自转行入坑NLP炼丹2年以来,一直没有打过相关的比赛,究其原因一个是觉得自己NLP相关的积累太少了,参加比赛完全没有什么用;另外一方面是公司任务安排的比较多,又是自学工作任务处理起来就比较费时间,所有就没有多余的时间来打比赛了;最后就是稍微有些空闲的时间就用来休息谈恋爱呀娱乐呀学做饭呀以及学习写博客之类的。在新公司适应的比较快,项目也不是特别多,公司又有打比赛的需要,抓住机会参加了datafountain上面的几个比赛。我主要打了大奖赛中的产品评论观点提取和千言-问题匹配鲁棒性评测(提交一个初版就放弃了);训练赛中的法律领域篇章级多事件检测(多标签的分类任务)和机器翻译领域适应这4个比赛。最后的成绩是产品评论观点提取A榜12名,B榜16名,遗憾没有进入决赛;训练赛中法律领域篇章级多事件检测(多标签的分类任务)暂时第一名,机器翻译领域适应暂时第一名,示意如下。
产品评论观点提取
A榜
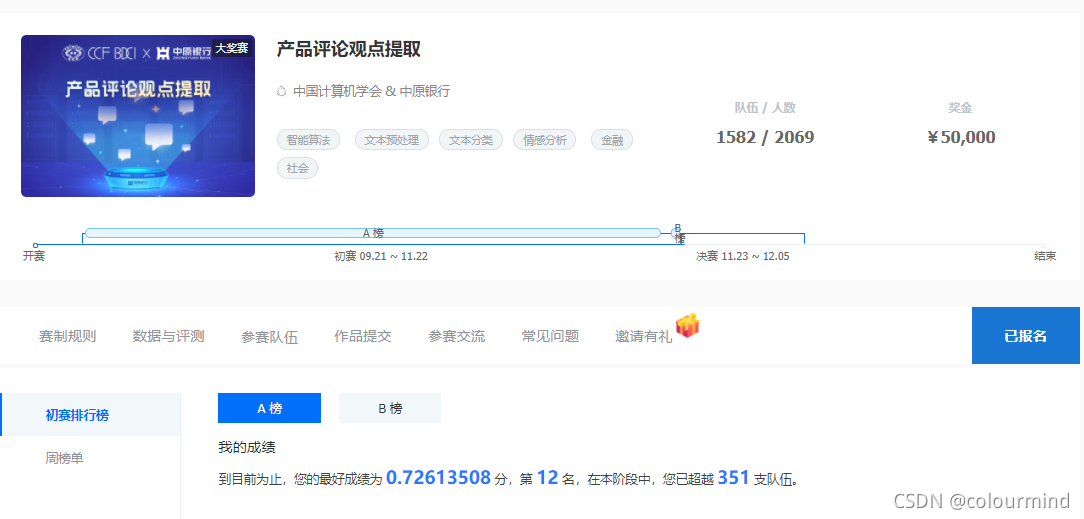
B榜
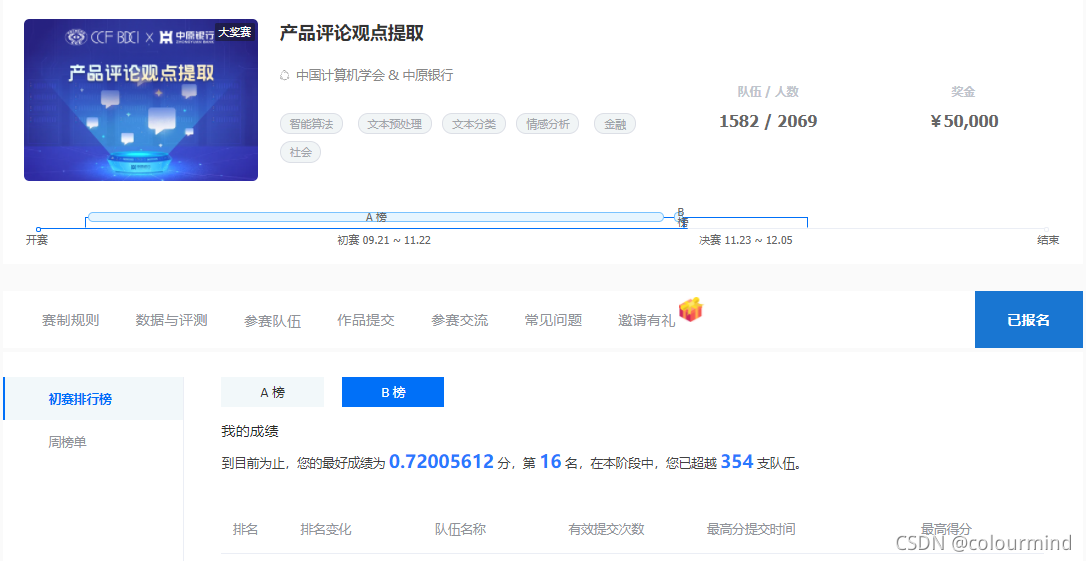
法律领域篇章级多事件检测(多标签分类任务)

训练赛截止日期是2021.12.06,法律领域篇章级多事件检测最终掉到了第四名,第一名的成绩是0.99663917,领先还是很多!
