“他山之石,可以攻玉”,站在巨人的肩膀才能看得更高,走得更远。在科研的道路上,更需借助东风才能更快前行。为此,我们特别搜集整理了一些实用的代码链接,数据集,软件,编程技巧等,开辟“他山之石”专栏,助你乘风破浪,一路奋勇向前,敬请关注。
作者:知乎—wxj630地址:https://www.zhihu.com/people/wxj630
- 知识图谱是数据科学中最迷人的概念之一
- 学习如何构建知识图谱来从维基百科页面挖掘信息
- 您将在Python中动手使用流行的spaCy库构建知识图谱
01
知识图谱1、什么是知识图谱
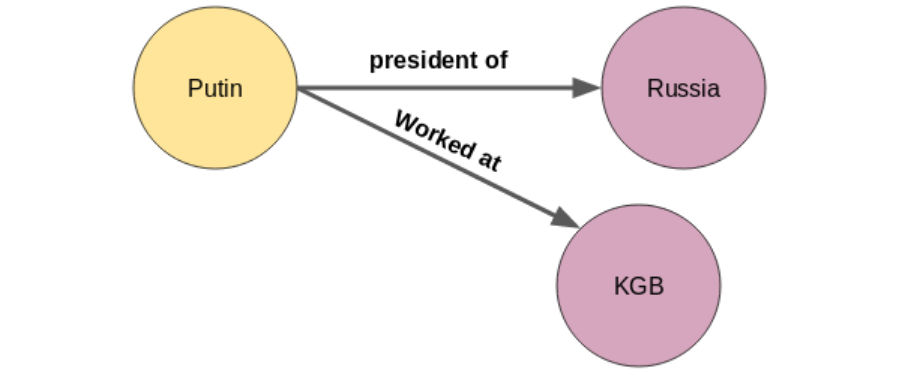
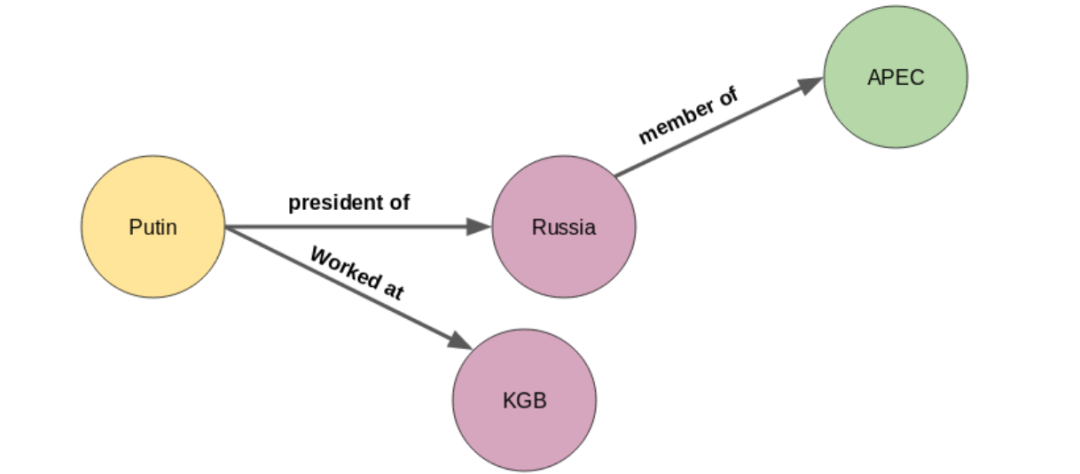
We can define a graph as a set of nodes and edges. 知识图谱就是一组节点和边构成的三元组。 这里的节点A和节点B是两个不同的实体。这些节点由代表两个节点之间关系的边连接,也被称为一个三元组。

2、句子分割Sentence Segmentation
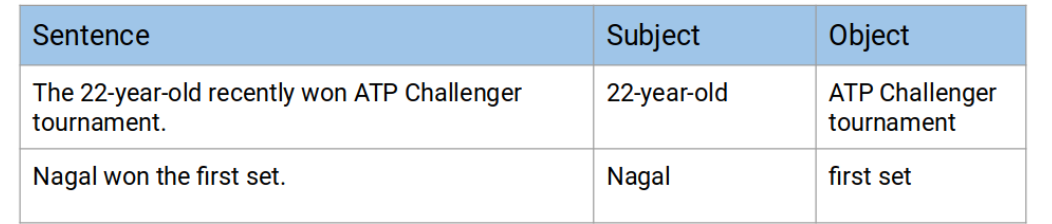
构建知识图的第一步是将文本文档或文章分解成句子。然后,我们将选出只有一个主语和一个宾语的句子。让我们看看下面的示例文本: “Indian tennis player Sumit Nagal moved up six places from 135 to a career-best 129 in the latest men’s singles ranking. The 22-year-old recently won the ATP Challenger tournament. He made his Grand Slam debut against Federer in the 2019 US Open. Nagal won the first set.”在最新的男子单打排名中,印度网球选手纳加尔(Sumit Nagal)上升了6位,从135名上升到职业生涯最好的129名。这位22岁的选手最近赢得了ATP挑战赛的冠军。在2019年的美国网球公开赛上,他迎来了自己的大满贯处子秀,对手是费德勒。纳加尔赢了第一盘。 将文本分割成句子:
- Indian tennis player Sumit Nagal moved up six places from 135 to a career-best 129 in the latest men’s singles ranking
- The 22-year-old recently won the ATP Challenger tournament
- He made his Grand Slam debut against Federer in the 2019 US Open
- Nagal won the first set
3、实体识别Entities Recognition
首先我们需要抽取实体,也就是知识图谱上的“节点”: 从一个句子中提取一个单词并不是一项艰巨的任务。借助词性标签,我们可以很容易地做到这一点。名词和专有名词就是我们的实体。但是,当一个实体跨越多个单词时,仅使用POS标记是不够的。我们需要解析句子的依赖树。在下一篇文章中,您可以阅读更多有关依赖解析dependency parsing的内容。 我们使用spaCy库来解析依赖:import spacynlp = spacy.load('en_core_web_sm')doc = nlp("The 22-year-old recently won ATP Challenger tournament.")for tok in doc: print(tok.text, "...", tok.dep_)'''输出:The … det22-year … amod– … punctold … nsubjrecently … advmodwon … ROOTATP … compoundChallenger … compoundtournament … dobj. … punct'''4、关系抽取Extract Relations
然后我们需要提取关系,也就是知识图谱上的“边”: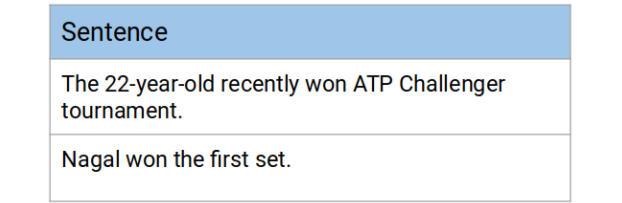
