目录
五、使用MindStudio对RotatE模型训练、评估和导出
Bilibili视频教程链接:【经验分享】使用MindStudio进行RotatE模型开发_哔哩哔哩_bilibili
一、MindSpore深度学习框架环境与配置介绍
1、MindSpore深度学习框架介绍
MindSpore是一个全场景深度学习框架,旨在实现易开发、高效执行、全场景覆盖三大目标,其中易开发表现为API友好、调试难度低,高效执行包括计算效率、数据预处理效率和分布式训练效率,全场景则指框架同时支持云、边缘以及端侧场景。
MindSpore总体架构如下图所示,其中:
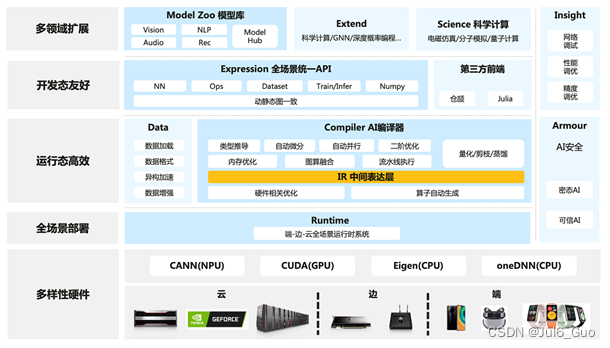
ModelZoo(网络样例):ModelZoo提供可用的深度学习算法网络,也欢迎更多开发者贡献新的网络。
MindSpore Extend(扩展层):MindSpore的扩展包,支持拓展新领域场景,如GNN/深度概率编程/强化学习等,期待更多开发者来一起贡献和构建。
MindScience(科学计算):MindScience是基于MindSpore融合架构打造的科学计算行业套件,包含了业界领先的数据集、基础模型、预置高精度模型和前后处理工具,加速了科学行业应用开发。
MindExpression(表达层):基于Python的前端表达与编程接口。同时未来计划陆续提供C/C++、华为自研编程语言前端-仓颉(目前还处于预研阶段)等第三方前端的对接工作,引入更多的第三方生态。
MindData(数据处理层):提供高效的数据处理、常用数据集加载等功能和编程接口,支持用户灵活的定义处理注册和pipeline并行优化。
MindCompiler(编译优化层):图层的核心编译器,主要基于端云统一的MindIR实现三大功能,包括硬件无关的优化(类型推导、自动微分、表达式化简等)、硬件相关优化(自动并行、内存优化、图算融合、流水线执行等)、部署推理相关的优化(量化、剪枝等)。
MindRT(全场景运行时):MindSpore的运行时系统,包含云侧主机侧运行时系统、端侧以及更小IoT的轻量化运行时系统。
MindInsight(可视化调试调优工具):提供MindSpore的可视化调试调优等工具,支持用户对训练网络的调试调优。
MindArmour(安全增强包):面向企业级运用时,安全与隐私保护相关增强功能,如对抗鲁棒性、模型安全测试、差分隐私训练、隐私泄露风险评估、数据漂移检测等技术。
MindSpore源于全产业的最佳实践,向数据科学家和算法工程师提供了统一的模型训练、推理和导出等接口,支持端、边、云等不同场景下的灵活部署,推动深度学习和科学计算等领域繁荣发展。
MindSpore提供了Python编程范式,用户使用Python原生控制逻辑即可构建复杂的神经网络模型,AI编程变得简单。
目前主流的深度学习框架的执行模式有两种,分别为静态图模式和动态图模式。静态图模式拥有较高的训练性能,但难以调试。动态图模式相较于静态图模式虽然易于调试,但难以高效执行。
MindSpore提供了动态图和静态图统一的编码方式,大大增加了静态图和动态图的可兼容性,用户无需开发多套代码,仅变更一行代码便可切换动态图/静态图模式,例如设置 context.set_context(mode=context.PYNATIVE_MODE)
切换成动态图模式,设置context.set_context(mode=context.GRAPH_MODE)即可切换成静态图模式,用户可拥有更轻松的开发调试及性能体验。
神经网络模型通常基于梯度下降算法进行训练,但手动求导过程复杂,结果容易出错。MindSpore的基于源码转换(Source Code Transformation,SCT)的自动微分(Automatic Differentiation)机制采用函数式可微分编程架构,在接口层提供Python编程接口,包括控制流的表达。用户可聚焦于模型算法的数学原生表达,无需手动进行求导。
