一、前言
本系列为个人Dubbo学习笔记,内容基于《深度剖析Apache Dubbo 核心技术内幕》, 过程参考官方源码分析文章,仅用于个人笔记记录。本文分析基于Dubbo2.7.0版本,由于个人理解的局限性,若文中不免出现错误,感谢指正。
集群组件相关文章:
- Dubbo笔记⑫ :Dubbo 集群组件概述
- Dubbo笔记⑬ :Dubbo 集群组件 之 Cluster & ClusterInvoker
- Dubbo笔记⑭ :Dubbo集群组件 之 Directory
- Dubbo笔记⑮ :Dubbo集群组件 之 Router
- Dubbo笔记⑯ :Dubbo集群组件 之 LoadBalance
本文部分内容参考官方文档。
1. Cluster 的概念
Dubbo集群容错中存在两个概念,分别是集群接口 Cluster 和 Cluster Invoker,这两者是不同的。Cluster 是接口,而 Cluster Invoker 是一种 Invoker。服务提供者的选择逻辑,以及远程调用失败后的的处理逻辑均是封装在 Cluster Invoker 中。而 Cluster 接口和相关实现类的用途比较简单,仅用于生成 Cluster Invoker。简单来说,Cluster 就是用来创建 Cluster Invoker 的,并且一一对应。而Cluster 和 Cluster Invoker 的作用就是,在消费者进行服务调用时选择何种容错策略,如:服务调用失败后是重试、还是抛出异常亦或者返回一个空的结果集等。
Cluster 接口如下:
@SPI(FailoverCluster.NAME)
public interface Cluster {
//
@Adaptive
<T> Invoker<T> join(Directory<T> directory) throws RpcException;
}
配置方式
<dubbo:reference cluster="failsafe" />
2. Cluster 的种类
Cluster 接口存在多个实现对应不同的容错策略。 如下是org.apache.dubbo.rpc.cluster.Cluster 文件中针对不同协议的具体实现类:
mock=org.apache.dubbo.rpc.cluster.support.wrapper.MockClusterWrapper
failover=org.apache.dubbo.rpc.cluster.support.FailoverCluster
failfast=org.apache.dubbo.rpc.cluster.support.FailfastCluster
failsafe=org.apache.dubbo.rpc.cluster.support.FailsafeCluster
failback=org.apache.dubbo.rpc.cluster.support.FailbackCluster
forking=org.apache.dubbo.rpc.cluster.support.ForkingCluster
available=org.apache.dubbo.rpc.cluster.support.AvailableCluster
mergeable=org.apache.dubbo.rpc.cluster.support.MergeableCluster
broadcast=org.apache.dubbo.rpc.cluster.support.BroadcastCluster
registryaware=org.apache.dubbo.rpc.cluster.support.RegistryAwareCluster
上面的每个类都 对应一个 Cluster Invoker, 其中 MockClusterWrapper 是 扩展类,对应的 Cluster Invoker 为 MockClusterInvoker,其余都是容错策略,其作用如下:
MockClusterInvoker : MockClusterWrapper 对应的 Cluster Invoker。完成了本地Mock 的功能。这里需要注意由于MockClusterWrapper 是 扩展类,所以 MockClusterInvoker 在最外层,即当服务调用时的顺序为 :
MockClusterInvoker#invoker -> XxxClusterInvoker#invoker。关于 MockClusterInvoker 的实现,详参: Dubbo衍生篇⑦ :本地Mock 和服务降级Failover Cluster:失败重试。当服务消费方调用服务提供者失败后,会自动切换到其他服务提供者服务器进行重试,这通常用于读操作或者具有幂等的写操作。需要注意的是,重试会带来更长延迟。可以通过retries="2"来设置重试次数(不含第1次)。 可以使用<dubbo:reference retries=“2”/>来进行接口级别配置的重试次数,当服务消费方调用服务失败后,此例子会再重试两次,也就是说最多会做3次调用,这里的配置对该接口的所有方法生效。
