第一章 引论
引论没什么可说的,出现在填空题中的概率都很低,更别提出现在大题中了。
本章需要知道:
- 编译程序只翻译不执行,解释程序边解释边执行。编译程序和解释程序的本质区别在于:是否生成目标代码。
- 编译程序总框:词法分析器(输入为源程序,最小单位是单个符号)、语法分析器(输入为单词符号,输出为语法单位)、语义分析及中间代码产生(输入为语法单位,输出中间代码)、代码优化、目标代码生成。
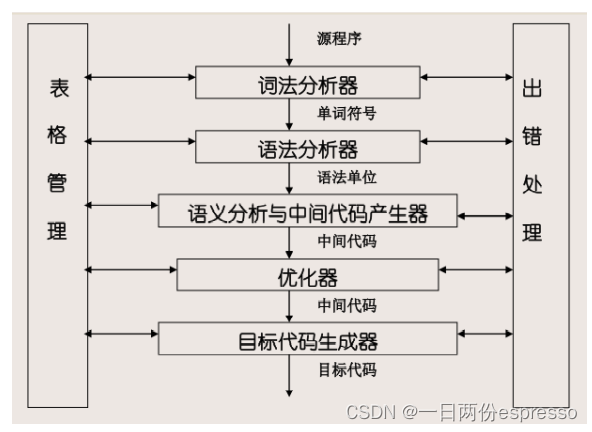
两边是出错处理和表格管理。 - 编译程序的大部分时间用在了表格管理上。
- 标识符属于语法范畴,名字属于语义范畴,名字由标识符来表示,但是二者有着本质的区别。
- 编译程序的五个基本阶段是将源程序翻译为目标程序在逻辑上要完成的工作,而遍是指完成以上五个阶段的工作需要对源程序进行几次扫描。
第二章 高级语言及其语法特性
仍然是集中在判断、选择、填空,且占比可能不多,大题可能性为0。
- 程序语言由两方面定义:语法(标识符)、语义(名字)(课件里还加了一个语用)。
- 某个文法产生式的语言,在选择、填空题有可能问到。此外,算术表达式的文法要记住,因为期中考试考了,它是:

