springcloud常用组件
1、服务注册与发现:Eureka ---有nacos替换
2、服务网关: Zuul ---版本不更新,由 GateWay替换
3、服务负载均衡:Ribbon
4、服务之间调用:Feign
5、服务熔断:Hystrix ---因官网不继续维护,可以使用阿里提供的Alibaba Sentinel 轻量级的流量控制、熔断降级 Java 库
6、配置中心:config ---如果不想自己维护,可以使用阿里云nacos作为配置中心
7、服务链路追踪:Sleuth
8、链路日志服务:Zipkin ---Sleuth和Zipkin一起组合使用
(5)、服务熔断(Hystrix) :Hystrix的设计目的是将应用中的远程系统访问、服务调用、第三方依赖包的调用入口,通过资源控制的方式隔离开,避免了在分布式系统中失败的级联塌方式传递,提升系统的弹性和健壮性。
限流
设置信号量模式下的最大并发量、线程池大小、缓冲区大小和缓冲区降级阈值。在示例中我们作如下设置
资源隔离模式 ----配置请求隔离的方式,有 threadPool(线程池,默认)和 semaphore(信号量)
hystrix.command.default.execution.isolation.strategy=THREAD
核心线程池的大小,默认值是 10
hystrix.threadpool.default.coreSize=1
线程池缓冲区大小, 如果为-1,则不缓冲,直接进行降级 fallback
hystrix.threadpool.default.maxQueueSize=200
线程池缓冲区大小超限的阈值,超限就直接降级
hystrix.threadpool.default.queueSizeRejectionThreshold=199 --即便是maxQueueSize没有超过200个,只要过199就会被拒绝。
超时时间设置,默认1000毫秒
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=2000
线程池配置,如图所示: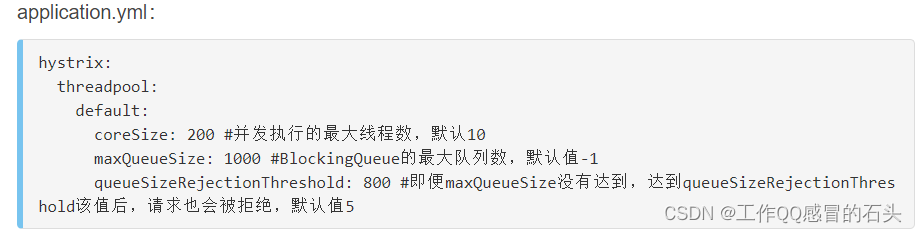