机器翻译领域适应

训练赛截止日期是2021.12.06,机器翻译领域适应最终经过9次提交一微弱的优势拿到了第一名,可以得到一个CCF会员名额和纪念奖牌。
成绩很差,也不太重要,重要的是在比赛过程中学习到的知识、经验和总结。
证书如下:
产品评论观点提取吧比赛

法律领域篇章级多事件检测(多标签分类任务)

机器翻译领域适应

一、赛题剖析和比赛中的尝试
A、产品评论观点提取比赛
比赛的任务分为单标签多分类任务和命名实体识别任务,举办方11.01提供了训练集和测试集,其中训练集约7500条,测试集约2800条。分类任务是一个单标签3分类任务,判定句子的消极、积极和中性等3中情感类别,比例8:3:64;NER任务就是提取句子中产品、评论实体、银行和评论形容词四种实体(PRODUCT、COMMENTS_N、BANK和COMMENTS_ADJ),其中COMMENTS_ADJ实体比例偏少。具体数据如下所示:
id,text,BIO_anno,class
0,交行14年用过,半年准备提额,却直接被降到1K,半年期间只T过一次三千,其它全部真实消费,第六个月的时候为了增加评分提额,还特意分期两万,但降额后电话投诉,申请提...,B-BANK I-BANK O O O O O O O O O O B-COMMENTS_N I-COMMENTS_N O O O O O B-COMMENTS_ADJ I-COMMENTS_ADJ O O O O O O O O O O O O O O O O O O O O O B-COMMENTS_N I-COMMENTS_N O O O O O O O O O O B-COMMENTS_N I-COMMENTS_N O O B-COMMENTS_N I-COMMENTS_N O O O O B-PRODUCT I-PRODUCT O O O O B-COMMENTS_ADJ O O O O O O O O O O O O O,0
1,单标我有了,最近visa双标返现活动好,B-PRODUCT I-PRODUCT O O O O O O B-PRODUCT I-PRODUCT I-PRODUCT I-PRODUCT B-PRODUCT I-PRODUCT B-COMMENTS_N I-COMMENTS_N I-COMMENTS_N I-COMMENTS_N B-COMMENTS_ADJ,1
2,建设银行提额很慢的……,B-BANK I-BANK I-BANK I-BANK B-COMMENTS_N I-COMMENTS_N B-COMMENTS_ADJ I-COMMENTS_ADJ O O O,0
3,我的怎么显示0.25费率,而且不管分多少期都一样费率,可惜只有69k,O O O O O O O O O O B-COMMENTS_N I-COMMENTS_N O O O O O O B-COMMENTS_ADJ I-COMMENTS_ADJ O O O O B-COMMENTS_N I-COMMENTS_N O B-COMMENTS_ADJ I-COMMENTS_ADJ B-COMMENTS_ADJ I-COMMENTS_ADJ O O O,2
4,利率不错,可以撸,B-COMMENTS_N I-COMMENTS_N B-COMMENTS_ADJ I-COMMENTS_ADJ O O O O,1
5,不能??好像房贷跟信用卡是分开审核的反正我的不得,O O O O O O O O O O O O O O O B-COMMENTS_N I-COMMENTS_N O O O O O O O,2
6,我感觉这样才是合理的,花呗白条没要那么多信息,照样可以给额度。有征信威慑,没那么多人敢借了不还。与其眉毛胡子一把抓,还不如按额度区间对客户进行不同程度的调查,免...,O O O O O O O B-COMMENTS_ADJ I-COMMENTS_ADJ O O B-PRODUCT I-PRODUCT B-PRODUCT I-PRODUCT O O O O O O O O O O O O O B-COMMENTS_N I-COMMENTS_N O O B-PRODUCT I-PRODUCT B-COMMENTS_ADJ I-COMMENTS_ADJ O O O O O O O O O O O O O O O O O O O O O O O O O O B-COMMENTS_N I-COMMENTS_N O O O O O O O O O O O O O O O O O O O,2
7,羡慕,可能上个月申请多了。上月连续下了浦发广发华夏交通。这个月申请建行,农业??邮储各种秒拒,买了点建行理财,3个月后在看...,O O O O O O O O O O O O O O O O O O O B-BANK I-BANK B-BANK I-BANK B-BANK I-BANK O O O O O O O O O O O O O O O O O O O O O O O O O O O B-PRODUCT I-PRODUCT O O O O O O O O O O,0
8,这个短债只是用来提升信誉刷建行预审批的,又不是什么赚钱的基金。也只有建行有卖,我买过,不但不赚钱还会亏本的。...,O O B-PRODUCT I-PRODUCT O O O O B-COMMENTS_ADJ I-COMMENTS_ADJ O O O B-BANK I-BANK B-COMMENTS_N I-COMMENTS_N I-COMMENTS_N O O O O O O O B-COMMENTS_ADJ I-COMMENTS_ADJ O B-PRODUCT I-PRODUCT O O B-COMMENTS_ADJ I-COMMENTS_ADJ B-BANK I-BANK O O O O O O O O O B-COMMENTS_ADJ I-COMMENTS_ADJ I-COMMENTS_ADJ O O B-COMMENTS_ADJ I-COMMENTS_ADJ O O O O O,0
