16 | 揭开神秘的“位移主题”面纱
Kafka 中神秘的内部主题(Internal Topic)__consumer_offsets。
但是,ZooKeeper 其实并不适用于这种高频的写操作,因此,Kafka 社区自 0.8.2.x 版本开始,就在酝酿修改这种设计,并最终在新版本 Consumer 中正式推出了全新的位移管理机制,自然也包括这个新的位移主题

我们现在知道 Key 中保存了 Group ID,但是只保存 Group ID 就可以了吗?别忘了,Consumer 提交位移是在分区层面上进行的,即它提交的是某个或某些分区的位移,那么很显然,Key 中还应该保存 Consumer 要提交位移的分区
位移主题的 Key 中应该保存 3 部分内容:<Group ID,主题名,分区号 >



17 | 消费者组重平衡能避免吗?
Rebalance 就是让一个 Consumer Group 下所有的 Consumer 实例就如何消费订阅主题的所有分区达成共识的过程。在 Rebalance 过程中,所有 Consumer 实例共同参与,在协调者组件的帮助下,完成订阅主题分区的分配。但是,在整个过程中,所有实例都不能消费任何消息,因此它对 Consumer 的 TPS 影响很大
所有 Broker 在启动时,都会创建和开启相应的 Coordinator 组件。也就是说,所有 Broker 都有各自的 Coordinator 组件。那么,Consumer Group 如何确定为它服务的 Coordinator 在哪台 Broker 上呢?答案就在我们之前说过的 Kafka 内部位移主题 __consumer_offsets 身上。
第 1 步:确定由位移主题的哪个分区来保存该 Group 数据:partitionId=Math.abs(groupId.hashCode() % offsetsTopicPartitionCount)。
第 2 步:找出该分区 Leader 副本所在的 Broker,该 Broker 即为对应的 Coordinator。
简单解释一下上面的算法。首先,Kafka 会计算该 Group 的 group.id 参数的哈希值。比如你有个 Group 的 group.id 设置成了“test-group”,那么它的 hashCode 值就应该是 627841412。其次,Kafka 会计算 __consumer_offsets 的分区数,通常是 50 个分区,之后将刚才那个哈希值对分区数进行取模加求绝对值计算,即 abs(627841412 % 50) = 12。此时,我们就知道了位移主题的分区 12 负责保存这个 Group 的数据。有了分区号,算法的第 2 步就变得很简单了,我们只需要找出位移主题分区 12 的 Leader 副本在哪个 Broker 上就可以了。这个 Broker,就是我们要找的 Coordinator。

就我个人经验而言,在真实的业务场景中,很多 Rebalance 都是计划外的或者说是不必要的。我们应用的 TPS 大多是被这类 Rebalance 拖慢的,因此避免这类 Rebalance 就显得很有必要了。下面我们就来说说如何避免 Rebalance



+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
18 | Kafka中位移提交那些事儿
Consumer 需要向 Kafka 汇报自己的位移数据,这个汇报过程被称为提交位移(Committing Offsets)。因为 Consumer 能够同时消费多个分区的数据,所以位移的提交实际上是在分区粒度上进行的,即 Consumer 需要为分配给它的每个分区提交各自的位移数据。

提交位移主要是为了表征 Consumer 的消费进度,这样当 Consumer 发生故障重启之后,就能够从 Kafka 中读取之前提交的位移值,然后从相应的位移处继续消费,从而避免整个消费过程重来一遍。换句话说,位移提交是 Kafka 提供给你的一个工具或语义保障,你负责维持这个语义保障,即如果你提交了位移 X,那么 Kafka 会认为所有位移值小于 X 的消息你都已经成功消费了


kafka还提供了异步提交位移的方法commitAsync
调用 commitAsync() 之后,它会立即返回,不会阻塞,因此不会影响 Consumer 应用的 TPS。由于它是异步的,Kafka 提供了回调函数(callback),供你实现提交之后的逻辑,比如记录日志或处理异常等;

手动提交位移consume_offset更加灵活
19 | CommitFailedException异常怎么处理?

