目录
1.算法伪代码
输入:事务数据库D;最小支持度阈值。
输出:D中的频繁项集L。
方法: L1 = find_frequent_1_itemsets(D); //找出频繁1-项集的集合L1
for(k = 2; Lk-1 ≠ ∅; k++) { //产生候选,并剪枝
Ck = aproiri_gen(Lk-1,min_sup);
for each transaction t∈D{ //扫描D进行候选计数
Ct = subset(Ck,t); //得到t的子集
for each candidate c∈Ct
c.count++; //支持度计数
}
Lk={c∈Ck| c.count ≥min_sup} //返回候选项集中不小于最小支持度的项集
}
return L = ∪kLk;//所有的频繁集
第一步(连接 join)
Procedure apriori_gen(Lk-1: frequent (k-1)-itemset; min_sup: support)
1) for each itemset l1∈Lk-1
2) for each itemset l2∈Lk-1
3) if(l1[1]=l2[1])∧...∧(l1[k-2]=l2[k-2])∧(l1[k-1]<l2[k-1]) then{
4) c = l1 l2; //连接步:l1连接l2 //连接步产生候选,若K-1项集中已经存在子集c,则进行剪枝
5) if has_infrequent_subset(c,Lk-1) then
6) delete c; //剪枝步:删除非频繁候选
7) else add c to Ck;
8) }
9) return Ck;
第二步:剪枝(prune)
Procedure has_infrequent_subset(c:candidate k-itemset; Lk-1:frequent (k-1)-itemset) //使用先验定理
1) for each (k-1)-subset s of c
2) if c∉Lk-1 then
3) return TRUE;
4) return FALSE;
2.算法代码
import itertools
import time
import psutil
import os
def item(dataset): # 求第一次扫描数据库后的 候选集,(它没法加入循环)
c1 = [] # 存放候选集元素
for x in dataset: # 就是求这个数据库中出现了几个元素,然后返回
for y in x:
if [y] not in c1:
c1.append([y])
c1.sort()
# print(c1)
return c1
def get_frequent_item(dataset, c, min_support):
cut_branch = {} # 用来存放所有项集的支持度的字典
for x in c:
for y in dataset:
if set(x).issubset(set(y)): # 如果 x 不在 y中,就把对应元素后面加 1
cut_branch[tuple(x)] = cut_branch.get(tuple(x),
0) + 1 # cut_branch[y] = new_cand.get(y, 0)表示如果字典里面没有想要的关键词,就返回0
# print(cut_branch)
Fk = [] # 支持度大于最小支持度的项集, 即频繁项集
sup_dataK = {} # 用来存放所有 频繁 项集的支持度的字典
for i in cut_branch:
if cut_branch[i] >= min_support: # Apriori定律1 小于支持度,则就将它舍去,它的超集必然不是频繁项集
Fk.append(list(i))
sup_dataK[i] = cut_branch[i]
# print(Fk)
return Fk, sup_dataK
def get_candidate(Fk, K): # 求第k次候选集
ck = [] # 存放产生候选集
for i in range(len(Fk)):
for j in range(i + 1, len(Fk)):
L1 = list(Fk[i])[:K - 2]
L2 = list(Fk[j])[:K - 2]
L1.sort()
L2.sort() # 先排序,在进行组合
if L1 == L2:
if K > 2: # 第二次求候选集,不需要进行减枝,因为第一次候选集都是单元素,且已经减枝了,组合为双元素肯定不会出现不满足支持度的元素
new = list(set(Fk[i]) ^ set(Fk[j])) # 集合运算 对称差集 ^ (含义,集合的元素在t或s中,但不会同时出现在二者中)
# new表示,这两个记录中,不同的元素集合
# 为什么要用new? 比如 1,2 1,3 两个合并成 1,2,3 我们知道1,2 和 1,3 一定是频繁项集,但 2,3呢,我们要判断2,3是否为频繁项集
# Apriori定律1 如果一个集合不是频繁项集,则它的所有超集都不是频繁项集
else:
new = set()
for x in Fk:
if set(new).issubset(set(x)) and list(
set(Fk[i]) | set(Fk[j])) not in ck: # 减枝 new是 x 的子集,并且 还没有加入 ck 中
ck.append(list(set(Fk[i]) | set(Fk[j])))
# print(ck)
return ck
def Apriori(dataset, min_support=2):
c1 = item(dataset) # 返回一个二维列表,里面的每一个一维列表,都是第一次候选集的元素
f1, sup_1 = get_frequent_item(dataset, c1, min_support) # 求第一次候选集
F = [f1] # 将第一次候选集产生的频繁项集放入 F ,以后每次扫描产生的所有频繁项集都放入里面
sup_data = sup_1 # 一个字典,里面存放所有产生的候选集,及其支持度
K = 2 # 从第二个开始循环求解,先求候选集,在求频繁项集
while (len(F[K - 2]) > 1): # k-2是因为F是从0开始数的 #前一个的频繁项集个数在2个或2个以上,才继续循环,否则退出
ck = get_candidate(F[K - 2], K) # 求第k次候选集
fk, sup_k = get_frequent_item(dataset, ck, min_support) # 求第k次频繁项集
F.append(fk) # 把新产生的候选集假如F