9,打电话问中信信用卡为啥没批呗,O O O O B-BANK I-BANK B-PRODUCT I-PRODUCT I-PRODUCT O O O O O,2粗略来看这个比赛其实实现难度比较低的,分类和NER都是比较经典的NLP任务,当然竞争也比较大,同时比赛中没有组队,一个人既要调分类,又要调NER,时间比较紧迫,好多想法都没有来得及去尝试。
首先数据分析
统计句长,选定句长;分析噪声,删除噪声——原始数据中存在很多特殊字符等等
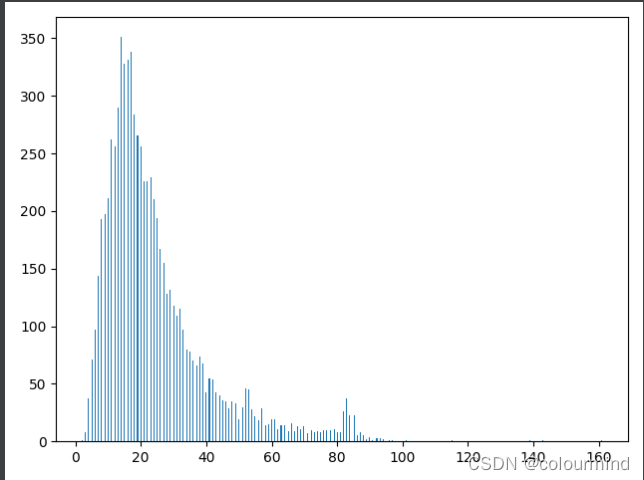
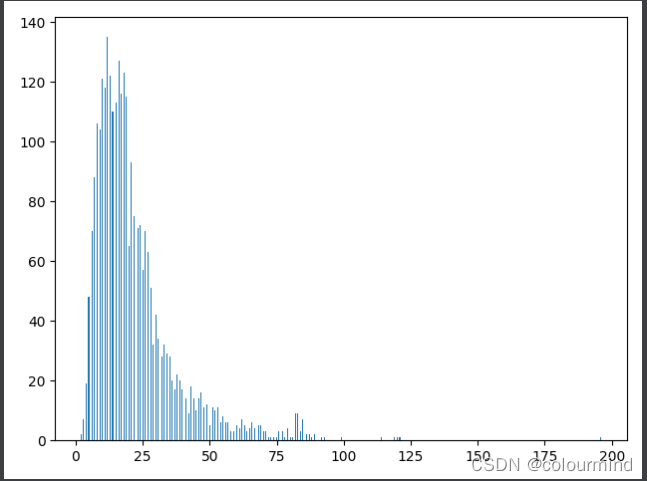
训练集和测试集中的句长大都集中在100以内,因此初始可以选用max_seq_length = 100
分类任务尝试的方案
简单的数据分析后,就是算法模型和调参了,尝试了以下方案
1、基本模型结构
Bert+nn.Linear
import torch.nn as nn
from transformers import BertModel,BertPreTrainedModel
import torch
import torch.nn.functional as F
class BertClassification(BertPreTrainedModel):
def __init__(self,config):
super(BertClassification, self).__init__(config)
self.bert = BertModel(config=config)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.dropouts = nn.ModuleList([nn.Dropout(0.2) for _ in range(5)])
# self.lcm = LCM(config.num_labels,config.hidden_size)
def pooling(self,token_embeddings,input):
output_vectors = []
# attention_mask
attention_mask = input['attention_mask']
# [B,L]------>[B,L,1]------>[B,L,768],矩阵的值是0或者1
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
# 这里做矩阵点积,就是对元素相乘(序列中padding字符,通过乘以0给去掉了)[B,L,768]
t = token_embeddings * input_mask_expanded
# [B,768]
sum_embeddings = torch.sum(t, 1)
# [B,768],最大值为seq_len
sum_mask = input_mask_expanded.sum(1)
# 限定每个元素的最小值是1e-9,保证分母不为0
sum_mask = torch.clamp(sum_mask, min=1e-9)
# 得到最后的具体embedding的每一个维度的值——元素相除
output_vectors.append(sum_embeddings / sum_mask)
# 列拼接
output_vector = torch.cat(output_vectors, 1)
return output_vector
def forward(self,inputs):
"""
:param inputs: 字典tensor,input_ids,attention_mask,token_type_ids
:return:
"""
output = self.bert(**inputs, return_dict=True, output_hidden_states=True)
embedding = output.hidden_states[-1]
embedding = self.pooling(embedding,inputs)
for i, dropout in enumerate(self.dropouts):
if i == 0:
h = self.classifier(dropout(embedding))
else:
hi = self.classifier(dropout(embedding))
h = h + hi
logists = h/len(self.dropouts)
return logists,embedding
class LCM(nn.Module):
def __init__(self,num_labels,hidden_size):
super(LCM,self).__init__()
self.label_embeding = nn.Embedding(num_labels,hidden_size)
def forward(self,token_embedding,labels):
sim = torch.matmul(token_embedding, labels.T)
labels = F.softmax(sim, dim=-1)
return labels
当然为了减少过拟合的风险也是可以采用Bert+dropout+nn.Linear这样的结构
baseline采用哈工大的bert预训练权重bert-wmm-ext
Bert+dropout+nn.Linear相比Bert+nn.Linear有提升
2、损失函数
cross_entropy、LabelSmoothingLoss和FocalLoss,其中LabelSmoothingLoss提升较大,缓解了样本不均衡