Failfast Cluster:快速失败。当服务消费方调用服务提供者失败后,立即报错,也就是只调用一次。通常,这种模式用于非幂等性的写操作。
Failsafe Cluster:安全失败。当服务消费者调用服务出现异常时,直接忽略异常。这种模式通常用于写入审计日志等操作。
Failback Cluster:失败自动恢复。当服务消费端调用服务出现异常后,在后台记录失败的请求,并按照一定的策略后期再进行重试。这种模式通常用于消息通知操作。
Forking Cluster:并行调用。当消费方调用一个接口方法后,Dubbo Client会并行调用多个服务提供者的服务,只要其中有一个成功即返回。这种模式通常用于实时性要求较高的读操作,但需要浪费更多服务资源。如下代码可通过forks="4"来设置最大并行数:
Available Cluster :可用集群调用器。前面提到doInvoke的入参有远程服务提供者的列表invokers。AvailableClusterInvoker遍历invokers,当遍历到第一个服务可用的提供者时,便访问该提供者,成功返回结果,如果访问时失败抛出异常终止遍历。
Mergeable Cluster :该集群容错策略是对多个服务端返回结果合并,在消费者调多个分组下的同一个服务时会指定使用该 Cluster 来合并 多个分组执行的结果。
Broadcast Cluster:广播调用。当消费者调用一个接口方法后,Dubbo Client会逐个调用所有服务提供者,任意一台服务器调用异常则这次调用就标志失败。这种模式通常用于通知所有提供者更新缓存或日志等本地资源信息。
RegistryAware Cluster :当消费者引用多个注册中心时会指定使用该策略。默认会首先引用默认的注册中心服务,如果默认注册中心服务没有提供该服务,则会从其他注册中心中寻找该服务。
Dubbo本身提供了丰富的集群容错模式,但是如果你有定制化需求,可以根据Dubbo提供的扩展接口Cluster进行定制。
上述的每个Cluster 对应一个Cluster Invoker, 如下 FailoverCluster 对应 FailoverClusterInvoker,而 FailoverClusterInvoker 才是容错逻辑实现的地方,所以下文会直接分析 Cluster Invoker。
public class FailoverCluster implements Cluster {
public final static String NAME = "failover";
@Override
public <T> Invoker<T> join(Directory<T> directory) throws RpcException {
return new FailoverClusterInvoker<T>(directory);
}
}
下图是消费者发起调用后的简化时序图 (图源 《深度剖析Apache Dubbo 核心技术内幕》)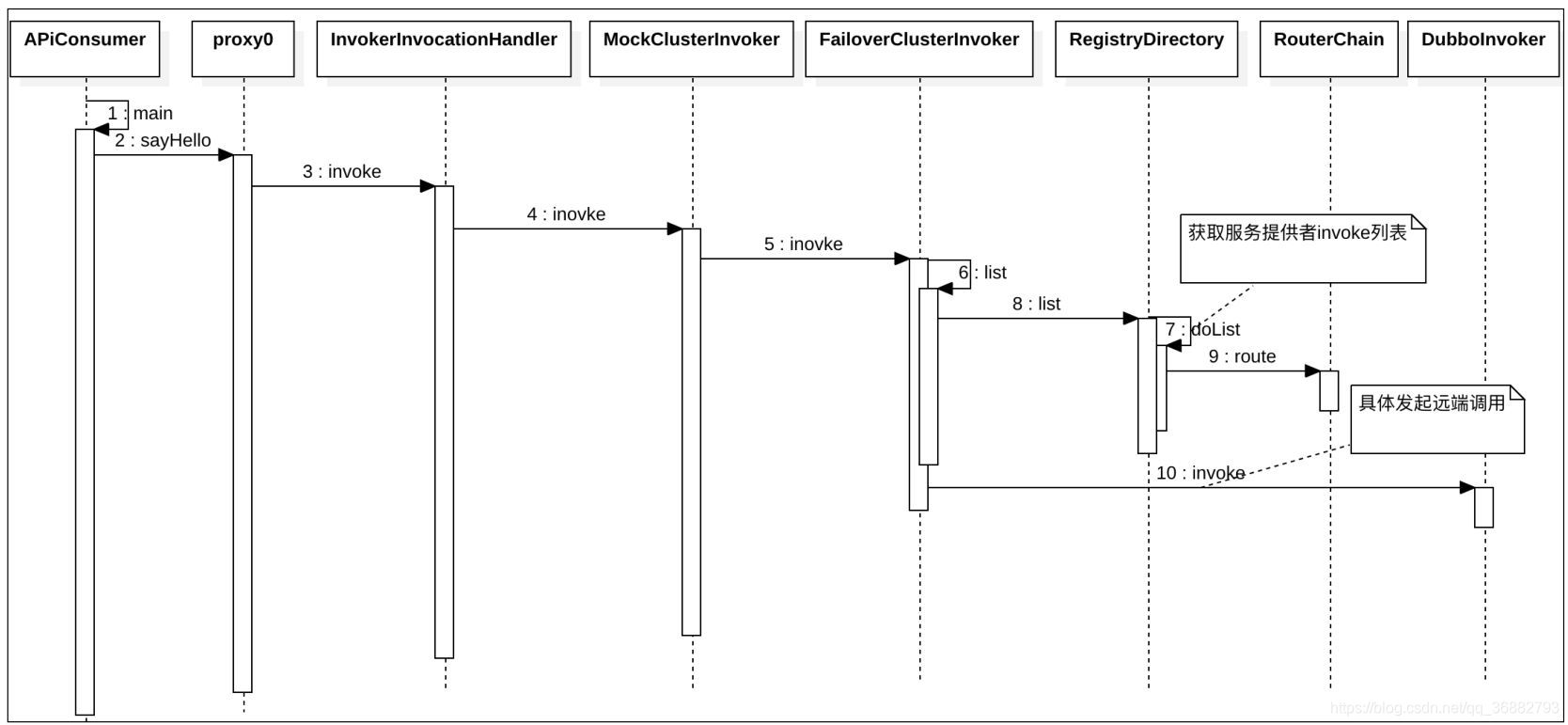
由于每个Cluster Invoker 都是 AbstractClusterInvoker 的子类,所以上图
中 MockClusterInvoker#invoker 后的调用为:
MockClusterInvoker#invoker => AbstractClusterInvoker#invoke => AbstractClusterInvoker#doInvoker (AbstractClusterInvoker并未实现该方法,供子类实现)
其中 MockClusterInvoker 为 MockClusterWrapper 对应 Cluster Invoker。完成了 本地mock功能。
三、AbstractClusterInvoker
由于上述的每个Cluster Invoker 都是 AbstractClusterInvoker 的子类。所以这里先来介绍一下AbstractClusterInvoker 中的一些公用方法。
1. AbstractClusterInvoker#invoke
我们上面提到过,服务消费者调用服务时会遵循如下流程:
MockClusterInvoker#invoker => AbstractClusterInvoker#invoke => AbstractClusterInvoker#doInvoker (AbstractClusterInvoker并未实现该方法,供子类实现)
所以我们这里先来看看 AbstractClusterInvoker#invoke 的实现:
@Override
public Result invoke(final Invocation invocation) throws RpcException {
checkWhetherDestroyed();
// binding attachments into invocation.