随着神经网络模型和数据集的规模不断增加,分布式并行训练成为了神经网络训练的常见做法,但分布式并行训练的策略选择和编写十分复杂,这严重制约着深度学习模型的训练效率,阻碍深度学习的发展。MindSpore统一了单机和分布式训练的编码方式,开发者无需编写复杂的分布式策略,在单机代码中添加少量代码即可实现分布式训练,例如设置
context.set_auto_parallel_context(parallel_mode=ParallelMode.AUTO_PARALLEL)
便可自动建立代价模型,为用户选择一种较优的并行模式,提高神经网络训练效率,大大降低了AI开发门槛,使用户能够快速实现模型思路。
2、MindSpore环境搭建与配置
选择适合自己的环境条件后,获取命令并按照指南进行安装,或使用云平台创建和部署模型
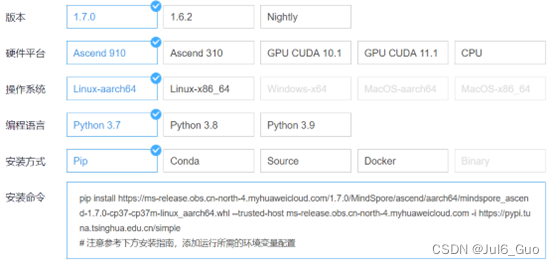
安装细节参见链接:https://www.mindspore.cn/install
验证是否成功安装
python -c “import mindspore;mindspore.run_check()”
如果输出:
MindSpore version: 版本号
The result of multiplication calculation is correct, MindSpore has been installed successfully!
说明MindSpore安装成功了。
二、MindStudio开发平台简介与安装
1、MindStudio开发平台简介
Mind Studio是一套基于华为昇腾AI处理器开发的AI全栈开发平台,包括基于芯片的算子开发、以及自定义算子开发,同时还包括网络层的网络移植、优化和分析,另外在业务引擎层提供了一套可视化的AI引擎拖拽式编程服务,极大的降低了AI引擎的开发门槛,全平台通过IDE的方式向开发者提供以下4项服务功能。
针对安装与部署,MindStudio提供多种部署方式,支持多种主流操作系统,为开发者提供最大便利。
针对算子开发,MindStudio提供包含UT测试、ST测试、TIK算子调试等的全套算子开发流程。支持TensorFlow、PyTorch、MindSpore等多种主流框架的TBE和AI CPU自定义算子开发。
针对网络模型的开发,MindStudio支持TensorFlow、Pytorch、MindSpore框架的模型训练,支持多种主流框架的模型转换。集成了训练可视化、脚本转换、模型转换、精度比对等工具,提升了网络模型移植、分析和优化的效率。
针对应用开发,MindStudio集成了Profiling性能调优、编译器、MindX SDK的应用开发、可视化pipeline业务流编排等工具,为开发者提供了图形化的集成开发环境,通过MindStudio能够进行工程管理、编译、调试、性能分析等全流程开发,能够很大程度提高开发效率。
MindStudio功能框架如下图所示,目前含有的工具链包括:模型转换工具、模型训练工具、自定义算子开发工具、应用开发工具、工程管理工具、编译工具、流程编排工具、精度比对工具、日志管理工具、性能分析工具、设备管理工具等多种工具。
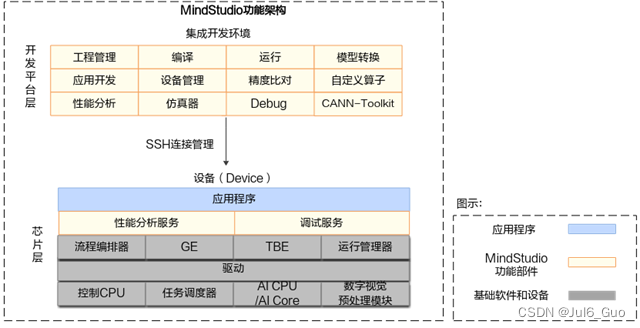
MindStudio工具中的主要几个功能特性如下:
- 工程管理:为开发人员提供创建工程、打开工程、关闭工程、删除工程、新增工程文件目录和属性设置等功能。
- SSH管理:为开发人员提供新增SSH连接、删除SSH连接、修改SSH连接、加密SSH密码和修改SSH密码保存方式等功能。
- 应用开发:针对业务流程开发人员,MindStudio工具提供基于AscendCL(Ascend Computing Language)和集成MindX SDK的应用开发编程方式,编程后的编译、运行、结果显示等一站式服务让流程开发更加智能化,可以让开发者快速上手。