3、对比学习R-drop,提升明显
4、滑动平均ema 无提升
5、标签调整logit adjustment——Long-Tail Learning via Logit Adjustment 谷歌论文新方法 没有效果
6、标签混淆模型 label confusion model——Label Confusion Learning to Enhance Text Classification Models 无提升
7、梯度裁剪——防止梯度爆炸的作用
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
无提升
8、对抗训练——embedding层进行扰动
FGM/PGD/FreeLB/SMART
仅验证了FGM和PGD,PGD提升更大,训练时间更多
9、半监督训练
测试集预测以后,选择预测概率大于一定阈值的样本,加入训练集中再训练;标准的做法是给测试集样本在训练的时候设定一个loss的参数
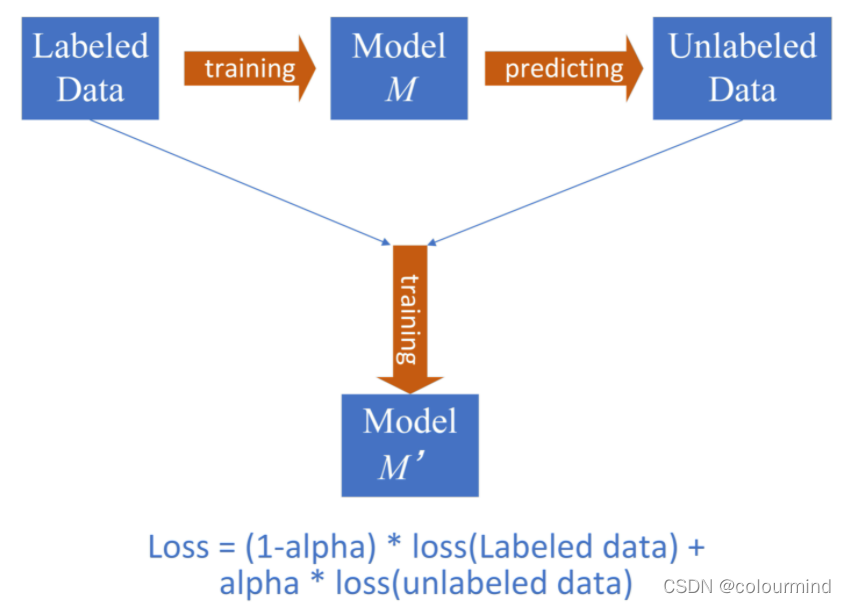
实现比较麻烦,直接抽样加入更简单
10、多折交叉验证
3579折交叉验证——5折效果最好,融合的方式可以考虑概率融合也可以采取投票方式
11、多模型融合
采用不同的随机种子、不同的预训练权重,例如bert、roberta、ernie、nezha等多模型融合——时间来不及未验证
12、继续预训练——数据量小不建议采取,时间来不及未验证
13、数据增强也没有验证——回译、同义词替换、随机drop等,回译按照经验来说是有效的
比赛过程中的记录

NER任务尝试的方案
NER任务算是比较成熟了,嵌套实体、词汇及增强在最新的论文中都有一定的解决方案了;由于时间有限,本次比赛仅仅参考了Chinese-DeepNER-Pytorch——天池中药说明书实体识别挑战冠军方案的思路和CLUENER 细粒度命名实体识别给出的基线代码,快速的实现了NER任务,具体方案
1、bert+crf

如图验证了 半监督、对抗训练、dropout、和多折交叉验证(概率融合+投票)
2、bert+span
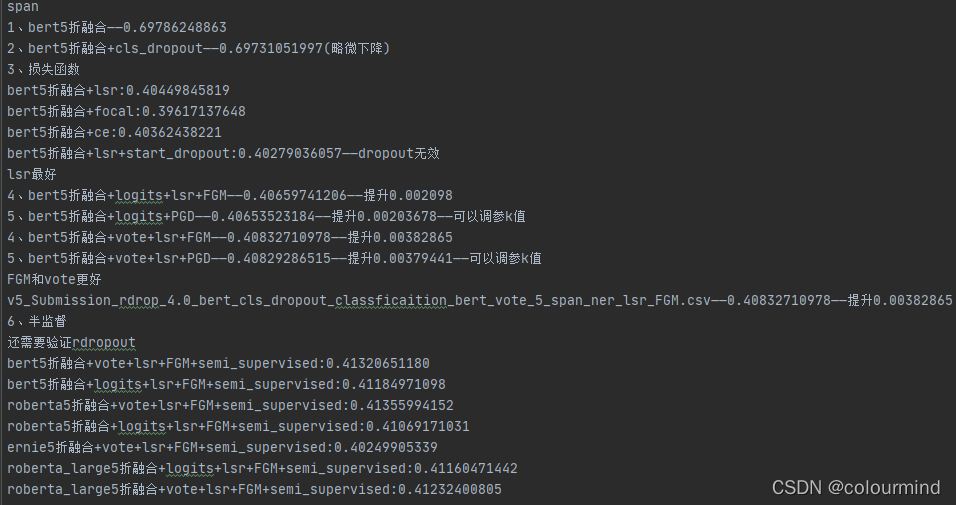
如图验证了 半监督、对抗训练、dropout、和多折交叉验证(概率融合+投票) 、不同的损失函数(labelsmoothloss效果最好,这里缓解了实体的不均衡分布)
3、bert+softmax
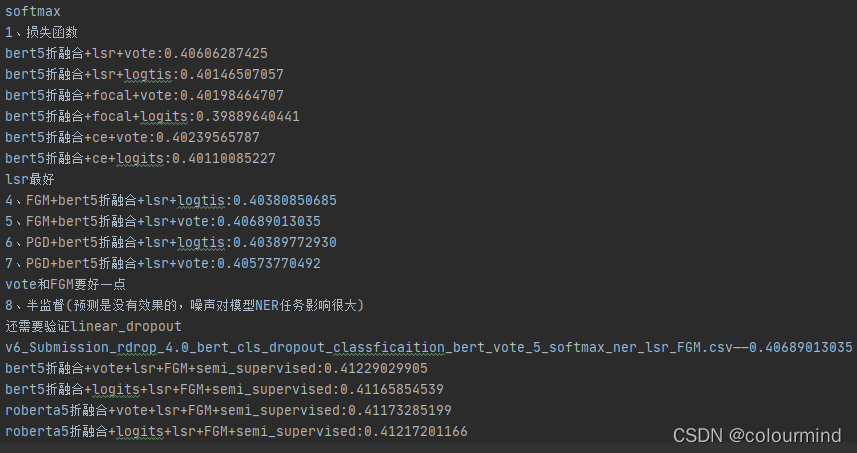
如图验证了 半监督、对抗训练、dropout、和多折交叉验证(概率融合+投票) 、不同的损失函数
由于时间有限,并没有验证MRC和邱锡鹏教授组的FLATNer,也没有验证滑动平均,最后选取以上3个模型最佳效果做投票融合作为最终提交结果
B、法律领域篇章级多事件检测——多标签分类任务
之所以想打这个比赛,主要之前没有做过多标签的分类任务,对相关的真实业务场景和算法进行过实战,并不清楚算法的效果如何。在之前的一篇博客——NLP分类任务中的损失函数的选择——中写到过对于多标签分类任务的一些分析,这里算是一个精细的实战操作。
数据分析
数据质量比较好,并没有噪声,只是句长很长,大部分都是在500以内,句子500之外甚至5000的都有几条,鉴于比例非常小,直接把这部分数据舍弃掉。最后max_length = 512
首先模型的结构
1、bert+nn.linear+BCEloss
2、bert+nn.linear+MLCE(苏剑林——将“softmax+交叉熵”推广到多标签分类问题)
经过验证2效果更好,训练模型收敛速度更快,最后提交的结果更好。
其他的方案尝试
1、模型训练的时候评价指标选用最佳准确率的模型保存,提交的结果要好于使用mico-f1,虽然评测结果是mico-f1
2、R-drop参数alpha 1、2、4、8 均没有不采用R-drop的效果好
3、多折交叉验证3折和7折均没有5折好;
4、对抗训练验证了FGM/PGD/FreeLB,FGM效果最佳——还没有验证SMART
5、融合策略——投票优于概率融合,投票的阈值设置也是需要调试的
6、ema滑动平均很有效果,上个比赛的使用可能出现了问题
ema.apply_shadow()之后验证模型,保存最佳模型
循环迭代的时候没有执行
ema.restore()#恢复权重系数
每个epoch训练的模型都是在上一个滑动平均改变系数后的模型,导致模型的系数变动过大,效果不好,比较科学的用法如下,注意一定要ema.restore(),我在上一个比赛的时候还故意不使用ema.restore(),效果不太好,当时分析有问题
for epoch in epochs:
for batch in dataloader:
....
loss.backforward()
optimizer.zero_grad()
optimizer.step()
ema.update()
ema.apply_shadow()
model.eval()
#模型评估
evaluate()
#保存最佳的那个模型
model.save()——————这里模型就是保存的影子权重
ema.restore()————————这里又恢复模型参数,这一步做了效果好一些,没有做导致模型参数变化过大
......
#模型推理——由于保存的是影子权重所以没有问题
model.eval()
test(model)7、对比学习的思想
batch内增加样本数,由于同样的样本数据,在一个batch内有2条,经过bert类的模型输出向量不一致,增加了模型的泛化能力和鲁棒性。具体实现是直接在batch内copy一下数据
#batch:list t:tensor
if args.double_copy:
batch = [ t.repeat(2,1) for t in batch]8、模型输出后dropout
并没有效果,可能和对抗训练冲突了
9、多次迭代半监督训练