20 | 多线程开发消费者实例
从 Kafka 0.10.1.0 版本开始,KafkaConsumer 就变为了双线程的设计,即用户主线程和心跳线程
所谓用户主线程,就是你启动 Consumer 应用程序 main 方法的那个线程,而新引入的心跳线程(Heartbeat Thread)只负责定期给对应的 Broker 机器发送心跳请求,以标识消费者应用的存活性(liveness)。引入这个心跳线程还有一个目的,那就是期望它能将心跳频率与主线程调用 KafkaConsumer.poll 方法的频率分开,从而解耦真实的消息处理逻辑与消费者组成员存活性管理
不过,虽然有心跳线程,但实际的消息获取逻辑依然是在用户主线程中完成的。因此,在消费消息的这个层面上,我们依然可以安全地认为 KafkaConsumer 是单线程的设计。
首先,我们要明确的是,KafkaConsumer 类不是线程安全的(thread-safe)。所有的网络 I/O 处理都是发生在用户主线程中,因此,你在使用过程中必须要确保线程安全。简单来说,就是你不能在多个线程中共享同一个 KafkaConsumer 实例,否则程序会抛出 ConcurrentModificationException 异常。
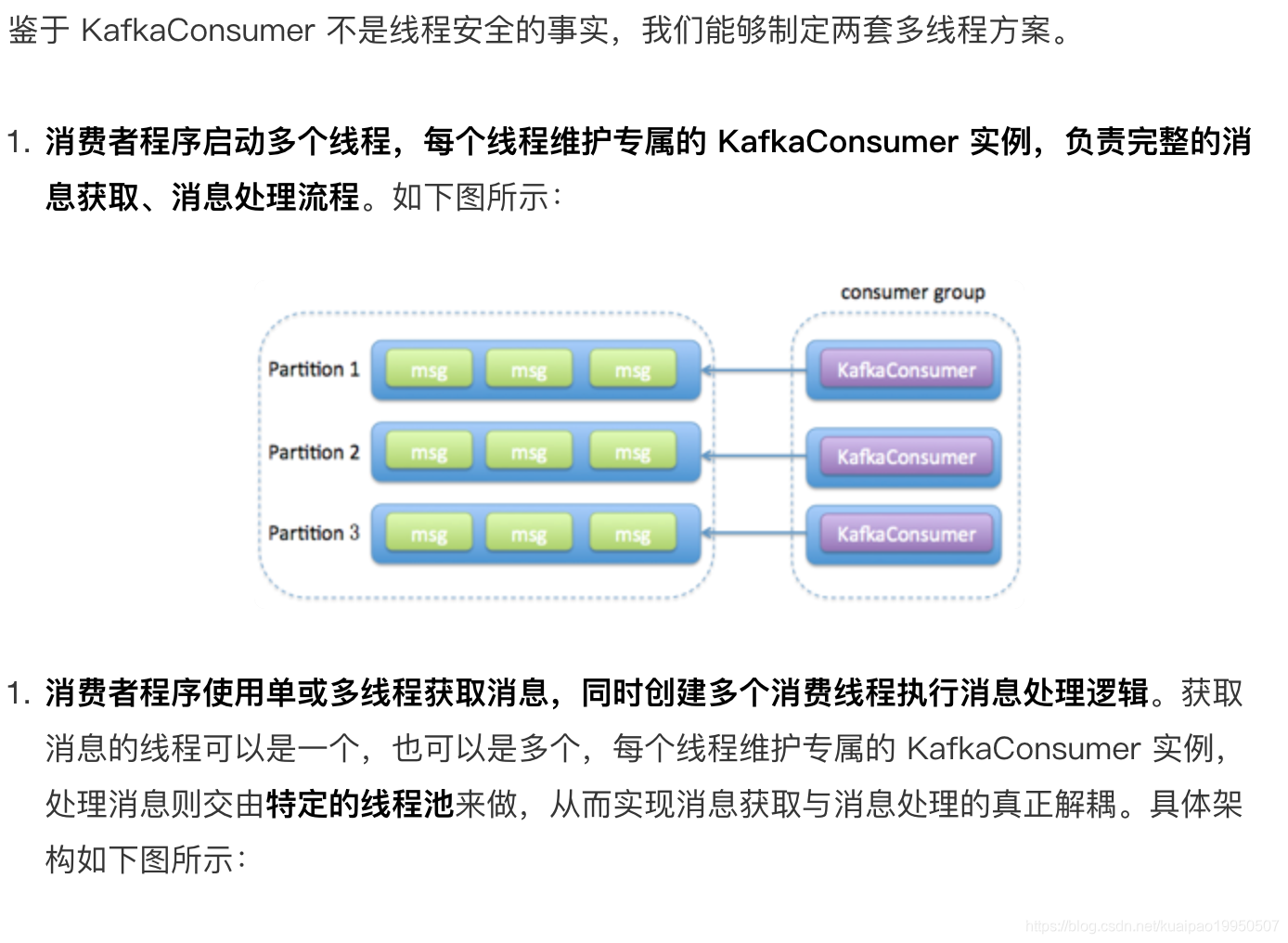
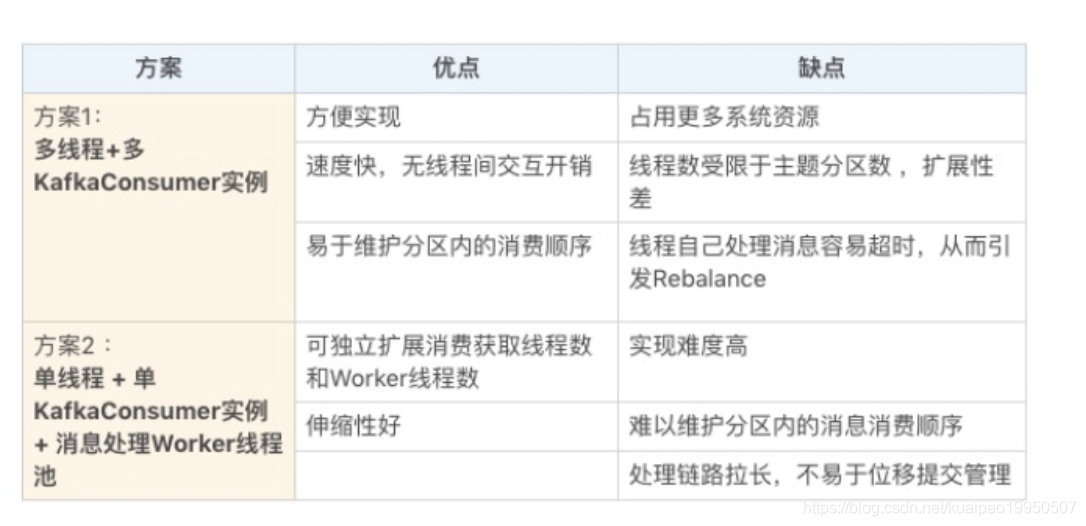
我们来打个比方。比如一个完整的消费者应用程序要做的事情是 1、2、3、4、5,那么方案 1 的思路是粗粒度化的工作划分,也就是说方案 1 会创建多个线程,每个线程完整地执行 1、2、3、4、5,以实现并行处理的目标,它不会进一步分割具体的子任务;而方案 2 则更细粒度化,它会将 1、2 分割出来,用单线程(也可以是多线程)来做,对于 3、4、5,则用另外的多个线程来做。


21 | Java 消费者是如何管理TCP连接的?
TCP 连接是在调用 KafkaConsumer.poll 方法时被创建的。
再细粒度地说,在 poll 方法内部有 3 个时机可以创建 TCP 连接。



22 | 消费者组消费进度监控都怎么实现?
