HBase
HBase是什么?
hbase是bigtable的开源(源码使用Java编写)版本。是建立在hdfs之上的,被设计用来提供高可靠性、高性能、列存储、可伸缩、多版本的NoSQL的分布式数据存储系统,实现对大型数据的实时、随机读写的读写访问
事务的四大特性
事务主要用于管理insert、update、delete语句。
一般来说,事务必须满足四个条件:原子性、一致性、隔离性、持久性。
- 原子性:一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某环节。事务在执行过程中发生错误,会回滚到事务开始前的状态,就像这个事务没有执行过一样。
- 一致性:在事务开始之前、结束之后,数据库的完整性没有被破坏。
- 隔离性:数据库i允许多个并发事务,同时对其数据进行读写和修改的能力。隔离性可以防止多个并发事务执行,由于交叉执行,而导致的数据不一致。事物的隔离分为不同级别,包括读未提交;读提交;可重复读;和串行化。
- 持久性:事务处理结束后,对数据的修改就是永久的,即使系统故障也不会丢失数据。
HBase的数据库要点
- 高并发,可扩展,解决海量数据集的随机实时增删改查
- HBase 本质依然是 Key-Value 数据库,查询数据功能很简单,不支持 join 等复杂操作(可通过 Hive 支持来实现多表 join 等复杂操作)
- 不支持复杂的事务,只支持行级事务
- HBase 中支持的数据类型:byte[](底层所有数据的存储都是字节数组)
- 主要用来存储结构化和半结构化的松散数据。
数据结构
- 结构化:数据结构字段含义确定,清晰,典型的如数据库中的表结构
- 半结构化:具有一定结构,但语义不够确定,典型的如HTML网页,有些字段是确定的(title),有些不确定(table)
- 非结构化:杂乱无章的数据,很难按照一个概念去进行抽取,无规律性
hbase的特点
- 面向列
hbase是面向列的存储和权限控制,并支持独立索引。列式存储,其数据在表中是按照某列存储的,在查询只需要少数的几个字段时,能够大大的减少读取的数据量。 - 多版本
hbase每一个列的存储有多个Version。 - 稀疏性
为空的列不占用存储空间,表可以设计的非常稀疏。 - 大
一个表可以有数十亿行,上百万列。 - 数据类型单一
hbase中的数据都是字符串,没有类型
CAP理论
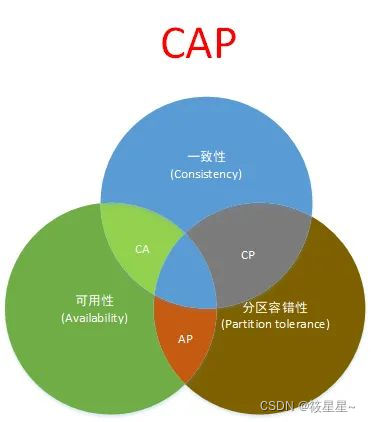
- Consistency(一致性):数据一致更新,所有数据变动都是同步的。
- Availability(可用性):保证每个请求不管成功或者失败都有响应
- Partition tolerance分区容错性(分区容错性) 系统中任意信息的丢失或失败不会影响系统的继续运作
== CAP是没办法同时达到的,要么是CP,要么是CA,要么是AP,是不可能存在CAP的,因为如下:
假如分布式情况下数据库1和数据库2,用户上传一张图片必须同时同步成功才满足一致性(Consistency),并且用户可以看到信息也满足了(可用性),当突发场景数据库1和数据库2突然间因为网络断电原因,某一个直接宕机,那还有另外一个数据库可以提供分区容错性,但是这时候已经无法满足一致性了,所以这种没办法实现。==
hbase架构
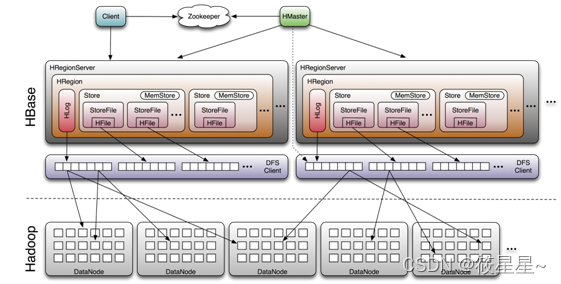
- Client:包含了访问HBase的接口,还有维护缓存加速HBase的访问。
- Zookeeper:实现HMaster的高可用;监控HRegionServer的状态;存储.META.的地址。
- HMaster:维护.META.;为HRegionServer分配Region;维护集群的负载均衡。
- HRegionServer:处理客户端的读写请求;管理HMaster分配的Region。
- HDSF:为HBase提供最终的底层数据存储服务。
Rowkey设计原则
Rowkey 长度原则
Rowkey 是一个二进制码流,Rowkey 的长度被很多开发者建议说设计在10~100 个字节,不过建议是越短越好,不要超过 16 个字节。
原因如下:
- 数据的持久化文件 HFile 中是按照 KeyValue 存储的,如果 Rowkey 过长比如 100 个字节,1000 万列数据光 Rowkey 就要占用 100*1000 万=10 亿个字节, 将近 1G 数据,这会极大影响 HFile 的存储效率;
