第二节 Shell脚本编写语法及命令
2.1如何创建脚本文件?
1.创建脚本文件 -----vim 名字.sh
2.文件中的第一行-----编写解释器----#!/bin/bash
3.编写内容----不要出现交互式的语句
4.给脚本可执行权限----创建的文件没有x权限,需要给X权限
5.执行脚本---- ./脚本名.sh
6.作业: 编写脚本 :执行脚本会在/tmp创建yyn.log文件,并且文件中第一行是1,第二行是2,…10
第一种方式:内容如下: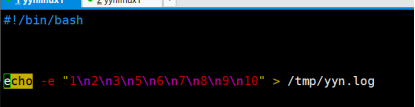
执行结果如下: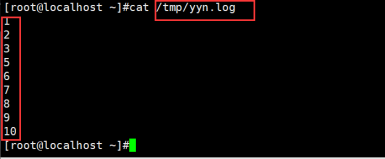
2.2标准输入重定向----脚本中的非交互式编辑文件
1.命令<
<表示标准输入重定向 +文件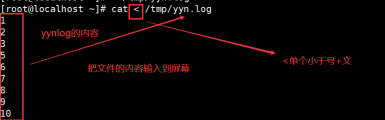
2.命令<<
<<表示标准输入重定向 +自定义文本 命令+<<+字符1+回车+内容+字符2
字符1和字符2必须是一样的
练习:一般使用<<EOF 和>EOF来定义
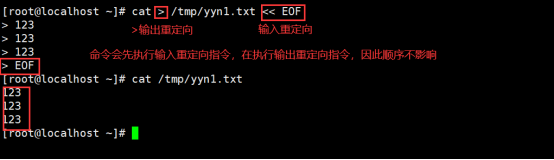
命令行中会有续航符,但是在编写脚本的时候,没有续航符,直接回车编写就行,
练习:编写yum源的配置文件:------脚本中的非交互式编辑文件
2.3执行脚本的方式
2.3.1.第一种方式(推荐使用)
脚本文件的第一行必须写命令解释器 ------#!/bin/bash
执行时,----绝对路径/相对路径 脚本文件必须有可执行权限(x)
---------绝对路径执行
-----------相对路径执行
绝对和相对执行的脚本文件中必须有-----#! /bin/bash
2.3.2.第二种方式
脚本中无需定义命令解释器
执行时 bash+脚本路径
-------相对路径执行
-------绝对路径执行
这个执行方式不需要写-----#!/bin/bash
总结:.上述2种方式都是在子shell中执行脚本都是先运行子shell,
2.3.3.第三种方式(极少用)
1.使用source进行执行------在当前设立了执行脚本
Source 脚本 ========== .(点) 脚本
Source .bashrc source .bash_profile----文件生效
在当前shell执行脚本,即使子进程执行完,退出,当前shell窗口也可以看到执行的结果
作业:编写脚本:
创建/tmp/test1目录
在目录中创建以时间命名的文件
将指定/etc/profile.d目录中的内容放入目录中
第一种方式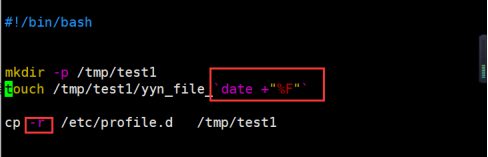
执行结果:
出现大量一样的数据需要修改,咋办?
1)在vim编辑器下在冒号模式下执行替换操作: %s/替换前的字符/替换后的字符/g
%S表示在所有行进行搜索, /g表示全局变量的全部行匹配
第二种方式: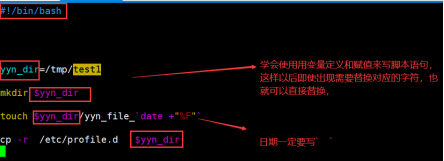
2.4脚本编写语法
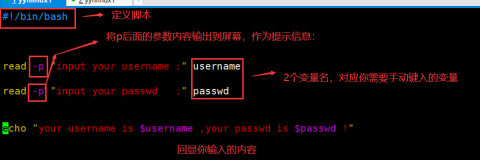
2.4.1 read 语法
语法格式: read +参数 “ 提示内容”+变量名
参数: -p+参数内容------参数内容显示在屏幕上,作为提示信息
-s--------(针对输入密码字符,使其不可见)
语法功能:可以从外界读入变量值
常用命令: read 变量名
Read -p “提示内容” 变量名
Read -s 不回显---类似密码
练习1:

针对密码不可见:-----加-s参数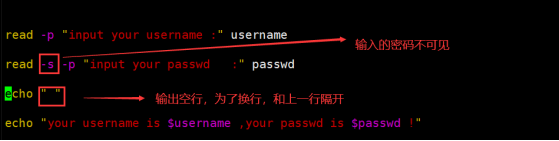
练习2: 不指定用户固定使用一个目录来创建,+配合使用read -p
练习3: 配合使用$1参数

