K-Means导图整理: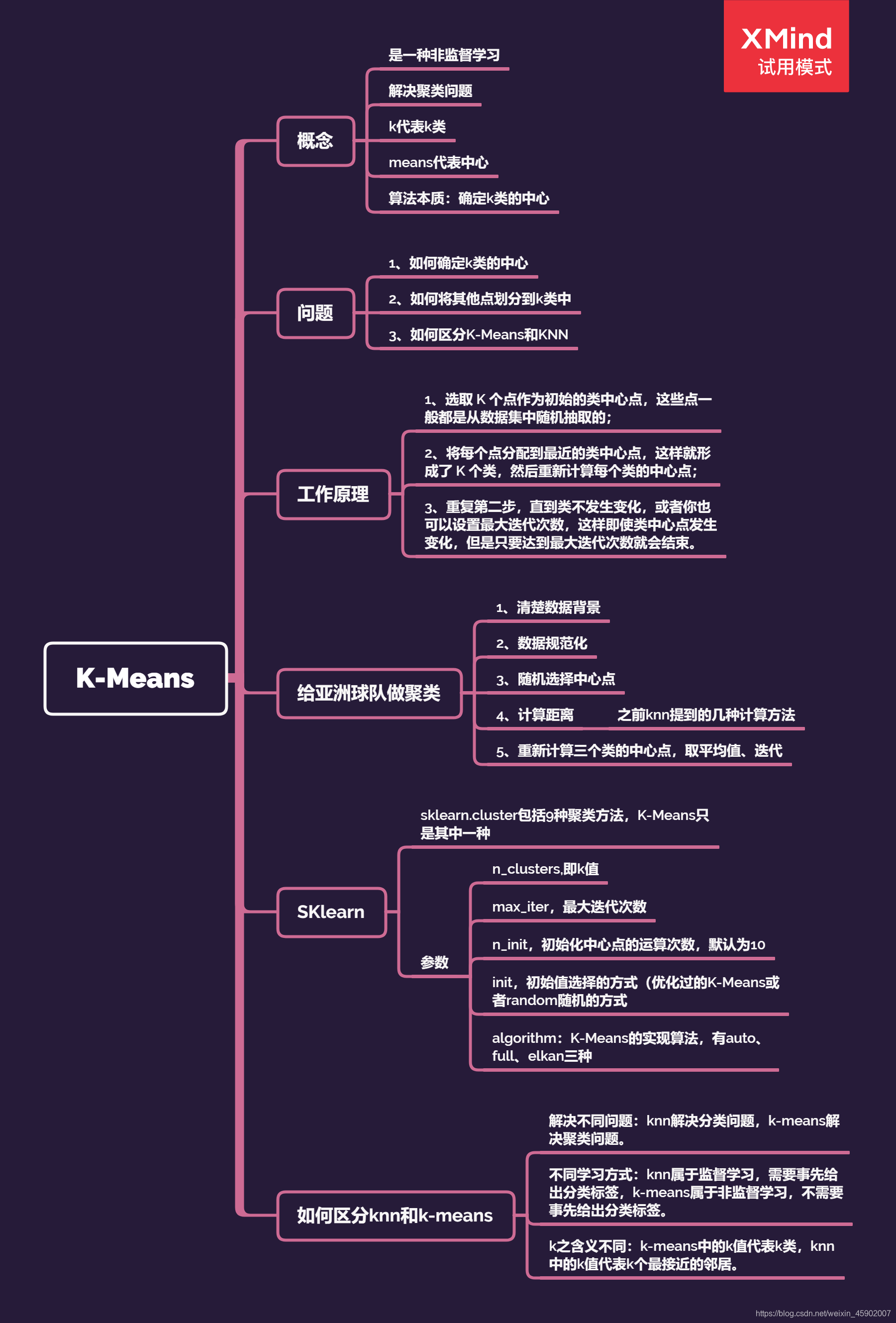
实战1:
#导入需要的包和工具
from sklearn.cluster import KMeans
from sklearn import preprocessing
import pandas as pd
import numpy as np
#加载数据
data=pd.read_csv("data.csv",encoding="gbk")
train_x=data[["2019年国际排名","2018世界杯","2015亚洲杯"]]
df=pd.DataFrame(train_x)
kmeans=KMeans(n_clusters=3)
#将数据规范化到[0,1]空间
min_max_scaler=preprocessing.MinMaxScaler()
train_x=min_max_scaler.fit_transform(train_x)
#kmeans算法:
kmeans.fit(train_x)
predict_y=kmeans.predict(train_x)
#合并聚类结果,插入到原数据中:
result=pd.concat((data,pd.DataFrame(predict_y)),axis=1)
result.rename({0:u"聚类"},axis=1,inplace=True)
print(result)
输出:
国家 2019年国际排名 2018世界杯 2015亚洲杯 聚类
0 中国 73 40 7 2
1 日本 60 15 5 1
2 韩国 61 19 2 1
3 伊朗 34 18 6 1
4 沙特 67 26 10 1
5 伊拉克 91 40 4 2
6 卡塔尔 101 40 13 0
7 阿联酋 81 40 6 2
8 乌兹别克斯坦 88 40 8 2
9 泰国 122 40 17 0
10 越南 102 50 17 0
11 阿曼 87 50 12 0
12 巴林 116 50 11 0
13 朝鲜 110 50 14 0
