数据挖掘xgb使用总结
1.集成学习背景
说到Xgb一般会先想到GBDT,从而引出boost类模型,什么是xgb模型,简单的说这就是一个常见的分类(回归)模型,和LR,SVM一样广泛应用在数据分类中,xgb的全称是X (Extreme) GBoosted,其中的X是极端的,G是梯度,翻译过来可以是极致的梯度提升模型,说到底还是梯度提升模型,本质和gbdt,adaboost一样的“误差”渐少的集成模型方式。那为什么会有如此好的效果呐?
先提到boost开始,对待一个决策问题我们首先会想到使用多人意见进行综合然后输出最终结果,即实际生产中我们很难产出一个决策力超强的模型,但是总能生产出"有点"准的策略,集成学习(boost、bagging)便是利用这一特点,选择相对较准的弱模型进行“组合”得到一个强模型。当然这些都是感官认识,实际理论支持可以以PAC准则(不是pca)进行证明,这些我们不会进行过多讨论。
实际的生产中这类模型比较受欢迎,相比较LR这类“线性”单特征组合模型,集成学习能更多的学习到内部特征组合也同时能得到更高的准召,但往往会有‘过拟合’的困扰,这些后面在剪枝,缩减等trick上进行了优化。
2.常见模型及特点
2.1 模型adaboost
Adaboost模型作为介绍boosting类型模型就像rf在bagging模型中一样,模型的迭代内容比较能代表boosting的迭代过程,其实在生产中我们不太会用了,为什么呐?我们直接从迭代过程进行了解
基本原理:学习较多的“弱分类器”利用“权重”将“弱分类器”进行加权得到最终结果
涉及两个问题1)“弱分类器”如何学习? 2)加权的权重如何计算?
提高上一轮弱分类器误分类数据的权重,降低分类正确的分类数据权重;当前分类器可以对分类正确的起到很好的分类作用,而当前分类器错误的由于样本权重提高,在下一轮构造弱分类器时对loss的影响(惩罚)更大,因此下一轮分类器会偏向上一轮分类错误的数据,迭代多轮即生产多轮弱分类器
X i j , Y i , G i ( x ) , w i j , e i , D i , Z i , a i X^{j}_i,Y_i ,G_i(x),w_ij,e_i,D_i,Z_i,a_iXij,Yi,Gi(x),wij,ei,Di,Zi,ai 一般i表示第i个data,j表示第j维数据,所有上式子的取值是第i个数据的第j维数值。上面的一组符号表示分别代表:待分类数据,label,第i个弱分类器,第i个分类器对应样本的权重,第i个分类器的分类误差率,权重的vertor表示,第i轮的规范化因子(用于更新下一个分类器的权重),第i个分类器的权重,看到这么多定义其实直接组装就可以知道分类器的结果了:
G ( x ) = s i g n ( f ( x ) ) = s i g n [ ∑ a i G i ( x ) ] G(x) = sign(f(x)) = sign[\sum a_iG_i(x)]G(x)=sign(f(x))=sign[∑aiGi(x)]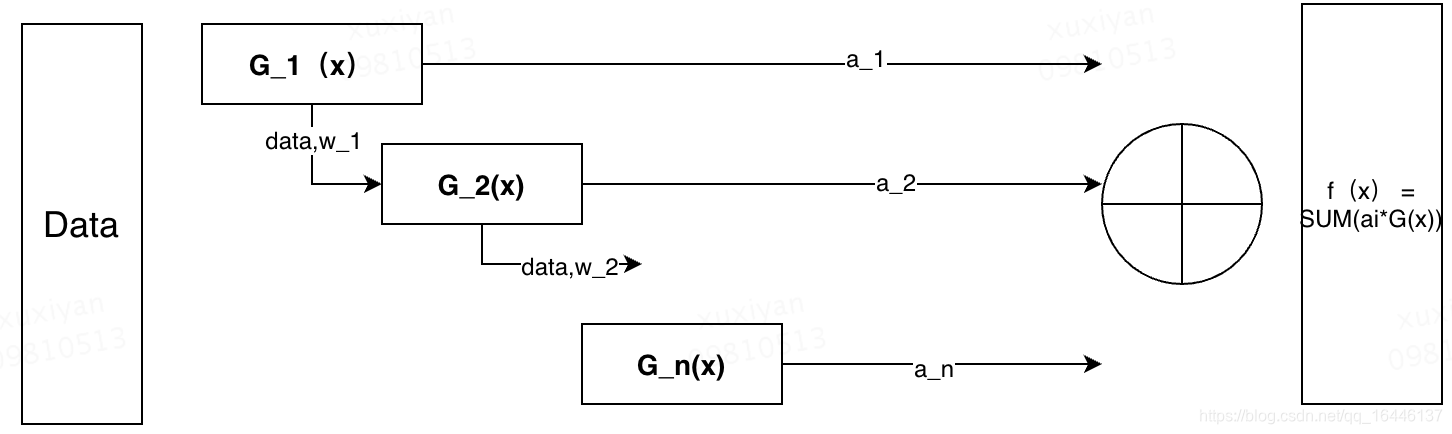
adaboost经常会说训练误差是以指数速率下降的,可以通过下式得出:
1 / N ∑ I ( G ( x i ) ! = y i ) < = e x p ( − 2 M r 2 ) 1/N \sum I(G(x_i)!=y_i)<=exp(-2Mr^2)1/N∑I(G(xi)!=yi)<=exp(−2Mr2)
不等式左侧即为adaboost函数的平均误差,右侧是以r为参数指数函数