-------------------------------------------------------------------------------------------------------------------------------------------------------
信号量模式下,最大并发量
hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests=200
是一个绝对值,无时间窗口,相当于亚毫秒级的,指任意时间点允许的并发数。当请求达到或超过该设置值后,其其余就会被拒绝。默认值是100
熔断
在配置文件中我们开启了熔断,并且以5秒为度量周期,当5秒内请求超过4个错误超过50%时,就会开启熔断器,所有的请求都会直接降级,如果5秒内的请求不够4个,就算有三个请求且全部失败也不会开启熔断器。10秒后熔断器进入半打开状态会让一部分请求向服务端发起调用,如果成功关闭熔断器,否则再次进入熔断状态
如图所示: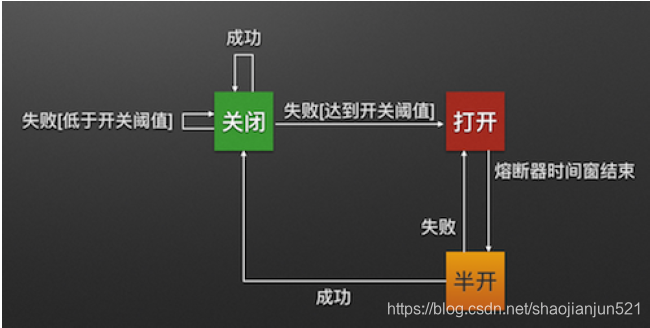
Open:熔断器打开状态,此时对下游的调用都内部直接返回错误,不走网络,但设计了一个时钟选项,默认的时钟达到了一定时间(这个时间一般设置成平均故障处理时间,也就是MTTR),到了这个时间,进入半熔断状态;
重点:意思是熔断器打开状态下,通过路由网关还是转发请求到熔断服务上,只不过返回友好报错信息而已,至于高可用状态需要设置
Half-Open:半熔断状态,允许定量的服务请求,如果调用都成功(或一定比例)则认为恢复了,关闭熔断器,否则认为还没好,又回到熔断器打开状态;
常用参数如下:
启用/禁用熔断机制 默认:true
hystrix.command.default.circuitBreaker.enabled=true
度量策略---5秒为一次统计周期,术语描述:滚动窗口的长度为5秒
hystrix.command.default.metrics.rollingStats.timeInMilliseconds=5000
错误百分比。达到或超过这个百分比,熔断器打开。 比如:5秒内有100请求,60个请求超时或者失败,就会自动开启熔断
hystrix.command.default.circuitBreaker.errorThresholdPercentage=50
前提条件,一定时间内发起一定数量的请求。 也就是5秒钟内(这个5秒对应下面的滚动窗口长度)至少请求30次,熔断器才发挥起作用。总数 默认20
