首先肯定要有一个账号嘛
超级鹰验证码识别-专业的验证码云端识别服务,让验证码识别更快速、更准确、更强大 (chaojiying.com)
注册我觉得没啥好说的小伙伴门自己来哈,注册好账号之后我们点击开发文档,选择自己的语言我这里选择的是python

点击下载之后得到的是一个压缩文件需要解压
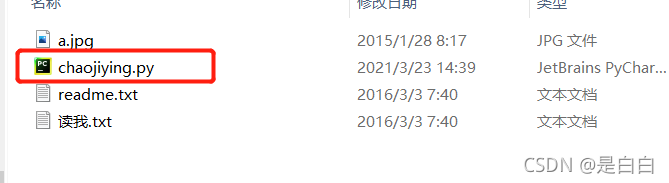
我们点击这个文件即可其它不用管
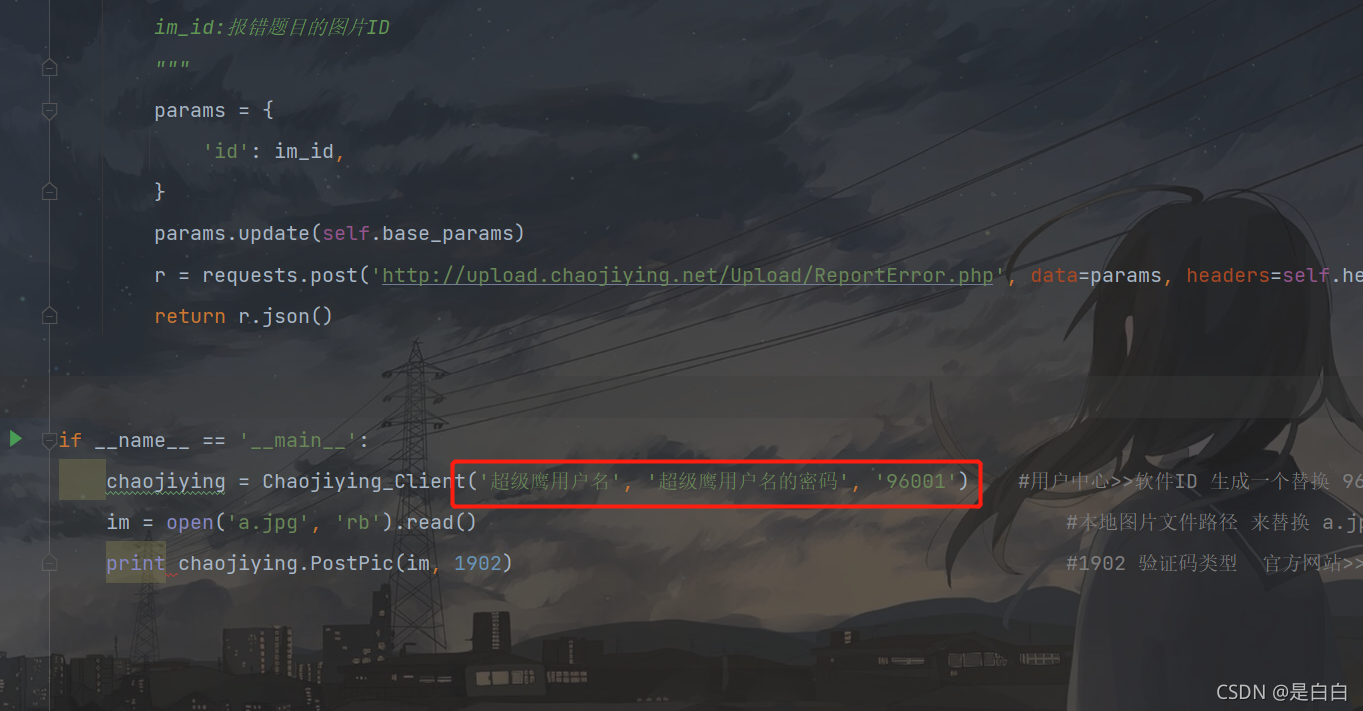
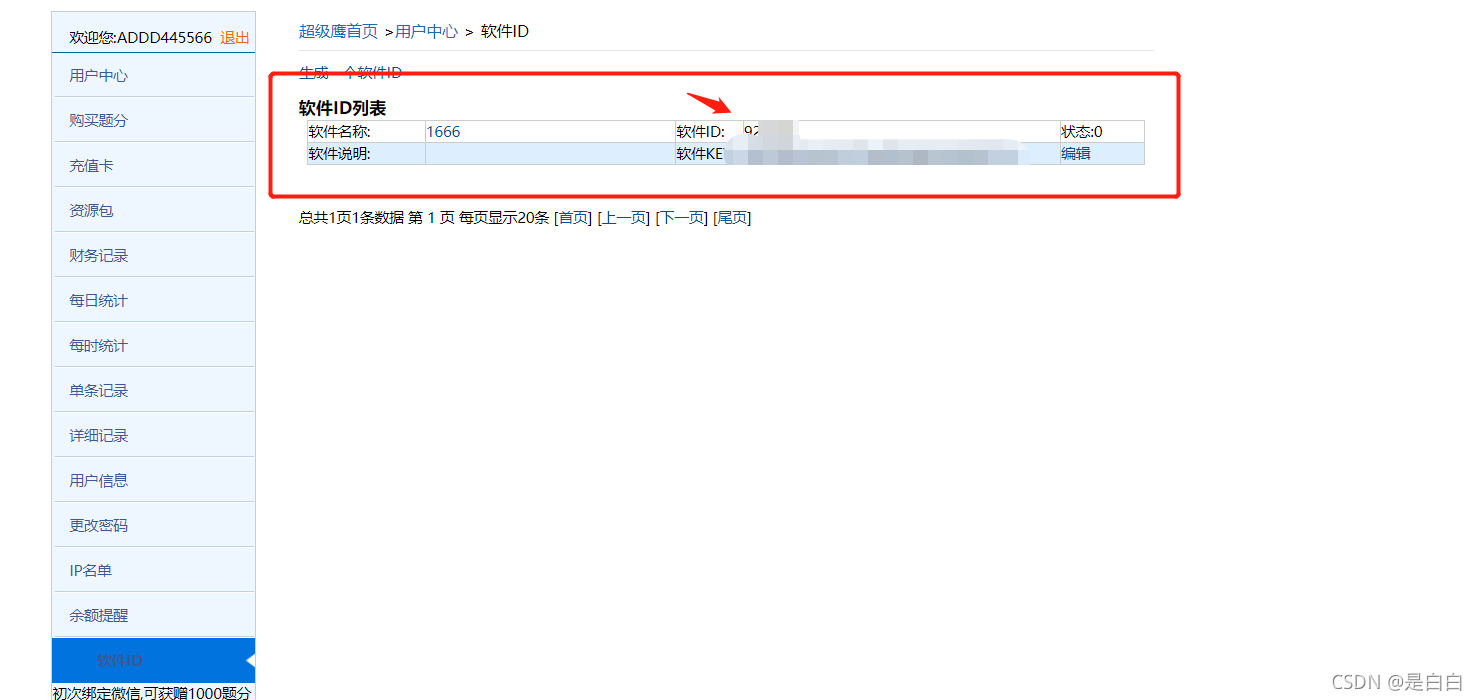
这里更换为自己的账号密码,最后的软件ID 如下图获取
这里需要注意的是由于是python3的版本我们还需要在print后面加上()

到这里就差不多了,接下来我们来实践用超级鹰去干超级鹰
创建一个新的py文件之后记得把刚刚chaojiying的文件放在同一个目录下面方便导入
from selenium import webdriver
from lxml import etree
from selenium.webdriver import ChromeOptions #这个包用来规避被检测的风险
import time
from chaojiying import Chaojiying_Client
option = webdriver.ChromeOptions()
option.add_experimental_option('useAutomationExtension', False)
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver_path = r'驱动的路径' # 定义好路径
driver = webdriver.Chrome(executable_path=driver_path,options=option) # 初始化路径+规避检测
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
chaojiying = Chaojiying_Client('输入超级鹰账号','输入超级鹰密码', '软件ID')
driver.get('https://www.chaojiying.com/user/login/')到这里程序启动之后我们需要获取验证码的位置并且截图,我是直接右键复制的XPATH路径,如果有时候直接复制的路径,程序运行之后报错就自己写一下,原因可能是网站代码写的并不规范,但是浏览器有很强的纠错能力,比如原本是没有body标签,但是浏览器自动补全了这样导致复制下来的路径里面带有一个body标签但实际上是没有的,就会出现报错说找不到这个标签