- 自定义算子开发:提供了基于TBE和AI CPU的算子编程开发的集成开发环境,让不同平台下的算子移植更加便捷,适配昇腾AI处理器的速度更快。
- 离线模型转换:训练好的第三方网络模型可以直接通过离线模型工具导入并转换成离线模型,并可一键式自动生成模型接口,方便开发者基于模型接口进行编程,同时也提供了离线模型的可视化功能。
- 日志管理:MindStudio为昇腾AI处理器提供了覆盖全系统的日志收集与日志分析解决方案,提升运行时算法问题的定位效率。提供了统一形式的跨平台日志可视化分析能力及运行时诊断能力,提升日志分析系统的易用性。
- 性能分析:MindStudio以图形界面呈现方式,实现针对主机和设备上多节点、多模块异构体系的高效、易用、可灵活扩展的系统化性能分析,以及针对昇腾AI处理器的性能和功耗的同步分析,满足算法优化对系统性能分析的需求。
- 设备管理:MindStudio提供设备管理工具,实现对连接到主机上的设备的管理功能。
- 精度比对:可以用来比对自有模型算子的运算结果与Caffe、TensorFlow、ONNX标准算子的运算结果,以便用来确认神经网络运算误差发生的原因。
- 开发工具包的安装与管理:为开发者提供基于昇腾AI处理器的相关算法开发套件包Ascend-cann-toolkit,旨在帮助开发者进行快速、高效的人工智能算法开发。开发者可以将开发套件包安装到MindStudio上,使用MindStudio进行快速开发。Ascend-cann-toolkit包含了基于昇腾AI处理器开发依赖的头文件和库文件、编译工具链、调优工具等。
将MindStudio安装在Windows服务器上时,Windows服务器为本地环境,Linux服务器为远端环境。本地环境要求:Windows 10 x86_64操作系统。
2、MindStudio安装
第一步:安装python
1、MindStudio目前支持Python版本为3.7.0 ~3.9.7,下面以安装Python3.7.5依赖包为例。将Python3.7.5安装到本地。
其他安装细节请参考链接:
https://www.hiascend.com/document/detail/zh/mindstudio/304/instg/atlasms_02_0022.html
2、打开系统命令行,输入python -V命令确认python版本是否为3.7.5。安装Python3相关依赖。
pip install xlrd==1.2.0
pip install absl-py
pip install numpy
如若返回如下信息,则表示安装成功。
Successfully installed xlrd-1.2.0
Successfully installed absl-py-0.12.0 six-1.15.0
Successfully installed numpy-1.20.1
第二步:安装MinGW
1、请用户到下载最新的MinGW安装包,根据系统选择对应版本,例如windows64位选择x86_64-posix-seh。安装细节参见链接:
https://www.hiascend.com/document/detail/zh/mindstudio/304/instg/atlasms_02_0022.html
2、打开系统命令行,输入gcc -v命令。当界面提示“gcc version x.x.x (x86_64-posix-sjlj-rev0, Built by MinGW-W64 project)”信息时,表示安装成功。若未提示该信息,请尝试重启计算机。
第三步:安装cMake
CMake是个一个开源的跨平台自动化建构系统,用来管理软件建置的程序,并不依赖于某特定编译器,并可支持多层目录、多个应用程序与多个库。