// 绑定 attachments 到 invocation 中.
Map<String, String> contextAttachments = RpcContext.getContext().getAttachments();
if (contextAttachments != null && contextAttachments.size() != 0) {
((RpcInvocation) invocation).addAttachments(contextAttachments);
}
// 列举 Invoker,即 从 Directory 中获取 Invoker 列表(路由后的列表)
// 这里的调用顺序是 list -> AbstractDirectory#List -> RegistryDirectory#doList
List<Invoker<T>> invokers = list(invocation);
// 初始化负载均衡。如果 invokers 不为空,则从第一个invokers 的URL进行初始化,如果调用为空,则从默认调用LoadBalance(RandomLoadBalance)进行调用
LoadBalance loadbalance = initLoadBalance(invokers, invocation);
// 异步调用时附加 id
RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
// 供ClusterInvoker 子类实现。
return doInvoke(invocation, invokers, loadbalance);
}
...
// 加载负载均衡策略。
protected LoadBalance initLoadBalance(List<Invoker<T>> invokers, Invocation invocation) {
// 如果 invokers 不为空,则从第一个 invoker 上获取调用方法指定的 负载均衡策略,没有指定默认为 random
if (CollectionUtils.isNotEmpty(invokers)) {
return ExtensionLoader.getExtensionLoader(LoadBalance.class).getExtension(invokers.get(0).getUrl()
.getMethodParameter(RpcUtils.getMethodName(invocation), Constants.LOADBALANCE_KEY, Constants.DEFAULT_LOADBALANCE));
} else {
return ExtensionLoader.getExtensionLoader(LoadBalance.class).getExtension(Constants.DEFAULT_LOADBALANCE);
}
}
整个流程比较简单:
- list(invocation); :方法获取服务路由后的 invoker 列表。通过 Directory#list 获取。关于服务目录的内容详参: Dubbo笔记⑭ :Dubbo集群组件 之 Directory
- initLoadBalance(invokers, invocation) : 加载负载均衡策略,加载策略为 : 如果 invokers 不为空,则从第一个 invoker 上获取调用方法指定的 负载均衡策略,没有指定默认为 random。关于负载均衡详参: Dubbo笔记⑯ :Dubbo集群组件 之 LoadBalance
- doInvoke(invocation, invokers, loadbalance); :开始真正调用逻辑。该方法 AbstractClusterInvoker 类中并未实现,供子类实现。
2. AbstractClusterInvoker#select
AbstractClusterInvoker#select 的作用是负载均衡策略来筛选 Invoker,AbstractClusterInvoker 的子类 在 doInvoker 中会调用该方法来应用负载均衡策略。如FailoverClusterInvoker等。但是需要注意并非所有的容错策略都会应用负载均衡策略。
AbstractClusterInvoker#select 的实现如下:
// 源码注释:使用负载平衡策略选择一个调用程序。
// a)首先,使用loadbalance选择一个调用程序。 如果此调用程序在先前选择的列表中,或者如果此调用程序不可用,则继续执行步骤b(重新选择),否则返回第一个选定的调用程序
// b)重新选择,重新选择的验证规则:selected > 可用。 此规则确保所选调用者有最小机会成为先前选择的列表中的一个,并且还保证此调用者可用。
// 入参中的 selected 代表之前已经调用过的 invoker 列表
protected Invoker<T> select(LoadBalance loadbalance, Invocation invocation,
List<Invoker<T>> invokers, List<Invoker<T>> selected) throws RpcException {
if (CollectionUtils.isEmpty(invokers)) {
return null;
}
// 获取调用方法名
String methodName = invocation == null ? StringUtils.EMPTY : invocation.getMethodName();
// 获取 sticky 配置,sticky 表示粘滞连接。所谓粘滞连接是指让服务消费者尽可能的
// 调用同一个服务提供者,除非该提供者挂了再进行切换
boolean sticky = invokers.get(0).getUrl()
.getMethodParameter(methodName, Constants.CLUSTER_STICKY_KEY, Constants.DEFAULT_CLUSTER_STICKY);
//ignore overloaded method
// 检测 invokers 列表是否包含 stickyInvoker,如果不包含,
// 说明 stickyInvoker 代表的服务提供者挂了,此时需要将其置空
if (stickyInvoker != null && !invokers.contains(stickyInvoker)) {
stickyInvoker = null;
}
//ignore concurrency problem
// 在 sticky 为 true,且 stickyInvoker != null 的情况下。如果 selected 包含
// stickyInvoker,表明 stickyInvoker 对应的服务提供者可能因网络原因未能成功提供服务。
// 但是该提供者并没挂,此时 invokers 列表中仍存在该服务提供者对应的 Invoker。
if (sticky && stickyInvoker != null && (selected == null || !selected.contains(stickyInvoker))) {
// availablecheck 表示是否开启了可用性检查,如果开启了,则调用 stickyInvoker 的
// isAvailable 方法进行检查,如果检查通过,则直接返回 stickyInvoker。
if (availablecheck && stickyInvoker.isAvailable()) {
return stickyInvoker;
}
}
// 如果线程走到当前代码处,说明前面的 stickyInvoker 为空,或者不可用。
// 此时继续调用 doSelect 选择 Invoker