hystrix.command.default.circuitBreaker.requestVolumeThreshold=30
10秒后,进入半打开状态(熔断开启,间隔一段时间后,会让一部分的命令去请求服务提供者,如果结果依旧是失败,则又会进入熔断状态,如果成功,就关闭熔断)。 默认5秒
hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds=10000
Spring Cloud Hystrix设计原理 - 简书
Hystrix原理与实战_漏水亦凡的专栏-CSDN博客_hystrix
https://blog.csdn.net/chenxyz707/article/details/80913725
Sentinel限流
Spring Cloud Gateway 整合阿里 Sentinel网关限流实战
网关如何限流?
Spring Cloud Gateway本身自带的限流实现,过滤器是RequestRateLimiterGatewayFilterFactory,不过这种上不了台面的就不再介绍了,有兴趣的可以实现下。
今天的重点是集成阿里的Sentinel实现网关限流,sentinel有不懂的可以看陈某的文章:阿里限流神器Sentinel夺命连环 17 问?
从1.6.0版本开始,Sentinel提供了SpringCloud Gateway的适配模块,可以提供两种资源维度的限流:
- route维度:即在配置文件中配置的路由条目,资源名为对应的
routeId,这种属于粗粒度的限流,一般是对某个微服务进行限流。 - 自定义API维度:用户可以利用Sentinel提供的API来自定义一些API分组,这种属于细粒度的限流,针对某一类的uri进行匹配限流,可以跨多个微服务。
sentinel官方文档:https://github.com/alibaba/Sentinel/wiki/网关限流
Spring Cloud Gateway集成Sentinel实现很简单,这就是阿里的魅力,提供简单、易操作的工具,让程序员专注于业务
新建项目
新建一个gateway-sentinel9026模块,添加如下依赖:
<!--nacos注册中心-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--spring cloud gateway-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!-- spring cloud gateway整合sentinel的依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-sentinel-gateway</artifactId>
</dependency>
<!-- sentinel的依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
注意:这依然是一个网关服务,不要添加WEB的依赖
配置文件
配置文件中主要指定以下三种配置:
- nacos的地址
- sentinel控制台的地址
- 网关路由的配置
配置如下:
spring:
cloud:
## 整合sentinel,配置sentinel控制台的地址
sentinel:
transport:
## 指定控制台的地址,默认端口8080
dashboard: localhost:8080
nacos:
## 注册中心配置
discovery:
# nacos的服务地址,nacos-server中IP地址:端口号
server-addr: 127.0.0.1:8848
gateway:
## 路由
routes:
## id只要唯一即可,名称任意
- id: gateway-provider
uri: lb://gateway-provider
## 配置断言
predicates:
## Path Route Predicate Factory断言,满足/gateway/provider/**这个请求路径的都会被路由到http://localhost:9024这个uri中
- Path=/gateway/provider/**
上述配置中设置了一个路由gateway-provider,只要请求路径满足/gateway/provider/**都会被路由到gateway-provider这个服务中。
限流配置
经过上述两个步骤其实已经整合好了Sentinel,此时访问一下接口:http://localhost:9026/gateway/provider/port