1、获取CMake,推荐安装的版本为3.16.5-win64-x64。安装细节请参考链接:
https://www.hiascend.com/document/detail/zh/mindstudio/304/instg/atlasms_02_0022.html
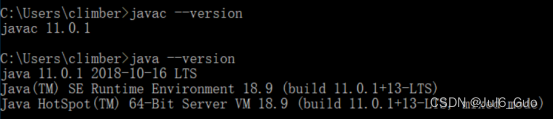
第四步:安装jdk11
1、请注意mindstudio不支持jdk8,请安装jdk11
安装细节参考链接:
https://gitee.com/ascend/docs-openmind/blob/master/guide/mindstudio/cases/tutorials/Windows安装MindStudio.md#安装java依赖
在cmd中输入javac –-version和java –version,得到如下输出,代表安装完成。
第五步:安装mindstudio
1、软件安装前,请获取所需软件包和对应的数字签名文件。
(1) MindStudio_{version}_win.zip,MindStudio免安装压缩包,含有GUI的集成开发环境。获取链接:https://www.hiascend.com/software/mindstudio/download
(2)MindStudio_{version}_win.exe,MindStudio安装包,含有GUI的集成开发环境。
获取链接:https://www.hiascend.com/software/mindstudio/download
2、为了防止软件包在传递过程或存储期间被恶意篡改,下载软件包时需下载对应的数字签名文件用于完整性验证。
3、安装MindStudio--两种方式
(1)以免安装压缩包形式,直接解压到相应文件目录即可
(2)下载exe文件以及对应的数字签名文件
安装参考链接:
https://www.hiascend.com/document/detail/zh/mindstudio/304/instg/atlasms_02_0023.html
三、训练工程创建及其相关配置
1、启动MindStudio
2、本文以RotatE模型为例,介绍使用MindStudio进行MindSpore训练脚本开发流程。下载RotatE项目代码,项目地址
https://gitee.com/mindspore/models/tree/master/research/nlp/rotate
3、点击Open图标
4、选择项目所在位置,添加rotate项目,点击OK
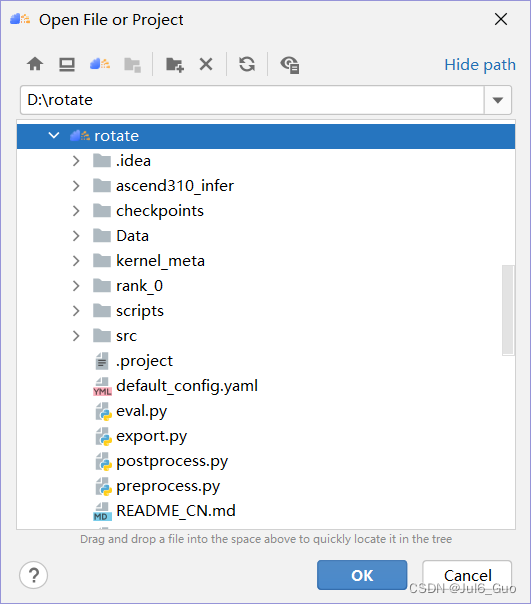
5、项目结构如图所示
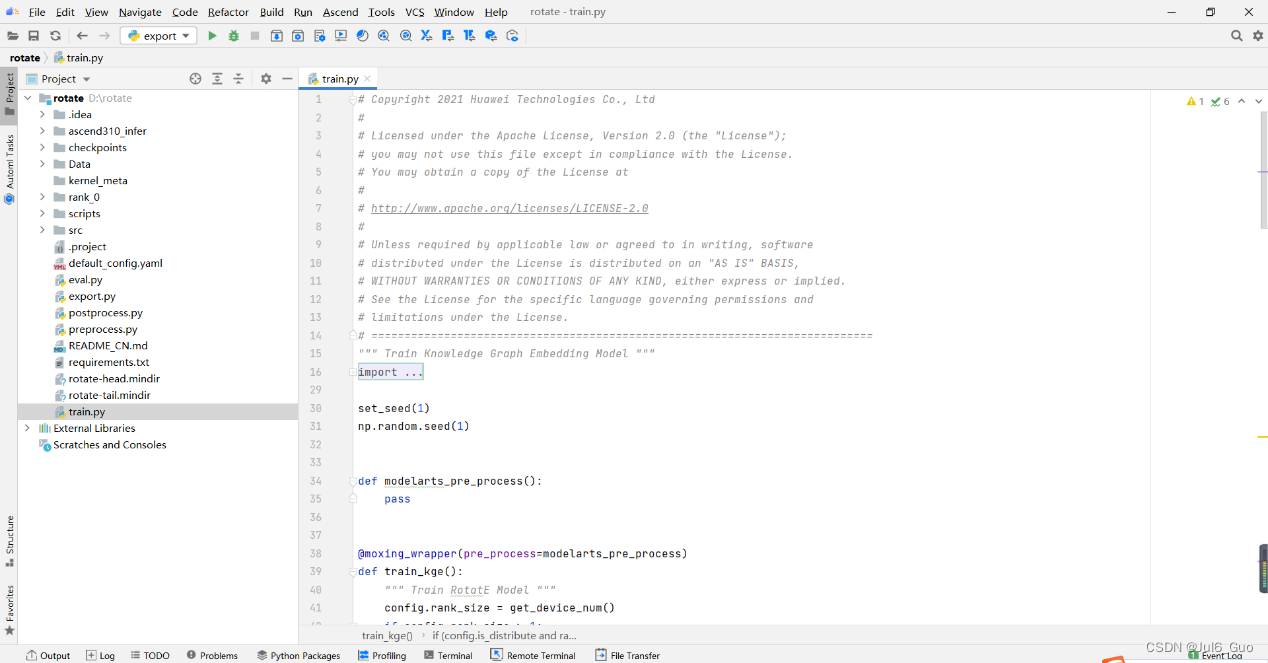
6、代码目录结构如图所示

7、开始项目
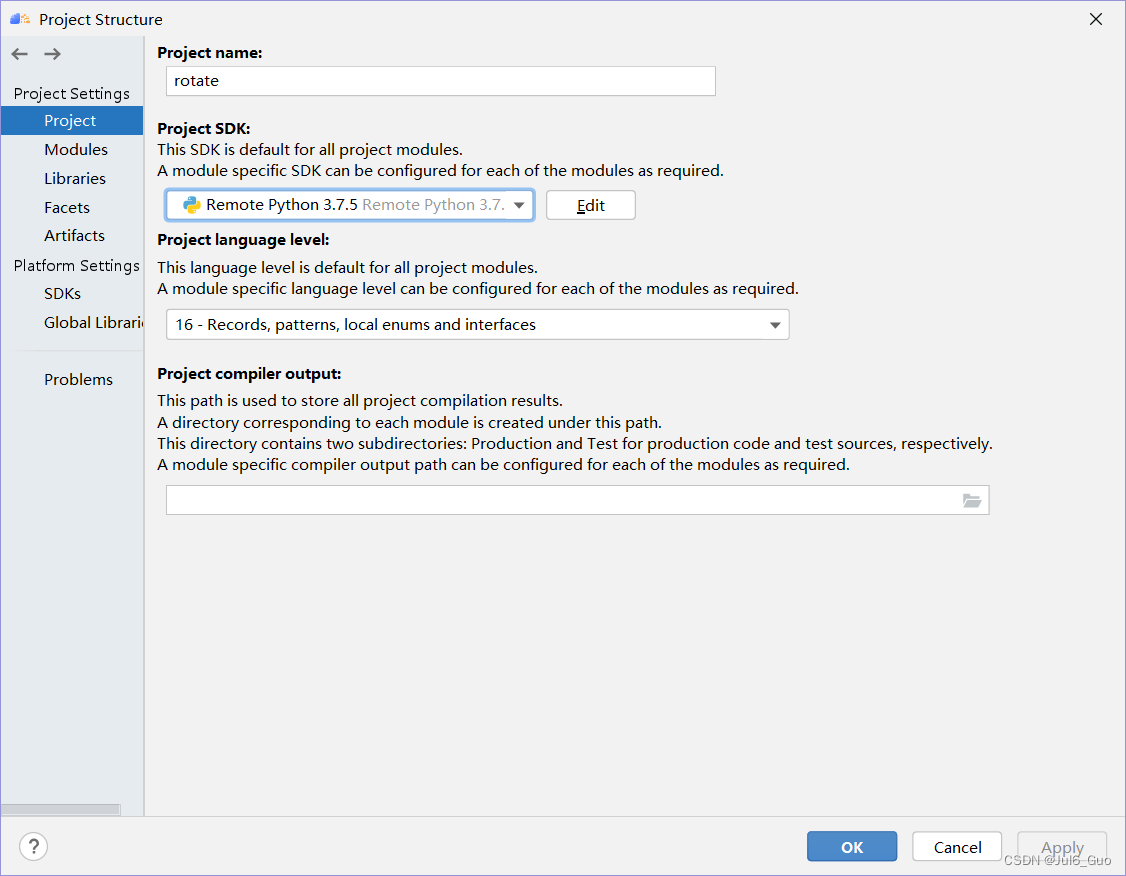
①点击File->Projects Structure
②点击Add Python SDK
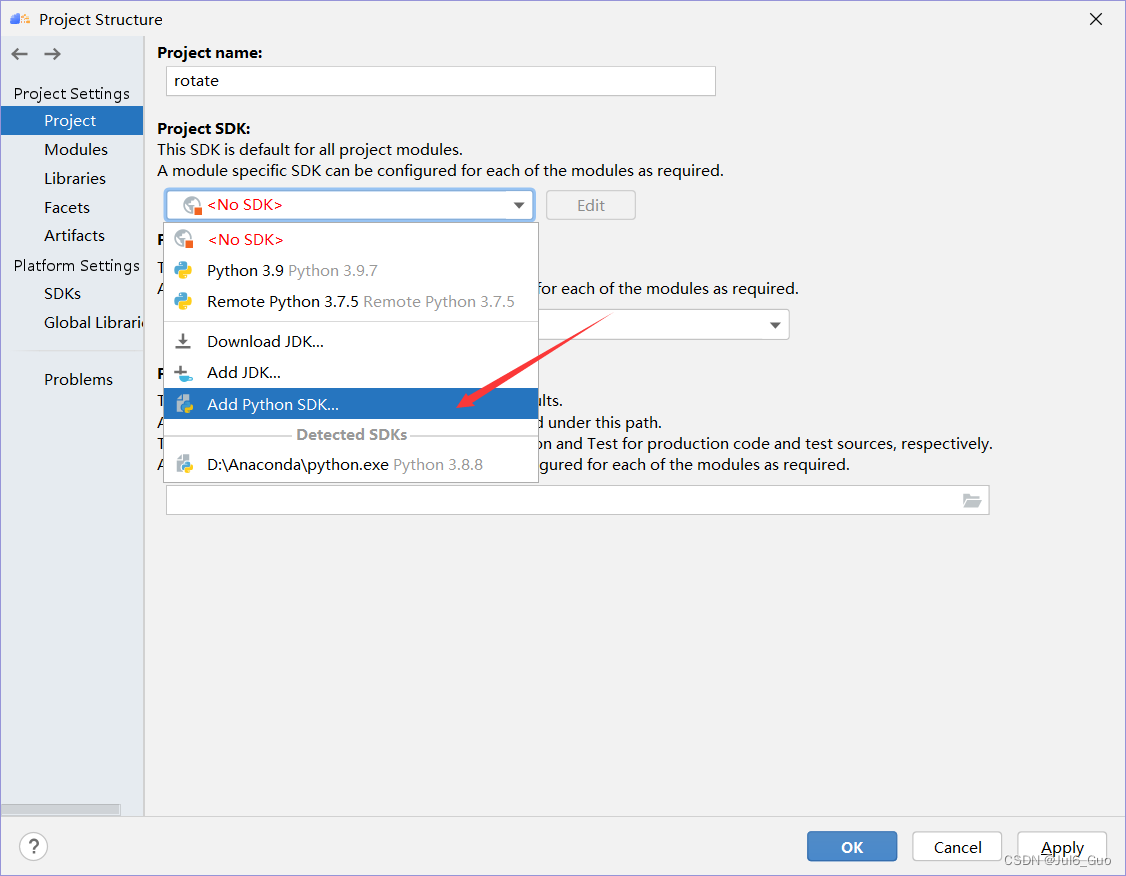
③选择SSH Interpreter,点击Deploy后的按钮
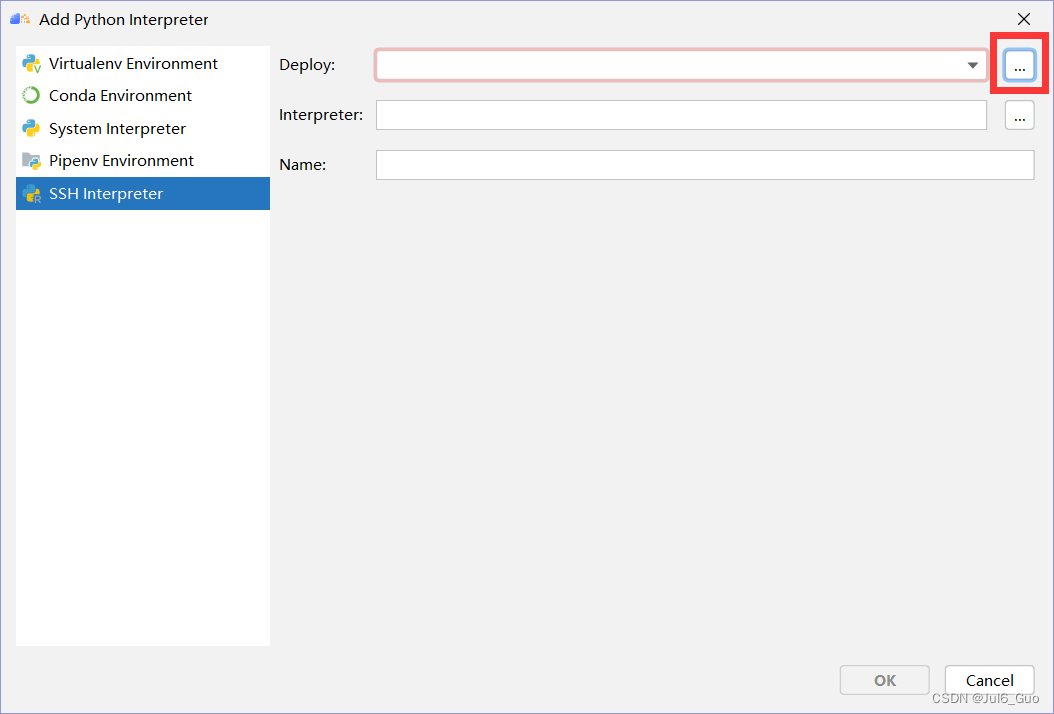
④点击左上角+号,输入服务器IP地址,点击OK
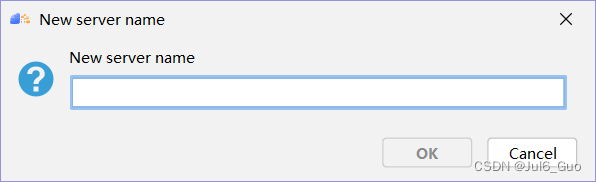
⑤Python解释器自动选为服务器远程解释器,点击OK
⑥在主界面点击File->settings->tools->Deployment,配置映射。点击左上角加号,输入连接名称。点击OK。
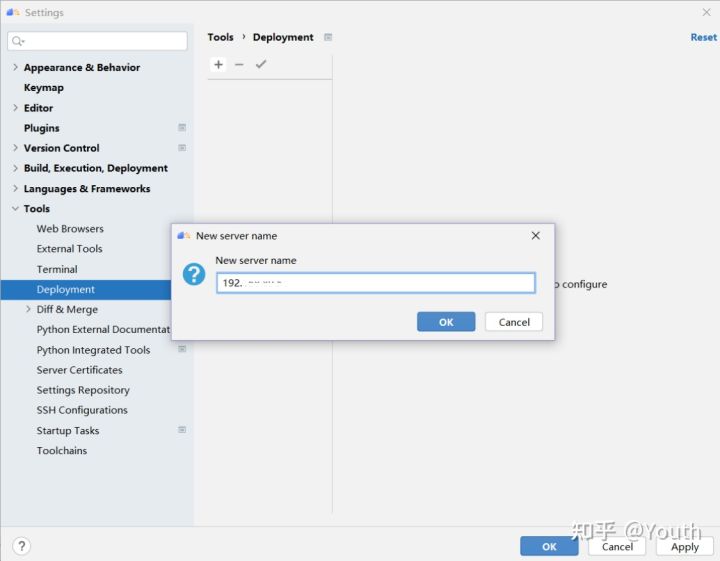