不断的修正预测的结果,和训练集一并训练模型,模型指标不断上升
10、数据量小,继续预训练没有提升
11、多种预训练权重尝试
具体尝试结果记录
1、v0_submition_MLCE_L512_rdrop4_logits_integrate.json——0.95749170938
2、v1_submition_MLCE_L512_rdrop0_logits_integrate.json——0.94833185710
3、v2_submition_MLCE_L512_rdrop2_logits_integrate.json——0.94275700935
4、v2_submition_MLCE_L512_rdrop2_vote_integrate.json——0.95243757432
5、v3_submition_MLCE_L512_rdrop0_logits_integrate.json——0.92826274849
6、v3_submition_MLCE_L512_rdrop0_vote_integrate.json——0.95147365287
7、v3_submition_MLCE_L512_rdrop0_logits_integrate_max3.json——0.94855115316
8、v3_submition_MLCE_L512_rdrop0_vote_integrate_max3.json——0.94814378315
模型训练的时候采用准确率验验证更好!——不要用micro_f1
0、v0_submition_MLCE_L512_rdrop_0_RRL_scheduler_vote_integrate_max_all_20211114.json——0.96883509834、第一名最佳
1、v0_submition_MLCE_L512_rdrop_0_RRL_scheduler_logits_integrate_max_all_20211114.json——0.96514423077——低很多
2、v0_submition_MLCE_L512_rdrop_0_RRL_scheduler_vote_integrate_max3_20211114.json——0.96628537026——低一点点
3、v0_submition_MLCE_L512_rdrop_0_RRL_scheduler_logits_integrate_max3_20211114.json——0.96739130——低一点点
4、v1_submition_MLCE_L512_rdrop_0_linear_dropouts_RRL_scheduler_logits_integrate_max_5_20211115.json——0.96508127635——linear_dropouts无效
5、v1_submition_MLCE_L512_rdrop_0_linear_dropouts_RRL_scheduler_vote_integrate_max_5_20211115.json——0.96668685645——linear_dropouts无效
6、v2_submition_MLCE_L512_rdrop_4_RRL_scheduler_vote_integrate_max_5_20211115.json——0.96840826245、第二名rdrop-4无效
7、v2_submition_MLCE_L512_rdrop_4_RRL_scheduler_logits_integrate_max_5_20211115.json——0.96566265060、logits比vote差
8、v3_submition_MLCE_L512_rdrop_2_RRL_scheduler_vote_integrate_max_5_20211115.json——0.96783980583
9、v3_submition_MLCEL512_rdrop_2_RRL_scheduler_logits_integrate_max_5_20211115.json——0.96452194829
6789来看可以增大alpha的参数来提高性能
10、v4_submition_MLCE_L512_rdrop_8_RRL_scheduler_vote_integrate_max_5_20211115.json——0.96785930867提升一点 还是r_drop = 0最佳
11、v4_submition_MLCE_L512_rdrop_8_RRL_scheduler_vote_integrate_max_3_20211115.json——0.96443640
12、v4_submition_MLCEL512_rdrop_8_RRL_scheduler_logits_integrate_max_3_20211115.json——0.96466324
13、v4_submition_MLCEL512_rdrop_0_RRL_scheduler_FGM_logits_integrate_max_5_20211115.json——0.96566
14、v4_submition_MLCE_L512_rdrop_0_RRL_scheduler_FGM_vote_integrate_max_5_20211115.json——0.96964177292——第一名
15、v5_submition_MLCEL512_rdrop_0_RRL_scheduler_PGD_logits_integrate_max_5_20211115.json——0.96597410419
16、v5_submition_MLCEL512_rdrop_0_RRL_scheduler_PGD_vote_integrate_max_5_20211115.json——0.96962332928——第二名