doc = nlp("Nagal won the first set.")for tok in doc: print(tok.text, "...", tok.dep_)'''输出:Nagal … nsubjwon … ROOTthe … detfirst … amodset … dobj. … punct'''
02
知识图谱python实践 我们将使用与维基百科文章相关的一组电影和电影中的文本从头开始构建一个知识图。我已经从500多篇维基百科文章中提取了大约4300个句子。每个句子都包含两个实体一个主语和一个宾语。你可以从这里下载这些句子。1、导入相关库Import Libraries
import reimport pandas as pdimport bs4import requestsimport spacyfrom spacy import displacynlp = spacy.load('en_core_web_sm')from spacy.matcher import Matcher from spacy.tokens import Span import networkx as nximport matplotlib.pyplot as pltfrom tqdm import tqdmpd.set_option('display.max_colwidth', 200)%matplotlib inline2、读取文本数据Read Data
# import wikipedia sentencescandidate_sentences = pd.read_csv("wiki_sentences_v2.csv")candidate_sentences.shape'''(4318, 1)'''candidate_sentences['sentence'].sample(5)
doc = nlp("the drawdown process is governed by astm standard d823")for tok in doc: print(tok.text, "...", tok.dep_)
3、抽取"主语-宾语"对Entity Pairs Extraction
这些节点将是出现在维基百科句子中的实体。边是这些实体之间相互连接的关系。我们将以无监督的方式提取这些元素,也就是说,我们将使用句子的语法。主要思想是浏览一个句子,在遇到主语和宾语时提取出它们。但是,一个实体在跨多个单词时存在一些挑战,例如red wine。依赖关系解析器只将单个单词标记为主语或宾语。所以,我在下面创建了一个额外的函数:def get_entities(sent): ## chunk 1 # 我在这个块中定义了一些空变量。prv tok dep和prv tok text将分别保留句子中前一个单词和前一个单词本身的依赖标签。前缀和修饰符将保存与主题或对象相关的文本。 ent1 = "" ent2 = "" prv_tok_dep = "" # dependency tag of previous token in the sentence prv_tok_text = "" # previous token in the sentence prefix = "" modifier = "" ############################################################# for tok in nlp(sent): ## chunk 2 # 接下来,我们将遍历句子中的记号。我们将首先检查标记是否为标点符号。如果是,那么我们将忽略它并转移到下一个令牌。如果标记是复合单词的一部分(dependency tag = compound),我们将把它保存在prefix变量中。复合词是由多个单词组成一个具有新含义的单词(例如“Football Stadium”, “animal lover”)。 # 当我们在句子中遇到主语或宾语时,我们会加上这个前缀。