connection选项是基本的连接配置,类型一般选用SFTP,点击右侧按钮,输入服务器ip地址和端口号,然后可以点击Test Connection按钮测试连接是否通畅。
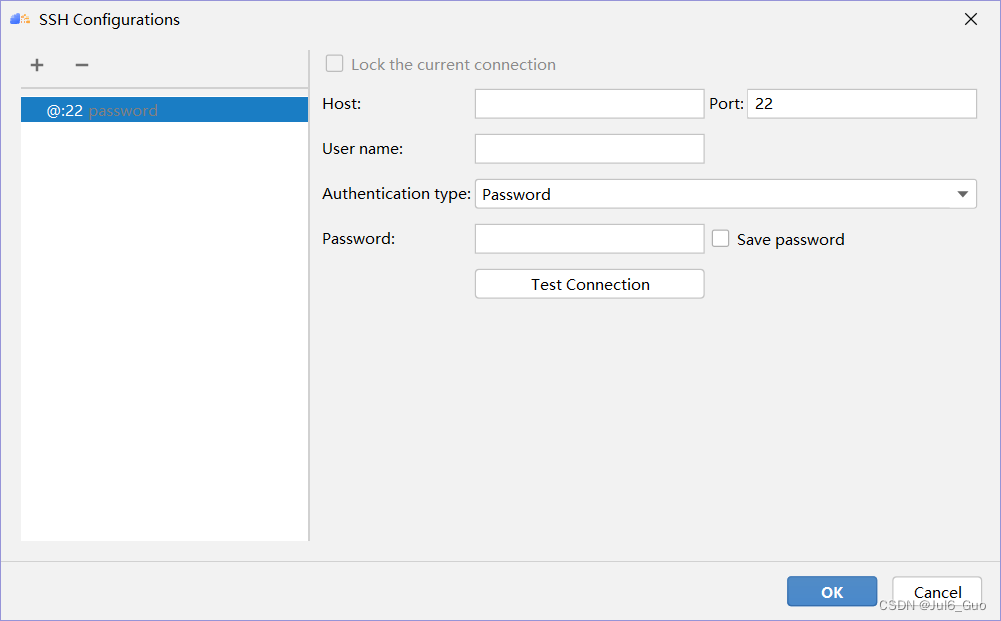
下拉选择刚才配置好的ssh连接
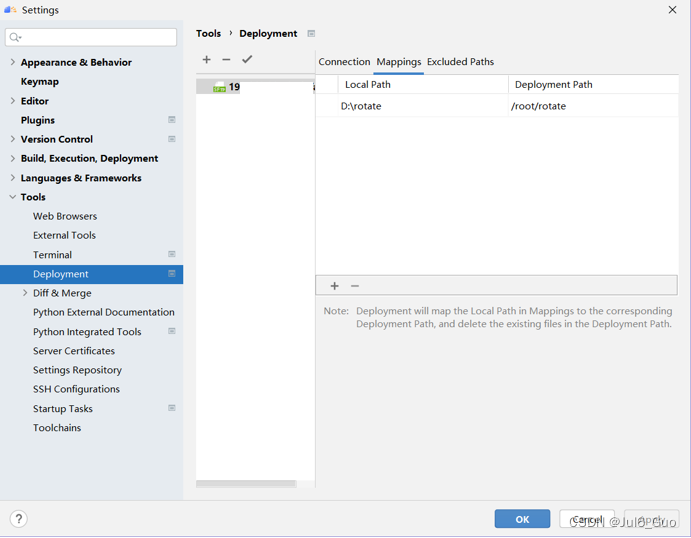
接下来点击Mappings配置映射关系。Local Path要求的是填入本地的项目名称路径,Deployment Path的是部署到服务器上的项目路径。
 点击OK
点击OK
⑦当本地文件进行修改需要上传到服务器时,点击项目名称rotate,再选择Tools->Deployment->Upload to上传项目。同理,Download项目可以下载服务器文件到本地。勾选Automatic Upload,可以在每次本地文件保存后,自动同步项目到服务器。至此,本地项目连接到远程服务器的步骤完成。
8、点击工具栏Ascend,将项目转化为昇腾项目,如图所示:
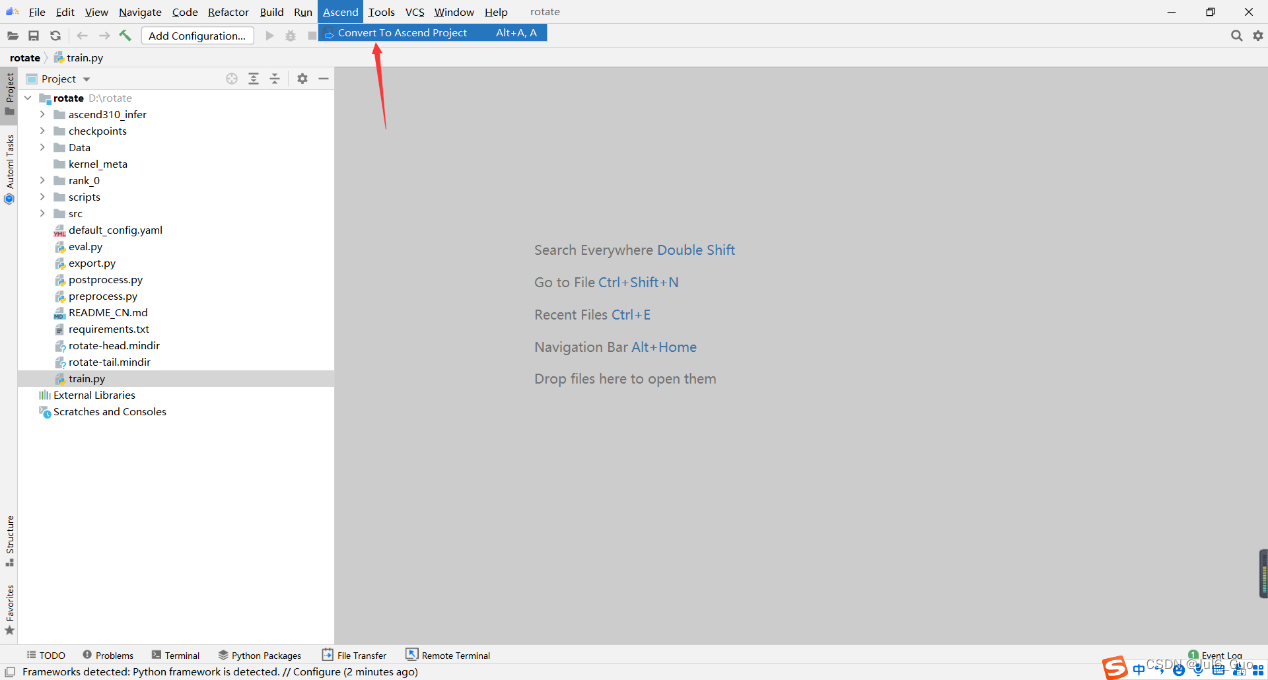
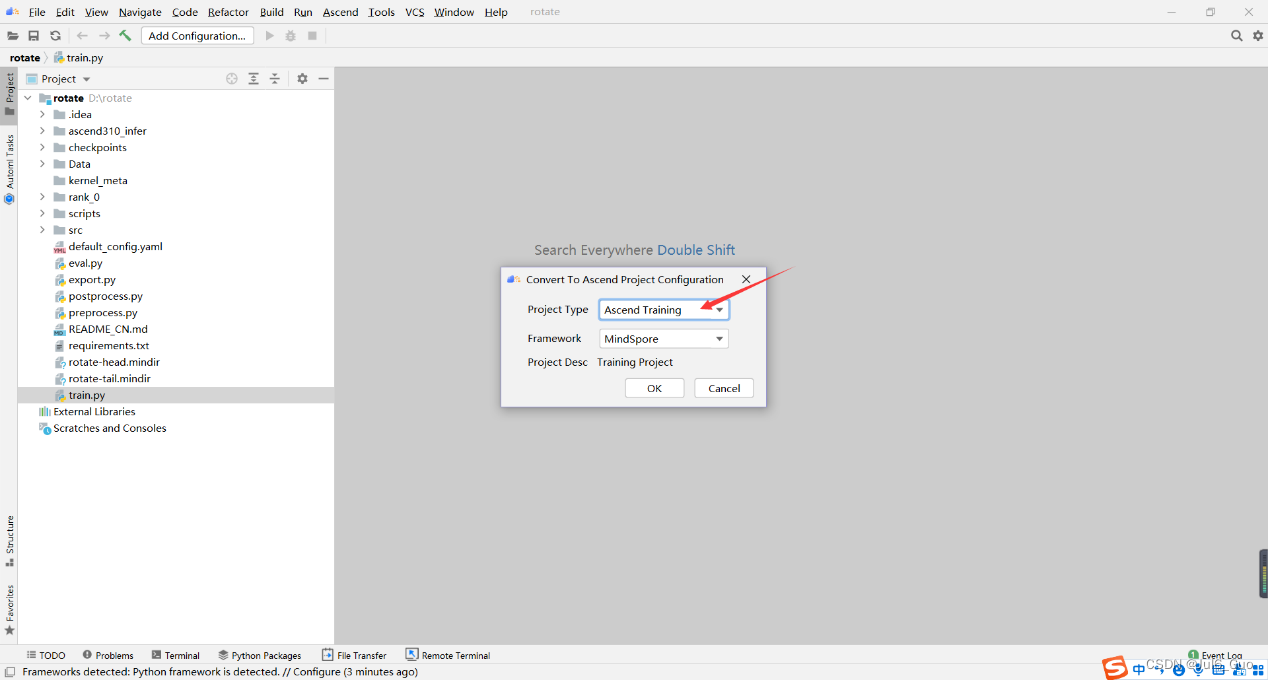
然后按照如下进行配置,点击OK
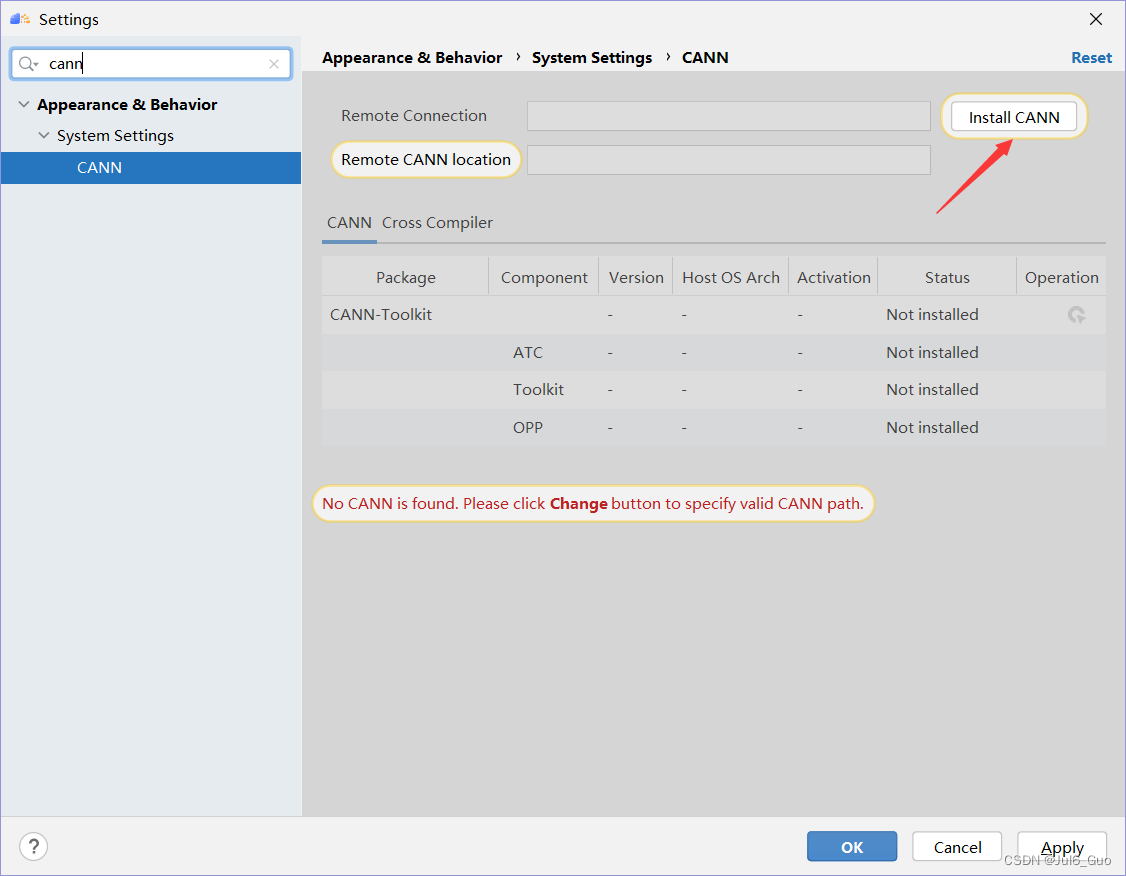
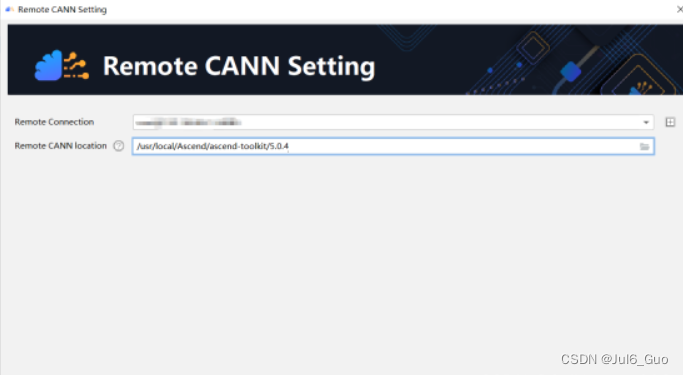
若提示没有CANN,在File->Setting下搜索CANN,点击Install配置,等待同步完成
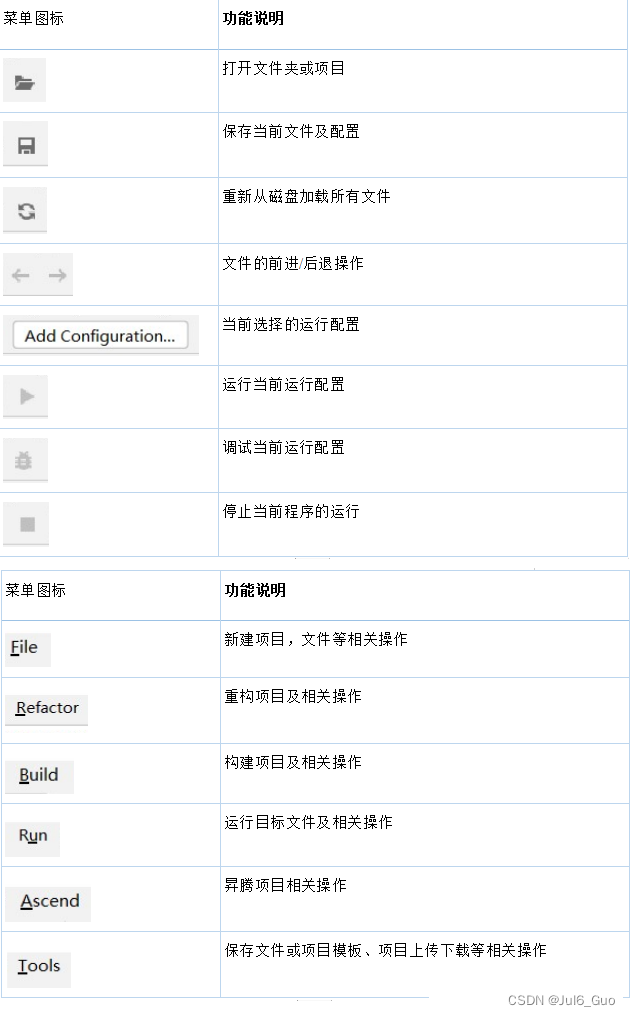
9、相关菜单介绍:

四、Rotate模型介绍
本部分简要介绍mindspore模型开发的要点,详细开发教程与API可参考mindspore官网:https://www.mindspore.cn/,也可以在昇腾论坛进行讨论和交流:
https://bbs.huaweicloud.com/forum/forum-726-1.html
1、模型简介
论文名称:RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space
项目链接:
https://gitee.com/mindspore/models/tree/master/research/nlp/rotate
RotatE是一个用于链接预测任务的知识图谱嵌入模型。RotatE模型旨在解决知识图谱中学习实体和关系表示的问题,以预测缺少的链接。 此类任务的成功在很大程度上取决于建模和推断关系(或关系之间)模式的能力。 RotatE模型能够建模和推断各种关系模式,包括:对称/反对称,反演和组成。
2、数据集介绍
wn18rr数据集(https://github.com/DeepGraphLearning/KnowledgeGraphEmbedding)是从WordNet数据集中抽取的子集,其中更多地保留了原数据集中的对称关系、非对称关系和组合关系,而去除了反转关系。wn18rr数据集一共包含40943个实体,11种关系,数据集总大小3.78M,其中训练集一共86835个三元组,验证集一共3034个三元组,测试集一共3134个三元组。需要注意的是,三元组数据中的实体采用数字id的形式,具体的实体名称可以在entities.dict中查找到。
3、模型迁移
由于RotatE模型源码由PyTorch深度学习框架编写,利用了其动态图的特性,对输入数据进行交叉负采样,从而能够训练出更加鲁棒的模型。Mindspore训练模式是以静态图为基础的,为了完成源码当中交叉负采样的效果,我们可以针对两种不同的负采样形式构建两个网络,共同训练同一组参数(即实体嵌入矩阵和关系嵌入矩阵)。在数据集负采样阶段,我们对负采样的种类进行标注,训练阶段对输入数据进行判断,从而让不同负采样的数据进入到不同的图里进行训练。