然后在sentinel控制台可以看到已经被监控了,监控的路由是gateway-provider,如下图:
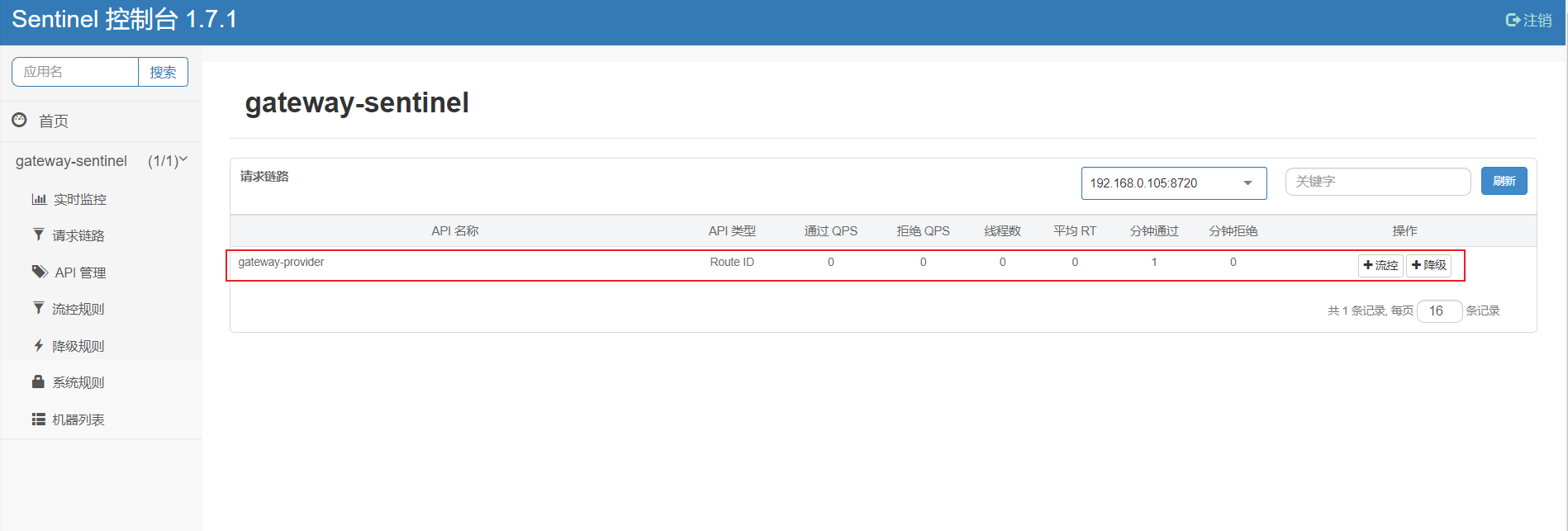
此时我们可以为其新增一个route维度的限流,如下图:
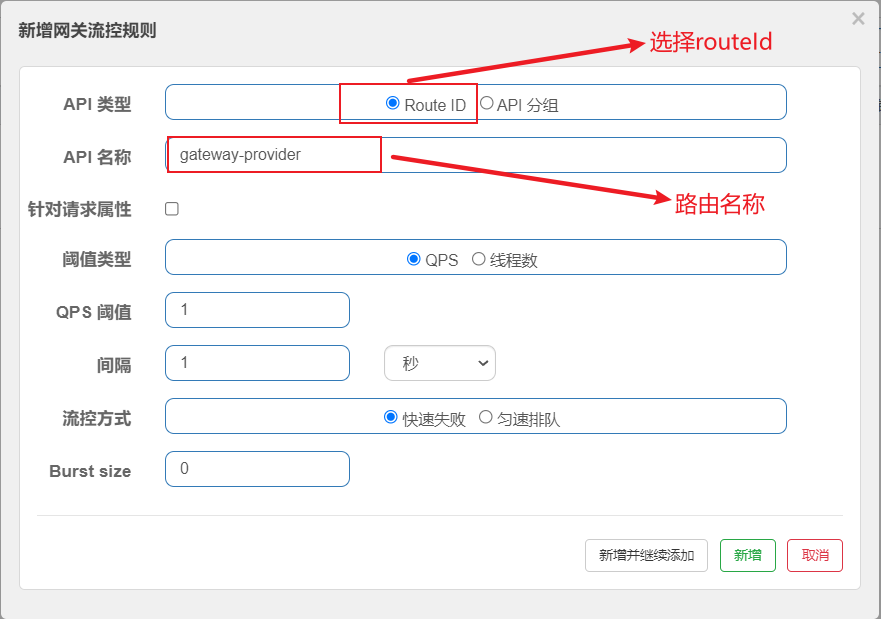
上图中对gateway-provider这个路由做出了限流,QPS阈值为1。
此时快速访问:http://localhost:9026/gateway/provider/port,看到已经被限流了,如下图:
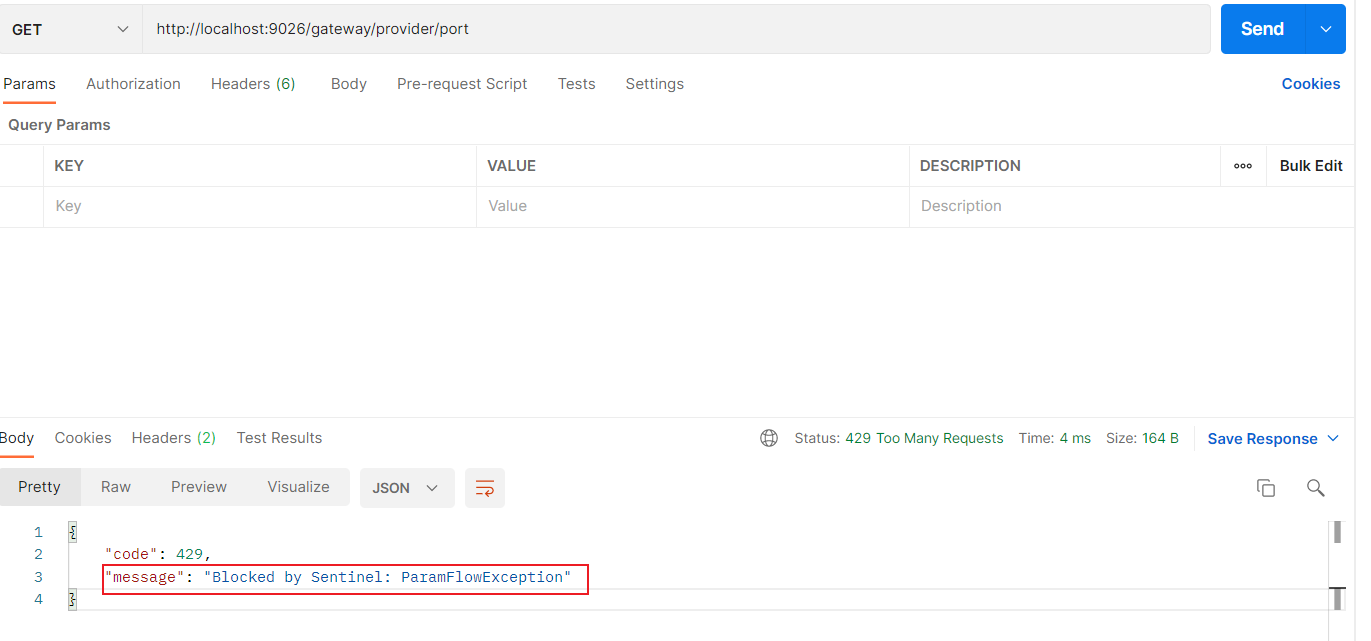
以上route维度的限流已经配置成功,小伙伴可以自己照着上述步骤尝试一下。
API分组限流也很简单,首先需要定义一个分组,API管理-> 新增API分组,如下图:
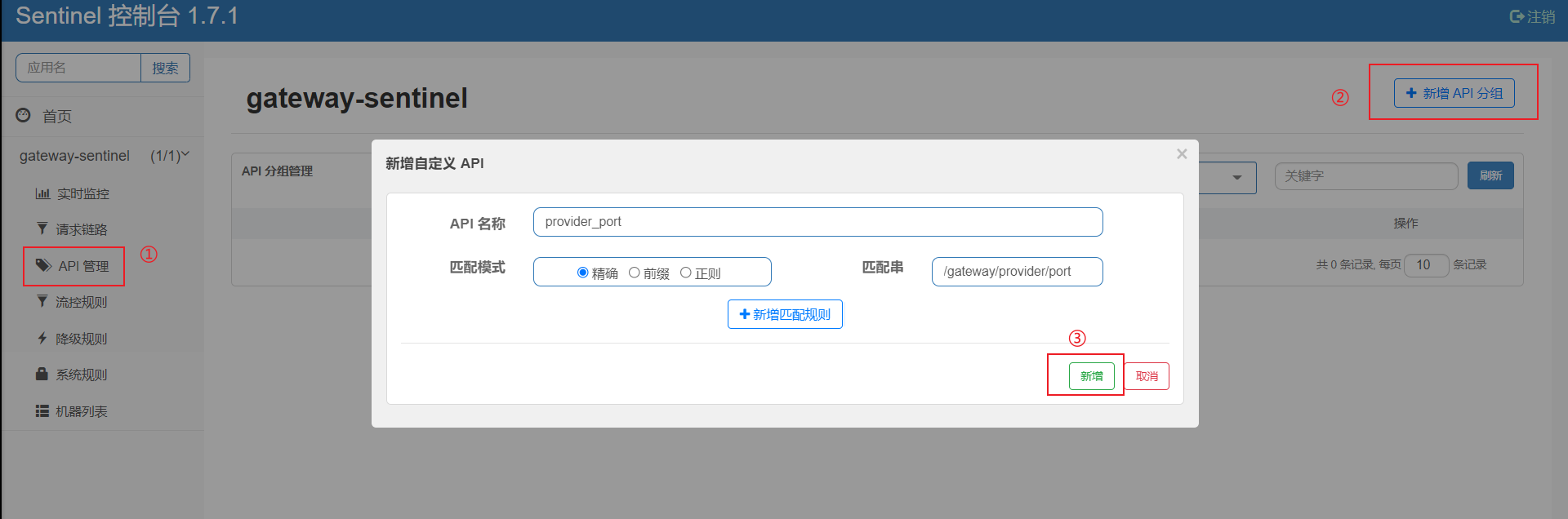
匹配模式选择了精确匹配(还有前缀匹配,正则匹配),因此只有这个uri:http://xxxx/gateway/provider/port会被限流。
第二步需要对这个分组添加流控规则,流控规则->新增网关流控,如下图:
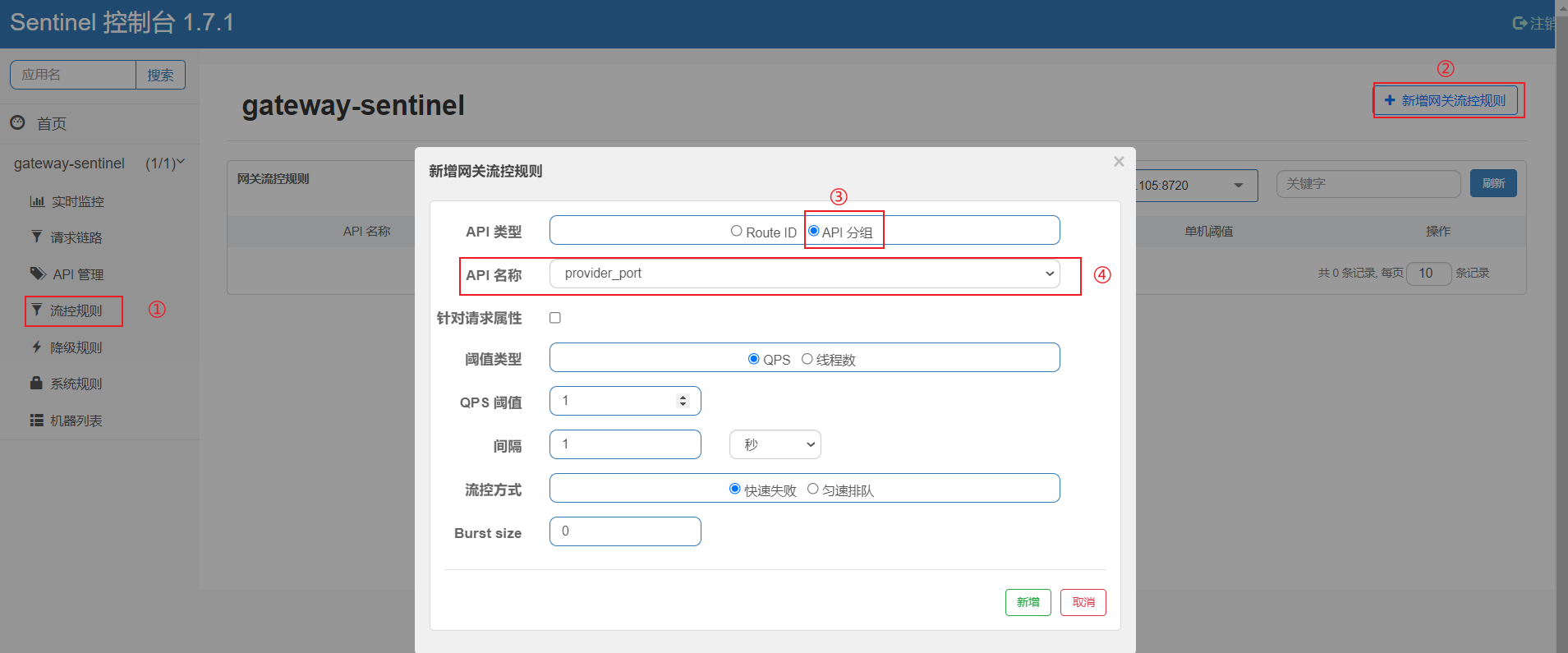
API名称那里选择对应的分组即可,新增之后,限流规则就生效了。
陈某不再测试了,小伙伴自己动手测试一下吧...............
陈某这里只是简单的配置一下,至于限流规则持久化一些内容请看陈某的Sentinel文章,这里就不再过多的介绍了。
如何自定义限流异常信息?
从上面的演示中可以看到默认的异常返回信息是:"Block.........",这种肯定是客户端不能接受的,因此需要定制自己的异常返回信息。
下面介绍两种不同的方式定制异常返回信息,开发中自己选择其中一种。
直接配置文件中定制
开发者可以直接在配置文件中直接修改返回信息,配置如下:
spring:
cloud:
## 整合sentinel,配置sentinel控制台的地址
sentinel:
#配置限流之后,响应内容
scg:
fallback:
## 两种模式,一种是response返回文字提示信息,
## 一种是redirect,重定向跳转,需要同时配置redirect(跳转的uri)
mode: response
