一、fetch 的本地抓取策略
核心思想
能直接通过表目录获取到文件就不走MR
能不走MR就不走MR查询
执行原理
Hive 简单读取表对应的存储目录下的文件(如下图),然后输出到控制台。
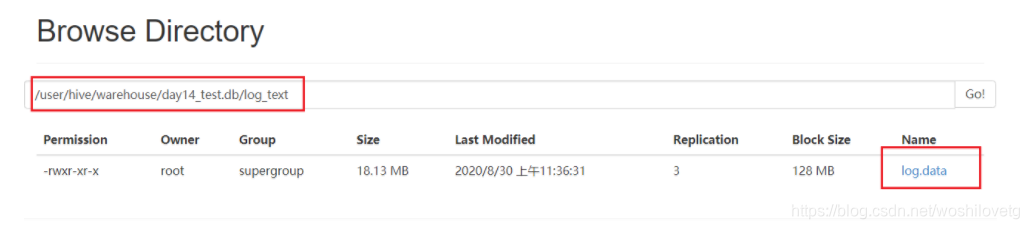
开启本地 fetch 抓取策略
set hive.fetch.task.conversion = more;
在hive-default.xml.template文件中hive.fetch.task.conversion默认more
取值:
minimal
more
none
说明
如果是none 意味着所有的SQL 查询都执行 MR
如果是minimal 意味着 select * from 表 或者 select 字段 from 表、查询分区表的时候,不会执行 MR , 在 hive 老版本 就是 )0.x 版本就是默认值
如果是 more 意味着 在执行 select * from 表 或者 select 字段 from 表、查询分区表、limit 查找、简单过滤查询等都不会执行 MR操作,这个是从 1.x 版本开始默认值。
二、hive的本地模式
核心思想
将 MR 的任务在本地运行,不要提交到 yarn 集群上。
原理
运行一些小数据的情况下,完全不需要上传到yarn集群上,进行分布式执行操作,只要将 MR 运行在 yarn集群上,将整个任务开启,资源分配,任务执行初始化的工作最起码要20s时间,才可以运行完成,小数据量的任务真正的执行时间,可能就那么几秒钟。
怎么开启本地的模式
set hive.exec.mode.local.auto=true; -- 开启本地MR
设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,默认为134217728,即128M
set hive.exec.mode.local.inputbytes.max=51234560 -- 48M
设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=10 --默认是4
建议
在测试环境中,一般开启本地模式
在生产环境中,开不开都行
以下皆是基于Hive2.x的版本
三、HDFS副本数
dfs.replication(HDFS)
文件副本数,通常设为3,不推荐修改。
如果测试环境只有二台虚拟机(2个datanode节点),此值要修改为2。

四、Yarn基础配置
4.1 NodeManager配置
4.1.1 CPU配置
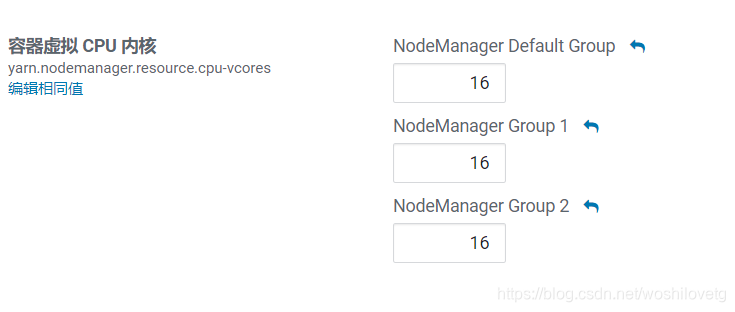
配置项:yarn.nodemanager.resource.cpu-vcores
表示该节点服务器上yarn可以使用的虚拟CPU个数,默认值是8,推荐将值配置与物理CPU线程数相同,如果节点CPU核心不足8个,要调小这个值,yarn不会智能的去检测物理核心数。

查看 CPU 线程数:
grep 'processor' /proc/cpuinfo | sort -u | wc -l |
4.1.2 内存配置
配置项:yarn.nodemanager.resource.memory-mb
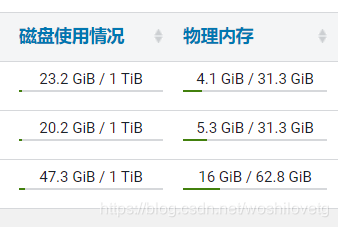
设置该nodemanager节点上可以为容器分配的总内存,默认为8G,如果节点内存资源不足8G,要减少这个值,yarn不会智能的去检测内存资源,一般按照服务器剩余可用内存资源进行配置。生产上根据经验一般要预留15-20%的内存,那么可用内存就是实际内存*0.8,比如实际内存是64G,那么64*0.8=51.2G,我们设置成50G就可以了(固定经验值)。

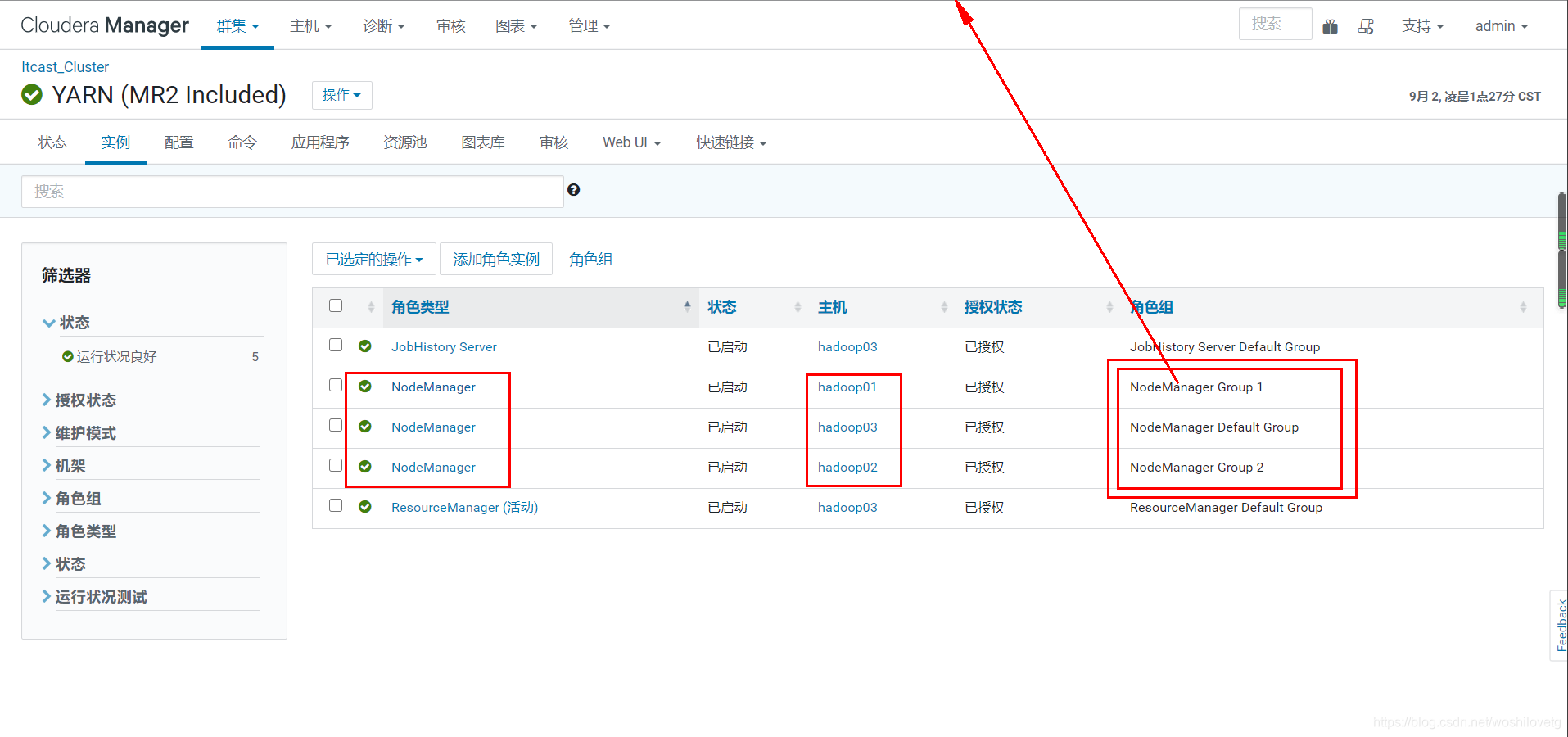
通过CM所有主机查看剩余内存:
可以看到第一台剩余内存为31.3-4.1=27.2G。
注意,要同时设置yarn.scheduler.maximum-allocation-mb为一样的值,yarn.app.mapreduce.am.command-opts(JVM内存)的值要同步修改为略小的值(-Xmx1024m)。
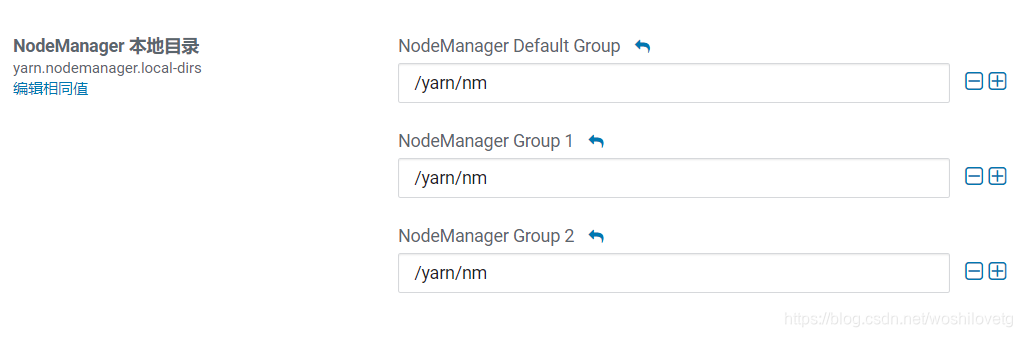
4.1.3 本地目录
yarn.nodemanager.local-dirs(Yarn)
NodeManager 存储中间数据文件的本地文件系统中的目录列表。
如果单台服务器上有多个磁盘挂载,则配置的值应当是分布在各个磁盘上目录,这样可以充分利用节点的IO读写能力。
4.2 mapReduce内存配置
当MR内存溢出时,可以根据服务器配置进行调整。
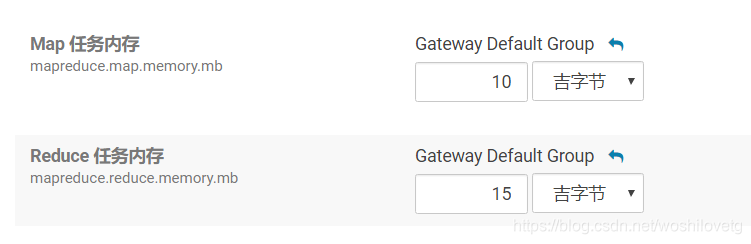
mapreduce.map.memory.mb
为作业的每个 Map 任务分配的物理内存量(MiB),默认为0,自动判断大小。
mapreduce.reduce.memory.mb
为作业的每个 Reduce 任务分配的物理内存量(MiB),默认为0,自动判断大小。
mapreduce.map.java.opts、mapreduce.reduce.java.opts
Map和Reduce的JVM配置选项。
注意:
mapreduce.map.java.opts一定要小于mapreduce.map.memory.mb;
mapreduce.reduce.java.opts一定要小于mapreduce.reduce.memory.mb,格式-Xmx4096m。
注意:
此部分所有配置均不能大于Yarn的NodeManager内存配置。

五、Hive基础配置
5.1 HiveServer2 的 Java 堆栈
Hiveserver2异常退出,导致连接失败的问题。
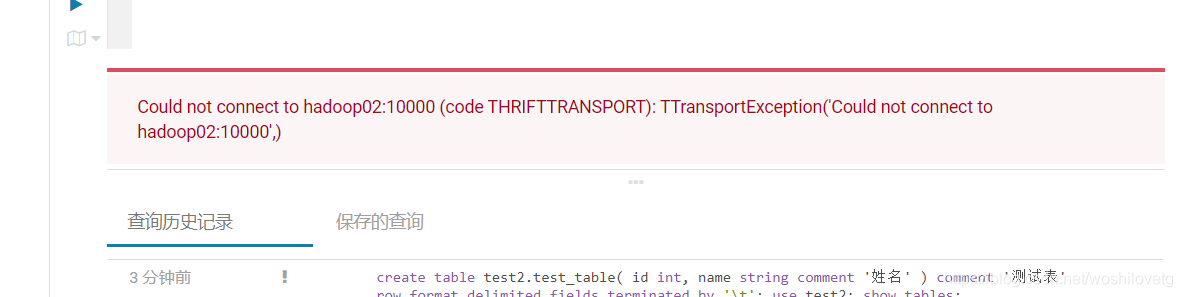
解决方法:修改HiveServer2 的 Java 堆栈大小。