14 印尼 164 50 17 0
15 澳洲 40 30 1 1
16 叙利亚 76 40 17 0
17 约旦 118 50 9 0
18 科威特 160 50 15 0
19 巴勒斯坦 96 50 16 0
实战2:
图像分割就是利用图像自身的信息,比如颜色、纹理、形状等特征进行划分,将图像分割成不同的区域,划分出来的每个区域就相当于是对图像中的像素进行了聚类。单个区域内的像素之间的相似度大,不同区域间的像素差异性大。这个特性正好符合聚类的特性,所以你可以把图像分割看成是将图像中的信息进行聚类。
聚类流程和分类差不多 :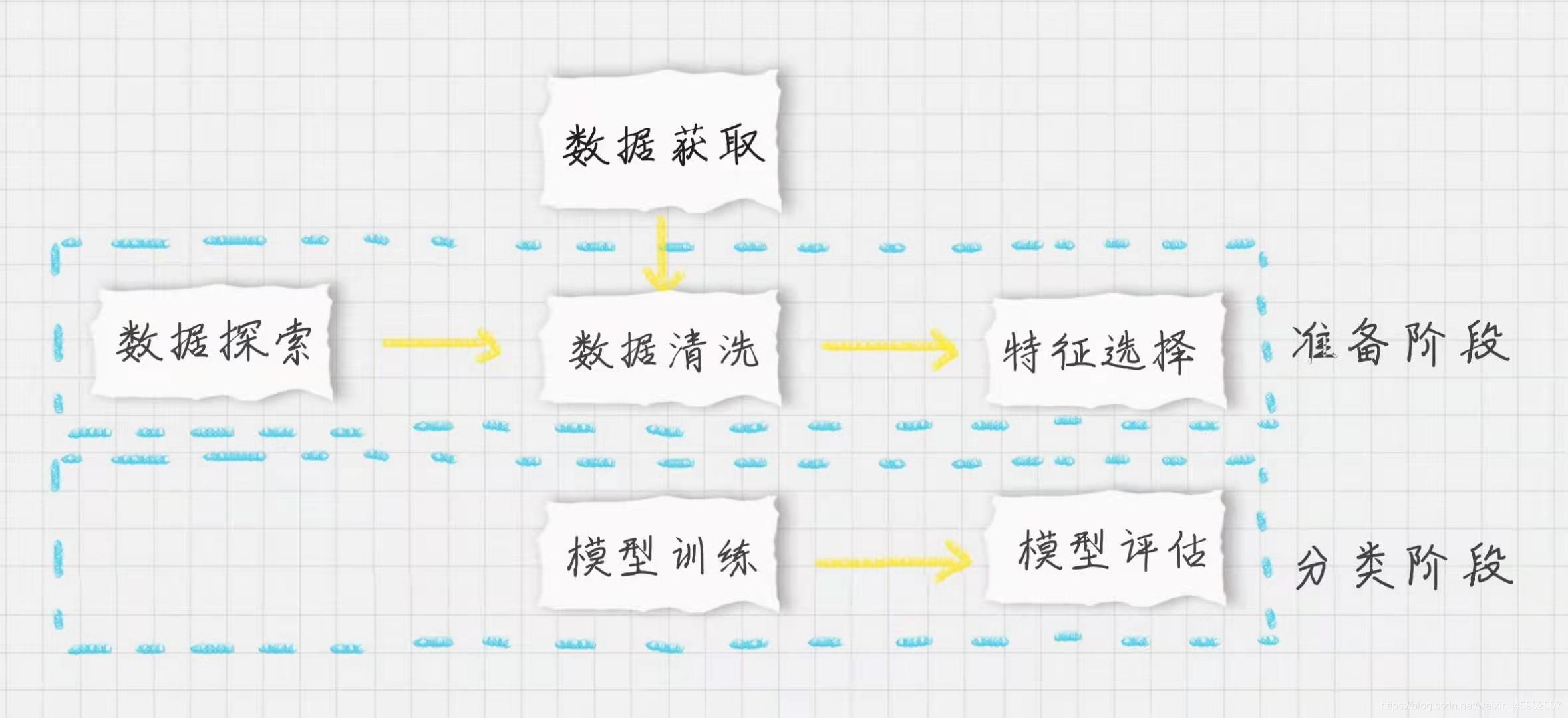
#使用聚类对微信开屏图像进行分割:
2聚类:
import numpy as np
import PIL.Image as image
from sklearn.cluster import KMeans
from sklearn import preprocessing
#加载图像,并对数据进行规范化;
def load_data(filepath):
#读文件
f=open(filepath,"rb")
data=[]
#得到图像的像素值:
img=image.open(f)
#得到图像尺寸;
width,height=img.size
for x in range(width):
for y in range(height):
#得到(x,y)点的三个通道值:
c1,c2,c3=img.getpixel((x,y))
data.append([c1,c2,c3])
f.close()
#采用min-max规范化:
mm=preprocessing.MinMaxScaler()
data=mm.fit_transform(data)
return np.mat(data),width,height
#加载图像 ,得到规范化的结果img,以及图像尺寸:
img,width,height=load_data("./weixin.jpg")
