这篇文章旨在让大家快速了解NoSQL的基本知识。
文章目录
NoSQL概述
NoSQL是对不同于传统的关联式资料库的数据库管理系统的统称。
”Not Only SQL ”,“不仅仅是SQL”。
如今,每天网络上都会产生非常庞大的数据量。这些数据有很大一部分是由关系数据库管理系统(RDBMS)来处理的。 1970年 E.F.Codd’s提出的关系模型的论文 “A relational model of data for large shared data banks”,使得数据建模和应用程序编程更加简单。
通过应用实践证明,关系模型非常适合于客户服务器编程,如今它是结构化数据存储在网络和商务应用的主导技术。
NoSQL 是一项全新的数据库革命性运动,早期就有人提出,2009年发展趋势越发高涨。NoSQL的拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,也暴露了很多难以克服的问题。当代典型的关系数据库在一些数据敏感的应用中(例如为巨量文档创建索引、高流量网站的网页服务,以及发送流式媒体时)表现出的是糟糕的性能。
关系型数据库的典型的主要用于执行规模小而读写频繁,或者大批量极少写访问的事务中。而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。该工具可以为大数据建立快速、可扩展的存储库。
显然,NoSQL可以用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。而这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
Big Data
那么什么又是大数据(big data)呢?
大数据通常被认为是PB(1024 terabytes)或EB(1EB=100 万TB)或更高数量级的数据,包括结构化的、半结构化的和非结构化的数据,其规模或复杂程度超出了常用传统数据库和软件技术所能管理和处理的数据集范围。随着技术的发展,大数据广泛存在,如企业数据、统计数据、科学数据、医疗数据、互联网数据、移动数据、物联网数据,等等。并且各行各业都可得益于大数据的应用。
按其应用类型,可将大数据分为海量交易数据 (企业OLTP应用)、海量交互数据(社网、传感器、GPS、Web信息)和海量处理数据(企业OLAP应用)这 3 类 。
海量交易数据的应用特点是多为简单的读写操作,访问频繁,数据增长快,一次交易的数据量不大,但要求支持事务特性。其数据的特点是完整性好、实效性强,有强一致性要求。
海量处理数据的应用特点是面向海量数据分析,操作复杂,往往涉及多次迭代完成,追求数据分析的高效率,但不要求支持事务特性,典型的是采用并行与分布处理框架实现。其数据的典型特点是同构性(如关系数据或文本数据或列模式数据)和较好的稳定性(不存在频繁的写操作)。
海量交互数据的应用特点是实时交互性强,但不要求支持事务特性。其数据的典型特点是结构异构、不完备、数据增长快,不要求具有强一致性。
大数据带来了大机遇,同时也为有效管理和利用大数据提出了挑战。
尽管不同种类的海量数据存在一定的差异,但总体而言,支持海量数据管理的系统应具有如下特性:高可扩展性(满足数据量增长的需要)、高性能 (满足数据读写的实时性和查询处理的高性能)、容错性(保证分布系统的可用性)、可伸缩性(按需分配资源)和尽可能低的运营成本等。
然而,由于传统的关系数据库所固有的局限性,如峰值性能、伸缩性、容错性、可扩展性差等特性,很难满足海量数据的柔性管理需求。为此,提出了云环境下面向海量数据管理的新模式,如采用 NoSQL存储系统或可扩展的数据管理系统(或称关系云系统)支持海量数据的存储和柔性管理。目前,它们是云环境下所采用的典型的云存储系统。
在性能上,NoSQL数据存储系统都具有传统关系数据库所不能满足的特性,是面向应用需求而提出的各具 特色的产品。在设计上,它们都关注对数据高并发地读写和对海量数据的存储等,并具有很好的灵活性和性能。它们都支持自由的模式定义方式,可实现海量数据的快速访问,灵活的分布式体系结构支持横向可伸缩性和可用性,且对硬件的需求较低。
可扩展的数据管理系统(关系云)是侧重扩展数据库系统到云环境下,使关系云支持海量数据管理。典型的系统如微软的SQL Azure和MIT的Relational Cloud等。主要针对事务特性、系统弹性性能、多租户负载均衡技术等进行研究。
发展历史
NoSQL一词最早出现于1998年,是Carlo Strozzi开发的一个轻量、开源、不提供SQL功能的关系数据库。
2009年,Last.fm的Johan Oskarsson发起了一次关于分布式开源数据库的讨论,来自Rackspace的Eric Evans再次提出了NoSQL的概念,这时的NoSQL主要指非关系型、分布式、不提供ACID的数据库设计模式。
2009年在亚特兰大举行的"no:sql(east)“讨论会是一个里程碑,其口号是"select fun, profit from real world where relational=false;”。因此,对NoSQL最普遍的解释是“非关联型的”,强调键-值存储和面向文档数据库的优点,而不是单纯的反对RDBMS。
基于2014年的收入,NoSQL市场领先企业是MarkLogic,MongoDB和Datastax。