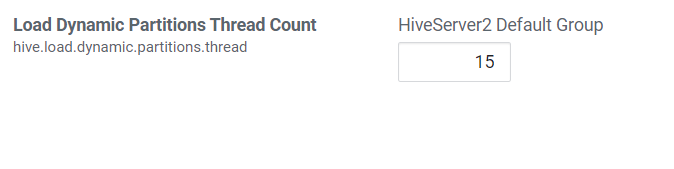
5.2 动态生成分区的线程数
hive.load.dynamic.partitions.thread
用于加载动态生成的分区的线程数。加载需要将文件重命名为它的最终位置,并更新关于新分区的一些元数据。默认值为15。
当有大量动态生成的分区时,增加这个值可以提高性能。根据服务器配置修改。
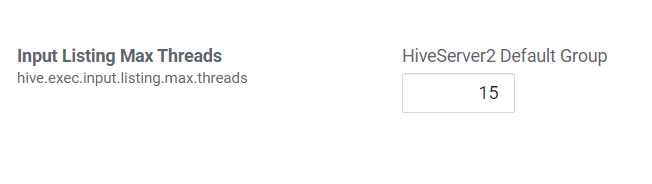
5.3 监听输入文件线程数
hive.exec.input.listing.max.threads
Hive用来监听输入文件的最大线程数。默认值:15。
当需要读取大量分区时,增加这个值可以提高性能。根据服务器配置进行调整。
六、压缩配置
6.1 Map输出压缩
除了创建表时指定保存数据时压缩,在查询分析过程中,Map的输出也可以进行压缩。由于map任务的输出需要写到磁盘并通过网络传输到reducer节点,所以通过使用LZO、LZ4或者Snappy这样的快速压缩方式,是可以获得性能提升的,因为需要传输的数据减少了。
MapReduce配置项:
mapreduce.map.output.compress
设置是否启动map输出压缩,默认为false。在需要减少网络传输的时候,可以设置为true。
mapreduce.map.output.compress.codec
设置map输出压缩编码解码器,默认为org.apache.hadoop.io.compress.DefaultCodec,推荐使用SnappyCodec:org.apache.hadoop.io.compress.SnappyCodec。
6.2 Reduce结果压缩
是否对任务输出结果压缩,默认值false。对传输数据进行压缩,既可以减少文件的存储空间,又可以加快数据在网络不同节点之间的传输速度。
配置项:
mapreduce.output.fileoutputformat.compress
是否启用 MapReduce 作业输出压缩。
mapreduce.output.fileoutputformat.compress.codec
指定要使用的压缩编码解码器,推荐SnappyCodec。
mapreduce.output.fileoutputformat.compress.type
指定MapReduce作业输出的压缩方式,默认值RECORD,可配置值有:NONE、RECORD、BLOCK。推荐使用BLOCK,即针对一组记录进行批量压缩,压缩效率更高。
6.3 Hive执行过程通用压缩设置
主要包括压缩/解码器设置和压缩方式设置:
mapreduce.output.fileoutputformat.compress.codec(Yarn)
map输出所用的压缩编码解码器,默认为org.apache.hadoop.io.compress.DefaultCodec;
推荐使用SnappyCodec:org.apache.hadoop.io.compress.SnappyCodec。
