+mapjoin©/d.*
from ( select distinct user_id from log ) c
join users d
on c.user_id = d.user_id
) x
on a.user_id = b.user_id;
假如,log里user_id有上百万个,这就又回到原来map join问题。所幸,每日的会员uv不会太多,有交易的会员不会太多,有点击的会员不会太多,有佣金的会员不会太多等等。所以这个方法能解决很多场景 下的数据倾斜问题。
Hive如果不用参数调优,在map和reduce端应该做什么
问过的一些公司:阿里参考答案:
1、map阶段优化
Map阶段的优化,主要是确定合适的map数。那么首先要了解map数的计算公式
1 num_reduce_tasks = min[h i v e . e x e c . r e d u c e r s . m a x , ( {hive.exec.reducers.max}, (hive.exec.reducers.max,({input.size}/h i v e . e x e c . r e d u c e r s . b y t e s . p e r . r e d u c e r ) ] m a p r e d . m i n . s p l i t . s i z e : 指的是数据的最小分割单元大小; m i n 的默认值是 1 B m a p r e d . m a x . s p l i t . s i z e : 指的是数据的最大分割单元大小; m a x 的默认值是 256 M B d f s . b l o c k . s i z e : 指的是 H D F S 设置的数据块大小。个已经指定好的值,而且这个参数默认情况下 h i v e 是识别不到的。通过调整 m a x 可以起到调整 m a p 数的作用,减小 m a x 可以增加 m a p 数,增大 m a x 可以减少 m a p 数。需要提醒的是,直接调整 m a p r e d . m a p . t a s k s 这个参数是没有效果的。 2 、 r e d u c e 阶段优化这里说的 r e d u c e 阶段,是指前面流程图中的 r e d u c e p h a s e (实际的 r e d u c e 计算)而非图中整个 r e d u c e t a s k 。 R e d u c e 阶段优化的主要工作也是选择合适的 r e d u c e t a s k 数量 , 与 m a p 优化不同的是, r e d u c e 优化时,可以直接设置 m a p r e d . r e d u c e . t a s k s 参数从而直接指定 r e d u c e 的个数。 1 n u m r e d u c e t a s k s = m i n [ {hive.exec.reducers.bytes.per.reducer})] mapred.min.split.size: 指的是数据的最小分割单元大小;min的默认值是1B mapred.max.split.size: 指的是数据的最大分割单元大小;max的默认值是256MB dfs.block.size: 指的是HDFS设置的数据块大小。个已经指定好的值,而且这个参数默认情况下hive 是识别不到的。 通过调整max可以起到调整map数的作用,减小max可以增加map数,增大max可以减少map数。需要提 醒的是,直接调整mapred.map.tasks这个参数是没有效果的。 2、reduce阶段优化 这里说的reduce阶段,是指前面流程图中的reduce phase(实际的reduce计算)而非图中整个reduce task。Reduce阶段优化的主要工作也是选择合适的reduce task数量, 与map优化不同的是,reduce优化时,可以直接设置mapred.reduce.tasks参数从而直接指定reduce的个数。 1 num_reduce_tasks = min[hive.exec.reducers.bytes.per.reducer)]mapred.min.split.size:指的是数据的最小分割单元大小;min的默认值是1Bmapred.max.split.size:指的是数据的最大分割单元大小;max的默认值是256MBdfs.block.size:指的是HDFS设置的数据块大小。个已经指定好的值,而且这个参数默认情况下hive是识别不到的。通过调整max可以起到调整map数的作用,减小max可以增加map数,增大max可以减少map数。需要提醒的是,直接调整mapred.map.tasks这个参数是没有效果的。2、reduce阶段优化这里说的reduce阶段,是指前面流程图中的reducephase(实际的reduce计算)而非图中整个reducetask。Reduce阶段优化的主要工作也是选择合适的reducetask数量,与map优化不同的是,reduce优化时,可以直接设置mapred.reduce.tasks参数从而直接指定reduce的个数。1numreducetasks=min[{hive.exec.reducers.max}, (i n p u t . s i z e / {input.size}/input.size/{hive.exec.reducers.bytes.per.reducer})]
hive.exec.reducers.max :此参数从Hive 0.2.0开始引入。在Hive 0.14.0版本之前默认值是999;而从Hive 0.14.0开始,默认值变成了1009,这个参数的含义是最多启动的Reduce个数
hive.exec.reducers.bytes.per.reducer :此参数从Hive 0.2.0开始引入。在Hive 0.14.0版本之前默认值是1G(1,000,000,000);而从Hive 0.14.0开始,默认值变成了256M(256,000,000),可以参见HIVE-7158和HIVE-7917。这个参数的含义是每个Reduce处理的字节数。比如输入文件的大小是1GB,那么会启动4个Reduce来处理数据。
也就是说,根据输入的数据量大小来决定Reduce的个数,默认Hive.exec.Reducers.bytes.per.Reducer为1G,而且Reduce个数不能超过一个上限参数值,这个参数的默认取值为999。所以我们可以调整Hive.exec.Reducers.bytes.per.Reducer来设置Reduce个数。
注意:
Reduce的个数对整个作业的运行性能有很大影响。如果Reduce设置的过大,那么将会产生很多小 文件,对NameNode会产生一定的影响,而且整个作业的运行时间未必会减少;如果Reduce设置的 过小,那么单个Reduce处理的数据将会加大,很可能会引起OOM异常。
如果设置了 mapred.reduce.tasks/mapreduce.job.reduces 参数,那么Hive会直接使用它的值作为Reduce的个数;
如果mapred.reduce.tasks/mapreduce.job.reduces的值没有设置(也就是-1),那么Hive会根据输入 文件的大小估算出Reduce的个数。根据输入文件估算Reduce的个数可能未必很准确,因为Reduce 的输入是Map的输出,而Map的输出可能会比输入要小,所以最准确的数根据Map的输出估算Reduce的个数。
Hive的用户自定义函数实现步骤与流程
问过的一些公司:阿里,恒生(2021.09) 参考答案:
1、如何构建UDF?