Invoker<T> invoker = doSelect(loadbalance, invocation, invokers, selected);
// 如果 sticky 为 true,则将负载均衡组件选出的 Invoker 赋值给 stickyInvoker
if (sticky) {
stickyInvoker = invoker;
}
return invoker;
}
这里需要注意 粘滞连接特性 :粘滞连接是指让服务消费者尽可能 调用同一个服务提供者,除非该提供者挂了再进行切换。
综上, AbstractClusterInvoker#select 方法的流程是(官方描述):
首先是获取 sticky 配置,然后再检测 invokers 列表中是否包含 stickyInvoker。如果不包含,则认为该 stickyInvoker 不可用,此时将其置空。这里的 invokers 列表可以看做是存活着的服务提供者列表,如果这个列表不包含 stickyInvoker,那自然而然的认为 stickyInvoker 挂了,所以置空。如果 stickyInvoker 存在于 invokers 列表中,此时要进行下一项检测 — 检测 selected 中是否包含 stickyInvoker。 如果selected 中包含 stickyInvoker的话,说明 stickyInvoker 在此之前没有成功提供服务(但其仍然处于存活状态)。此时我们认为这个服务不可靠,不应该在重试期间内再次被调用,因此这个时候不会返回该 stickyInvoker。如果 selected 不包含 stickyInvoker,此时还需要进行可用性检测,比如检测服务提供者网络连通性等。当可用性检测通过,才可返回 stickyInvoker,否则调用 doSelect 方法选择 Invoker。如果 sticky 为 true,此时会将 doSelect 方法选出的 Invoker 赋值给 stickyInvoker。
在上面的代码中,我们发现AbstractClusterInvoker#doSelect才是真正完成负载均衡的调用。所以下面我们来看看 AbstractClusterInvoker#doSelect 的实现。
2.1 AbstractClusterInvoker#doSelect
AbstractClusterInvoker#doSelect 真正完成了负载均衡的相关处理。其实现如下:
private Invoker<T> doSelect(LoadBalance loadbalance, Invocation invocation,
List<Invoker<T>> invokers, List<Invoker<T>> selected) throws RpcException {
if (CollectionUtils.isEmpty(invokers)) {
return null;
}
// 如果只有一个服务提供者,不用再执行负载均衡策略,直接返回即可。
if (invokers.size() == 1) {
return invokers.get(0);
}
// 通过 负载均衡策略选举出一个 Invoker
Invoker<T> invoker = loadbalance.select(invokers, getUrl(), invocation);
//If the `invoker` is in the `selected` or invoker is unavailable && availablecheck is true, reselect.
// 如果 selected 包含负载均衡选择出的 Invoker,或者该 Invoker 无法经过可用性检查,此时进行重选
// 即,如果 invoker 已经被调用过 || invoker 服务不可用,则进行重选
if ((selected != null && selected.contains(invoker))
|| (!invoker.isAvailable() && getUrl() != null && availablecheck)) {
try {
// 进行重选
Invoker<T> rinvoker = reselect(loadbalance, invocation, invokers, selected, availablecheck);
// 如果 rinvoker 不为空,则将其赋值给 invoker
if (rinvoker != null) {
invoker = rinvoker;
} else {
//Check the index of current selected invoker, if it's not the last one, choose the one at index+1.
// rinvoker 为空,定位 invoker 在 invokers 中的位置
int index = invokers.indexOf(invoker);
try {
//Avoid collision
// 获取 index + 1 位置处的 Invoker,以下代码等价于:
// invoker = invokers.get((index + 1) % invokers.size());
invoker = invokers.get((index + 1) % invokers.size());
} catch (Exception e) {
logger.warn(e.getMessage() + " may because invokers list dynamic change, ignore.", e);
}
}
} catch (Throwable t) {
logger.error("cluster reselect fail reason is :" + t.getMessage() + " if can not solve, you can set cluster.availablecheck=false in url", t);
}
}
return invoker;
}
AbstractClusterInvoker#doSelect 主要做了两件事 :
- 通过负载均衡组件选择 Invoker。
- 如果选出来的 Invoker 不稳定或不可用,此时需要调用 reselect 方法进行重选。若 reselect 选出来的 Invoker 为空,此时定位 invoker 在 invokers 列表中的位置 index,然后获取 index + 1 处的 invoker,这也可以看做是重选逻辑的一部分。
2.2 AbstractClusterInvoker#reselect
AbstractClusterInvoker#reselect 完成了服务的重选。当之前挑选的 Invoker 不可用,或者已经选择过(保存在 selected 集合中),则认为 invoker 不合格,进行重新筛选。
// 重新选择,首先使用不在“ selected”中的调用者,如果所有调用者都在“ selected”中,只需使用负载均衡策略选择一个可用的调用者。
private Invoker<T> reselect(LoadBalance loadbalance, Invocation invocation,
List<Invoker<T>> invokers, List<Invoker<T>> selected, boolean availablecheck) throws RpcException {
//Allocating one in advance, this list is certain to be used.
List<Invoker<T>> reselectInvokers = new ArrayList<>(
invokers.size() > 1 ? (invokers.size() - 1) : invokers.size());
// First, try picking a invoker not in `selected`.