mapreduce.output.fileoutputformat.compress.type
输出产生任务数据的压缩方式,默认值RECORD,可配置值有:NONE、RECORD、BLOCK。推荐使用BLOCK,即针对一组记录进行批量压缩,压缩效率更高。


6.4 Hive多个Map-Reduce中间数据压缩
控制 Hive 在多个map-reduce作业之间生成的中间文件是否被压缩。压缩编解码器和其他选项由上面Hive通用压缩mapreduce.output.fileoutputformat.compress.*确定。
set hive.exec.compress.intermediate=true; |
6.5 Hive最终结果压缩
控制是否压缩查询的最终输出(到 local/hdfs 文件或 Hive table)。压缩编解码器和其他选项由 上面Hive通用压缩mapreduce.output.fileoutputformat.compress.*确定。
set hive.exec.compress.output=true; |
面试:join如何优化,数据倾斜
七、join优化
7.1 Map Join
MapJoin顾名思义,就是在Map阶段进行表之间的连接。而不需要进入到Reduce阶段才进行连接。这样就节省了在Shuffle阶段时要进行的大量数据传输。从而起到了优化作业的作用。
要使MapJoin能够顺利进行,那就必须满足这样的条件:除了一份表的数据分布在不同的Map中外,其他连接的表的数据必须在每个Map中有完整的拷贝。
所以并不是所有的场景都适合用MapJoin。它通常会用在如下的一些情景:在二个要连接的表中,有一个很大,有一个很小,这个小表可以存放在内存中而不影响性能。
这样我们就把小表文件复制到每一个Map任务的本地,再让Map把文件读到内存中待用。
在Hive v0.7之前,需要使用hint提示 /*+ mapjoin(table) */才会执行MapJoin。Hive v0.7之后的版本已经不需要给出MapJoin的指示就进行优化。现在可以通过如下配置参数来进行控制:
set hive.auto.convert.join=true;
Hive还提供另外一个参数--表文件的大小作为开启和关闭MapJoin的阈值:
--旧版本为hive.mapjoin.smalltable.filesize set hive.auto.convert.join.noconditionaltask.size=512000000 #注意,如果hive.auto.convert.join是关闭的,则本参数不起作用。否则,如果参与连接的N个表(或分区)中的N-1个 的总大小小于512MB,则直接将连接转为Map连接。默认值为20MB。
MapJoin的使用场景:
1. 关联操作中有一张表非常小
2. 不等值的链接操作
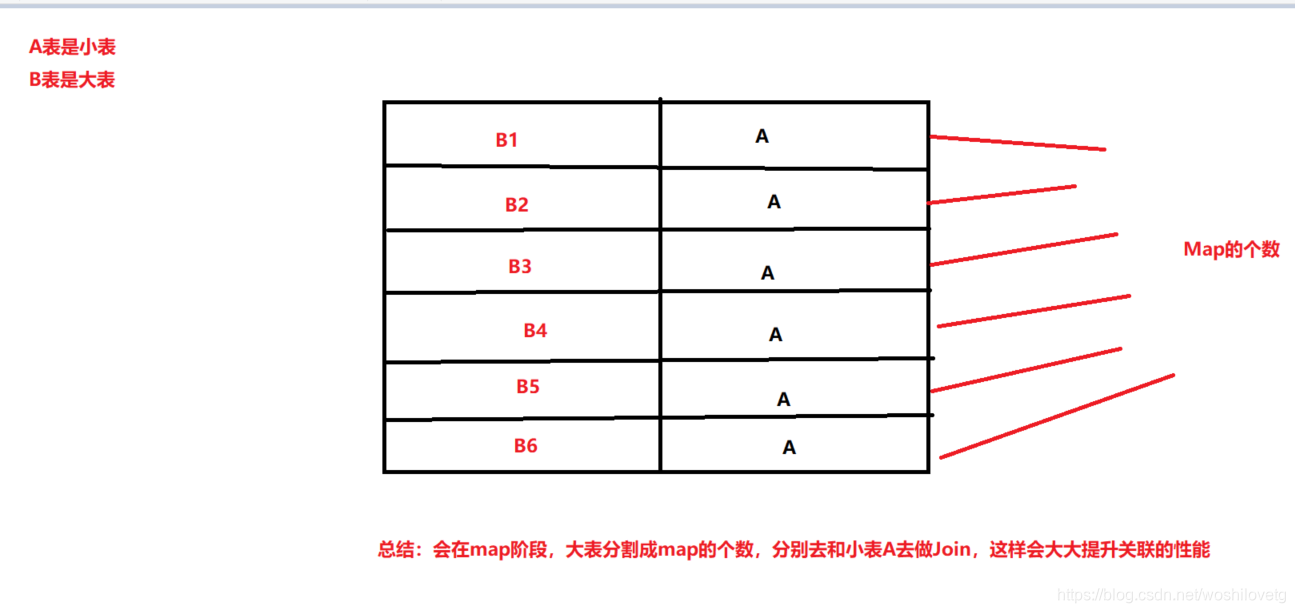