17、v6_submition_BCE_L512_rdrop_0_RRL_scheduler_FGM_logits_integrate_max_5_20211116.json——0.96327513546
18、v6_submition_BCE_L512_rdrop_0_RRL_scheduler_FGM_vote_integrate_max_5_20211116.json——0.96750683268
15-18来看BCE效果不好、FGM对抗训练更好,vote策略更好
半监督训练
19、v7_submition_MLCE_L512_rdrop_0_RRL_scheduler_semi_supervised_0_FGM_logits_integrate_max_5_20211116.json——0.96821071753
20、v7_submition_MLCE_L512_rdrop_0_RRL_scheduler_semi_supervised_0_FGM_vote_integrate_max_5_20211116.json——0.97019464720——第一名最高,加入prediact_result_BCE_0.csv概率大于0.9的样本
21、v8_submition_MLCE_L512_rdrop_0_RRL_scheduler_semi_supervised_1FGM_logits_integrate_max_5_20211116.json——0.97017650639——第二名,加入prediact_result_MLCE_vote_2.csv概率大于0.8的样本
22、v8_submition_MLCE_L512_rdrop_0_RRL_scheduler_semi_supervised_1FGM_vote_integrate_max_5_20211116.json——0.97074954296——第一名最高,加入prediact_result_MLCE_vote_2.csv概率大于0.8的样本
7折验证
23、v9_submition_MLCE_L512_rdrop_0_RRL_scheduler_FGM_logits_integrate_max_5_20211122.json——0.96282973621 < 0.96566 v4_submition_MLCEL512_rdrop_0_RRL_scheduler_FGM_logits_integrate_max_5_20211115.json
24、v9_submition_MLCE_L512_rdrop_0_RRL_scheduler_FGM_vote_integrate_max_5_20211122.json——0.96701966717 < 0.96964177292 v4_submition_MLCE_L512_rdrop_0_RRL_scheduler_FGM_vote_integrate_max_5_20211115.json
25、v9_submition_MLCE_L512_rdrop_0_RRL_scheduler_FGM_logits_integrate_max_7_20211122.json——0.96456456456 < 0.96566 v4_submition_MLCEL512_rdrop_0_RRL_scheduler_FGM_logits_integrate_max_5_20211115.json
26、v9_submition_MLCE_L512_rdrop_0_RRL_scheduler_FGM_vote_integrate_max_7_20211122.json——0.96768347931 < 0.96964177292 v4_submition_MLCE_L512_rdrop_0_RRL_scheduler_FGM_vote_integrate_max_5_20211115.json
7折无效
3折验证
27、v10_submition_MLCE_L512_rdrop_0_RRL_scheduler_FGM_logits_integrate_max_3_20211123.json——0.96047904192 < 0.96566
28、v10_submition_MLCE_L512_rdrop_0_RRL_scheduler_FGM_vote_integrate_max_3_20211123.json——0.96107784431 < 0.96964177292
3折无效
ema验证decay=0.999
29、v11_submition_MLCE_L512_rdrop_0_RRL_scheduler_FGM_vote_integrate_vote_alpha_0.6_max_5_20211123.json 0.97174111212 > 0.96964177292 提升明显
30、v11_submition_MLCE_L512_rdrop_0_RRL_scheduler_FGM_vote_integrate_vote_alpha_0.6_max_3_20211123.json 0.96649562330 < 0.96964177292 未提升
vote = 0.6
ema 有效
31、v11_submition_MLCE_L512_rdrop_0_RRL_scheduler_FGM_vote_integrate_vote_alpha_0.8_max_5_20211123.json 0.97055215 < 0.97174111212
vote 0.8 效果没有 0.6好
以上bs = 8 ; max_len = 512
序列长度验证
数据处理——训练集中把长于600的数据直接丢弃 max_len = 384
32、v12_submition_MLCE_L384_rdrop_0_RRL_scheduler_FGM_vote_integrate_vote_alpha_0.6_max_5_20211123.json 0.96489104116 < 0.97174111212