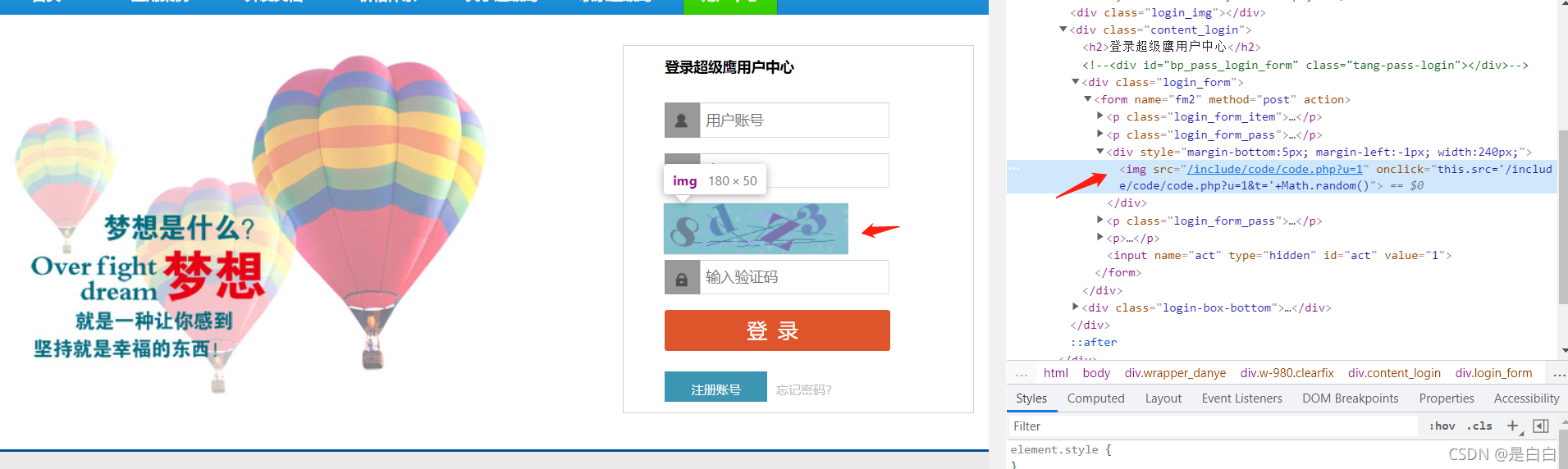
img=driver.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/div/img').screenshot_as_png #截图(这里补充说明一点哈,为什么不直接去获取img的链接直接请求呢,是因为有些网站你直接请求的话它请求到的图片是另外一张,就表明上你看上图是8dz3,但实际上可能已经变成了别的图片)
这个时候已经获取到验证码的图片,接下来只需要传递给超级鹰识别即可
dic=chaojiying.PostPic(img,1902)
print(dic)
可以看到已经返回了正确的结果在pic_str这个里面,诶那接下来不就明了了嘛

verification_code=dic['pic_str']
user_name=driver.find_element_by_xpath('//input[@name="user"]').send_keys('******') #输入账号1
time.sleep(1)
pass_word=driver.find_element_by_xpath('//input[@type="password"]').send_keys('*******') #输入密码
time.sleep(1)
auth_code=driver.find_element_by_xpath('//input[@name="imgtxt"]').send_keys(verification_code) #输入验证码
time.sleep(1)
log_in=driver.find_element_by_xpath('//input[@type="submit"]').click() #点击登录按钮就可以了亲测可用
全部源代码如下
from selenium import webdriver
from lxml import etree
from selenium.webdriver import ChromeOptions #这个包用来规避被检测的风险
import time
from chaojiying import Chaojiying_Client
option = webdriver.ChromeOptions()
option.add_experimental_option('useAutomationExtension', False)
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver_path = r'驱动的路径' # 定义好路径
driver = webdriver.Chrome(executable_path=driver_path,options=option) # 初始化路径+规避检测
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
chaojiying = Chaojiying_Client('超级鹰账号','超级鹰密码', 'ID') #超级鹰账号
driver.get('https://www.chaojiying.com/user/login/')
img=driver.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/div/img').screenshot_as_png #截图
dic=chaojiying.PostPic(img,1902)
print(dic)
verification_code=dic['pic_str']
user_name=driver.find_element_by_xpath('//input[@name="user"]').send_keys('********') #输入账号1
time.sleep(1)
pass_word=driver.find_element_by_xpath('//input[@type="password"]').send_keys('*********') #输入密码
time.sleep(1)
auth_code=driver.find_element_by_xpath('//input[@name="imgtxt"]').send_keys(verification_code) #输入验证码
time.sleep(1)
log_in=driver.find_element_by_xpath('//input[@type="submit"]').click() #点击登录按钮看到这里动动发财的小手点个赞吧

版权声明:本文为m0_59874815原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。