我们将对修饰语做同样的事情,例如“nice shirt”, “big house” # if token is a punctuation mark then move on to the next token if tok.dep_ != "punct": # check: token is a compound word or not if tok.dep_ == "compound": prefix = tok.text # if the previous word was also a 'compound' then add the current word to it if prv_tok_dep == "compound": prefix = prv_tok_text + " "+ tok.text # check: token is a modifier or not if tok.dep_.endswith("mod") == True: modifier = tok.text # if the previous word was also a 'compound' then add the current word to it if prv_tok_dep == "compound": modifier = prv_tok_text + " "+ tok.text ## chunk 3 # 在这里,如果令牌是主语,那么它将作为ent1变量中的第一个实体被捕获。变量如前缀,修饰符,prv tok dep,和prv tok文本将被重置。 if tok.dep_.find("subj") == True: ent1 = modifier +" "+ prefix + " "+ tok.text prefix = "" modifier = "" prv_tok_dep = "" prv_tok_text = "" ## chunk 4 # 在这里,如果令牌是宾语,那么它将被捕获为ent2变量中的第二个实体。变量,如前缀,修饰符,prv tok dep,和prv tok文本将再次被重置。 if tok.dep_.find("obj") == True: ent2 = modifier +" "+ prefix +" "+ tok.text ## chunk 5 # 一旦我们捕获了句子中的主语和宾语,我们将更新前面的标记和它的依赖标记。 # update variables prv_tok_dep = tok.dep_ prv_tok_text = tok.text ############################################################# return [ent1.strip(), ent2.strip()]get_entities("the film had 200 patents")'''Output: [‘film’, ‘200 patents’]'''entity_pairs = []for i in tqdm(candidate_sentences["sentence"]): entity_pairs.append(get_entities(i))entity_pairs[10:20]
4、关系抽取Relation / Predicate Extraction
我们的假设是,谓语实际上是句子中的主要动词。例如,在句子中,1929年上映的60部好莱坞音乐剧中,动词是在,这就是我们要用的,作为这个句子中产生的三元组的谓词。下面的函数能够从句子中捕获这样的谓词。在这里,我使用了spaCy的基于规则的匹配def get_relation(sent): doc = nlp(sent) # Matcher class object matcher = Matcher(nlp.vocab) #define the pattern pattern = [{'DEP':'ROOT'}, {'DEP':'prep','OP':"?"}, {'DEP':'agent','OP':"?"}, {'POS':'ADJ','OP':"?"}] matcher.add("matching_1", None, pattern) matches = matcher(doc) k = len(matches) - 1 span = doc[matches[k][1]:matches[k][2]] return(span.text)get_relation("John completed the task")'''Output: completed'''relations = [get_relation(i) for i in tqdm(candidate_sentences['sentence'])]pd.Series(relations).value_counts()[:50]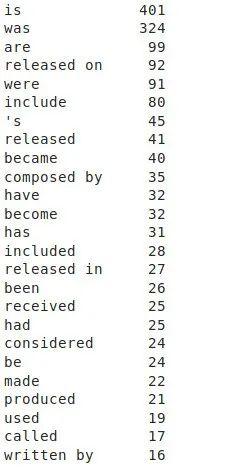