用户创建的UDF使用过程如下:
第一步:继承UDF或者UDAF或者UDTF,实现特定的方法; 第二步:将写好的类打包为jar,如hivefirst.jar;
第三步:进入到Hive外壳环境中,利用add jar /home/hadoop/hivefirst.jar注册该jar文件;
第四步:为该类起一个别名,create temporary function mylength as ‘com.whut.StringLength’,这里注意UDF只是为这个Hive会话临时定义的;
第五步:在select中使用mylength()。
2、函数自定义实现步骤
- 继承Hive提供的类
- org.apache.hadoop.hive.ql.udf.generic.GenericUDF
- org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
- 实现类中的抽象方法
- 在 hive 的命令行窗口创建函数添加 jar
- add jar linux_jar_path
创建 function
- create [temporary] function [dbname.]function_name AS class_name;
- 在 hive 的命令行窗口删除函数
1 drop [temporary] function [if exists] [dbname.]function_name; 2
3、自定义UDF案例 - 需求
自定义一个UDF实现计算给定字符串的长度,例如:
1 hive(default)> select my_len(“abcd”); 2 4
3
- 导入依赖
- org.apache.hive
- hive-exec
- 3.1.2
- 8
- 创建一个类,继承于Hive自带的UDF
1 /**
- 自定义 UDF 函数,需要继承 GenericUDF 类
- 需求: 计算指定字符串的长度
4 /
5 public class MyStringLength extends GenericUDF { 6 /*
7 *
- 需求: 计算指定字符串的长度
- *@param arguments 输入参数类型的鉴别器对象
- @return 返回值类型的鉴别器对象
- *@throws UDFArgumentException 11 */
12 @Override - public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
- // 判断输入参数的个数
- if(arguments.length !=1) {
- throw new UDFArgumentLengthException(“Input Args Length Error!!!”); 17 }
18 // 判断输入参数的类型
if(!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)
) {
throw new UDFArgumentTypeException(0,“Input Args Type Error!!!”);
}
//函数本身返回值为 int,需要返回 int 类型的鉴别器对象
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
- 函数的逻辑处理
*@param arguments 输入的参数
*@return 返回值
*@throws HiveException
*/ @Override
public Object evaluate(DeferredObject[] arguments) throws HiveException { if(arguments[0].get() == null) {
return 0;
}
return arguments[0].get().toString().length();
}
@Override
public String getDisplayString(String[] children) { return “”;
}
}
- 打成jar包上传到服务器/opt/module/data/myudf.jar 5)将jar包添加到hive的classpath
1 hive (default)> add jar /opt/module/data/myudf.jar; 2
6)创建临时函数与开发好的java class关联7)即可在hql中使用自定义的函数
1 hive (default)> select ename,my_len(ename) ename_len from emp; 2
Hive的三种自定义函数是什么?实现步骤与流程?它们之间的区别?作用是什么?
可回答:1)怎么实现Hive的UDF(UDF函数的开发流程);2)Hive中有哪些UDF
问过的一些公司:阿里云x3,快手x3,祖龙娱乐,知乎,大华,跟谁学,滴滴,途牛,网易,富途,搜 狐
参考答案:
Hive自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来 方便的扩展。
当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:
user-defined function)。
根据用户自定义函数类别分为以下三种:
UDF(User-Defined-Function):一进一出
UDAF(User-Defined Aggregation Function):聚集函数,多进一出
类似于:count/max/min
UDTF(User-Defined Table-Generating Functions):一进多出
如lateral view explode()
实现步骤和流程参考上一题
Hive的cluster by 、sort by、distribute by 、order by 区别?