## 响应的状态
response-status: 200
## 响应体
response-body: '{"code": 200,"message": "请求失败,稍后重试!"}'
上述配置中mode配置的是response,一旦被限流了,将会返回JSON串。
{
"code": 200,
"message": "请求失败,稍后重试!"
}
重定向的配置如下:
spring:
cloud:
## 整合sentinel,配置sentinel控制台的地址
sentinel:
#配置限流之后,响应内容
scg:
fallback:
## 两种模式,一种是response返回文字提示信息,一种是redirect,重定向跳转,需要同时配置redirect(跳转的uri)
mode: redirect
## 跳转的URL
redirect: http://www.baidu.com
一旦被限流,将会直接跳转到:http://www.baidu.com
编码定制
这种就不太灵活了,通过硬编码的方式,完整代码如下:
@Configuration
public class GatewayConfig {
/**
* 自定义限流处理器
*/
@PostConstruct
public void initBlockHandlers() {
BlockRequestHandler blockHandler = (serverWebExchange, throwable) -> {
Map map = new HashMap();
map.put("code",200);
map.put("message","请求失败,稍后重试!");
return ServerResponse.status(HttpStatus.OK)
.contentType(MediaType.APPLICATION_JSON_UTF8)
.body(BodyInserters.fromObject(map));
};
GatewayCallbackManager.setBlockHandler(blockHandler);
}
}
两种方式介绍完了,根据业务需求自己选择适合的方式,当然陈某更喜欢第一种,理由:约定>配置>编码。
网关限流了,服务就安全了吗?