- MemStore 将缓存部分数据到内存,如果 Rowkey 字段过长内存的有效利用率会降低,系统将无法缓存更多的数据,这会降低检索效率。 因此 Rowkey 的字节长度越短越好。
- 目前操作系统是都是 64 位系统,内存 8 字节对齐。控制在 16 个字节,8 字节的整数倍利用操作系统的最佳特性。
Rowkey 散列原则
如果 Rowkey 是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将 Rowkey 的高位作为散列字段,由程序循环生成,低位放时间字段, 这样将提高数据均衡分布在每个 RegionServer 实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有新数据都在一个 RegionServer 上堆积的 热点现象,这样在做数据检索的时候负载将会集中在个别RegionServer,降低查询效率。
Rowkey 唯一原则
必须在设计上保证其唯一性。
Hive与Hbase之间的区别
Hive的定位是数据仓库,虽然也有增删改查,但其删改查对应的是整张表而不是单行数据,查询的延迟较高。其本质是更加方便的使用MapReduce的威力来进行离线分析的一个数据分析工具。
HBase的定位是Hadoop的数据库,是一个典型的NoSQL,所以HBase是用来在大量数据中进行低延迟的随机查询的
HBase的过滤器
单个列过滤器
列过滤器
列族过滤器
前缀过滤器
键值过滤器
HMaster的作用
HBase中的每张表都通过键按照一定的范围被分割成多个子表(HRegion),默认一个 HRegion超过256M就要被分割成两个,这个过程由HRegionServer管理,而HRegion的分配由HMaster管理。
作用:
- 为HRegionServer分配HRegion
- 负责HRegionServer的负载均衡
- 发现失效的HRegionServer并重新分配
- HDFS上的垃圾文件回收
- 处理Schema更新请求
HRegionServer的作用
- 维护HMaster分配给它的HRegion,处理对这些HRegion的IO请求。
- 负责切分正在运行过程中变得过大的HRegion可以看到,Client访问HBase上的数据并不需要HMaster参与,寻址访问ZooKeeper和HRegionServer,数据读写访问HRegionServer,HMaster仅仅维护Table和Region的元数据信息,Table的元数据信息保存在ZooKeeper上,负载很低。HRegionServer存取一个子表时,会创建一个HRegion对象,然后对表的每个列簇创建一个Store对象,每个Store都会有一个MemStore和0或多个StoreFile与之对应,每个StoreFile都会对应一个HFile,HFile就是实际的存储文件。因此,一个HRegion有多少列簇就有多少个Store。
- 一个HRegionServer会有多个HRegion和一个HLog。
HRegion的作用
Table在行的方向上分割为多个HRegion,HRegion是HBase中分布式存储和负载均衡的最小单元,即不同的HRegion可以分别在不同的HRegionServer上,但同一个HRegion是不会拆分到多个HRegionServer上的。HRegion按大小分割,每个表一般只有一个HRegion,随着数据不断插入表,HRegion不断增大,当HRegion的某个列簇达到一个阀值(默认256M)时就会分成两个新的HRegion。
- <表名,StartRowKey, 创建时间>
- 由目录表(-ROOT-和.META.)记录该Region的EndRowKey
HRegion的定位
HRegion被分配给哪个HRegionServer是完全动态的,所以需要机制来定位HRegion具体在哪个HRegionServer,HBase使用三层结构来定位HRegion。
通过zk里的文件/hbase/rs得到-ROOT-表的位置。-ROOT-表只有一个region。
通过-ROOT-表查找.META.表的第一个表中相应的HRegion位置。其实-ROOT-表是.META.表的第一个region,.META.表中的每一个Region在-ROOT-表中都是一行记录。