可回答:Hive的排序函数
问过的一些公司:字节x3,百度社招,美团x3,头条,FreeWheel,蘑菇街,快手,百度校招,端点数据
(2021.07),大华(2021.07),兴业数金(2021.09),唯品会(2021.10),好未来(2021.08)
参考答案:
共有四种排序:Order By,Sort By,Distribute By,Cluster By
1、Order By:全局排序
对输入的数据做排序,故此只有一个reducer(多个reducer无法保证全局有序); 只有一个reducer,会导致当输入规模较大时,需要较长的计算时间;
- 使用 ORDER BY 子句排序ASC(ascend): 升序(默认) DESC(descend): 降序
- ORDER BY 子句在SELECT语句的结尾
- 案例
查询员工信息按工资升序排列
1 select * from emp order by sal; 2
2、Sort By:非全局排序
在数据进入reducer前完成排序;
当mapred.reduce.tasks > 1时,只能保证每个reducer的输出有序,不保证全局有序;
3、Distribute By:分区排序
按照指定的字段对数据进行划分输出到不同的reduce中,通常是为了进行后续的聚集操作; 常和sort by一起使用,并且distribute by必须在sort by前面;
4、Cluster By
相当于distribute by+sort by,只能默认升序,不能使用倒序。
Hive分区和分桶的区别
可回答:Hive分区和分桶的逻辑
问过的一些公司:字节,小米,阿里云社招,京东x2,猿辅导,竞技世界,美团,抖音 参考答案:
1、定义上分区
Hive的分区使用HDFS的子目录功能实现。每一个子目录包含了分区对应的列名和每一列的值。Hive的分区方式:由于Hive实际是存储在HDFS上的抽象,Hive的一个分区名对应一个目录名,子分 区名就是子目录名,并不是一个实际字段。
所以可以这样理解,当我们在插入数据的时候指定分区,其实就是新建一个目录或者子目录,或者 在原有的目录上添加数据文件。
注意:partitned by子句中定义的列是表中正式的列(分区列),但是数据文件内并不包含这些列。
创建分区表
create table student( id int,
name string, age int, address string
)
partitioned by (dt string,type string)
row format delimited fields terminated by ‘\t’ collection items terminated by ‘,’
map keys terminated by ‘:’ lines terminated by ‘\n’ stored as textfile
;
制定分区
指定字段分隔符为tab
指定数组中字段分隔符为逗号# 指定字典中KV分隔符为冒号# 指定行分隔符为回车换行
指定存储类型为文件
将数据加载到表中(此时时静态分区)
load data local inpath ‘/root/student.txt’ into
班’);
test.student partition(class='一
18
分桶:
分桶表是在表或者分区表的基础上,进一步对表进行组织,Hive使用对分桶所用的值;
进行hash,并用hash结果除以桶的个数做取余运算的方式来分桶,保证了每个桶中都有数据,但 每个桶中的数据条数不一定相等。
注意:
创建分区表时:
可以使用distribute by(sno) sort by(sno asc) 或是使用clustered by(字段)
当排序和分桶的字段相同的时候使用cluster by, 就等同于分桶+排序(sort)
1
2
创建分桶表
create table student(
id int,
name string, age int, address string
)
clustered by(id) sorted by(age) into 4 buckets row format delimited fields terminated by ‘\t’ stored as textfile;
开启分桶
set hive.enforce.bucketing = true; # 插入数据
insert overwrite table studentselect id ,name ,age ,address from employees; # 也可以用另一种插入方式
load data local inpath ‘/root/student.txt’ into test.student;
2、数据类型上
分桶随机分割数据库,分区是非随机分割数据库。因为分桶是按照列的哈希函数进行分割的,相对比较 平均;而分区是按照列的值来进行分割的,容易造成数据倾斜。