很多人认为只要网关层面做了限流,躲在身后的服务就可以高枕无忧了,你是不是也有这种想法?
很显然这种想法是错误的,复杂的微服务架构一个独立服务不仅仅被一方调用,往往是多方调用,如下图:
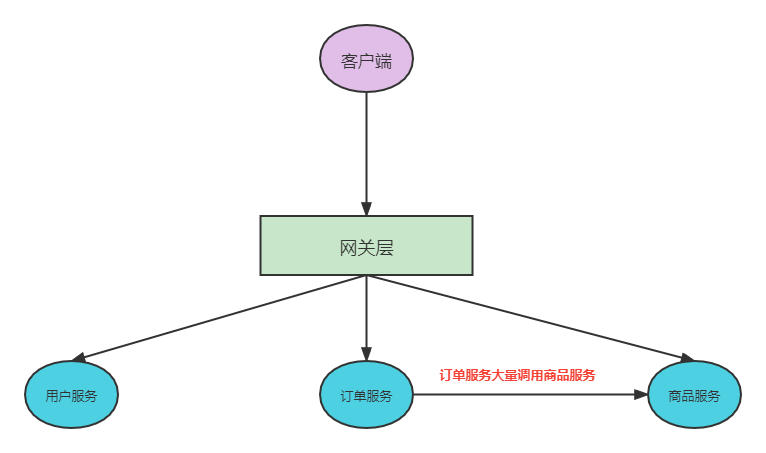
商品服务不仅仅被网关层调用,还被内部订单服务调用,这时候仅仅在网关层限流,那么商品服务还安全吗?
一旦大量的请求订单服务,比如大促秒杀,商品服务不做限流会被瞬间击垮。
因此需要根据公司业务场景对自己负责的服务也要进行限流兜底,最常见的方案:网关层集群限流+内部服务的单机限流兜底,这样才能保证不被流量冲垮。
可参考地址:Spring Cloud Gateway 整合阿里 Sentinel网关限流实战! - bucaichenmou - 博客园
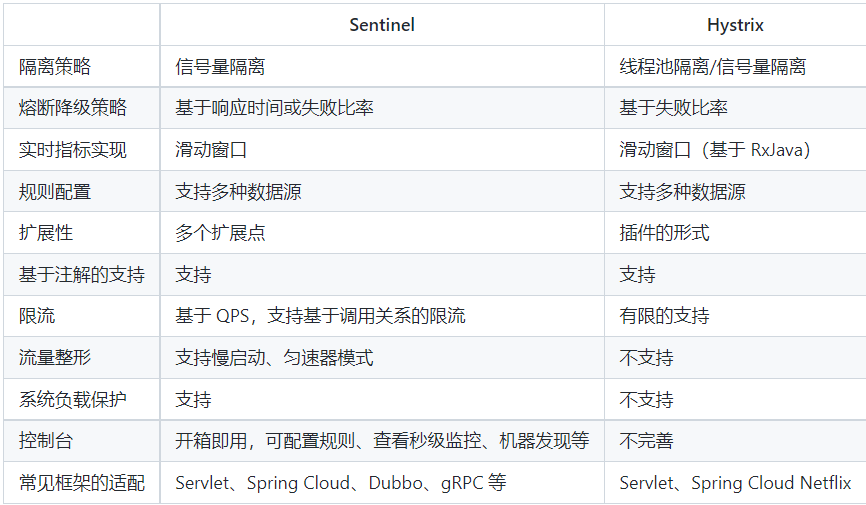
sentinel和Hystrix区别:
sentinel和nacos一样,都有一个控制台,但是这里不用自己手动搭建一个微服务,官方已经搭建好了,只需要下载对应得jar包运行即可。下载地址:https://github.com/alibaba/Sentinel/tags
可参考地址:阿里限流神器Sentinel夺命连环 17 问?