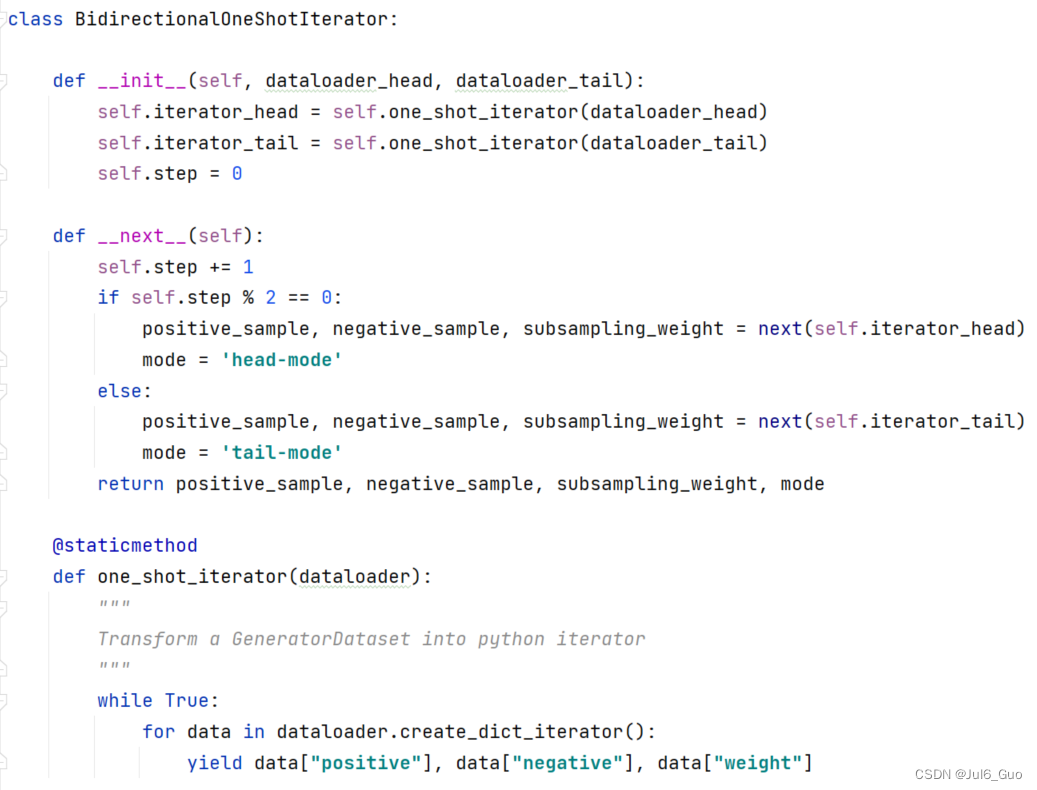
数据集交叉负采样类:
在此类的初始化阶段,我们需要传入两个mindspore.dataset.GeneratorDataset类,分别代表头实体负采样的数据类和尾实体负采样的数据类。
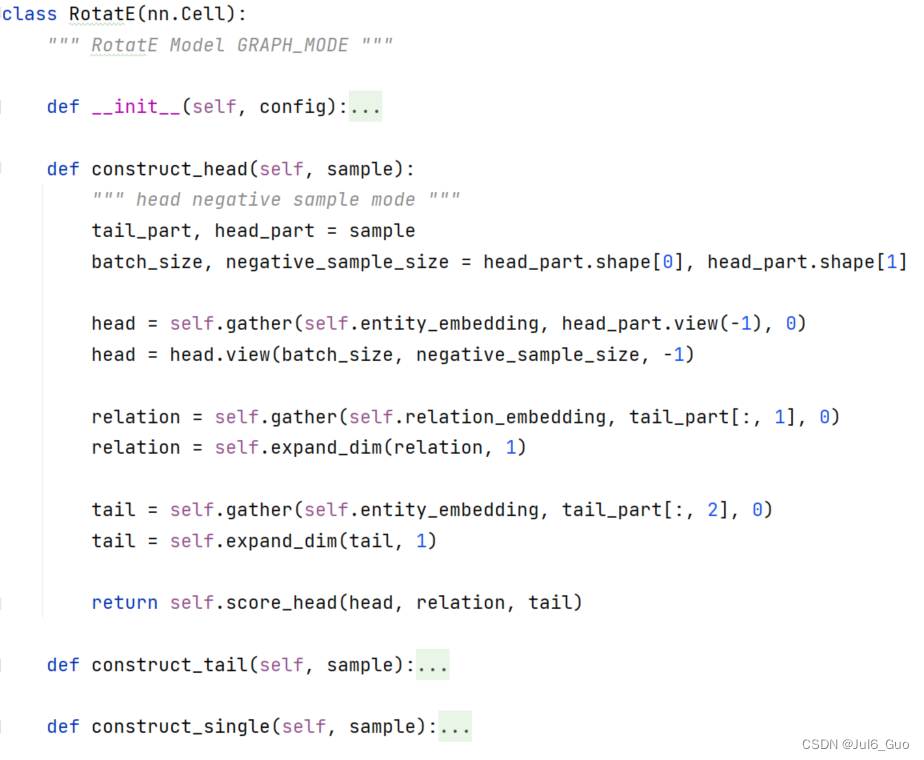
RotatE前向:
计算图需要继承mindspore.nn.Cell类,在 __init__ 函数中完成初始化,并在construct函数中编写前向传播代码(反向传播代码由Mindspore框架自动完成)。为了精简代码,我们自定义了头实体负采样、尾实体负采样以及正样本的前向逻辑,并根据输入的数据手动调用对应的方法。
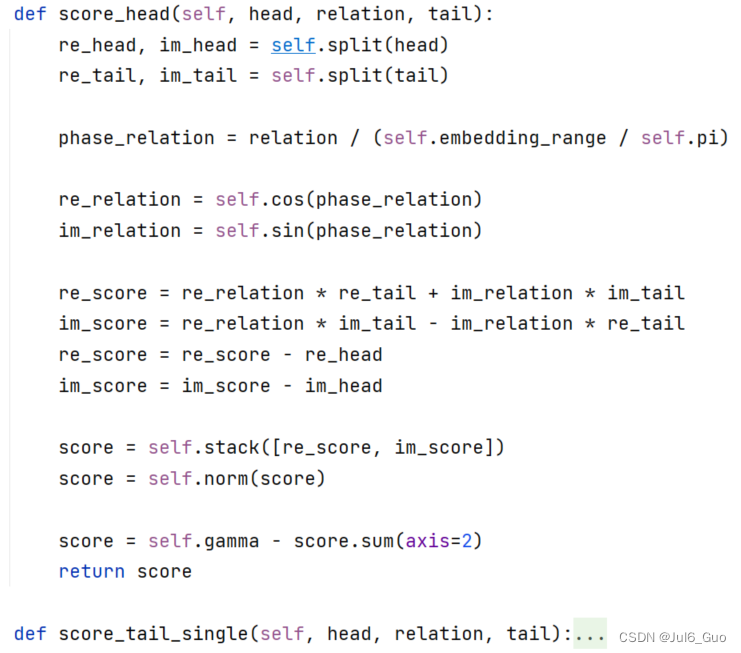
RotatE得分函数:
RotatE模型在以往模型实数范围的基础之上扩大到虚数范围,因此每个实体和关系都对应了实部和虚部两个部分。同样地,对于不同的负采样方案也有不同的处理方式。
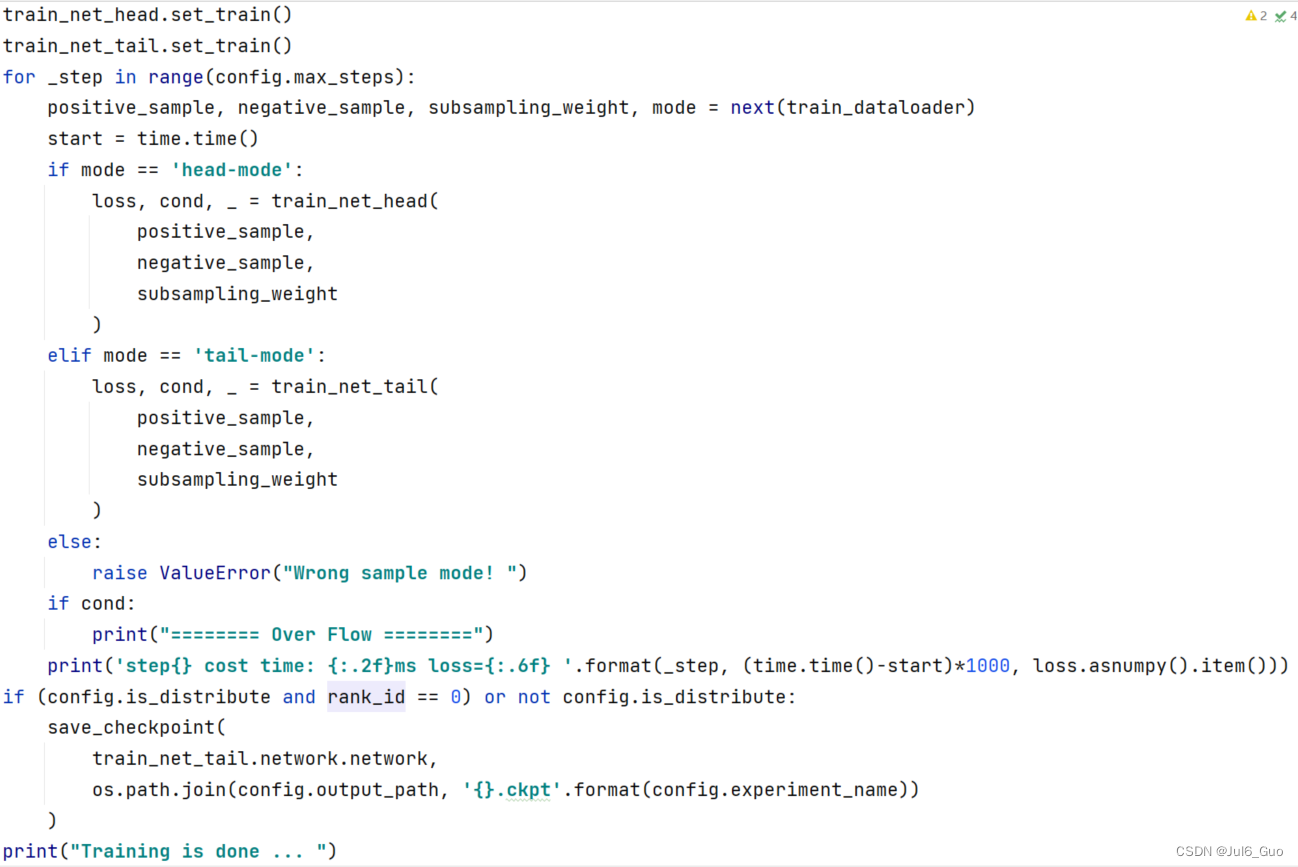
RotatE单卡训练:
我们实现了Ascend 910以及GPU设备上的训练逻辑。与其他模型不同地是,我们在实现RotatE模型训练的时候没有使用model.train()的模式,而是更像PyTorch编写的代码那样在for循环内执行训练,这为Mindspore开发的灵活性提供了新的思路。
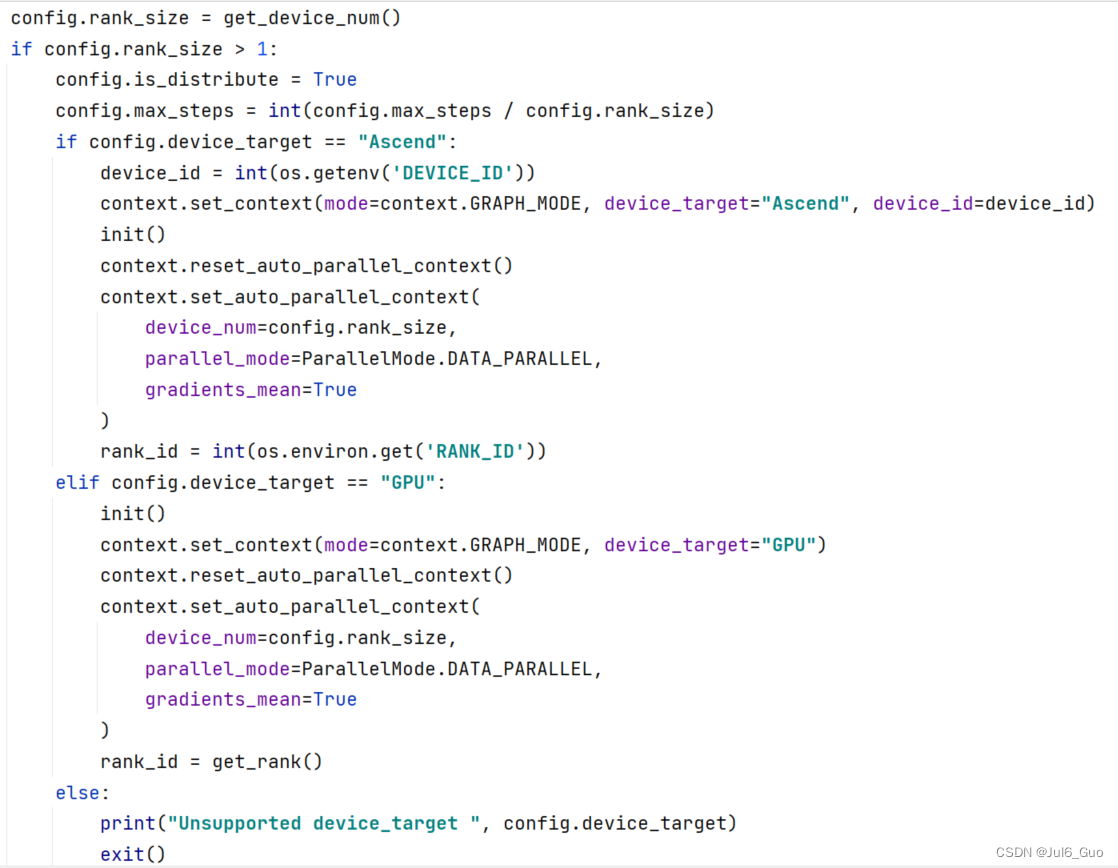
RotatE多卡训练:
同样地,我们也实现了RotatE模型在Ascend 910以及GPU上的多卡训练。对于多卡只需要设置好对应的参数和环境即可完成。
五、使用MindStudio对RotatE模型训练、评估和导出
1、执行训练
【重要】在每次训练完成后,请将服务器中output目录下的文件同步到本地,否则再次运行时这些文件将会被删除,导致不能评估
点击Run->Edit Configurations,在弹出的配置页面中,点击左上角“+”按钮,选择Ascend Trainingg,如下图。Name为该运行配置名称,不能重复。Executable填入本地被执行python文件位置,选择train.py。Command Aarguments为运行所需的参数,填入--device_target Ascend --output_path ./checkpoints/rotate-standalone-ascend/ --max_steps 80000。点击OK。
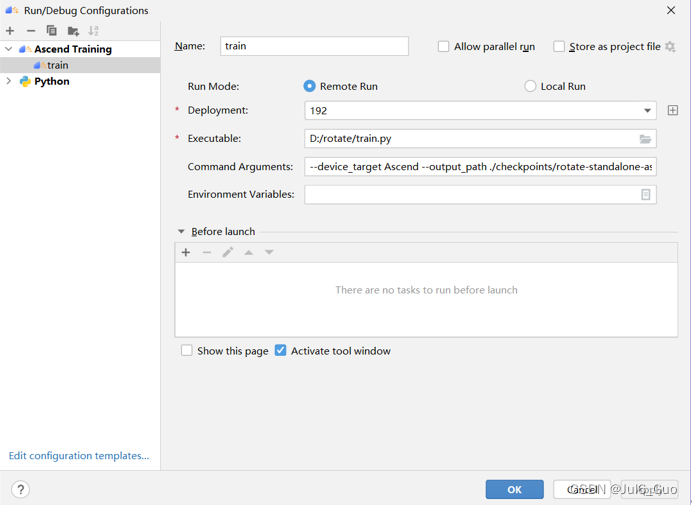
点击绿色三角运行。
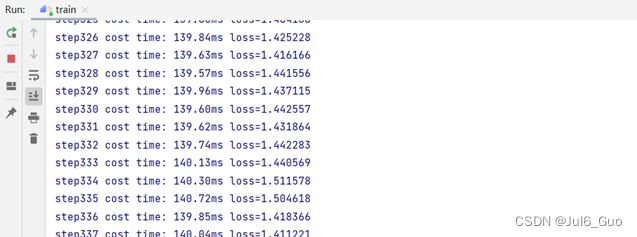
运行结果(部分),如图所示:
2、执行评估
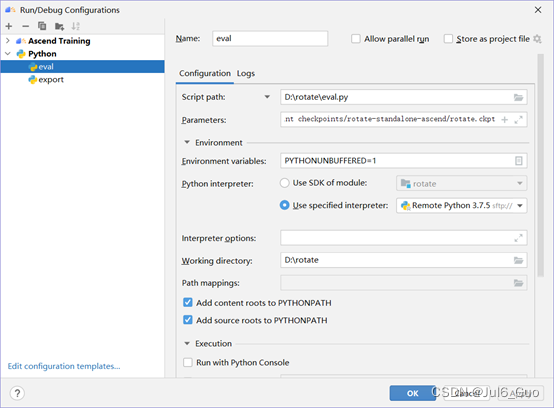
执行评估:点击Run->Edit Configurations,在弹出的配置页面中,点击左上角“+”按钮,选择Python。Name为该运行配置名称,不能重复。Script path填入本地被执行python文件位置,选择eval.py,parameters为运行所需的参数parameters中填入的参数为--device_target Ascend --eval_checkpoint checkpoints/rotate-standalone-ascend/rotate.ckpt,Working direcroty为当前项目根目录。点击绿色三角运行。
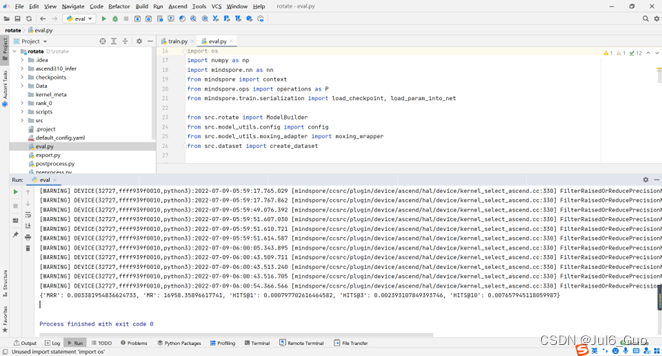
运行结果如图所示:
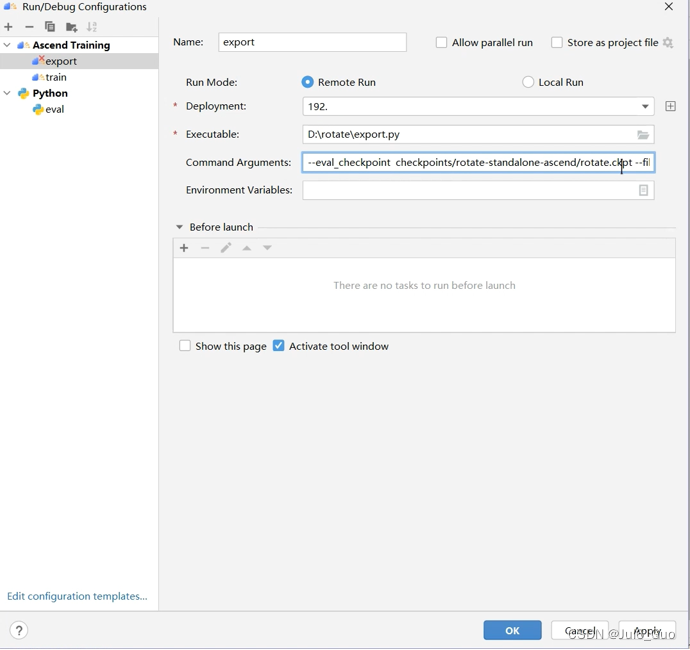
3、导出mindir模型