2.5位置参数变量
2.5.1 $n 用法—n是数字(除0)
$n----表示位置参数,表示传递的参数----是位置变量/位置参数
使用方式: 脚本名 变量值1 变量值2 变量值3 ……
$1到9 , 代 表 第 一 个 到 第 九 个 参 数 , 十 以 上 的 参 数 , 需 要 用 括 起 来 , − − − 9,代表第一个到第九个参数,十以上的参数,需要用{ }括起来,---9,代表第一个到第九个参数,十以上的参数,需要用括起来,−−−{10}
$1可以表示第一个变量值, $2表示第二个变量值, $3表示第三个变量值.,以此类推
变量名=$1—就表示,将脚本文件执行的第一个变量值,赋值给变量名
练习: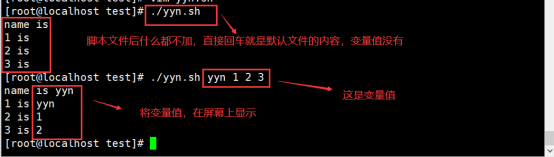

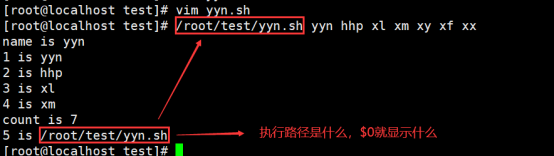
- $0 语法 —0(零)
$0—表示显示执行脚本文件的路径-----就是自己本身 ---- 是位置变量

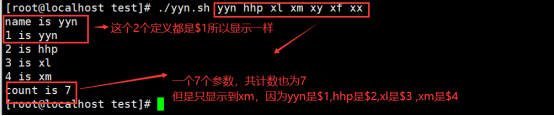
2.5.2 $# 用法
$#表示参数的数量,-----统计一共输入了多少个参数------是位置变量
统计脚本/命令后的参数数量
练习:在没有参数的情况下,统计的个数为零
练习:
2.5.3 $* 用法
∗ − − − − − 这 个 变 量 代 表 命 令 行 中 的 所 有 参 数 ( *-----这个变量代表命令行中的所有参数 (∗−−−−−这个变量代表命令行中的所有参数(*把所有参数看成是一个整体)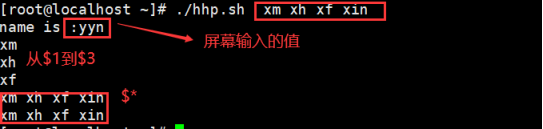

2.5.4 $@ 用法
@ − − − − 这 个 变 量 代 表 命 令 行 中 的 所 有 参 数 ( @----这个变量代表命令行中的所有参数 (@−−−−这个变量代表命令行中的所有参数(@把每个区分对待)
2.5.5 $? 用法
Echo $? 返回上一条命令的成功还是失败,0为成功,非0为失败
非0有(1-255)种定义,共计256种
2.6文本处理命令wc
1.wc命令-----(word count)----字数统计
基本语法:wc +参数+文件名/文件路径
参 数: -l 仅显示行数
-w 仅显示单词数
-c 仅显示字节数
-m 仅显示字符数
显示结果: 会显示行数,单词数,字节数,文件名
练习:相同的单词算一个单词

2.7管道符
- 管道符表示:| (竖杠表示)
- 命令格式:命令1 | 命令2 | 命令3 | 。。。。。。
- 管 道 符:把第一个命令的结果送给第二个命令,把第二个命令的输出,当做第二个命令的输入。管道符只传递正确执行信息。
2.7.1. 连续使用管道符
1.字符转换/删除命令 -----tr
1)命令格式:“命令内容” | tr + “替换前的字符集合”+ “替换后的字符集合”-----替换
“命令内容” | tr -d “要删除的字符集合”-----删除单个对应的字符
而不是以单词去删除
2)练习1:单个字符替换
练习2:字符集合替换-----大小写字母转换
练习3: 删除指定字符串里的内容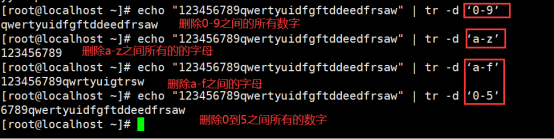

- 切割命令-------cut
1)2种切割依据:
按照指定的分割符进行切割
按照字符数切割
2)命令格式:“命令内容” | cut -d 分割符 -f ‘想要内容的分段数’-----分割符
参数: -d—指定分割符(空格—‘ ’)
-f ----指定想要保留的分段数
应用到文件中格式如下:
Cut -d + 分割符 -f 指定段数 文件路径
按照字符数切割:
Cut -c + 对应字符数 文件路径-------取出来的是单个字符
Cut -c + 字符集数 文件路径 --------取出来的是一段字符
练习1:以逗号,作为分割符,取字符----切记分割符不要加引号
练习2:以空格‘ ’ 作为分割符,取字符
练习3:切割文件中想要的字符
练习:取出/etc/passwd中第20行内容的第一个字段

