1 基本骨架nn.Module的使用
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
return output
tudui = Tudui()
x = 1
output = tudui(x)
print(output)
#输出2
2 卷积操作

import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 3, 0, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
output = F.conv2d(input, kernel, stride=1)
print(output)
output2 = F.conv2d(input, kernel, stride=1)
print(output2)
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)
# stride: 步长
# padding:边缘填充
3 Convolution Layers 卷积层
Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’, device=None, dtype=None)
- in_channels: 输入通道数目
- out_channels: 输出通道数目
- kernel_size: 卷积核尺寸
- stride: 每次卷积时移动的步长
- padding: 在边界外围增加像素
- dilation: 卷积核间距,如下图dilation=1

- 代码:
import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("/.dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
writer = SummaryWriter("./logs")
step = 0
for data in dataloader:
imgs, targets = data
output = tudui(imgs)
# torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# 只能识别三通道图像
# torch.Size([64, 6, 30, 30]) -> [xx, 3, 30, 30]
output = torch.reshape(output, (-1, 3, 30, 30)) # 不知道就写-1, 会自动根据后面的值来进行运算
writer.add_images("output", output, step)
step = step + 1
为什么要有多个卷积核?
一个卷积核就是一个特征提取器,多个卷积核就是多个特征提取器。
报错 !
AssertionError: size of input tensor and input format are different. tensor shape: (128, 3, 64, 64), input_format: CHW
错误:
writer.add_image(“input”, imgs)
正确:
writer.add_images(“input”, imgs)
4 Pooling layers 池化层
池化层的最主要作用就是压缩图像,它对下采样的卷积核为只取对应位置的最大值、平均值等(最大池化、平均池化)。
import torch
import torchvision.transforms
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
# 准备数据
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# ceil_mode: 当卷积核超过图像边界时,ceil_mode=True表示不舍弃数据
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
tudui = Tudui()
writer = SummaryWriter("logs_maxpool")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = tudui(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
5 非线性激活
ReLU

import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU()
def forward(self, input):
output = self.relu1(input)
return output
tudui = Tudui()
output = tudui(input)
print(output)
输出: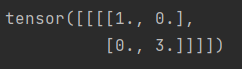
可以看出原始数据的负值被替换成了0。
Sigmoid
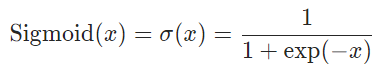

import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import Sigmoid
from torch.utils.data import DataLoader
# 准备数据
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
tudui = Tudui()
writer = SummaryWriter("./logs_relu")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = tudui(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()

6 Linear layers 线性层
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
tudui = Tudui()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
output = torch.reshape(imgs, (1, 1, 1, -1))
print(output.shape)
output = tudui(output)
print(output.shape)
7 搭建一个神经网络

import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 下列注释可由Sequential部分代替
# self.conv1 = Conv2d(3, 32, 5, padding=2) # padding 利用官方文档给出的公式计算出值为2
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(32, 32, 5, padding=2)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(32, 64, 5, padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.linear1 = Linear(1024, 64)
# self.linear2 = Linear(64, 10)
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2), # padding 利用官方文档给出的公式计算出值为2
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.linear2(x)
x = self.model1(x)
return x
tudui = Tudui()
print(tudui)
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
版权声明:本文为yinwei975原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。