无效 下降蛮多
预训练验证
33、v13_submition_MLCE_L512_rdrop_0_RRL_scheduler_FGM_vote_integrate_vote_alpha_0.6_max_5_pretrained_20211123.json 0.96883509834 < 0.97174111212
下降蛮多,无效,也有可能是预训练出了问题没有预训练好
dropout验证
34、v14_submition_MLCE_L512_rdrop_0_RRL_scheduler_FGM_vote_integrate_vote_alpha_0.6_max_5_dropout_20211123.json 0.97028502122 < 0.97174111212
可能是dropout和FGM对抗训练冲突了
roberta
35、v15_roberta_submition_MLCE_L512_rdrop_0_RRL_scheduler_FGM_vote_integrate_vote_alpha_0.6_max_5_20211123.json 0.97014015844 < 0.97174111212
看情况拿来融合
半监督验证
把20211124_prediact_result_MLCE_vote_0.csv > 0.9的样本加入训练集中 模型bert
36、v16_bert_submition_MLCE_L512_rdrop_0_RRL_scheduler_semi_supervised_FGM_vote_integrate_vote_alpha_0.6_max_5_20211124.json 0.97289064880 > 0.97174111212 第一名
把20211124_prediact_result_MLCE_vote_1.csv > 0.8的样本加入训练集中 模型bert
37、v17_bert_submition_MLCE_L512_rdrop_0_RRL_scheduler_semi_supervised_1_FGM_vote_integrate_vote_alpha_0.6_max_5_20211124.json 0.97343511450 > 0.97289064880 第一名
roberta/ernie验证
把20211124_prediact_result_MLCE_vote_1.csv > 0.8的样本加入训练集中 模型roberta
38、v18_roberta_submition_MLCE_L512_rdrop_0_RRL_scheduler_semi_supervised_1_FGM_vote_integrate_vote_alpha_0.6_max_5_20211124.json 0.97251069029 < 0.97343511450
感觉可以拿来融合
39、v19_ernie_submition_MLCE_L512_rdrop_0_RRL_scheduler_semi_supervised_1_FGM_vote_integrate_vote_alpha_0.6_max_5_20211124.json 0.97158570119 < 0.97174111212
感觉有点差不过也可以拿来融合 如果效果不好 可以用bert模型多跑几个不同的随机种子融合
双份数据验证——batch内复制
40、v20_bert_submition_MLCE_L512_rdrop_0_RRL_scheduler_semi_supervised_1_double_copy_FGM_vote_integrate_vote_alpha_0.6_max_5_20211124.json 0.97406164175 > 0.97343511450
batch内复制有效——借助SIMCSE对比学习的思想
对抗学习 FreeLB对比FGM验证 FGM最佳 0.97343511450
41、v21_bert_submition_MLCE_L512_rdrop_0_RRL_scheduler_semi_supervised_1_FreeLB_vote_integrate_vote_alpha_0.6_max_5_20211125.json 0.97317073171 < 0.97343511450
无效 FGM > FreeLBC、机器翻译领域适应
这是一个多领域数据的中文到英文的机器翻译任务,机器翻译目前来说采用神经网络来做翻译算是比较成熟了。NMT一般都是采用transformer——seq2seq,encoder和decoder的架构;一般是有6层;单语训练的预训练模型bert权重等可以在NMT上提升一个bleu;基本的一些知识理论就是transformer block的理解了,pre-layernorm、post-layernorm 、FFN 、attention机制、解码和编码器采用的词表是采用独立的还是采用统一的(个人理解统一的代码实现起来工作量少,所有大都采用统一的词表)、解码策略(greedy search;beam serach;top-K;top-P等)。项目中完全没有接触过翻译,这个比赛正好可以来学习一下。
直接采用huggingface transformers中的机器翻译 translation支持如下生成类模型:

这里采用MarianMTModel,可以找到基于双语平行语料训练的模型。
比赛提供的训练数据如下:
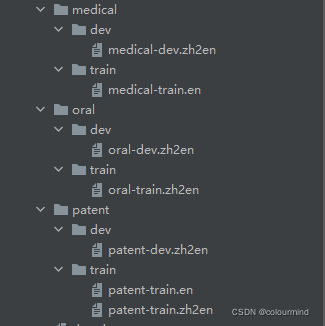
3个领域的双语平行语料,还有一部分单语语料,赛题的意图应该就是要参赛者充分的利用平行双语料来训练模型,同时把单语料也要利用起来,做数据增强。其他的一些方法比如对抗训练、半监督训练等也能提点,当然也有基础双语预训练模型的选取,后处理也是可以考虑进来的。
单语料怎么利用起来?