// 筛选出 可用 && 未被调用过的 invoker 保存到 reselectInvokers集合汇总
for (Invoker<T> invoker : invokers) {
if (availablecheck && !invoker.isAvailable()) {
continue;
}
if (selected == null || !selected.contains(invoker)) {
reselectInvokers.add(invoker);
}
}
// 如果 reselectInvokers 不为空,则再次进行负载均衡
if (!reselectInvokers.isEmpty()) {
return loadbalance.select(reselectInvokers, getUrl(), invocation);
}
// Just pick an available invoker using loadbalance policy
// 到这一步说明 reselectInvokers 为空,也即是说,所有的服务要么不可用,要么被调用过。则开始挑选已经调用过的 invoker 中可用的 invoker 保存到 reselectInvokers 集合中
if (selected != null) {
for (Invoker<T> invoker : selected) {
if ((invoker.isAvailable()) // available first
&& !reselectInvokers.contains(invoker)) {
reselectInvokers.add(invoker);
}
}
}
// 再次进行负载均衡调用
if (!reselectInvokers.isEmpty()) {
return loadbalance.select(reselectInvokers, getUrl(), invocation);
}
return null;
}
AbstractClusterInvoker#reselect 方法的逻辑很清楚
- 首先获取 服务提供者列表中 (未被调用过 && 可用的服务) 的 invoker列表 交由负载均衡组件筛选。
- 如果没有 (未被调用过 && 可用的服务) 的 invoker,则退而求其次,放松筛选规则,挑选 (调用过的服务 && 可用的服务) 的 invoker列表,并交由负载均衡组件筛选。
3. 总结
我们这里总结一下 AbstractClusterInvoker 做了什么事
AbstractClusterInvoker#invoke :
1. 从Directory中获取到服务提供者列表 2. 加载指定的负载均衡策略 3. 提供 AbstractClusterInvoker#doInvoke 方法供子类完成具体的容错实现AbstractClusterInvoker#select:
1. 使用负载平衡策略选择一个服务提供者 Invoker 返回。
四、源码分析
下面我们来分析AbstractClusterInvoker 各个子类的具体实现。根据上面的分析我们知道,AbstractClusterInvoker将 doInvoke 交由子类具体实现,所以我们下面着重看各个子类 doInvoke 方法的实现 。
1. FailoverClusterInvoker
失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。可通过 retries=“2” 来设置重试次数(不含第一次)。
FailoverClusterInvoker#doInvoke 实现如下 :
@Override
@SuppressWarnings({"unchecked", "rawtypes"})
public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
// 1. 获取所有服务提供者
List<Invoker<T>> copyInvokers = invokers;
// 检查服务提供者,如果集合为空则抛出异常
checkInvokers(copyInvokers, invocation);
String methodName = RpcUtils.getMethodName(invocation);
// 2. 获取指定的重试次数 retries。默认重试次数为1次,也就是会调用两次。
int len = getUrl().getMethodParameter(methodName, Constants.RETRIES_KEY, Constants.DEFAULT_RETRIES) + 1;
if (len <= 0) {
len = 1;
}
// retry loop.
// 使用循环,失败重试
RpcException le = null; // last exception.
List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyInvokers.size()); // invoked invokers.
Set<String> providers = new HashSet<String>(len);
// 3. 开始循环调用
for (int i = 0; i < len; i++) {
//Reselect before retry to avoid a change of candidate `invokers`.
//NOTE: if `invokers` changed, then `invoked` also lose accuracy.
// 重试时,进行重新选择,避免重试时 invoker 列表已经发生改变 这样做的好处是,如果某个服务挂了,通过调用 list 可得到最新可用的 Invoker 列表
// 注意: 如果 列表发生变化,则 invoked判断会失效,因为 invoker 实例已经改变
if (i > 0) {
// 3.1 重试时校验
// 如果当前实例已经被销毁,则抛出异常
checkWhetherDestroyed();
// 重新获取所有服务提供者
copyInvokers = list(invocation);
// check again
// 再次检查 invoker 列表是否为空
checkInvokers(copyInvokers, invocation);
}
// 3.2. 选择负载均衡策略。该方法调用的是上面所说的AbstractClusterInvoker#select 方法
Invoker<T> invoker = select(loadbalance, invocation, copyInvokers, invoked);
// 添加到 invoker 到 invoked 列表中,表明当前 invoker已经被调用过
invoked.add(invoker);
// 设置 invoked 到 RPC 上下文中
RpcContext.getContext().setInvokers((List) invoked);
try {
// 3.3具体发起远程调用
Result result = invoker.invoke(invocation);
// ... 日志处理
return result;
} catch (RpcException e) {
if (e.isBiz()) { // biz exception.
throw e;
}
le = e;
} catch (Throwable e) {
le = new RpcException(e.getMessage(), e);
} finally {
providers.add(invoker.getUrl().getAddress());
}
}
// ... 若重试失败,则抛出异常
}
FailoverClusterInvoker#doInvoke 的实现很简单:
- 获取所有的服务提供者。
- 获取消费者指定的重试次数,如果没有指定,则默认的重试次数为1次,那么这个接口总共调用次数=重试次数+1(1是正常调用)
- 开始根据重试次数,循环调用。如果调用成功,则跳出循环
- 重试时的校验。当服务第一次调用时,此时i=0,不会进行重试校验。而当进行重试时, i>0 条件满足,此时会进行校验。
checkWhetherDestroyed();检查是否有线程调用了当前ReferenceConfig的destroy()方法,销毁了当前消费者。如果当前消费者实例已经被销毁,那么重试就没意义了,所以会抛出RpcException异常。如果 消费者没有被销毁,则通过copyInvokers = list(invocation);重新获取当前服务提供者列表,这是因为从第一次调开始到现在可能提供者列表已经变化了。随后又通过checkInvokers(copyInvokers, invocation);对服务列表进行了一次校验。 - 通过负载均衡策略筛选出合适的 Invoker
- 进行具体调用。需要注意的是在具体调用时(即
invoker.invoke(invocation))出现异常会进行重试,而在3.1,3.2 时出现异常并不会重试。因为 3.1,3.2 属于调用前的准备工作。
- 重试时的校验。当服务第一次调用时,此时i=0,不会进行重试校验。而当进行重试时, i>0 条件满足,此时会进行校验。
2. FailfastClusterInvoker
FailfastClusterInvoker 即快速失败,其代码很简单,调用出错即抛出异常。
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
FailfastClusterInvoker#doInvoke 的实现如下,代码比较简单,不再赘述:
@Override
public Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
// 检查服务提供者,如果集合为空则抛出异常
checkInvokers(invokers, invocation);
// 通过负载均衡策略选择 Invoker
Invoker<T> invoker = select(loadbalance, invocation, invokers, null);
try {
// 服务调用
return invoker.invoke(invocation);
} catch (Throwable e) {
// 调用错误抛出异常
if (e instanceof RpcException && ((RpcException) e).isBiz()) { // biz exception.