熔断降级配置
对调用链路中不稳定的资源进行熔断降级是保障高可用的重要措施之一。由于调用关系的复杂性,如果调用链路中的某个资源不稳定,最终会导致请求发生堆积。Sentinel 熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误。当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认行为是抛出 DegradeException)
降级策略
- 平均响应时间 (DEGRADE_GRADE_RT):当 1s 内持续进入 5 个请求,对应时刻的平均响应时间(秒级)均超过阈值(count,以 ms 为单位),那么在接下的时间窗口(DegradeRule 中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地熔断(抛出 DegradeException)。
- 异常比例 (DEGRADE_GRADE_EXCEPTION_RATIO):当资源的每秒请求量 >= 5,并且每秒异常总数占通过量的比值超过阈值(DegradeRule 中的 count)之后,资源进入降级状态。
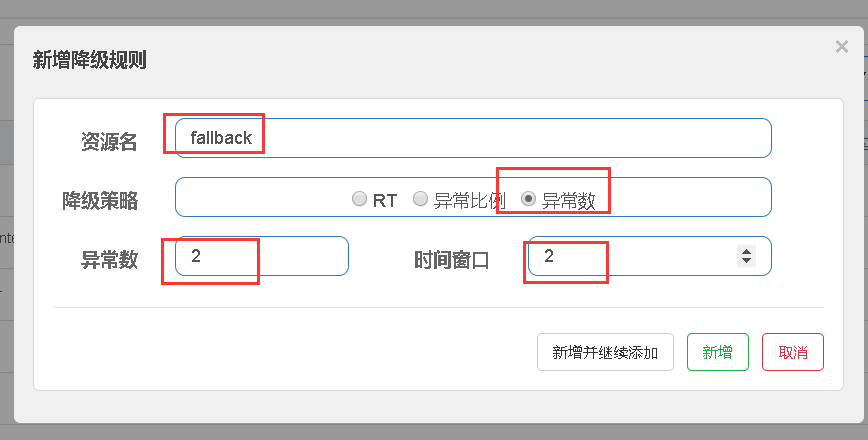
- 异常数 (DEGRADE_GRADE_EXCEPTION_COUNT):当资源近 1 分钟的异常数目超过阈值之后会进行熔断
如图所示:
案列
在
Spring Cloud Alibaba(一) 如何使用nacos服务注册和发现基础上,我们新建了ali-nacos-sentinel-feign项目,并调用ali-nacos-provider项目用作该示例的服务提供方,有以下二个项目做测试。
ali-nacos-provider:服务提供者,服务名:ali-nacos-provider,端口:9000
ali-nacos-sentinel-feign:服务消费者,服务名:ali-nacos-sentinel-feign,端口:9102
运行示例测试
首先要启动服务注册中心 nacos、ali-nacos-provider服务及ali-nacos-sentinel-feign服务
返回
我是服务提供者,见到你很高兴==>yuntian
表示我们的服务成功调用到了
- 关闭ali-nacos-provider服务,访问: http://localhost:9102/hello-feign/yuntian
返回服务调用失败,降级处理。异常信息:com.netflix.client.ClientException: Load balancer does not have available server for client: ali-nacos-provider
表示执行了我们预定的回调,服务成功降级了。
可参考地址如下:Spring Cloud Alibaba(三)Sentinel之熔断降级 - 云天 - 博客园
限流和熔断降级使用场景
限流:限流还是比较好理解,例如一个项目在上线之前经过性能测试评估,例如服务在 TPS 达到 1w/s 时系统资源利用率飙升,与此同时响应时间急剧增大,那我们就要控制该服务的调用TPS,超过该 TPS 的流量就需要进行干预,可以采取拒绝、排队等策略,实现流量的削峰填谷。
还有一个场景,例如一下开放平台,对接口进行收费,免费用户要控制调用TPS,账户的等级不同,允许调用的TPS也不同,这种情况就非常适合限流。
熔断降级:例如应用A 部署了3台机器,如果由于某种原因,例如线程池 hold 住,导致发送到它上面的请求会出现超时而报错,由于该进程并未宕机,请求还是会通过负载算法请求出现故障的机器,出现整个1/3的请求出现超时报错,影响整个系统的可用性?也就是其中一台故障会对整个服务质量产生严重的影响,虽然是集群部署,但无法达到高可用性。那如何解决该问题?如果在调用方(API-Center) 对异常进行统计,发现发往某一台机器的错误数或错误率达到设定的值,就在一定的世界间隔内不继续发往该机器,转而发送给集群内正常的节点,这样就实现了高可用,这就是所谓的熔断机制。