# 用K-Means对图像进行2聚类
kmeans =KMeans(n_clusters=2)
kmeans.fit(img)
label = kmeans.predict(img)
# 将图像聚类结果,转化成图像尺寸的矩阵
label = label.reshape([width, height])
# 创建个新图像pic_mark,用来保存图像聚类的结果,并设置不同的灰度值
pic_mark = image.new("L", (width, height))
for x in range(width):
for y in range(height):
# 根据类别设置图像灰度, 类别0 灰度值为255, 类别1 灰度值为127
pic_mark.putpixel((x, y), int(256/(label[x][y]+1))-1)
pic_mark.save("weixin_mark.jpg", "JPEG")
16聚类:
#用K-Means对图像进行聚类:
kmeans=KMeans(n_clusters=16)
kmeans.fit(img)
label=kmeans.predict(img)
#将图像聚类结果,转换成图像尺寸的矩阵:
label=label.reshape([width,height])
#将聚类标识矩阵转化为不同颜色的矩阵:
label_color=(color.label2rgb(label)*255).astype(np.uint8)
#设置三维矩阵的转换:将原来的(0,1,2)转换为(1,0,2)
label_color=label_color.transpose(1,0,2)
#通过矩阵来生成图片,并save保存;
images=image.fromarray(label_color)
images.save("weixin_mark_color.jpg")
输出:
2聚类:
16聚类:
版权声明:本文为weixin_45902007原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。