调参做为风控领域重要的一环,对于提升模型性能,达到高分必备的环节
对于本次比赛,我们选用auc作为模型评价标准,类似的评价标准还有ks、f1-score等,具体介绍与实现大家可以回顾下task1中的内容。
一起来看一下auc到底是什么?
在逻辑回归里面,对于正负例的界定,通常会设一个阈值,大于阈值的为正类,小于阈值为负类。如果我们减小这个阀值,更多的样本会被识别为正类,提高正类的识别率,但同时也会使得更多的负类被错误识别为正类。为了直观表示这一现象,引入ROC。
ROC曲线中的四个点:
- 点(0,1):即FPR=0, TPR=1,意味着FN=0且FP=0,将所有的样本都正确分类;
- 点(1,0):即FPR=1,TPR=0,最差分类器,避开了所有正确答案;
- 点(0,0):即FPR=TPR=0,FP=TP=0,分类器把每个实例都预测为负类;
- 点(1,1):分类器把每个实例都预测为正类
总之:ROC曲线越接近左上角,该分类器的性能越好,其泛化性能就越好。而且一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting。
但是对于两个模型,我们如何判断哪个模型的泛化性能更优呢?这里我们有主要以下两种方法:
如果模型A的ROC曲线完全包住了模型B的ROC曲线,那么我们就认为模型A要优于模型B;
如果两条曲线有交叉的话,我们就通过比较ROC与X,Y轴所围得曲线的面积来判断,面积越大,模型的性能就越优,这个面积我们称之为AUC(area under ROC curve)
但是读取数据时,数据的内存往往很大,因此需要函数来减少内存的使用
def reduce_mem_usage(df):
start_mem = df.memory_usage().sum()
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum()
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df 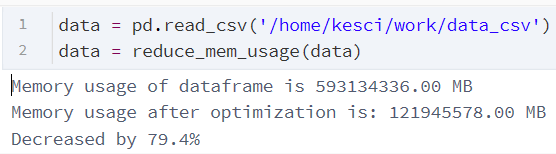

可以看到原来700mb的数据经过处理后仅占用100mb内存,内存降低了近80%。其理论可以发现将原来float64精度降为32,这种做法极大的节省了内存空间使用,但是这种方法在结构化问题中运用很不错,对于cv的化,这种做法可能对图像精度有一定影响,当然如果是混精度训练的化,也可能会有较大帮助。
Tips1:金融风控的实际项目多涉及到信用评分,因此需要模型特征具有较好的可解释性,所以目前在实际项目中多还是以逻辑回归作为基础模型。但是在比赛中以得分高低为准,不需要严谨的可解释性,所以大多基于集成算法进行建模。
"""对训练集数据进行划分,分成训练集和验证集,并进行相应的操作"""
from sklearn.model_selection import train_test_split
import lightgbm as lgb
# 数据集划分
X_train_split, X_val, y_train_split, y_val = train_test_split(X_train, y_train, test_size=0.2)
train_matrix = lgb.Dataset(X_train_split, label=y_train_split)
valid_matrix = lgb.Dataset(X_val, label=y_val)
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'learning_rate': 0.1,
'metric': 'auc',
'min_child_weight': 1e-3,
'num_leaves': 31,
'max_depth': -1,
'reg_lambda': 0,
'reg_alpha': 0,
'feature_fraction': 1,
'bagging_fraction': 1,
'bagging_freq': 0,
'seed': 2020,
'nthread': 8,
'silent': True,
'verbose': -1,
}
"""使用训练集数据进行模型训练"""
model = lgb.train(params, train_set=train_matrix, valid_sets=valid_matrix, num_boost_round=20000, verbose_eval=1000, early_stopping_rounds=200)使用lgb基础模型进行预测
未调参前lightgbm单模型在验证集上的AUC:0.7249469360631181import lightgbm as lgb
"""使用lightgbm 5折交叉验证进行建模预测"""
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(X_train, y_train)):
print('************************************ {} ************************************'.format(str(i+1)))
X_train_split, y_train_split, X_val, y_val = X_train.iloc[train_index], y_train[train_index], X_train.iloc[valid_index], y_train[valid_index]
train_matrix = lgb.Dataset(X_train_split, label=y_train_split)
valid_matrix = lgb.Dataset(X_val, label=y_val)
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'learning_rate': 0.1,
'metric': 'auc',
'min_child_weight': 1e-3,
'num_leaves': 31,
'max_depth': -1,
'reg_lambda': 0,
'reg_alpha': 0,
'feature_fraction': 1,
'bagging_fraction': 1,
'bagging_freq': 0,
'seed': 2020,
'nthread': 8,
'silent': True,
'verbose': -1,
}
model = lgb.train(params, train_set=train_matrix, num_boost_round=20000, valid_sets=valid_matrix, verbose_eval=1000, early_stopping_rounds=200)
val_pred = model.predict(X_val, num_iteration=model.best_iteration)
cv_scores.append(roc_auc_score(y_val, val_pred))
print(cv_scores)
print("lgb_scotrainre_list:{}".format(cv_scores))
print("lgb_score_mean:{}".format(np.mean(cv_scores)))
print("lgb_score_std:{}".format(np.std(cv_scores)))使用5折交叉验证后,模型的性能有所提升
...
lgb_scotrainre_list:[0.7303837315833632, 0.7258692125145638, 0.7305149209921737, 0.7296117869375041, 0.7294438695369077]
lgb_score_mean:0.7291647043129024
lgb_score_std:0.0016998349834934656模型调参也有很多方法,如贪心调参,网格搜索等