throw (RpcException) e;
}
// ... 抛出异常
}
}
3. FailsafeClusterInvoker
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
安全失败,即失败并不抛出异常,而是返回一个空结果。代码也很简单,这里不再赘述
FailsafeClusterInvoker#doInvoke 的实现如下,代码比较简单,不再赘述:
@Override
public Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
try {
checkInvokers(invokers, invocation);
Invoker<T> invoker = select(loadbalance, invocation, invokers, null);
return invoker.invoke(invocation);
} catch (Throwable e) {
logger.error("Failsafe ignore exception: " + e.getMessage(), e);
// 出现异常返回空结果集
return new RpcResult(); // ignore
}
}
4. FailbackClusterInvoker
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。FailbackClusterInvoker 会在调用失败后,返回一个空结果给服务消费者。并通过定时任务对失败的调用进行重传,适合执行消息通知等操作。
FailbackClusterInvoker#doInvoke 的实现如下:
@Override
protected Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
Invoker<T> invoker = null;
try {
checkInvokers(invokers, invocation);
invoker = select(loadbalance, invocation, invokers, null);
return invoker.invoke(invocation);
} catch (Throwable e) {
// 如果调用过程中发生异常,此时仅打印错误日志,不抛出异常
logger.error("Failback to invoke method " + invocation.getMethodName() + ", wait for retry in background. Ignored exception: "
+ e.getMessage() + ", ", e);
// 记录调用信息,进行重试调用
addFailed(loadbalance, invocation, invokers, invoker);
// 返回一个空结果给服务消费者
return new RpcResult(); // ignore
}
}
// 记录调用失败信息,并进行重试
private void addFailed(LoadBalance loadbalance, Invocation invocation, List<Invoker<T>> invokers, Invoker<T> lastInvoker) {
// 创建自定义计时器实例
if (failTimer == null) {
synchronized (this) {
if (failTimer == null) {
failTimer = new HashedWheelTimer(
new NamedThreadFactory("failback-cluster-timer", true),
1,
TimeUnit.SECONDS, 32, failbackTasks);
}
}
}
// 创建定时重试任务,每隔5秒执行一次
RetryTimerTask retryTimerTask = new RetryTimerTask(loadbalance, invocation, invokers, lastInvoker, retries, RETRY_FAILED_PERIOD);
try {
failTimer.newTimeout(retryTimerTask, RETRY_FAILED_PERIOD, TimeUnit.SECONDS);
} catch (Throwable e) {
logger.error("Failback background works error,invocation->" + invocation + ", exception: " + e.getMessage());
}
}
4.1 RetryTimerTask
RetryTimerTask 由于实现了 TimerTask 接口,所以我们这里只需要关注RetryTimerTask#run 方法即可。如下
@Override
public void run(Timeout timeout) {
try {
// 负载均衡选择
Invoker<T> retryInvoker = select(loadbalance, invocation, invokers, Collections.singletonList(lastInvoker));
lastInvoker = retryInvoker;
// 进行远端调用
retryInvoker.invoke(invocation);
} catch (Throwable e) {
logger.error("Failed retry to invoke method " + invocation.getMethodName() + ", waiting again.", e);
// 到达重试次数则不再重试
if ((++retryTimes) >= retries) {
logger.error("Failed retry times exceed threshold (" + retries + "), We have to abandon, invocation->" + invocation);
} else {
// 再次重试
rePut(timeout);
}
}
}
private void rePut(Timeout timeout) {
if (timeout == null) {
return;
}
Timer timer = timeout.timer();
if (timer.isStop() || timeout.isCancelled()) {
return;
}
timer.newTimeout(timeout.task(), tick, TimeUnit.SECONDS);
}
5. ForkingClusterInvoker
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks=“2” 来设置最大并行数。
ForkingClusterInvoker#doInvoke 的实现如下:
public Result doInvoke(final Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
try {
checkInvokers(invokers, invocation);
final List<Invoker<T>> selected;
// 1. 获取参数配置
// 获取最大并行数。默认2
final int forks = getUrl().getParameter(Constants.FORKS_KEY, Constants.DEFAULT_FORKS);
// 获取超时时间。默认1000
final int timeout = getUrl().getParameter(Constants.TIMEOUT_KEY, Constants.DEFAULT_TIMEOUT);
// 2. 筛选并行调用的 invoker
// 2.1如果 forks 配置不合理,则直接将 invokers 赋值给 selected
if (forks <= 0 || forks >= invokers.size()) {
selected = invokers;
} else {
selected = new ArrayList<>();
// 2.2 循环选出 forks 个 Invoker,并添加到 selected 中
for (int i = 0; i < forks; i++) {
// TODO. Add some comment here, refer chinese version for more details.