7.1.1 大小表关联
select f.a,f.b from A t join B f on ( f.a=t.a and f.ftime=20110802) |
该语句中B表有30亿行记录,A表只有100行记录,而且B表中数据倾斜特别严重,有一个key上有15亿行记录,在运行过程中特别的慢,而且在reduece的过程中遇到执行时间过长或者内存不够的问题。
MAPJION会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配,由于在map时进行了join操作,省去了reduce运行的效率会高很多。
这样就不会由于数据倾斜导致某个reduce上落数据太多而失败。于是原来的sql可以通过使用hint的方式指定join时使用mapjoin。
select /*+ mapjoin(A)*/ f.a,f.b from A t join B f on ( f.a=t.a and f.ftime=20110802) |
在实际使用中,只要根据业务调整小表的阈值即可,hive会自动帮我们完成mapjoin,提高执行的效率。
7.1.2 不等连接
mapjoin还有一个很大的好处是能够进行不等连接的join操作,如果将不等条件写在where中,
那么mapreduce过程中会进行笛卡尔积,运行效率特别低,如果使用mapjoin操作,在map的过程中就完成了不等值的join操作,效率会高很多。
select A.a ,A.b from A join B where A.a>B.a |
7.2 Bucket-MapJoin
两个表join的时候,小表不足以放到内存中,但是又想用map join这个时候就要用到bucket Map join。其方法是两个join表在join key上都做hash bucket,并且大表的bucket数设置为小表的倍数。这样数据就会按照key join,做hash bucket。小表依然复制到所有节点,Map join的时候,小表的每一组bucket加载成hashtable,与对应的一个大表bucket做局部join,这样每次只需要加载部分hashtable就可以了。
条件
1) set hive.optimize.bucketmapjoin = true;
2) 一个表的bucket数是另一个表bucket数的整数倍
3) bucket列 == join列
4) 必须是应用在map join的场景中
注意:如果表不是bucket的,则只是做普通join。
7.3 SMB Join
全称Sort Merge Bucket Join。
作用
大表对小表应该使用MapJoin来进行优化,但是如果是大表对大表,如果进行shuffle,那就非常可怕,第一个慢不用说,第二个容易出异常,此时就可以使用SMB Join来提高性能。SMB Join基于bucket-mapjoin的有序bucket,可实现在map端完成join操作,可以有效地减少或避免shuffle的数据量。SMB join的条件和Map join类似但又不同。