基于2015年的人气排名,最受欢迎的NoSQL数据库是MongoDB,Apache Cassandra和Redis。
关系型数据库
我们先来看看关系型数据库的特征:
关系型数据库遵循ACID规则
事务在英文中是transaction,和现实世界中的交易很类似,它有如下四个特性:
- 1、A (Atomicity) 原子性
一个事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。
比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成。 - 2、C (Consistency) 一致性
一致性不难理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
例如现有完整性约束a+b=10,如果一个事务改变了a,那么必须得改变b,使得事务结束后依然满足a+b=10,否则事务失败。 - 3、I (Isolation) 独立性
所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
比如现在有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的。 - 4、D (Durability) 持久性
持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
分布式系统简介
分布式系统(distributed system)由多台计算机和通信的软件组件通过计算机网络连接(本地网络或广域网)组成。
分布式系统是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。
因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。
分布式系统可以应用在不同的平台上如:Pc、工作站、局域网和广域网上等。
分布式计算的优点
- 可靠性(容错) :
分布式计算系统中的一个重要的优点是可靠性。一台服务器的系统崩溃并不影响到其余的服务器。 - 可扩展性:
在分布式计算系统可以根据需要增加更多的机器。 - 资源共享:
共享数据是必不可少的应用,如银行,预订系统。 - 灵活性:
由于该系统是非常灵活的,它很容易安装,实施和调试新的服务。 - 更快的速度:
分布式计算系统可以有多台计算机的计算能力,使得它比其他系统有更快的处理速度。 - 开放系统:
由于它是开放的系统,本地或者远程都可以访问到该服务。 - 更高的性能:
相较于集中式计算机网络集群可以提供更高的性能(及更好的性价比)。
分布式计算的缺点
- 故障排除:
故障排除和诊断问题。 - 软件:
更少的软件支持是分布式计算系统的主要缺点。 - 网络:
网络基础设施的问题,包括:传输问题,高负载,信息丢失等。 - 安全性:
开放系统的特性让分布式计算系统存在着数据的安全性和共享的风险等问题。
非关系型数据库分类
由于非关系型数据库本身天然的多样性,以及出现的时间较短,因此,不像关系型数据库,有几种数据库能够一统江山,非关系型数据库非常多,并且大部分都是开源的,这里列出一些:
Redis,TokyoCabinet,Cassandra,Voldemort,MongoDB,Dynomite,HBase,CouchDB,Hypertable,Riak,Tin, Flare ,Lightcloud ,KiokuDB, Scalaris,…
这些数据库中,除了一些共性外,很大一部分都是针对某些特定的应用需求出现的,因此,对于该类应用,具有极高的性能。依据结构化方法以及应用场合的不同,主要分为以下几类:
- 面向高性能并发读写的
Key-Value(键值)数据库:Key-Value数据库的主要特点就是具有极高的并发读写性能,Redis,Tokyo Cabinet,Flare就是这类的代表。 - 面向海量数据访问的
面向文档数据库(Document store):这类数据库的特点是,可以在海量的数据中快速的查询数据。典型代表为MongoDB以及CouchDB。 - 面向可扩展性的
分布式数据库(Object Store):这类数据库想解决的问题就是传统数据库在可扩展性上的缺陷,这类数据库可以适应数据量的增加以及数据结构的变化,如Google Appengine的Big Table,Hadoop生态中的HDFS。
其中,key-value存储备受关注,已经成为NoSQL的代名词。
NoSQL的特点
NoSQL是指那些非关系型的、分布式的、不保证遵循ACID原则的数据存储系统。
它典型地遵循CAP定理和BASE原则。
CAP定理(CAP theorem)
在计算机科学中, CAP定理(CAP theorem), 又被称作 布鲁尔定理(Brewer’s theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
• 一致性(Consistency) (所有节点在同一时间具有相同的数据)
• 可用性(Availability) (保证每个请求不管成功或者失败都有响应)
• 分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三大类:
• CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
• CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
• AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
BASE
BASE:Basically Available, Soft-state, Eventually Consistent。 由 Eric Brewer 定义。
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
BASE是NoSQL数据库通常对可用性及一致性的弱要求原则:
• Basically Availble --基本可用
• Soft-state --软状态/柔性事务。 “Soft state” 可以理解为"无连接"的, 而 “Hard state” 是"面向连接"的
• Eventual Consistency – 最终一致性, 也是是 ACID 的最终目的。
NoSQL适用场景
NoSQL数据库在以下的这几种情况下比较适用:
1、数据模型比较简单;
2、需要灵活性更强的IT系统;
3、对数据库性能要求较高;
4、不需要高度的数据一致性;
5、对于给定key,比较容易映射复杂值的环境。
Key-Value数据模型
1) Key-Value 型
Key-Value 键值对数据模型实际上是一个映射,即 key 是查找每条数据地址的唯一关键字,value 是该数据实 际存储的内容。例如键值对:(“20091234”,“张三”),其 key:“20091234”是该数据的唯一入口,而value:“张三”是该数 据实际存储的内容。Key-Value 数据模型典型的是采用哈希函数实现关键字到值的映射,查询时,基于 key 的 hash 值直接定位到数据所在的点,实现快速查询,并支持大数据量和高并发查询。
2) Key-Column 型
Key-Column 型数据模型主要来自 Google 的 BigTable。目前流行的开源项目 Hbase 和 Cassandra 也采用了 该种模型。Column 型数据模型可以理解成一个多维度的映射,主要包含 column,row 和 columnfamily 等概念。下表描述了一个 column 型数据模型的实例。

在key-column型数据模型中,column是数据库中最小的存储单元,它是一个三元组,包括name (如c 1 ,c 2 ),value(如v 1 ,v 2 )和timestamp(如 123456),即一个带有时间戳的key-value键值对。每一个row也是一个 key-value对,对于任意一个row,其key是该row下数据的唯一入口(如k 1 ),value是一个column的集合(如column: c 1 ,c 2 )。Columnfamily是一个包含了多个row的结构,相当于关系库中表的概念。
简单来说,key-column 型数据模型是通过多层的映射模拟了传统表的存储格式,实际上类似于 key-value 数 据模型,需要通过 key 进行查找。因此,key-column 型数据模型是 key-value 数据模型的一种扩展。
关键技术问题
尽管大多数 NoSQL 数据存储系统都已被部署于实际应用中,但归纳其研究现状,还有许多挑战性问题。
研究现状:
- 已有key-value数据库产品大多是面向特定应用自治构建的,缺乏通用性;
- 已有产品支持的功能有限(不支持事务特性),导致其应用具有一定的局限性;
- 已有一些研究成果和改进的NoSQL数据存储系统,但它们都是针对不同应用需求而提出的相应解决方案,如支持组内事务特性、弹性事务等,很少从全局考虑系统的通用性,也没有形成系列化的研究成果;
- 缺乏类似关系数据库所具有的强有力的理论(如armstrong公理系统)、技术(如成熟的基于启发式的优化策略、两段封锁协议等)、标准规范(如SQL语言) 的支持。
典型的关键问题如下:
• 海量数据分布存储与局部性
海量数据均匀分布存储在各节点上,典型的策略是采用 Hash分布存储或连续存储。Hash存储可实现均匀分布,但弱化了数据间的联系,不能很好地支持范围查询;连续存储支持范围查询但影响数据分布存储的均衡性。
目前,简单的 key-value 数据模型为提升可扩展性,弱化了数据间的关联关系,这对于 key 间不具有关联性的事务是合适的。然而,产生的大数据不是孤立存在的,它们之间存在必然联系,如社网中某一主题的数据、同类产品的销售数据等。另外,为增值海量数据的价值,进行海量数据分析也是必然趋势。因此,在弱化数据关系实现可扩展性的同时,需要考虑数据的局部性,以有效提升海量数据查询与分析的 I/O 性能。为此,数据模型应兼顾可扩展性和数据间的关联性。
• 分布式事务特性
为了支持分布环境下的事务特性,典型的策略是采用两段提交协议(2PC) 实现。然而,集群环境下节点的动态性很 难保证支持事务的节点的及时提交,导致事务代价大。为此,需要研究如何避免采用 2PC来支持事务特性的 key-value数据库。典型的研究是将事务操作数据分布到一个节点上或动态重组到一个节点上来避开分布环境, 但这种策略局限性较大。为此,需要考虑如何避开 2PC协议,即回避因单点失败导致整个事务废弃的处理过程,如采用乐观的并发控制方法,并结合副本数据支持云环境下的事务特性。
