SQL作为一门声明式语言,屏蔽了底层的执行过程,但是其语句的执行顺序也不再是简单的顺序执行。因此,想要熟练的阅读SQL语句,要掌握SQL语言的执行顺序,而其中层层嵌套的 SELECT 正是难点所在。
截至本周,同学们应该已经掌握了 SELECT 语句的所有从句:
SELECT [DISTINCT | ALL]
column-list FROM table-names
[WHERE condition]
[ORDER BY column-list]
[GROUP BY column-list]
[HAVING condition]
为了透彻地理解 SELECT 语句,有必要掌握其从句的执行顺序:
- from子句组装来自不同数据源的数据。
- where子句基于指定的条件对记录进行筛选。
- group by子句将数据划分为多个分组。
- 使用聚集函数(Aggregate function)进行计算。
- 使用having子句筛选分组。
- 计算所有的表达式。
- select 的属性。
- 使用order by对结果集进行排序。
这个顺序并不需要强记,明白大概的先后顺序即可,比较关键的有两点:
(1)SELECT 虽然出现在最前面,但是其执行的顺序几乎在最后,这能够解释为什么列的别名不能在 WHERE 从句中使用,因为在SELECT中对列的命名在WHERE之后才执行。
(2)聚集函数(Aggregate function)的执行在 GROUP BY 之后,在 HAVING
之前,这代表:
- Aggregate function 执行的对象不再是 FROM 指定的整张表,而是由
GROUP BY产生的 每一个集合. - 写在SELECT语句中的聚合函数的结果的别名可以在 HAVING 从句中使用。
例如某事业单位组织员工体检,向医院提供了一张体检套餐选择表,有1000余条记录。这张表记录了每个员工的信息以及其所选择的体检套餐(每人选择一种体检套餐),导入MySQL数据库之后表定义如下:

在录入信息时发现,存在某一人重复选择套餐且两次选择的套餐不一样的情况(在表中有多条该人员记录,且 Combination 属性的值不一样),那么此时需要查出这张表中多次出现过的人员,通知他们确认所选套餐。
执行如下语句:
SELECT name,ID,count(*) as Frequency
FROM result0
GROUP BY ID
HAVING Frequency>1;
即可获得所需要的记录:
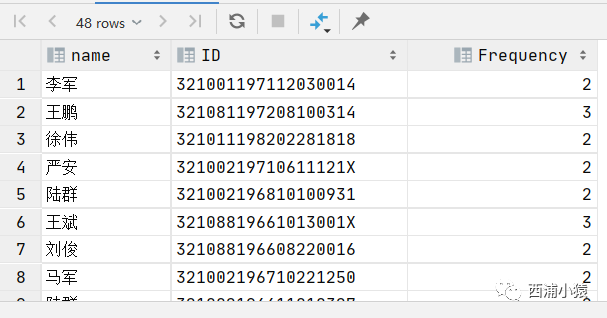
在这个查询语句中 HAVING 中成功的使用了 SELECT 语句中聚合函数结果的别名Frequency,而聚合函数count(*) 计算的是每个由 ID 相同的记录构成的集合中的记录个数,这说明聚合函数的执行在GROPU BY之后,在 HAVING 之前。
相关子查询 和 EXIST
一般而言,当 SELECT 中存在嵌套的子查询语句时
子查询 (subquery) 分为两种:非相关子查询和相关子查询,判定的标准在于子查询是否可以提出来单独执行产生结果。由于相关子查询依赖父查询中表的数据工作,不能够独立于父查询执行。IN多见于处理非相关子查询的结果,而 EXISTS 一般与相关子查询连用
SELECT * FROM
Employee AS E1
WHERE EXISTS(
SELECT * FROM
Employee AS E2
WHERE E1.Name = E2.Manager);
EXISTS本身的含义非常简单,EXISTS Set 当Set为空时,结果就为false,Set 非空时,结果就为 EXISTS。但是当 EXISTS 和相关子查询连用时,含义就有些晦涩,其实这种复杂性是相关子查询带来的。
相关子查询的机制如下:
- 从外层查询中取出一个元组,将元组相关列的值传给内层查询。
- 执行内层查询,得到子查询操作的值。
- 外查询根据子查询返回的结果或结果集得到满足条件的行。
- 然后外层查询取出下一个元组重复做步骤1-3,直到外层的元组全部处理完毕
以上面的查询语句为例,E1.Name = E2.Manager 这个语句其实表示的是嵌套循环,外循环遍历左侧列,内循环遍历右侧列,内循环中判断左侧列中当前元素和右侧列中当前元素是否相等,相等则将记录保留到结果集合中。
相关子查询和非相关子查询最大的区别在于:从逻辑上理解,非相关子查询执行完毕之后返回一个 集合/单值集合,然后外部语句使用这个集合运算,而相关子查询每执行一步(内循环一步),其结果就会被封装成一个集合交给外部语句,这一步产生的结果与上一步的结果不会共存在一个集合中。也就是说,在运行中的任意一个时间节点,相关子查询所形成的结果集合中只可能有1个或0个元素,那么用EXISTS来判断,自然就可以确定当前的记录是否满足条件了。