sup_data.update(sup_k) # 字典更新,加入新得出的数据
K += 1
return F, sup_data # 返回所有频繁项集, 以及存放频繁项集支持度的字典
def generate_association_rules(patterns, confidence_threshold):
rules = []
for itemset in patterns.keys():
upper_support = patterns[itemset]
for i in range(1, len(itemset)):
for antecedent in itertools.combinations(itemset, i):
antecedent = tuple(sorted(antecedent))
consequent = tuple(sorted(set(itemset) - set(antecedent)))
if antecedent in patterns:
lower_support = patterns[antecedent]
confidence = float(upper_support) / lower_support
if confidence >= confidence_threshold:
rules.append([antecedent, consequent, confidence])
return rules
def printPatterns(patterns):
keys1 = list(patterns.keys())
values1 = list(patterns.values())
for i in range(len(keys1)):
keys1[i] = list(keys1[i])
for i in range(len(keys1)):
for j in range(len(keys1[i])):
print(keys1[i][j], end=" ")
for i2 in range(10 - 2 * len(keys1[i])):
print(" ", end="")
print(" : ", end="")
print(values1[i], end="\n")
def printRules2(rlues):
keys1 = []
values1 = []
for i in range(len(rules)):
keys1.append(list(rules[i][0]))
values1.append(list(rules[i][1]))
for i in range(len(keys1)):
for j in range(len(keys1[i])):
print(keys1[i][j], end=" ")
for i2 in range(10 - 2 * len(keys1[i])):
print(" ", end="")
print(" --> ", end="")
for i1 in range(len(values1[i])):
print(values1[i][i1], end=" ")
for i3 in range(10 - 2 * len(values1[i])):
print(" ", end="")
print(": " + str(rules[i][2]), end="\n")
if __name__ == '__main__':
begin_time = time.time()
dataset = [
['M', 'O', 'N', 'K', 'E', 'Y'],
['D', 'O', 'N', 'K', 'E', 'Y'],
['M', 'A', 'K', 'E'],
['M', 'U', 'C', 'K', 'Y'],
['C', 'O', 'O', 'K', 'I', 'E']
] # 装入数据 二维列表
F, sup_data = Apriori(dataset, min_support=3) # 最小支持度设置为3
rules = generate_association_rules(sup_data, 0.8) # 置信度(条件概率)删选
print("各频繁集及其出现次数", end="\n")
printPatterns(sup_data)
print('---------------------------------')
print("各强关联规则及其置信度", end="\n")
printRules2(rules)
end_time = time.time()
timeget = end_time - begin_time
print("程序开始时间:",begin_time)
print("程序结束时间:",end_time)
print("程序花费时间:",timeget)
print(u'当前进程的内存使用:%.4f GB' % (psutil.Process(os.getpid()).memory_info().rss / 1024 / 1024 / 1024))注:代码具体来源已找不到
3.测试数据
['M', 'O', 'N', 'K', 'E', 'Y'],
['D', 'O', 'N', 'K', 'E', 'Y'],
['M', 'A', 'K', 'E'],
['M', 'U', 'C', 'K', 'Y'],
['C', 'O', 'O', 'K', 'I', 'E']
4.结果
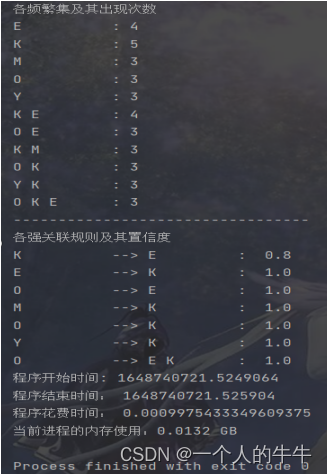
程序开始时间: 1648740721.5249064
程序结束时间: 1648740721.525904
程序花费时间: 0.0009975433349609375
当前进程的内存使用:0.0132 GB
各频繁集及其出现次数
E : 4
K : 5
M : 3
O : 3
Y : 3
K E : 4
O E : 3
K M : 3
O K : 3
Y K : 3
O K E : 3
各强关联规则及其置信度
K --> E: 0.8
E --> K: 1.0
O --> E: 1.0
M --> K: 1.0
O --> K: 1.0
Y --> K: 1.0
O--> E K: 1.0
执行Apriori算法花费的时间和占有的内存。
程序花费时间: 0.0009975433349609375
当前进程的内存使用:0.0132 GB
基础知识参考:
大白话解析Apriori算法python实现(含源代码详解)_A little storm的博客-CSDN博客_apriori算法python实现
关联规则挖掘——Apriori算法的基本原理以及改进_水澹澹兮生烟的博客-CSDN博客_apriori算法
本文仅仅是个人的学习笔记,如有错误,敬请指正!