要编写解决这个问题的代码,需要三个散列表。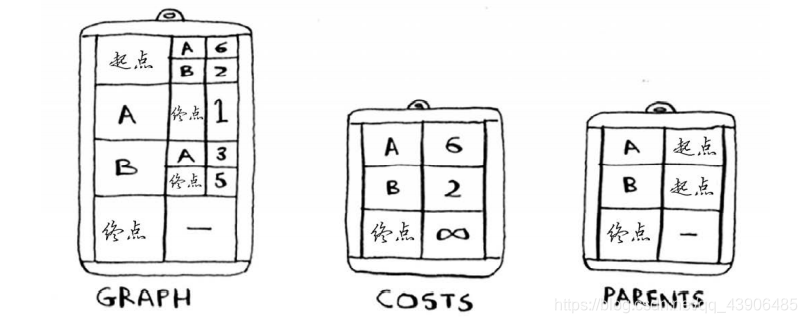
随着算法的进行,你将不断更新散列表costs和parents。首先,需要实现这个图,为此可像第6章那样使用一个散列表,样将节点的所有邻居都存储在散列表中。但这里需要同时存储邻居和前往邻居的开销。例如,起点有两个邻居——A和B。如何表示这些边的权重呢?为何不使用另一个散列表呢?因此graph[“start”]是一个散列表。有一条从起点到A的边,还有一条从起点到B的边。要获悉这些边的权重,该如何办呢?表示整个图的散列表类似于下面这样。
接下来,需要用一个散列表来存储每个节点的开销。节点的开销指的是从起点出发前往该节点需要多长时间。你知道的,从起点到节点B需要2分钟,从起点到节点A需要6分钟(但你可能会找到所需时间更短的路径)。你不知道到终点需要多长时间。对于还不知道的开销,你将其设
置为无穷大。

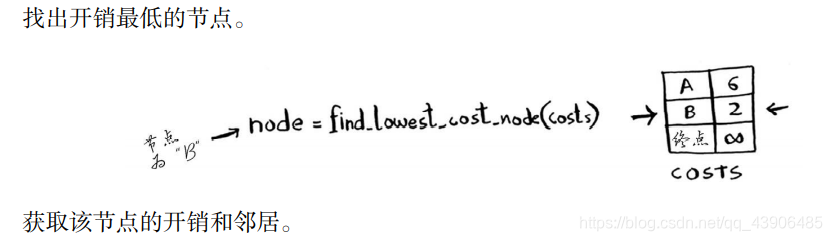





狄杰斯特拉算法实现过程如下:
def find_lowest_cost_node(costs):
lowest_cost = float('inf')
lowest_cost_node = None
for node in costs:
cost = costs[node]
if cost < lowest_cost and node not in processed:
lowest_cost = cost
lowest_cost_node = node
return lowest_cost_node
graph = {}
graph['start'] = {}
graph['start']['a'] = 6
graph['start']['b'] = 2
graph['a'] = {}
graph['a']['end'] = 1
graph['b'] = {}
graph['b']['a'] = 3
graph['b']['end'] = 5
graph['end'] = {}
print(graph)
infinity = float('inf')
costs = {}
costs['a'] = 6
costs['b'] = 2
costs['end'] = infinity
parents = {}
parents['a'] = 'start'
parents['b'] = 'start'
parents['end'] = None
processed = []
node = find_lowest_cost_node(costs) # 在未处理的节点中找到开销最小的节点。
while node is not None:
cost = costs[node]
neighbors = graph[node]
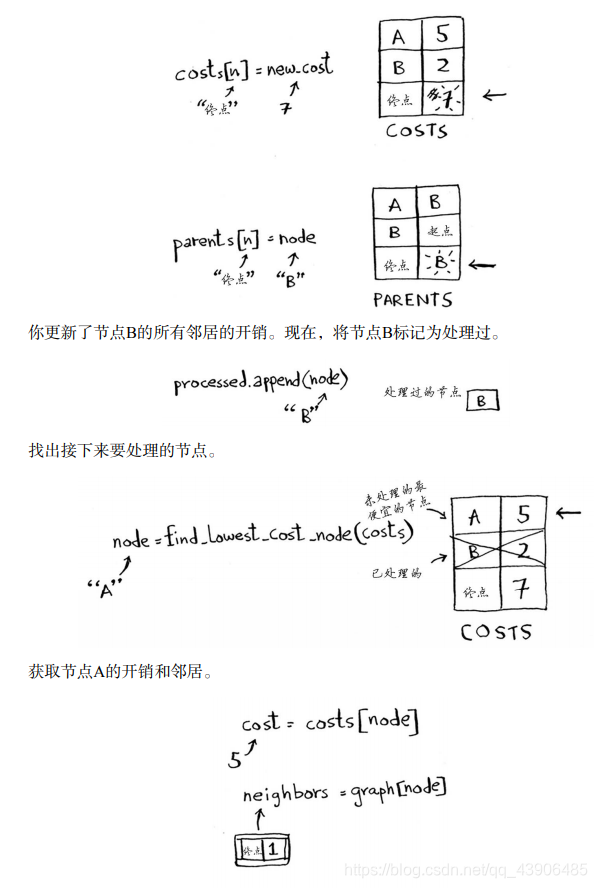
for n in neighbors.keys():
new_cost = cost + neighbors[n]
if new_cost < costs[n]:
costs[n] = new_cost
parents[n] = node
processed.append(node)
node = find_lowest_cost_node(costs)
```
版权声明:本文为qq_43906485原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。