导出模型,点击Run->Edit Configurations,在弹出的配置页面中,点击左上角“+”按钮,选择Ascend Trainingg,如下图。Name为该运行配置名称,不能重复。Executable填入本地被执行python文件位置,选择export.py。Command Aarguments为运行所需的参数,填入--eval_checkpoint checkpoints/rotate-standalone-ascend/rotate.ckpt --file_format MINDIR。点击OK。点击绿色三角运行。
文件生成在./rotate/,如图所示:
![]()
六、使用MindInsight进行性能评估
1、安装MindInsight
可以采用pip安装或者源码编译安装两种方式,本教程采用pip安装。
安装PyPI上的版本:pip install mindinsight
如果上面安装较慢,建议安装自定义版本:
Pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/{version}/MindInsight/any/mindinsight-{version}-py3-none-any.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple注:{version}表示MindInsight版本号,例如下载1.7.0版本MindInsight时,{version}应写为1.7.0。
配置环境变量:
1.执行如下命令打开文件系统中的~/.bashrc文件:
vi ~/.bashrc
在文件最后添加如下环境变量:
export PATH=/usr/local/python3/bin:$PATH
“/usr/local/python3/bin”为示例安装路径,请根据实际情况配置。
输入:wq!保存退出。
2.执行命令使环境变量生效。
source ~/.bashrc
3.验证是否成功安装。
执行如下命令:
mindinsight start
如果出现下列提示,说明安装成功。
Web address: http://127.0.0.1:8080
service start state: success
重启MindStudio启用MIndInsight
2、使用MindInsight组件
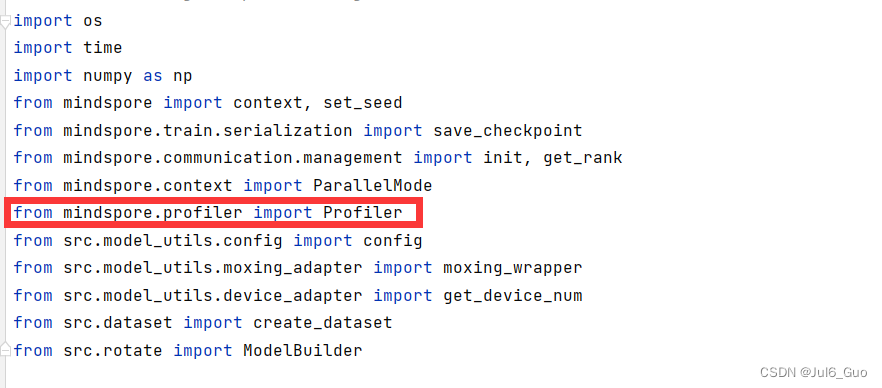
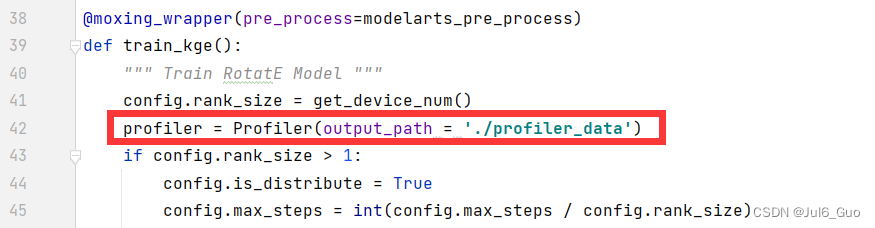
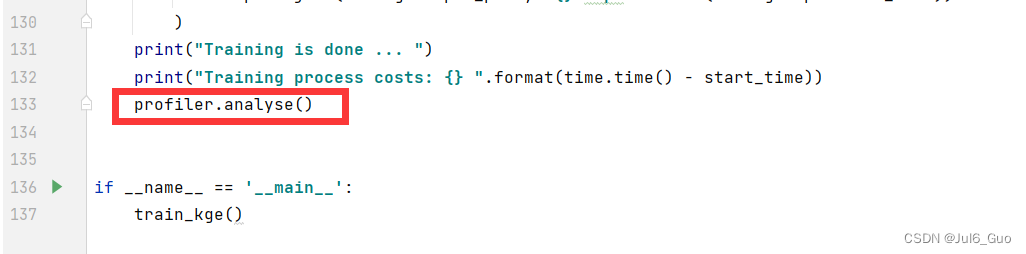
第一步:为了收集神经网络的性能数据,需要在训练脚本中添加MindSpore Profiler相关接口。修改train.py,在以下三处分别添加
from mindspore.profiler import Profiler
profiler = Profiler(output_path = './profiler_data')
profiler.analyse()
第二步:在工具栏选择“Ascend >MindInsight”打开MindInsight管理界面。
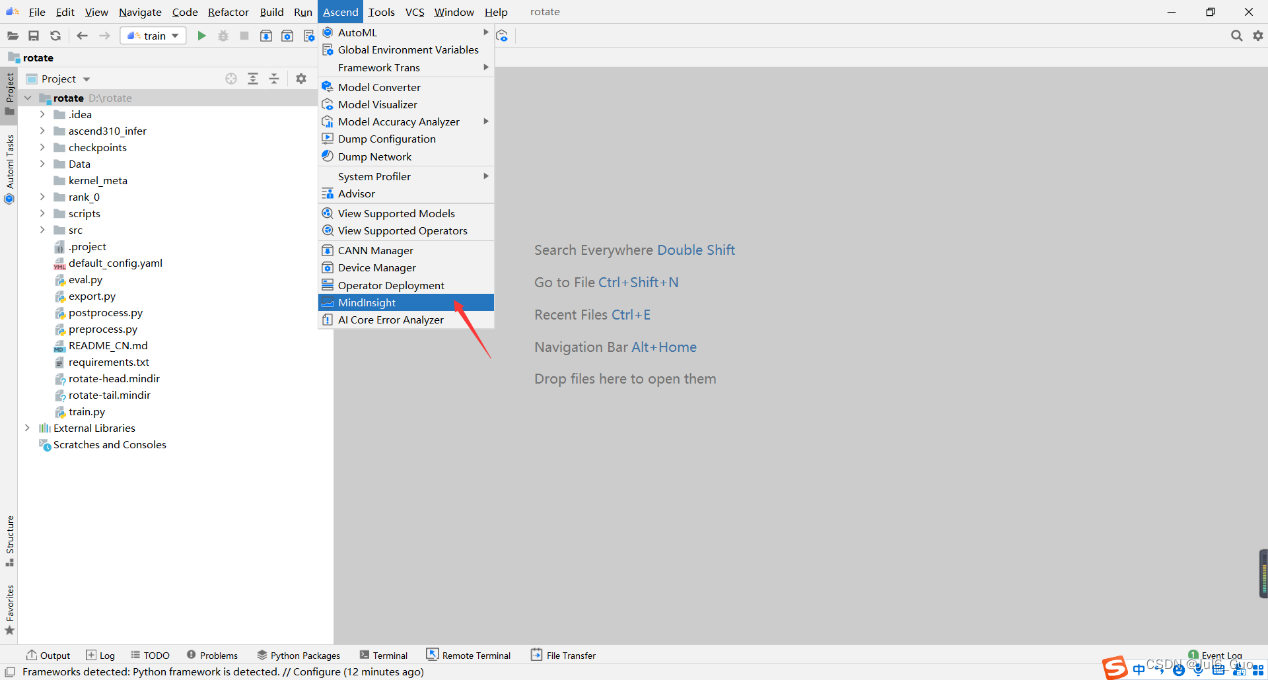
MindInsight管理界面可显示并管理多个MindInsight训练可视化工程。MindInsight管理界面相关属性说明如下图所示。点击Enable按钮,配置MindInsight组件相关参数。
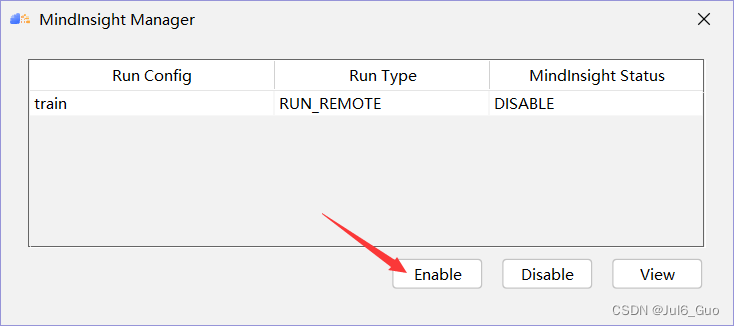
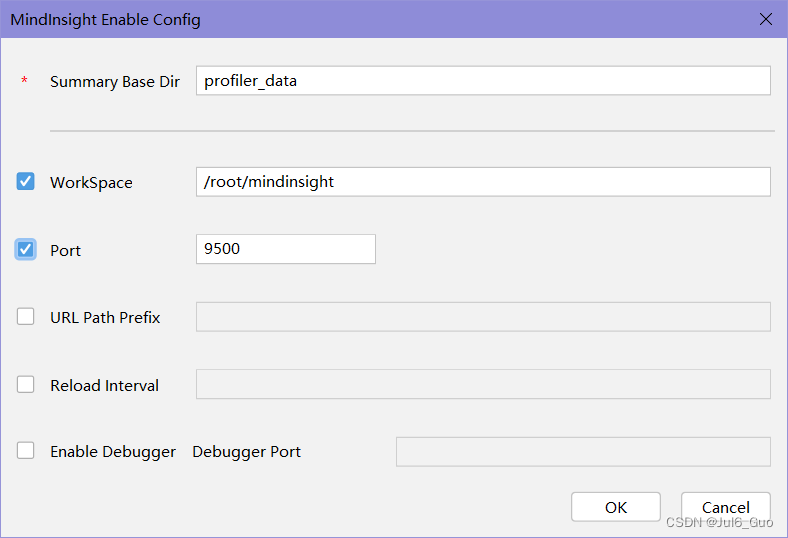
单击“OK”完成MindInsight组件相关参数配置,出现如图所示界面,说明配置成功(注意,Run Config的名称是执行训练/评估步骤中Ascend Training中的配置的名称,可能有所变化)