• 负载均衡的自适应性
在面向海量数据管理的云环境下,用户访问量、数据变化量或执行任务量都是事先无法精确预见的。随着数据量的增加或应用范围的扩大或应用用户的增加,都可能出现存储热点或应用热点。因此,弹性动态平衡是云环境下分布系统的典型特点。弹性(elasticity),就是随着负载的增加和减少可动态调节,并最小化操作代价。为此,需要有自适应协调方法,保证系统的弹性性能,有效地提高系统资源利用率。目前,典型的研究是:
- 侧重多租户的事务迁移达到动态平衡;
- 事先选择均衡的执行方案,没有考虑自适应性。
• 灵活支持复杂查询
若按需满足不同用户的查询需求,云环境必须具有更大的灵活性和柔性。目前,已有 key-value数据库均支持 简单查询,而将复杂查询交由应用层完成。MapReduce 是被广泛接受的分布式处理框架,用于实现海量数据的并行处理,通常,应用层基于该框架定制相应的查询视图。尽管 MapReduce 为海量数据处理提供了灵活的并行处理框架,但如何最优地实现各种复杂查询和数据分析还需要深入研究。希望能提供一种更为灵活的、可优化的复杂查询定义模型,可按需满足不同用户的查询和数据分析需求。
• 灵活的副本一致性策略
在云环境下,典型的是基于副本策略提高系统的可用性,同时也带来了维护副本一致性的代价。已有系统采用最终一致性策略或强一致性策略实现副本同步。然而,无论何种策略都具有一定的局限性,限制了 NoSQL数据存储系统的应用范围。如强一致性适用于同时访问数据量不是很大的OLTP 应用或在线交易系统,而最终一致性适用于不要求具有实时一致需求的Web查询系统。因此,需要提供一个灵活的、自适应的副本一致性策略模型,按需配置副本一致性策略,并最小代价地满足各种应用需求。
实战演练–MongoDB数据库
MongoDB简介
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
基本概念
(1)文档
文档是 MongoDB 中数据的基本单位,类似于关系数据库中的行(但是比行复杂)。多个键及其关联的值有序地放在一起就构成了文档。不同的编程语言对文档的表示方法不同,在JavaScript 中文档表示为:
{“greeting”:“hello,world”}
这个文档只有一个键“greeting”,对应的值为“hello,world”。多数情况下,文档比这个更复杂,它包含多个键/值对。例如:
{“greeting”:“hello,world”,“foo”: 3}
文档中的键/值对是有序的,下面的文档与上面的文档是完全不同的两个文档。
{“foo”: 3 ,“greeting”:“hello,world”}
文档中的值不仅可以是双引号中的字符串,也可以是其他的数据类型,例如,整型、布尔型等,也可以是另外一个文档,即文档可以嵌套。文档中的键类型只能是字符串。

需要注意的是:
- 文档中的键/值对是有序的。
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
- MongoDB区分类型和大小写。
- MongoDB的文档不能有重复的键。
- 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
文档键命名规范:
• 键不能含有\0 (空字符)。这个字符用来表示键的结尾。
• .和$有特别的意义,只有在特定环境下才能使用。
• 以下划线"_"开头的键是保留的(不是严格要求的)。
(2)集合
集合就是一组文档,类似于关系数据库中的表。集合是无模式的,集合中的文档可以是各式各样的。例如,{“hello,word”:“Mike”}和{“foo”: 3},它们的键不同,值的类型也不同,但是它们可以存放在同一个集合中,也就是不同模式的文档都可以放在同一个集合中。既然集合中可以存放任何类型的文档,那么为什么还需要使用多个集合?这是因为所有文档都放在同一个集合中,无论对于开发者还是管理员,都很难对集合进行管理,而且这种情形下,对集合的查询等操作效率都不高。所以在实际使用中,往往将文档分类存放在不同的集合中,例如,对于网站的日志记录,可以根据日志的级别进行存储,Info级别日志存放在Info 集合中,Debug 级别日志存放在Debug 集合中,这样既方便了管理,也提供了查询性能。但是需要注意的是,这种对文档进行划分来分别存储并不是MongoDB 的强制要求,用户可以灵活选择。
可以使用“.”按照命名空间将集合划分为子集合。例如,对于一个博客系统,可能包括blog.user 和blog.article 两个子集合,这样划分只是让组织结构更好一些,blog 集合和blog.user、blog.article 没有任何关系。虽然子集合没有任何特殊的地方,但是使用子集合组织数据结构清晰,这也是MongoDB 推荐的方法。
(3)数据库
MongoDB 中多个文档组成集合,多个集合组成数据库。一个MongoDB 实例可以承载多个数据库。它们之间可以看作相互独立,每个数据库都有独立的权限控制。在磁盘上,不同的数据库存放在不同的文件中。MongoDB 中存在以下系统数据库。
● Admin 数据库:一个权限数据库,如果创建用户的时候将该用户添加到admin 数据库中,那么该用户就自动继承了所有数据库的权限。