练习4:取出指定文件的单个字符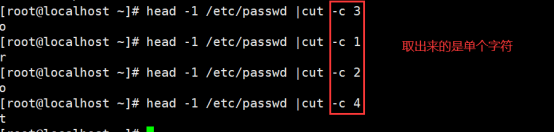
练习5,取出root这个单词
练习:取出不连续的单个字符
3.将处理结果保存到变量
4.与文本处理命令与管道符配合使用
与文本处理命令与管道符配合使用,可以接收管道符的输入

6.字符替换命令-------sed
命令格式1:sed ‘s/原字符串/新字符串/’ 文件
命令格式2:sed ‘s/原字符串/新字符串/g’ 文-----g表示全局global
命令格式3:sed ‘s/原字符串//’g 文件------删除原字符串,或者替换为空
2.8排序命令(重点)
2.8.1排序命令----sort
基础语法: sort +参数+文件
参数: -f:忽略字符大小写
-n:对数值进行排序
Sort -n +文件
-k:指定排序字段
-u(uniq,)重复的行只显示一行
-t:指定分隔符---把整个文件中的每一行以指定的分隔符进行切片,然后
比较选定的片进行排序
Sort -t +分割符 + -k 指定字段数±n 文件
功能描述:对指定的文件中的行进行排序
2.8.2.删除重复行命令----uniq
参数: -c:统计每一行出现的次数 count
-d:仅显示重复过的行
-u:仅显示未重复行
参数用的少
2.8.3.练习

没有指定是字符还是数值,按照字符选择
对数值进行排序
对文件以数值(uid)方式排序
对文件的单个字符,进行去重复工作
如果执行去重复操作后发现,还有重复的字符,是因为文本处理的时候认为只有连续的在一起的才是重复的

以上2种去重操作,配合排序使用,可以真正的做到去除重复字符,效果一样
对去重后的字符,进行统计
作业:
1.统计/bin,/usr/bin,/sbin和/usr/sbin等目录中的文件个数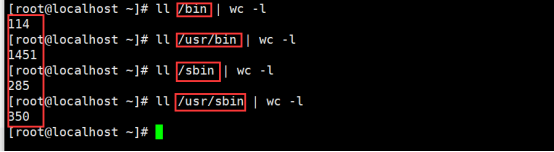
2.显示当前系统中所有用户的shell,要求,每种shell只显示一次
/etc/passwd中的内容----root❌0:0:root:/root:/bin/bash
root表示用户名,X表示密码,0:0表示属主和属组,
/root表示家目录 /bin/bash表示shell(命令解释程序)
3.取出/etc/passw文件的第七行
4.显示第三题中取出的第7行的用户名
5.统计/etc目录下以p或者P开头的文件个数
6.从ifconfig文件中将IP地址保存在IP变量中

2.9Linux的哲学思想:
组合单一的功能的命令,完成复杂的任务。
2.10tee命令:
1.tee命令:一个输入,两个输出
2.我们想把命令执行结果既通过管道符送给另外一个命令,又想保存一份
练习:
2.11grep命令:
1.Grep命令---------G:Global RE:Regular Expression P:Printing
-----过滤文本/文本匹配------全局正则表达式匹配并打印
正则表达式可以在vim /less里用
2.11.1基本用法
- grep +选项+模式(pattern) +文件
Pattern模式是由字母数字结合元字符共同构成的匹配模式
1)grep +模式+文件----指定文件中匹配指定模式
2)命令 | grep 模式-----从管道符的输入中匹配指定模式
3)grep 关键词 文件-----从指定文件中找到对应关键词的行
2.选项:
-v: 删选出不包含匹配项的行,-----invert-match—把结果显示出来
-i:在过滤的时候不区分大小写ignore-case

-o:只显示匹配到的内容,only-matching
-A(after),显示匹配到的行后,还显示其行后的其他行内容,每一个匹配项下面的多行
一般格式为: grep -A +数字 +关键词+文件-----向下面取行内容
-B(before),-----向前面的行取内容
-C(context)-----上下文各取内容行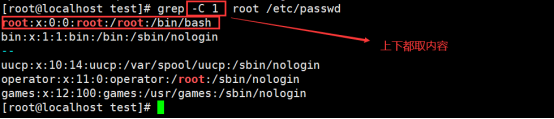
2.11.2基本正则表达式元字符
之前学的*,?都是统配符,而正则表达式里也会出现,但不是一个概念
正则表达式的元字符----用于进行匹配的特殊符号
1.字符匹配
. (点) 匹配任意单个字符
[ ] (中括号) 匹配指定范围内的任意单个字符
[^] (中括号+脱字符) 指定范围外的单个字符
[[:space:]] (:space:) 匹配空白字符,包括空格,tab
[1] -------表示匹配所有非空白字符
[:punct:] (:标点:) 标点符号
2.练习(1):查找r…t的匹配单词,其中点可以是好多个—r…t
练习(2):用[加一个范围]----[abc]固定范围/[a-z]不固定范围,最后的出现的字符是匹配到的范围内容的任意单个字符