// 挑选 invoker。
Invoker<T> invoker = select(loadbalance, invocation, invokers, selected);
// 添加 invoker 到 selected 中
if (!selected.contains(invoker)) {
//Avoid add the same invoker several times.
selected.add(invoker);
}
}
}
RpcContext.getContext().setInvokers((List) selected);
// 用于记录调用出现异常的次数
final AtomicInteger count = new AtomicInteger();
// 创建阻塞队列
final BlockingQueue<Object> ref = new LinkedBlockingQueue<>();
// 3. 进行并发调用
for (final Invoker<T> invoker : selected) {
// 开启线程并发调用
executor.execute(new Runnable() {
@Override
public void run() {
try {
// 进行远程调用
Result result = invoker.invoke(invocation);
// 将结果存在阻塞队列中。
ref.offer(result);
} catch (Throwable e) {
// 3.1 value >= selected.size() 则说明所有调用都失败了,记录错误
int value = count.incrementAndGet();
if (value >= selected.size()) {
ref.offer(e);
}
}
}
});
}
try {
// 4. 从阻塞队列中取出远程调用结果并返回
Object ret = ref.poll(timeout, TimeUnit.MILLISECONDS);
// 如果结果类型为 Throwable,则抛出异常
if (ret instanceof Throwable) {
Throwable e = (Throwable) ret;
throw new RpcException(e instanceof RpcException ? ((RpcException) e).getCode() : 0, "Failed to forking invoke provider " + selected + ", but no luck to perform the invocation. Last error is: " + e.getMessage(), e.getCause() != null ? e.getCause() : e);
}
// 返回结果
return (Result) ret;
} catch (InterruptedException e) {
throw new RpcException("Failed to forking invoke provider " + selected + ", but no luck to perform the invocation. Last error is: " + e.getMessage(), e);
}
} finally {
// clear attachments which is binding to current thread.
RpcContext.getContext().clearAttachments();
}
}
上面的代码逻辑如下:
- 获取参数配置 :这里获取消费者指定的forks 和 timeout 。forks 代表最大并发量, timeout 代表请求超时时间
- 筛选并行调用的 invoker :这里分为两种情况
- forks <= 0 || forks >= invokers.size() : 参数配置不合理,则所有的 invoker 都作为并发调用的 invoker
- 否则遍历通过负载均衡策略筛选出指定数量的 invoker
- 进行并发调用:开启线程池进行并发调用。
- 当 value >= selected.size() 时才会将异常信息入队。当 value >= selected.size() 则说明所有的并发调用都失败了,此时需要将异常信息记录到队列中。供后面使用。
- 从阻塞队列中取出远程调用结果并返回。这里需要注意的是,即使这里的RPC 调用返回了值,其他的并行调用还在继续。
6. BroadcastClusterInvoker
BroadcastClusterInvoker 会逐个调用每个服务提供者,如果其中一台报错,在循环调用结束后,BroadcastClusterInvoker 会抛出异常。该类通常用于通知所有提供者更新缓存或日志等本地资源信息。
BroadcastClusterInvoker#doInvoke 的实现如下:
@Override
@SuppressWarnings({"unchecked", "rawtypes"})
public Result doInvoke(final Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
checkInvokers(invokers, invocation);
RpcContext.getContext().setInvokers((List) invokers);
RpcException exception = null;
Result result = null;
// 遍历调用所有 Invoker
for (Invoker<T> invoker : invokers) {
try {
result = invoker.invoke(invocation);
} catch (RpcException e) {
exception = e;
logger.warn(e.getMessage(), e);
} catch (Throwable e) {
exception = new RpcException(e.getMessage(), e);
logger.warn(e.getMessage(), e);
}
}
if (exception != null) {
throw exception;
}
return result;
}
7. AvailableClusterInvoker
AvailableClusterInvoker遍历invokers,当遍历到第一个服务可用的提供者时,便访问该提供者,成功返回结果,如果访问时失败抛出异常终止遍历。