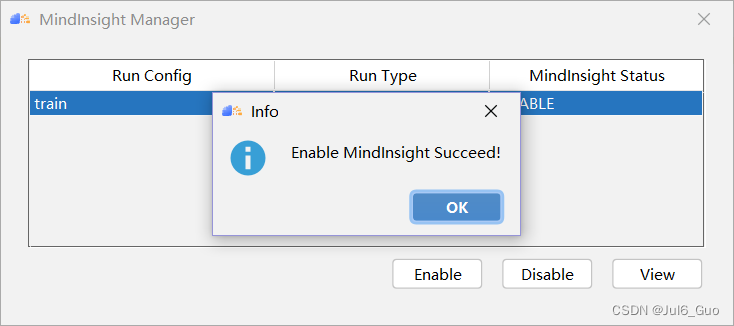
点击view按钮即可跳转进入浏览器,即可进入到UI面板界面
运行训练,即可得到各自的训练可视化情况。若想停止监控,单击“Disable”停止MindInsight可视化进程
第三步:查看训练样板,如下所示:
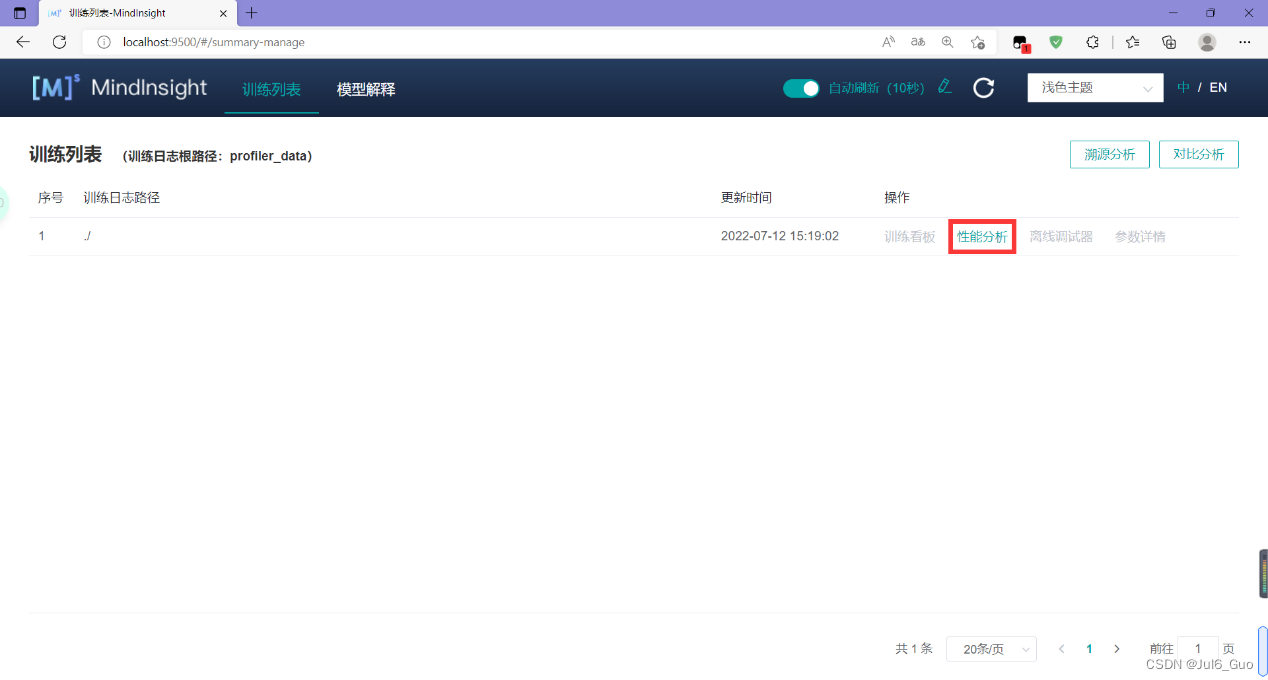
点击性能分析
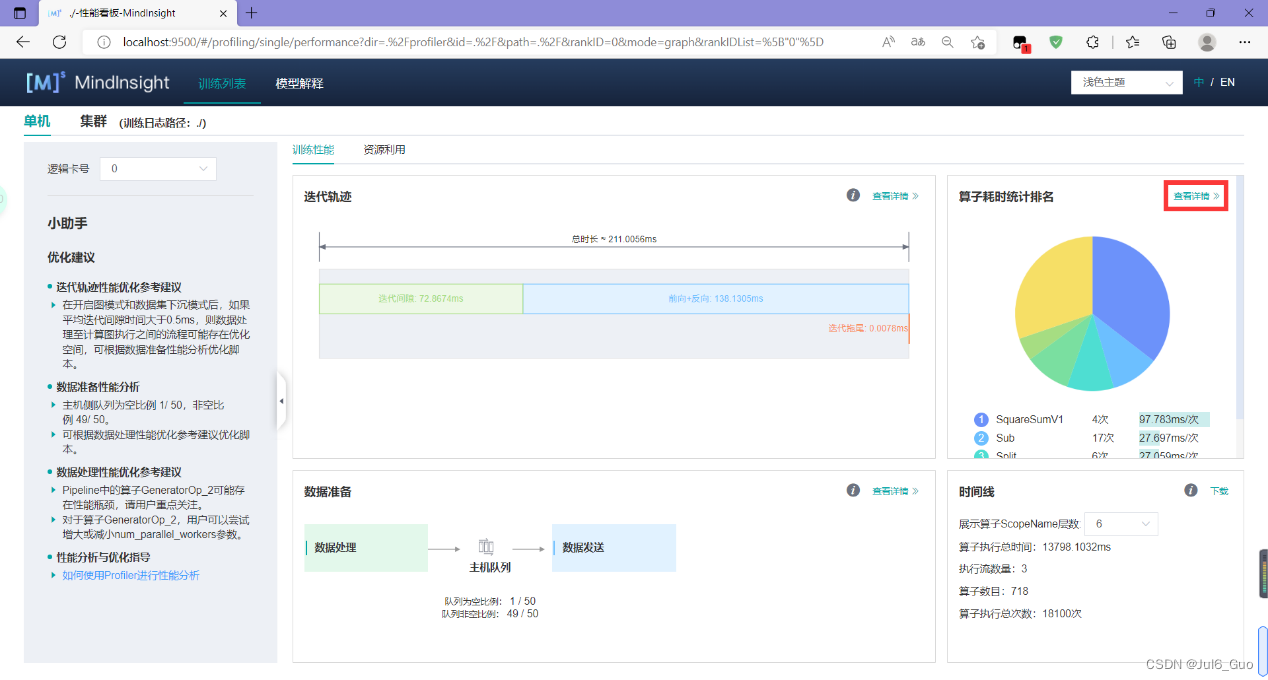
上图展示了性能数据总览页面,包含了迭代轨迹(Step Trace)、算子性能、数据准备性能和时间线等组件的数据总体呈现。各组件展示的数据如下:
- 迭代轨迹:将训练step划分为几个阶段,统计每个阶段的耗时,按时间线进行展示;总览页展示了迭代轨迹图。
- 算子性能:统计单算子以及各算子类型的执行时间,进行排序展示;总览页中展示了各算子类型时间占比的饼状图。
- 数据准备性能:统计训练数据准备各阶段的性能情况;总览页中展示了各阶段性能可能存在瓶颈的step数目。
- 时间线:按设备统计每个stream中task的耗时情况,在时间轴排列展示;总览页展示了Timeline中stream和task的汇总情况。
用户可以点击查看详情链接,进入某个组件页面进行详细分析。MindInsight也会对性能数据进行分析,在左侧的智能小助手中给出性能调试的建议。
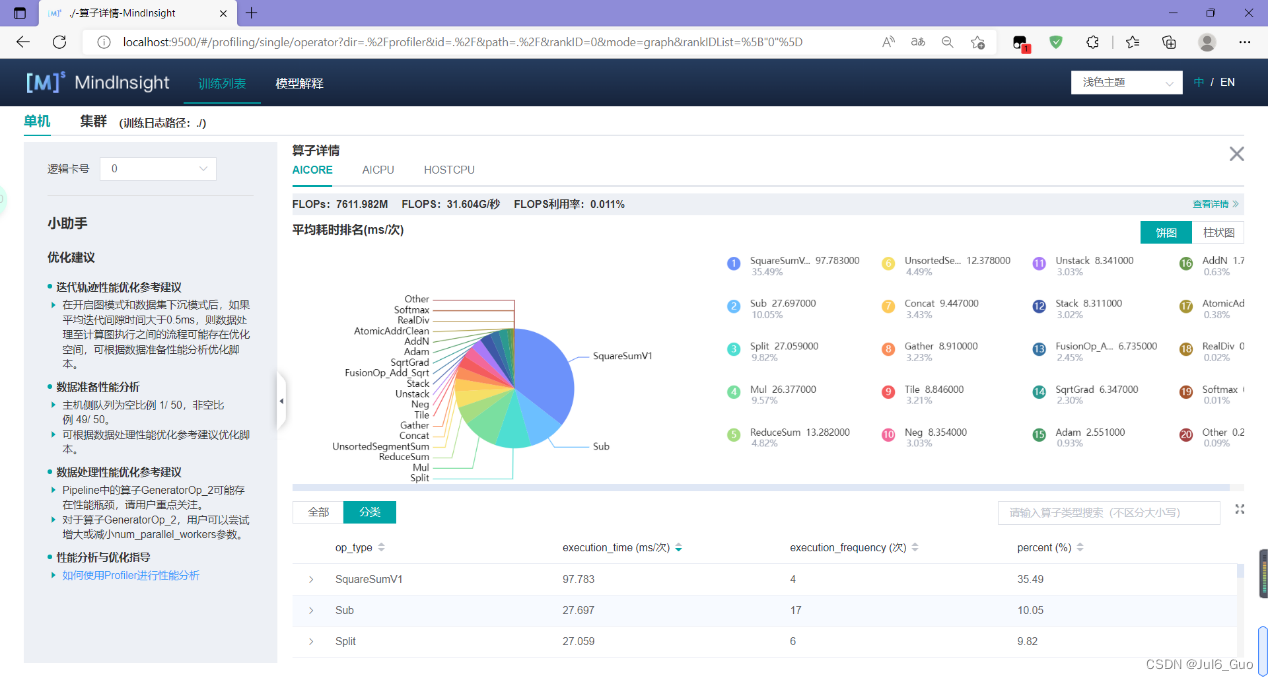
点击算子耗时统计排名模块的“查看详情”,可以对MindSpore运行过程中的各个算子的执行时间进行统计展示(包括AICORE、AICPU、HOSTCPU算子)。
七、FAQ
1.使用mindinsight –version出现以下提示并不能说明mindinsight可用
![]()
输入命令:mindinsight start出现“failed”,此时在MindStudio中配置mindinsight时会有“Enable MindInsight Failed!”的报错

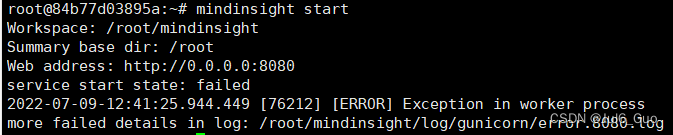
解决方法:重装mindinsight包
2.Ascend菜单中无Mindinsight选项
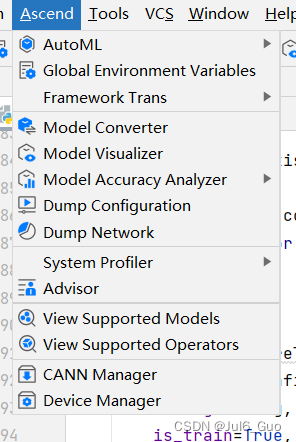
原因:Ascend -> convert to Training project步骤中,Project Type未设置成Ascend Training
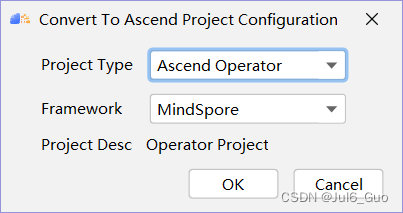
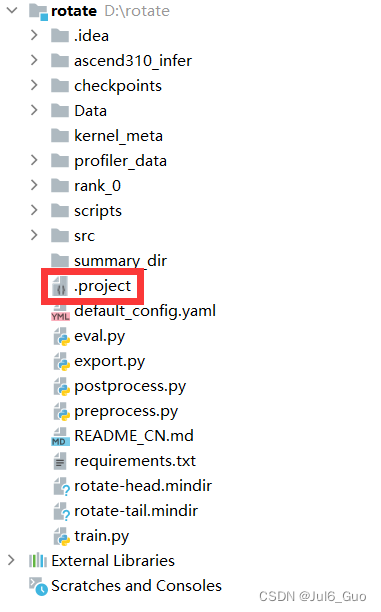
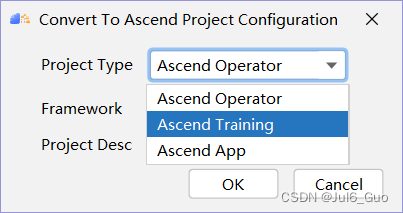
解决方法:删除.project文件,即可重新设置Project Type
3.Mindinsight卡顿,或者View后在浏览器中查看只能得到空白页
解决方法:采用命令行查看
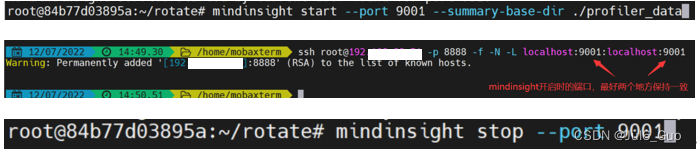
八、从昇腾官方体验更多内容
mindspore模型开发教程与API可参考mindspore官网:https://www.mindspore.cn/,
也可以在昇腾论坛进行讨论和交流:
https://bbs.huaweicloud.com/forum/forum-726-1.html
总结
以上就是本文要讲的内容,本文详细介绍了MindSpore深度学习框架的环境搭建和配置介绍、MindStudio开发平台的安装与使用、RotatE模型的介绍与迁移、使用MindStudio进行训练评估与导出、MindInsight性能分析。
欢迎大家提出意见与反馈,谢谢!