- 形式语言鸟瞰:各类文法的描述能力如下:
0型文法——图灵机;
1型文法——线性界限自动机;
2型文法——不确定的下推自动机;
3型文法——有限自动机。
注意3型文法(线性文法/正规文法的形式定义)
①α是终结符的闭包,而非单个终结符。
②产生式可以是A → αB也可以是A → α。 - 文法、语言的二义性,不要混淆:
第三章 词法分析
看了下2016年和2020年的期末卷子,2016年第一道大题考察了NFA转DFA,2020年第一道题考察NFA转DFA,第二道题考察文法转化为等价的正规文法后(可以通过正规式转化,右线性文法),画出状态转换图。掌握了期中考试两道与词法分析有关的题目,这块的分应该是必拿的。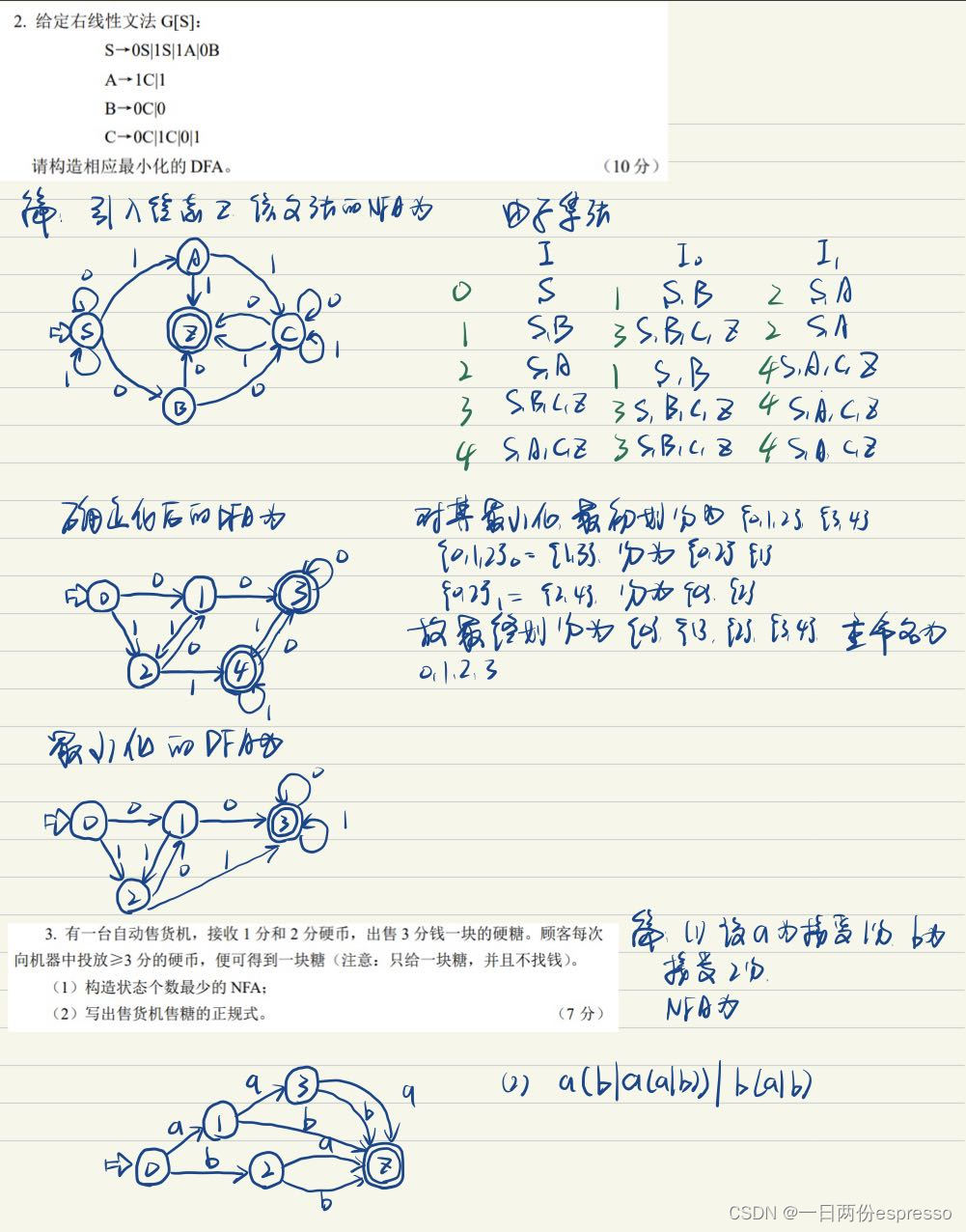
- 词法分析器的任务:输入源程序,输出单词符号,一般包括单词的种别编码和属性值。
- NFA和DFA的终态集都是可有可无可多个,DFA初态唯一,NFA初态可以有多个。
- 与DFA等价的正规式——看首尾。与正规式等价的DFA——首先它要是一个DFA,可以有无用的状态。
第四章 自上而下的语法分析
2020年没考大题,但是由于期中考试此部分的大题占到了16分且是最难的,因此仍保守的估计会有一道大题,大题无非是三步走:
- 消除左递归、克服回溯(提取左公共因子);
- 求FIRST和FOLLOW集合;
- 求预测分析表。
写递归下降程序考的可能性就和自下而上语法分析写出详细的移进规约过程一样,为0。
因此,先解决期中考试的大题:
预测分析表的构造:
注意:(2)和(3)只执行一条,不同时执行。
构造FIRST(α):
构造FOLLOW(A):
注意第三条,对于A → B,在FOLLOW(A)中的都在FOLLOW(B)中,原因是A推导至B后不会影响之前A后面的格局,注意与FIRSTVT和LASTVT区分,这二者是向前传递,而FOLLOW向后传递。
课件与单元测试中要注意的地方不多:
- LL(1)的第一个L表示对源程序自左向右扫描,第二个L表示构造一个最左推导。(LR(1)的R是构造一个最右推导的逆过程)
- 使用LL(1)前需要先消除左递归、克服回溯。