分桶是对应不同的文件(细粒度),分区是对应不同的文件夹(粗粒度)。桶是更为细粒度的数据范围 划分,分桶的比分区获得更高的查询处理效率,使取样更高效。
注意:普通表(外部表、内部表)、分区表这三个都是对应HDFS上的目录,桶表对应是目录里的文件。
Hive的执行流程
可回答:Hive是怎么执行的问过的一些公司:美团,多益参考答案:
1、执行流程概述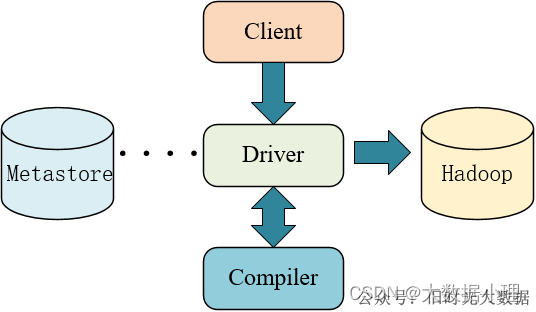
查看hive语句的执行流程:explain select ….from t_table …;
查看hive语句的执行流程:explain select ….from t_table …;
操作符是hive的最小执行单元
Hive通过execmapper和execreducer执行MapReduce程序,执行模式有本地模式和分布式模式 每个操作符代表一个HDFS 操作或者MapReduce 作业
hive操作符: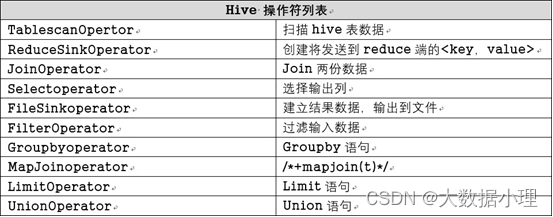
Hive编译器的工作职责:
Parser:将Hql语句转换成抽像的语法书(Abstract Syntax Tree) Semantic Analyzer:将抽象语法树转换成查询块
Logic Plan Generator:将查询树,转换成逻辑查询计划Logic Optimizer:重写逻辑查询计划,优化逻辑执行计划Physical Plan Gernerator:将逻辑执行计划转化为物理计划
Physical Optimizer:选择最佳的join策略,优化物理执行计划
2、Hive工作原理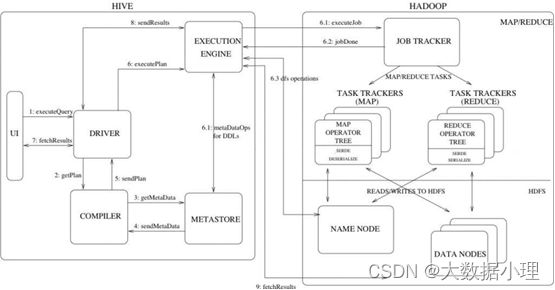
流程步骤:
- 用户提交查询等任务给Driver。
- 编译器获得该用户的任务Plan。
- 编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
- 编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语 法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计 划(MapReduce), 最后选择最佳的策略。
- 将最终的计划提交给Driver。
- Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作。
- 获取执行的结果。
- 取得并返回执行结果。
3、hive的具体执行过程分析1)Join(reduce join)
例 :SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON pv.userid = u.userid;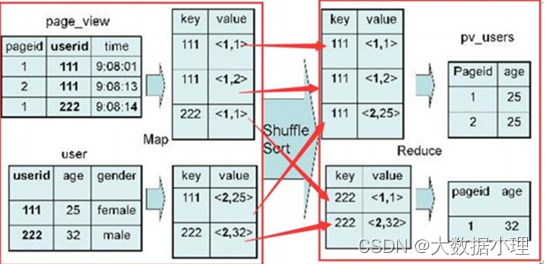
map 端:以 JOIN ON 条件中的列作为 Key,以page_view表中的需要字段,表标识作为value,最终通过key进行排序,也就是join字段进行排序。
shuGle端:根据 Key 的值进行 Hash,并将 Key/Value 对按照 Hash 值推 至不同对 Reduce 中reduce 端:根据key进行分组,根据不同的表的标识,拿出不同的数据,进行拼接。2)group by
例:SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age;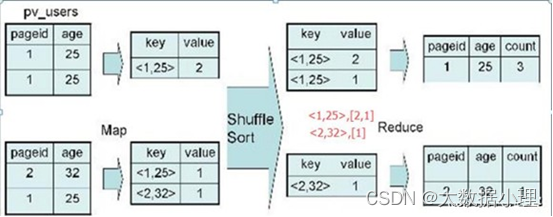
map 端:
key:以pageid, age作为key,并且在map输出端有combiner。value :1次
reduce 端:对value进行求和
58 distinct
例:select distinct age from log;
map 端 : key:age value:null reduce端:
一组只要一个输出context.write(key,null)。
59 distinct+count
例:select count(distinct userid) from weibo_temp;
即使设置了reduce个数为3个,最终也只会执行一个,因为,count()是全局,只能开启一个reducetask。
map 端 : key:userid value: null reduce端:
一组只要一个,定义一个全局变量用于计数,在cleanup(Context context)中输出context.write(key,count),当然distinct+count是一个容易产生数据倾斜的做法,应该尽量避免,如果无法 避免,那么就使用这种方法:select count(1) from (select distinct userid from weibo_temp); 这样可以并行多个reduce task任务,从而解决单节点的压力过大。