5、构建知识图谱Build a Knowledge Graph
最后,我们将从提取的实体(主语-宾语对)和谓词(实体之间的关系)创建知识图。 让我们创建一个实体和谓词的dataframe:# extract subjectsource = [i[0] for i in entity_pairs] # extract objecttarget = [i[1] for i in entity_pairs] kg_df = pd.DataFrame({'source':source, 'target':target, 'edge':relations})# create a directed-graph from a dataframeG=nx.from_pandas_edgelist(kg_df, "source", "target", edge_attr=True, create_using=nx.MultiDiGraph())画图展示下:plt.figure(figsize=(12,12))pos = nx.spring_layout(G)nx.draw(G, with_labels=True, node_color='skyblue', edge_cmap=plt.cm.Blues, pos = pos)plt.show()
G=nx.from_pandas_edgelist(kg_df[kg_df['edge']=="composed by"], "source", "target", edge_attr=True, create_using=nx.MultiDiGraph())plt.figure(figsize=(12,12))pos = nx.spring_layout(G, k = 0.5) # k regulates the distance between nodesnx.draw(G, with_labels=True, node_color='skyblue', node_size=1500, edge_cmap=plt.cm.Blues, pos = pos)plt.show()
G=nx.from_pandas_edgelist(kg_df[kg_df['edge']=="written by"], "source", "target", edge_attr=True, create_using=nx.MultiDiGraph())plt.figure(figsize=(12,12))pos = nx.spring_layout(G, k = 0.5)nx.draw(G, with_labels=True, node_color='skyblue', node_size=1500, edge_cmap=plt.cm.Blues, pos = pos)plt.show()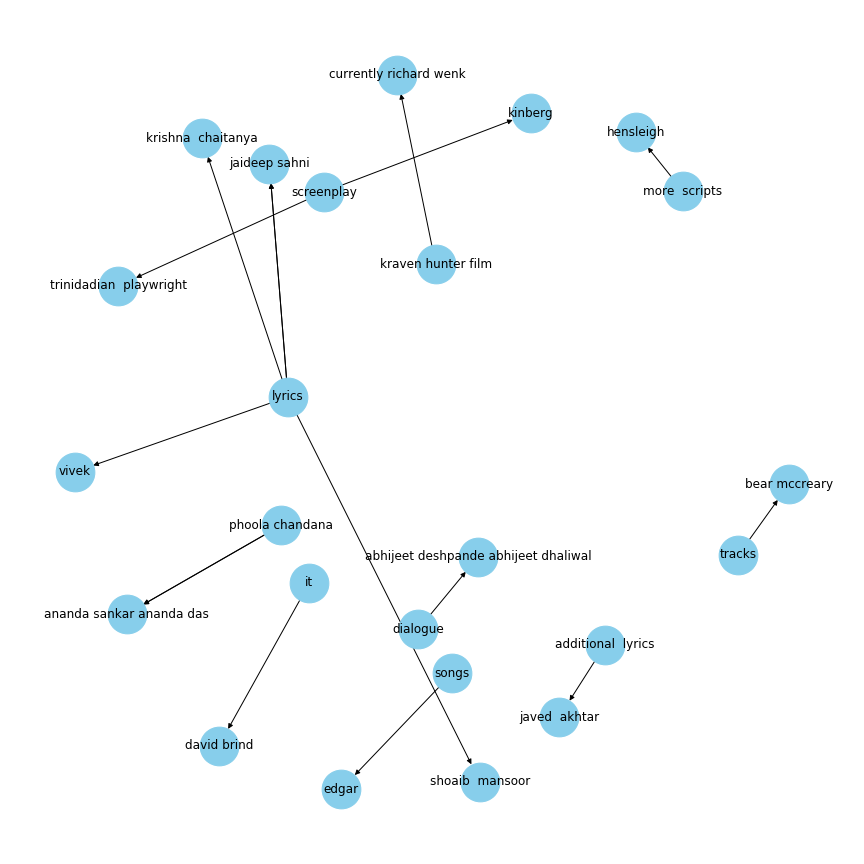

03
总结 在本文中,我们学习了如何以三元组的形式从给定文本中提取信息,并从中构建知识图谱。但是,我们限制自己只使用两个实体的句子。即使在这种情况下,我们也能够构建非常有用的知识图谱。想象一下知识图谱在现有的海量非结构化文本中提取知识的潜力!!! 参考连接[1] Knowledge Graph – A Powerful Data Science Technique to Mine Information from Text (with Python code):
https://www.analyticsvidhya.com/blog/2019/10/how-to-build-knowledge-graph-text-using-spacy/
[2] spacy文档:
https://github.com/explosion/spaCy
[3] spacy中文教程:
https://www.jianshu.com/p/e6b3565e159d

版权声明:本文为weixin_39667797原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。