- LL(1)文法一定是无二义的,并且预测分析表入口唯一。
第五章 自下而上的语法分析
可以确定100%会有一道大题,套路是(1)画语法树,求短语、句柄、素短语那一套;(2)构造FIRSTVT、LASTVT和算符优先关系表;(3)问该文法是否为算符优先文法;
故先解决期中考试中分值最高的大题:
注:
- 算符文法——OG:不含相继出现的两个非终结符,但是可以有ε-产生式。
- 算符优先文法——OPG:不含ε-产生式,且算符之间的优先关系至多为一种。
FIRSTVT构造方法:
注意向前传递,即P → Q…时,FIRSTVT(Q)都在FIRST§中。
LASTVT的构造: 仍然注意 P → …Q(非终结符Q在最后时),LASTVT(Q)加入LASTVT§。
仍然注意 P → …Q(非终结符Q在最后时),LASTVT(Q)加入LASTVT§。
小题需要注意:
- 规范归约(最左归约)是一个最右推导的逆过程(LR中的R),最右推导也称为规范推导,由最右推导推出的句型称为规范句型。
- 语法分析器的四个动作:移进、归约、识别、报错。前三者都会改变当前格局,而匹配终结符不会,因为它不是原子操作。
- 规范归约可归约串:句柄(最左直接短语)。
算符优先分析可归约串:最左素短语。
二者不一定等价。 - 若一个句型中出现了某个产生式的右部,则此右部不一定是句柄。
- 优先函数分为f和g,f称为入栈优先函数,g称为比较优先函数。如果优先函数存在,则不唯一(无穷多个)。
- YACC是语法分析器的自动生成器,使用LALR(1)分析法。LEX是词法分析器自动生成器。
- LR分析法中文法的描述能力:
LR(K) > LR(1) > LALR > SLR(1) > LR(0)
可见,LR(k)最强,LR(1)次之,SLR(1)不如LR(1),是它的真子集,LALR(1)介于二者之间,LR(0)最弱。 - 自上而下、自下而上分析的所有文法都是无二义文法。
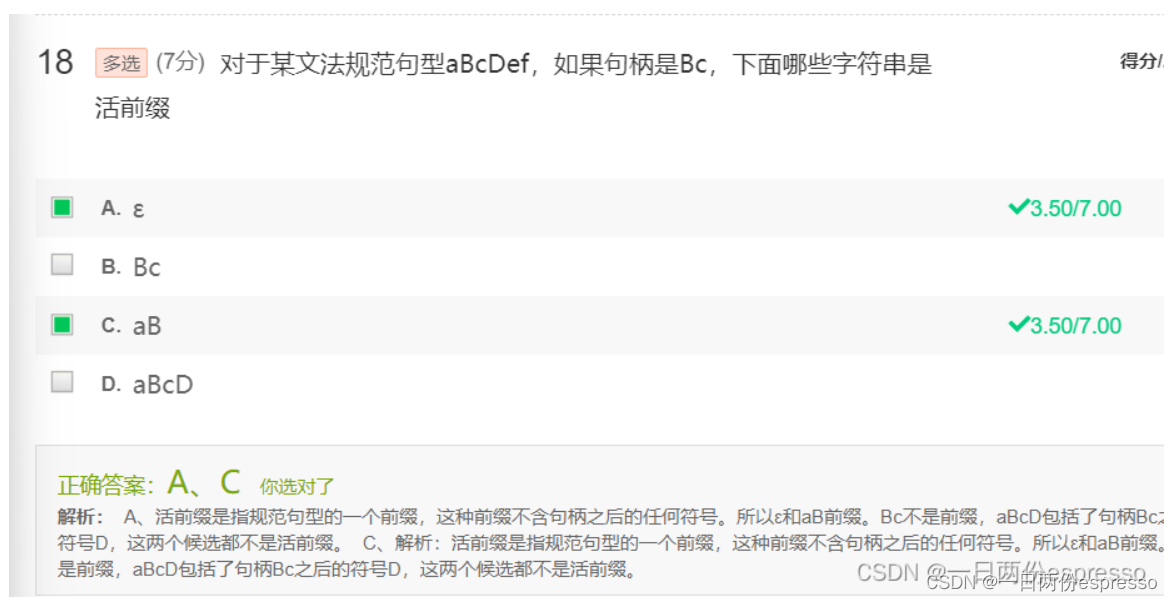
- 识别活前缀:
- 识别活前缀的DFA:
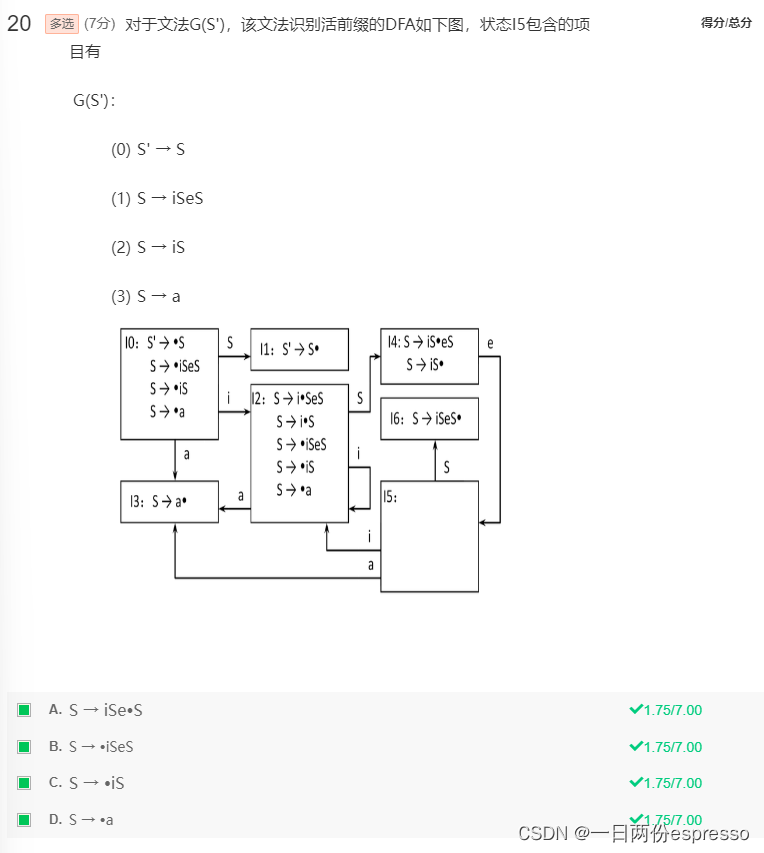
- 判断文法的LR项目:

点在最后,是归于/接受项目,点在终结符前是移进项目,点在非终结符前是待约项目。
第六章 属性文法和语法制导翻译
期末100%不会单独出与期中考试相同类型的大题。
因此这一章着重关注一下判断、选择、填空:
- 名字属于语义范畴,标识符属于语法范畴,名字使用标识符表示,但是二者有着本质的区别。
- 属性文法是对上下文无关文法的拓展。
属性文法提供了描述语言的语义的机制。
- 属性文法中的属性可以代表与文法符号相关类型、值、代码序列、符号表内容等。且语义规则不止可以进行数值型计算。
- 综合属性:自下而上传递信息;
继承属性:自上而下传递信息。 - 对出现在产生式右边的继承属性和产生式左边的综合属性都必须提供一个计算规则。而对于出现在产生式左边的符号的继承属性以及出现在产生式右边的符号的综合属性,均不由当前产生式给出其运算规则,而由其它产生式的属性规则计算或者有属性计算器参数提供。
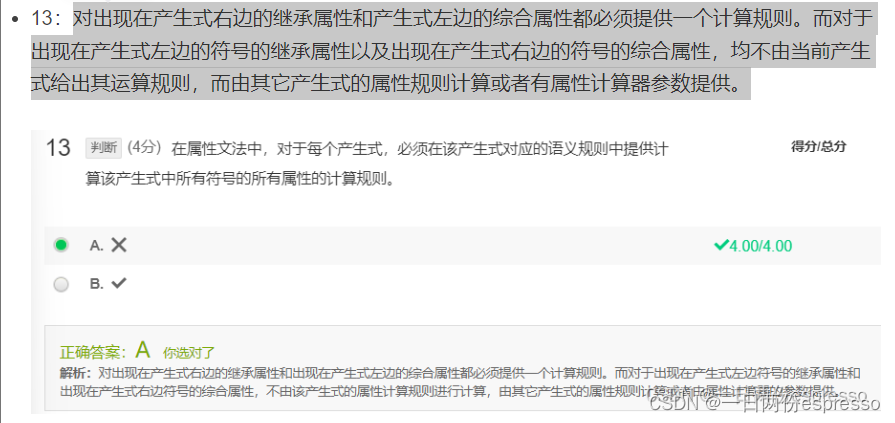
即:不是每个产生式都需要在该产生式语义规则中提供计算该产生式所有符号的计算规则。 - 只包含综合属性:S-属性文法。
L-属性文法包含了S-属性文法,即S-属性文法必然是L-属性文法,反之不一定。 - 语法制导是一种由源程序的语法结构驱动的翻译方法。 (记住语法制导与源程序的语法结构相关)
- 属性文法可以看作是关于语言翻译的规范说明,而翻译模式给出了语义规则进行计算的实现细节。
- 翻译模式的设计通常考虑和语法分析器结合。(语法制导就是由语法结构驱动的)
- 对于给定的属性文法,其翻译模式不唯一。
第七章 语义分析及中间代码的产生
大题看作业,小题看单元测试。作业题中甩掉了我认为考的可能性不大的题,如写后缀式、朴素的三地址代码转换、语法制导翻译过程。
作业题 7.5