根据论文Exploiting Monolingual Data at Scale for Neural Machine Translation以及知乎文章大规模利用单语数据提升神经机器翻译可以得到一些提升BLEU的方案,文章中给出的方案流程如下:
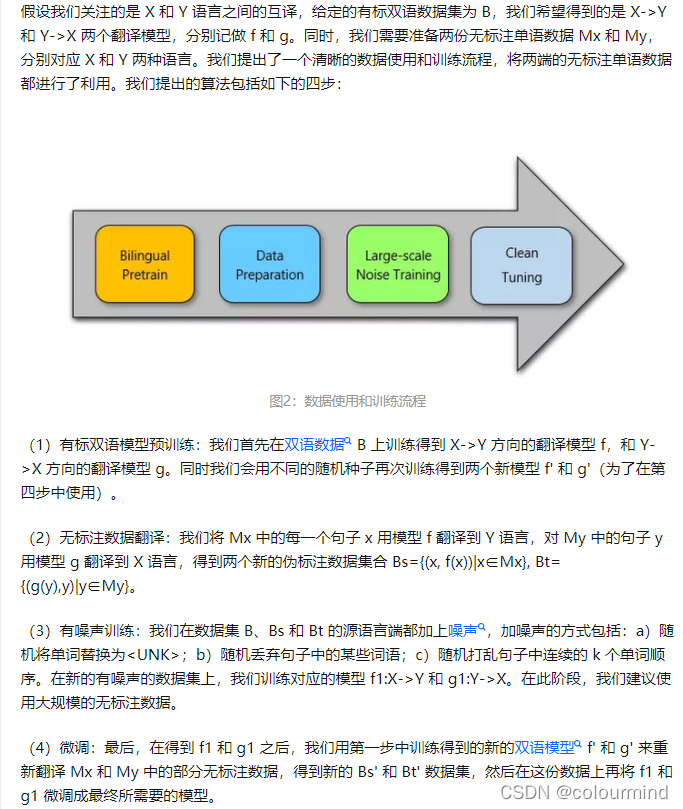
简单来说就是把单语料模型用平行语料训练好的模型翻译后,作为新的数据集添加到训练集中,给这个新的数据集源语言端添加部分噪声,训练出一个新的模型,以这个模型作为基础然后再之前的部分数据集(有一定的技巧和细节)上做微调。
这个任务数据量适中,平行语料28W、单语料30W;采用3090单卡来训练平行语料8个epoch大概需要13个小时,所以这个比赛设备也很关键!看一张图,训练英语到中文的模型
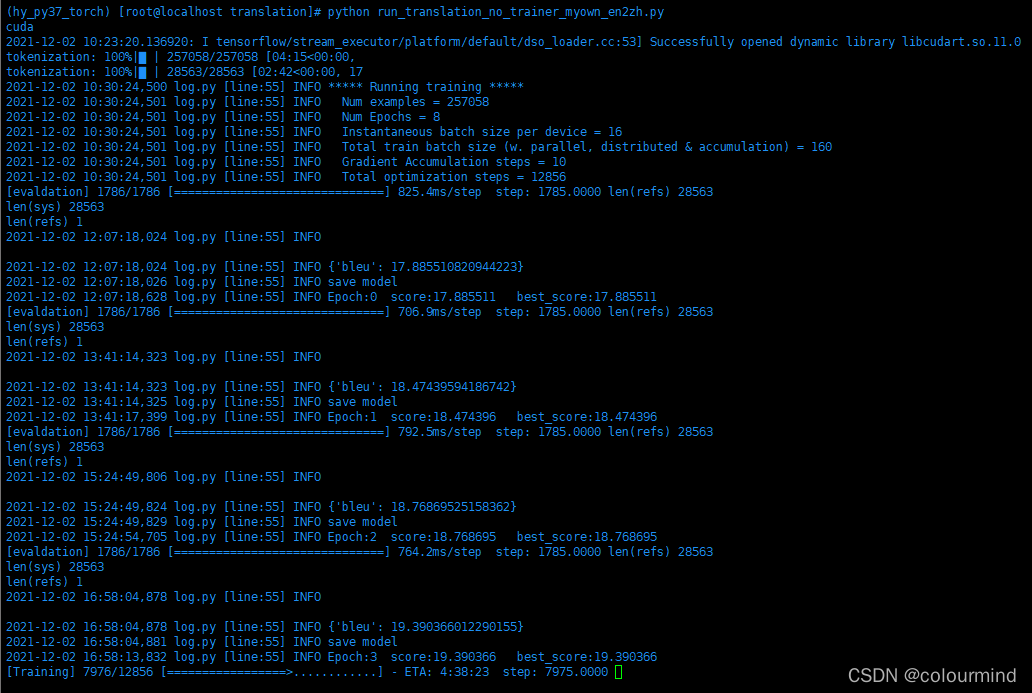
训练时间还是很久的,英语到汉语的BLEU还是比较低的,没有中文到英语的BLEU高。
这里不放模型代码也不放代码解读,就列一下基本思路,最后展示一下实验效果。
baseline利用MarianMTModel训练8个epoch的结果,BLEU:41.98844382766
论文中的第三步:
30W伪平行语料(30W英文语料翻译为中文构建而来)加20W平行语料的训练结果(不加噪声)BLEU:44.67761919329
论文的第四步:取一部分单语料使用新模型(第一步中的模型)翻译得到新的伪平行语料5W条,做微调结果:BLEU:43.93912
比赛采用第三步的结果最后做后处理,对翻译结果做简单的符号调整,人工过滤最后得分BLEU:45.88338754782
比赛最后的后处理方案思路是来自第二名的交流——感谢!
以上代码在我的github上dataFountionCompetition_translatino_ner_mutillabel_classification
二、比赛的感悟和思考
经过这次比赛发现自己的积累还是不够,需要再这个领域更多的积累。通过这次比赛熟悉了更多的比赛技巧和炼丹知识,收获颇多!
1、赛题解析和方案预研
针对一个赛题一定好做好预研,看看以往相关的最优方案,也需要收集更多的资料,丰富自己的方案库。
2、细心耐心
方案的尝试和调参的过程中,一定要能坚持到底,同时保证每一步的正确性,做好记录,消融实验,确认实验方案中的正向变量和因素。
3、团队的重要性
如果能找到志同道合的人一起参加比赛,多多讨论交流,把不同的想法实现出来,融合在一起,会得到更高的提升。
期待下次比赛能有所突破,取得更好的成绩!