如果范围是这个----r[azAZ09]t,最后只会匹配6个:rat/rzt/rAt/rZt/r0t/r9t
注意,一定要看自己匹配的范围,[ ]表示匹配范围内容的任意单个字符
练习(3):匹配除范围内的字符—r[^abc]t 表示,带r a/b/c t都不要
练习(4) ----匹配空格
练习(5):—匹配空白字符+tab------- r [ abc [:space:] ] t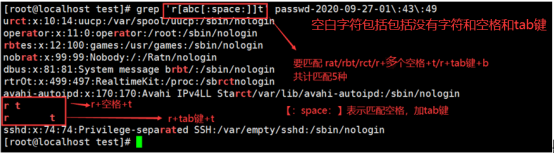

练习(6):匹配标点符号
2.次数匹配
1.次数匹配分类
(星号)—匹配号前面的字符,—任意次(零次,1次,多次都属于任意次匹配)
?(问号)----匹配?号前面的字符0次或1次----通常?使用
{ }(花括号)-----{m,n} 最少m次,最多n次----通常{m,n}使用
2.练习:匹配*号的前面字符的任意次

练习(1): 匹配任意单个字符的任意次----只要是以r开头,以r结尾的都会找出来,
任意单个字符匹配,点表示任意字符
练习(2)匹配?前面字符的零次和1次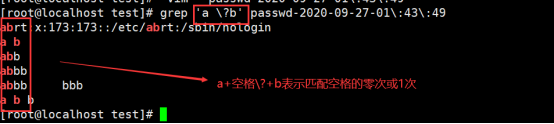
练习(3):匹配前面字符的n次,–可以是一个范围,可以是单个数字,
{1,}-----没有下限,就表示最少匹配前面字符1个空格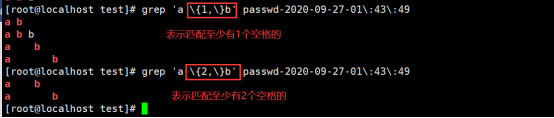

总结------a{2,4}b:至少匹配2个a,最多匹配4个a
------a *:匹配a的任意次(有零次,有1次,有多次)
------a?:匹配a的零次或者1次
------次数匹配符前面是什么字符,就匹配这个字符几次
------.表示任意字符单次
------*匹配前面的字符任意次
------.*表示匹配任意字符任意次
3. 锚定符
^ 行首锚定 ------匹配行开头是一个单词的------^字符
$ 行尾锚定 -----匹配行结尾的单词----字符$
< 词首锚定 -----配合<字符-------加\为了表示是锚定, 否则就是<小于号
>词尾锚定-----配合字符>-------加\为了表示是锚定,否则就是>大于号

练习:
•1. 显示/proc/meminfo文件中以不区分大小写的s开头的行

•2. 显示/etc/passwd中以nologin结尾的行
•3. 显示/etc/inittab中以#开头,且后面跟至少一个空白字符,而后面又跟了至少一个非空白字符的行 (多看几遍)
• grep ‘#[[:space:]]{1,}[[:space:]]{1,}’ /etc/inittab
•4. 显示/etc/inittab中包含了,即两个冒号中间一个数字的行
4.分组字符/分组匹配
1.分组字符----( 内容 ) 用小括号表示,
-----通常这样使用: ----(内容) 就是一个括号加一个
前向引用: 在正则表达式中,对()中内容能实现前向引用,
扩展使用:\ (分组内容).*\1-----》\1表示调用第一个分组里面的内容就是( )
就是(分组内容)是什么,后面的就匹配和分组内容一样的
2.练习: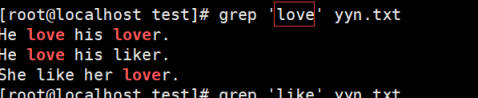


匹配都是like或者love的字符

显示/etc/initab文件中以一个数字开始并以一个相同的数字结尾的行
统计/etc目录下以p或者P开头的文件个数
7.请写出可以精确找到类似两行的模式:
l1:1:wait:/etc/rc.d/rc_1
l3:3:wait:/etc/rc.d/rc_3
l1:1:wait:/etc/rc.d/rc_3
l3:1:wait:/etc/rc.d/rc_3
:space: ↩︎