通过.META.表找到所要的用户表HRegion的位置。用户表的每个HRegion在.META.表中都是一行记录。
-ROOT-表永远不会被分隔为多个HRegion,保证了最多需要三次跳转,就能定位到任意的region。Client会将查询的位置信息保存缓存起来,缓存不会主动失效,因此如果Client上的缓存全部失效,则需要进行6次网络来回,才能定位到正确的HRegion,其中三次用来发现缓存失效,另外三次用来获取位置信息。
hbase的写数据的流程\
- Client先访问zookeeper,从.META.表获取相应region信息,然后从meta表获取相应region信息
- 根据namespace、表名和rowkey根据meta表的数据找到写入数据对应的region信息。
- 找到对应的regionserver 把数据先写到WAL中,即HLog,然后写到MemStore上
- MemStore达到设置的阈值后则把数据刷成一个磁盘上的StoreFile文件。
- 当多个StoreFile文件达到一定的大小后(这个可以称之为小合并,合并数据可以进行设置,必须大于等于2,小于10——hbase.hstore.compaction.max和hbase.hstore.compactionThreshold,默认为10和3),会触发Compact合并操作,合并为一个StoreFile,(这里同时进行版本的合并和数据删除。)
- 当Storefile大小超过一定阈值后,会把当前的Region分割为两个(Split)【可称之为大合并,该阈值通过hbase.hregion.max.filesize设置,默认为10G】,并由Hmaster分配到相应的HRegionServer,实现负载均衡
hbase读数据的流程
- 首先,客户端需要获知其想要读取的信息的Region的位置,这个时候,Client访问hbase上数据时并不需要Hmaster参与(HMaster仅仅维护着table和Region的元数据信息,负载很低),只需要访问zookeeper,从meta表获取相应region信息(地址和端口等)。【Client请求ZK获取.META.所在的RegionServer的地址。】
- 客户端会将该保存着RegionServer的位置信息的元数据表.META.进行缓存。然后在表中确定待检索rowkey所在的RegionServer信息(得到持有对应行键的.META表的服务器名)。【获取访问数据所在的RegionServer地址】
- 根据数据所在RegionServer的访问信息,客户端会向该RegionServer发送真正的数据读取请求。服务器端接收到该请求之后需要进行复杂的处理。
- 先从MemStore找数据,如果没有,再到StoreFile上读(为了读取的效率)。
HBase 优化
高可用
在 HBase 中 Hmaster 负责监控 RegionServer 的生命周期,均衡 RegionServer 的负载,如果 Hmaster 挂掉了,那么整个 HBase 集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以 HBase 支持对 Hmaster 的高可用配置。预分区
每一个 region 维护着 startRow 与 endRowKey,如果加入的数据符合某个 region 维护的rowKey 范围,则该数据交给这个 region 维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高 HBase 性能 .RowKey 设计
一条数据的唯一标识就是 rowkey,那么这条数据存储于哪个分区,取决于 rowkey 处于哪个一个预分区的区间内,设计 rowkey 的主要目的 ,就是让数据均匀的分布于所有的 region中,在一定程度上防止数据倾斜。接下来我们就谈一谈 rowkey 常用的设计方案内存优化
HBase 操作过程中需要大量的内存开销,毕竟 Table 是可以缓存在内存中的,一般会分配整个可用内存的 70%给 HBase 的 Java 堆。但是不建议分配非常大的堆内存,因为 GC 过程持续太久会导致 RegionServer 处于长期不可用状态,一般 16~48G 内存就可以了,如果因为框架占用内存过高导致系统内存不足,框架一样会被系统服务拖死。基础优化