图片网站的选择
http://lab.scrapyd.cn/archives/55.html
分析网站
使用开发者工具进行分析网站
作者使用谷歌游览器开发工具
右键选择检查,定位到包含图片的盒子

- 对盒子进行分析
scrapy 关于对页面信息的定位,常用的方法有三种,css ,xpath,re。本文用css进行定位,如果有不了解以下三种定位,可以自己百度进行补充学习。
先试试盒子的class名字,使用ctrl和f调用find搜索class名字,是否有重复的,发现唯一,可以使用。这是一个偷懒的方法,因为我们最好是在源代码中分析,因为一些网页是动态加载的,使用检查看的是动态代码,而scrapy是基于静态代码分析的。那么问题来了,如何使用scrapy进行动态网页的分析呢,我们可以使用scrapy与selenium进行动态网页的分析,不过我们还是先进行静态页面的分析吧,学习要一步一步走。
- 对其中的元素进行提取
这里推荐一个css提取的网站
https://try.jsoup.org/
你可以使用把源代码复制到该网站,根据检查中网页结构使用css语法进行匹配
tip:ctrl+a实现全选,ctrl+c和ctrl+v大家都懂
.post-content 选择 class=“post-content” 的所有元素。
p 选择所有<p> 元素。 这里是post-content 中 p 的元素
img 选择所有<img> 元素 同理,是p中的元素
可以看见所有图片的地址在img的src属性中
有些网站会对爬虫进行反爬虫,比如设置referer,User-Agent,cookie等,不过这次爬取的网站是作为scrapy下载图片的实验站,没有进行反爬虫的设置。
项目
创建项目
网站分析完成,我们要新建项目scrapy startproject ImageSpider把项目导入pycharm
如图,ImgSpider.py是后建的
编辑itmes.py文件
item.py是配置爬虫具体返回的数据
既然我们要下载图片,肯定要得到图片的链接,也就是src里面的内容,因此我们需要定义一个item,用来存放图片链接import scrapy # 继承scrapy.item类 class ImagespiderItem(scrapy.Item): # Field类仅是内置字典类(dict)的一个别名,并没有提供额外的方法和属性。 # 被用来基于类属性的方法来支持item生命语法。 imgurl = scrapy.Field() pass创建蜘蛛文件ImgSpider.py