作业题 7.6

作业题 7.7 极为重要,可以确定会出现在明天的试卷上,并且极有可能和数组元素的引用一起考察

作业题 7.8

作业题 7.9 考的可能性仍然不大

用2016年的卷子提前演练一下,明天大概率是这种大题

与第六章语法制导翻译结合


- 中间代码生成的依据是:语义规则,而非等价变换原则。
- 终结符只具有综合属性。
第八章 符号表 + 第九章 目标代码生成与代码优化
第八章只会考小题(判断、选择),第九章DAG进行局部优化一定会考大题。大题只看下作业题9.6即可,因为非常重要。
小题:
- 符号表的信息分为名字栏和信息栏两大栏。
- 符号表可以用来帮助做名字的作用域分析。
- 中间语言程序基本块划分后,未纳入基本块的可以删除。
- 编译程序对符号表的操作时机:
Ⅰ分析变量声明语句时
Ⅱ分析包括变量名的表达式时。
Ⅲ分析过程的形式参数列表时。
Ⅳ分析名字的作用域时。 - 目标代码生成需要计算各变量的引用次数,据此分配寄存器。
- 二叉树查找具有效率高、实现困难的特点。
- 对于整理与查找来说,杂凑(HASH)算具有效率最高,实现复杂,消耗额外存储空间的特点。
- 中间代码优化的目的是为了产生更高效的代码。由优化编译程序提供的对代码的各种变换必须遵循有效原则、合算原则,以及等价原则。
有效、合算、等价。
压轴题
我认为大概率是写语义子程序的问题,16年、20年的大题均与写语义子程序相关,这里挑三个例题看一下。
do…while

while…do 这个没有可参考的答案,不一定是正确的。

repeat…until

此外,再看下if-then和if-then-else的语义子程序。
if-then 和 if-then-else 的语义子程序

布尔表达式的语义子程序
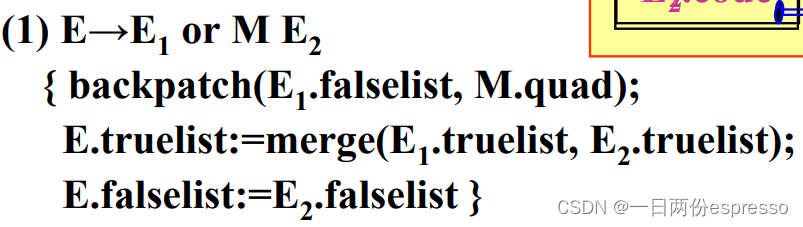




至此,2022年春季学期的编译原理期末考试复习全部结束,祝大家考试周顺利,高分通过。