条件
bucket mapjoin | SMB join |
set hive.optimize.bucketmapjoin = true; | set hive.optimize.bucketmapjoin = true; set hive.auto.convert.sortmerge.join=true; set hive.optimize.bucketmapjoin.sortedmerge = true; set hive.auto.convert.sortmerge.join.noconditionaltask=true; |
一个表的bucket数是另一个表bucket数的整数倍 | 小表的bucket数=大表bucket数 |
bucket列 == join列 | Bucket 列 == Join 列 == sort 列 |
必须是应用在map join的场景中 | 必须是应用在bucket mapjoin 的场景中 |
确保分同列排序
hive并不检查两个join的表是否已经做好bucket且sorted,需要用户自己去保证join的表数据sorted,否则可能数据不正确。
有两个办法:
1)hive.enforce.sorting 设置为 true。开启强制排序时,插数据到表中会进行强制排序,默认false。
2)插入数据时通过在sql中用distributed c1 sort by c1 或者 cluster by c1
另外,表创建时必须是CLUSTERED且SORTED,如下:
create table test_smb_2(mid string,age_id string) CLUSTERED BY(mid) SORTED BY(mid) INTO 500 BUCKETS; |
综上,涉及到分桶表操作的齐全配置为:
--写入数据强制分桶 set hive.enforce.bucketing=true; --写入数据强制排序 set hive.enforce.sorting=true; --开启bucketmapjoin set hive.optimize.bucketmapjoin = true; --开启SMB Join set hive.auto.convert.sortmerge.join=true; set hive.auto.convert.sortmerge.join.noconditionaltask=true; |
开启MapJoin的配置(hive.auto.convert.join和hive.auto.convert.join.noconditionaltask.size),还有限制对桶表进行load操作(hive.strict.checks.bucketing)可以直接设置在hive的配置项中,无需在sql中声明。
自动尝试SMB联接(hive.optimize.bucketmapjoin.sortedmerge)也可以在设置中进行提前配置。