import scrapy # 导入itmes文件中ImagespiderItem类 from ImageSpider.items import ImagespiderItem class ImgspiderSpider(scrapy.Spider): name = 'ImgSpider' allowed_domains = ['lab.scrapyd.cn'] start_urls = ['http://lab.scrapyd.cn/archives/55.html'] # Spider的解析方法 def parse(self, response): item = ImagespiderItem() # 实例化item # 提取图片地址url # ::attr(src)获取src中的内容 imgurls = response.css(".post-content p img::attr(src)").getall() # 注意这里是一个集合也就是多张图片 item['imgurl'] = imgurls # 生成器 yield item pass图片下载中间件pipeline编写:
from scrapy import Request from scrapy.pipelines.images import ImagesPipeline class ImagespiderPipeline(ImagesPipeline): def get_media_requests(self, item, info): # 循环每一张图片地址下载,若传过来的不是集合则无需循环直接yield for image_url in item['imgurl']: yield Request(image_url)设置settings.py
#图片存储位置 IMAGES_STORE = 'D:\ImageSpider' #启动图片下载中间件 ITEM_PIPELINES = { 'ImageSpider.pipelines.ImagespiderPipeline': 300, }
项目启动
scrapy crawl ImgSpider
运行完成,我们下载的图片就在ImageSpider中了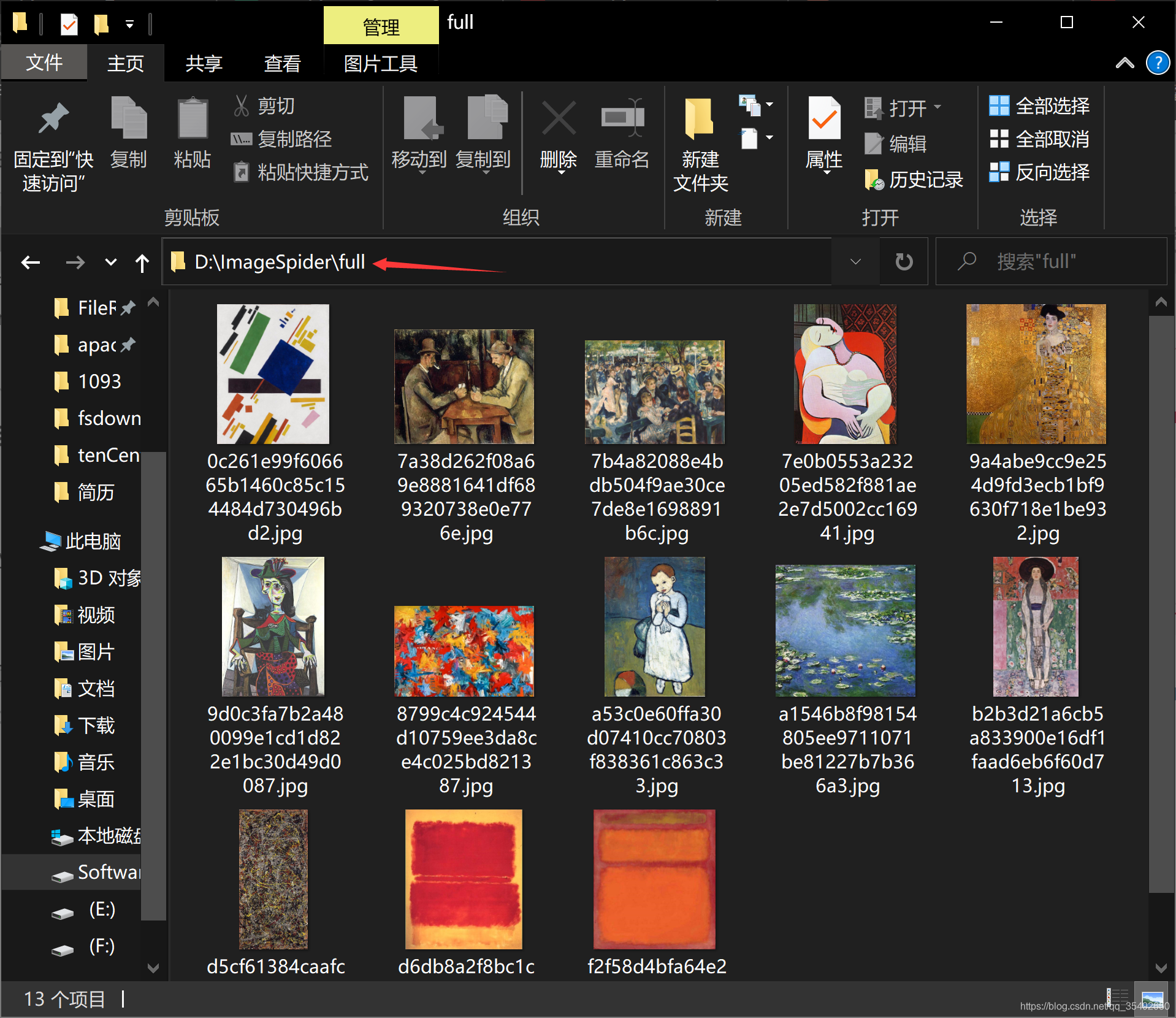
我们设置下载的文件夹是ImageSpider,为什么图片会在一个full文件夹里?
scrapy抓取图片时,通常情况下所有图片都会被保存到IMAGES_STORE指定路径下的full这个目录下
参考网站http://www.scrapyd.cn/example/174.html
版权声明:本文为qq_35492650原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。