● Local 数据库:这个数据库永远不会被复制,可以用来存储本地单台服务器的任意集合。
● Config 数据库:当MongoDB 使用分片模式时,config 数据库在内部使用,用于保存分片的信息。
安装
MongoDB可以安装在Windows、Linux、Mac os平台上,这里以64位Linux平台的安装使用为例(实际环境:centos 7.4,Linux内核: 3.1)
步骤:
下载完安装包,并解压 tgz(以下演示的是 64 位 Linux上的安装) 。
curl -O https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.0.6.tgz # 下载
tar -zxvf mongodb-linux-x86_64-3.0.6.tgz # 解压
mv mongodb-linux-x86_64-3.0.6/ /usr/local/mongodb # 将解压包拷贝到指定目录
MongoDB 的可执行文件位于 bin 目录下,所以可以将其添加到 PATH 路径中:
export PATH=/usr/local/mongodb/bin:$PATH
创建数据库目录
MongoDB的数据存储在data目录的db目录下,但是这个目录在安装过程不会自动创建,所以你需要手动创建data目录,并在data目录中创建db目录。
cd /usr/local/mongodb
mkdir log #日志文件夹
mkdir -p data/db
运行MongoDB服务
进入到mongodb下的bin路径,执行
cd /usr/local/mongodb/bin
./mongod
MongoDB后台管理 Shell
./mongo
基本操作
(,演示一小部分)
由于它是一个JavaScript shell,可以运行一些简单的算术运算:
也可以插入一些简单的数据,并对插入的数据进行检索:
第一个命令将数字10插入到test集合的x字段中。
版本号
Db命令可以显示当前数据库对象或集合, ‘use’命令可以指定连接到哪个数据库,如
use local #如果数据库不存在,则创建数据库,否则切换到指定数据库。
注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
Mongodb Built-In Roles(内置角色):
1. 数据库用户角色:read、readWrite; 2. 数据库管理角色:dbAdmin、dbOwner、userAdmin; 3. 集群管理角色:clusterAdmin、clusterManager、clusterMonitor、hostManager; 4. 备份恢复角色:backup、restore; 5. 所有数据库角色:readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase 6. 超级用户角色:root 7.内部角色:__system// 这里还有几个角色间接或直接提供了系统超级用户的访问(dbOwner 、userAdmin、userAdminAnyDatabase)
如,我们可以创建一个角色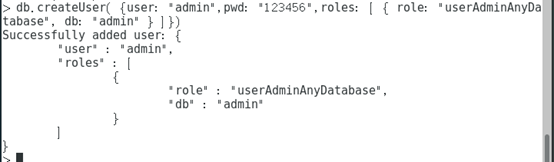
删除当前数据库:
db.dropDatabase()
创建集合
db.createCollection(name, options)
参数说明:
• name: 要创建的集合名称
• options: 可选参数, 指定有关内存大小及索引的选项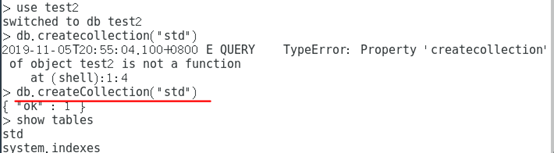
删除集合
db.collection_name.drop() #collection_name是你要删除的集合名
插入文档
MongoDB 使用 insert() 或 save() 方法向集合中插入文档,语法如下:
db.COLLECTION_NAME.insert(document)
例如,下面的文档存在test2中的student集合中:
当然,我们也可以在java或者python程序中连接并使用MongoDB(以下是window环境下进行操作)
参考文献
http://www.sigma.me/2011/06/11/intro-to-nosql.html(NoSQL非关系数据库简介)
http://publications.lib.chalmers.se/records/fulltext/123839.pdf(Investigating
storage solutions for large data) https://zh.wikipedia.org/wiki/NoSQL
(NOSQL-维基百科)
http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=rjxb201308007#
(Journal of Software 软件学报 Vol.24, No.8, August 2013)
https://www.yiibai.com/hadoop/intro-mapreduce.html (MapReduce简介和入门)
https://www.runoob.com/mongodb/mongodb-databases-documents-collections.html(菜鸟教程–mongodb)
注释