AvailableClusterInvoker#doInvoke 的实现如下:
@Override
public Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
for (Invoker<T> invoker : invokers) {
// 如果服务可用,则进行调用
if (invoker.isAvailable()) {
return invoker.invoke(invocation);
}
}
throw new RpcException("No provider available in " + invokers);
}
8. MergeableClusterInvoker
当消费者引用多分组的服务提供者时,Dubbo 会指定使用 MergeableClusterInvoker 作为集群容错策略。 MergeableClusterInvoker 的分析详参: Dubbo笔记衍生篇⑥ :MergeableClusterInvoker
9. RegistryAwareClusterInvoker
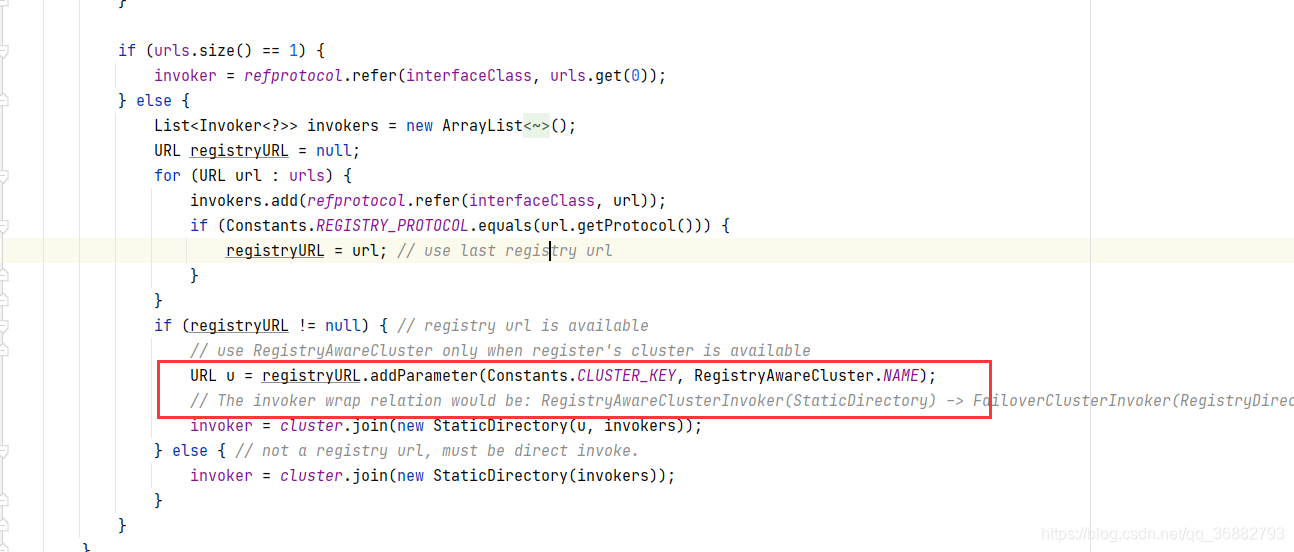
RegistryAwareClusterInvoker 会优先选择默认的注册中心来寻找服务(通过 default 属性来指定),如果默认注册中心没有提供该服务则选择其他注册中心提供的服务。
9.1 调用时机
如下,在服务调用的时候回优先调用 intlRegistry 注册中心的服务:
<!-- 多注册中心配置 -->
<!-- 在 RegistryDirectory#RegistryDirectory 构造函数中,通过 turnRegistryUrlToConsumerUrl 方法对 default 属性进行了解析。 -->
<dubbo:registry id="chinaRegistry" address="10.20.141.150:9090" />
<dubbo:registry id="intlRegistry" address="10.20.154.177:9010" default="true" />
而在 ReferenceConfig#get 方法如果判断是多注册中心时,会使用 RegistryAwareCluster作为集群容错策略。
9.2 RegistryAwareClusterInvoker#doInvoke
RegistryAwareClusterInvoker#doInvoke 的实现如下:
public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
// First, pick the invoker (XXXClusterInvoker) that comes from the local registry, distinguish by a 'default' key.
// 挑选默认注册中心中的服务,如果可用,优先调用
for (Invoker<T> invoker : invokers) {
if (invoker.isAvailable() && invoker.getUrl().getParameter(Constants.REGISTRY_KEY + "." + Constants.DEFAULT_KEY, false)) {
return invoker.invoke(invocation);
}
}
// If none of the invokers has a local signal, pick the first one available.
// 没有配置默认注册中心或者默认注册中心没有可用服务,则不限制注册中心,找到可用服务直接调用。
for (Invoker<T> invoker : invokers) {
if (invoker.isAvailable()) {
return invoker.invoke(invocation);
}
}
throw new RpcException("No provider available in " + invokers);
}
五、自定义 Cluster
创建自定义的集群类,实现Cluster接口。同时创建一个 ClusterInvoker 实现AbstractClusterInvoker类。
public class SimpleCluster implements Cluster { @Override public <T> Invoker<T> join(Directory<T> directory) throws RpcException { return new SimpleClusterInvoker<>(directory); } } public class SimpleClusterInvoker<T> extends AbstractClusterInvoker<T> { public SimpleClusterInvoker(Directory directory) { super(directory); } @Override protected Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException { return invokers.get(0).invoke(invocation); } }由于dubbo spi 机制,我们需要创建
META-INF/dubbo/org.apache.dubbo.rpc.cluster.Cluster文件,并添加内容,其中 simple 为key,集群容错的策略。value 为对应的实现类。这里即代表着 simple 容错策略使用 SimpleCluster 来实现。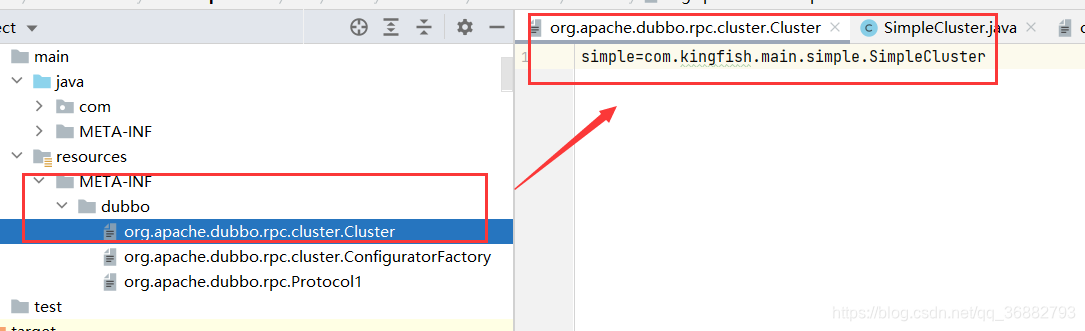
调用时通过 cluster 属性指定集群容错策略
@Reference(version = "1.0.0", group = "dubbo", cluster = "simple") private SimpleDemoService simpleDemoService;
以上:内容部分参考
《深度剖析Apache Dubbo 核心技术内幕》
https://dubbo.apache.org/zh/docs/v2.7/dev/source/
https://blog.csdn.net/abcde474524573/article/details/53026110
如有侵扰,联系删除。 内容仅用于自我记录学习使用。如有错误,欢迎指正