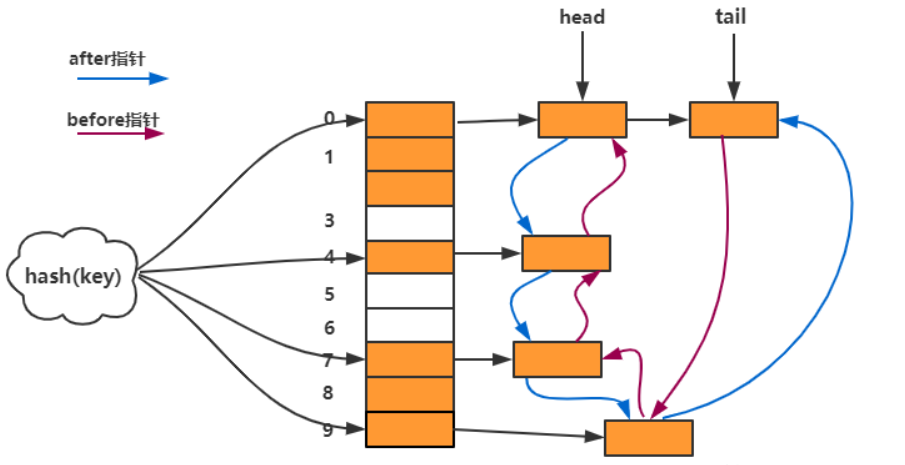
图解LinkedHashMap 数据结构
如下图所示,LinkedHashMap 在hashMap基础上增加一条双向链表,解决了HashMap不支持按照插入顺序和访问时间顺序访问问题。
LinkedHashMap 结点继承体系以及设计思想
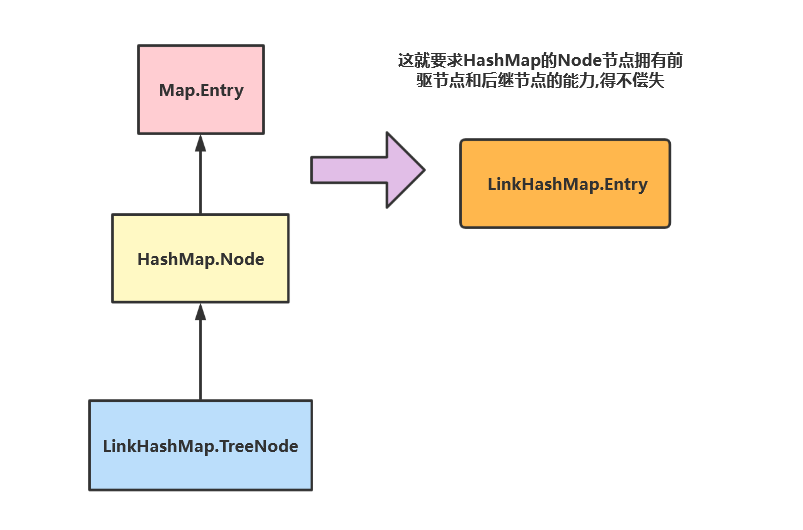
可以看到LinkedHashMap 使用TreeNode来自HashMap,而且HashMap的TreeNode居然包含维护其前驱节点和后继节点的引用prev和right。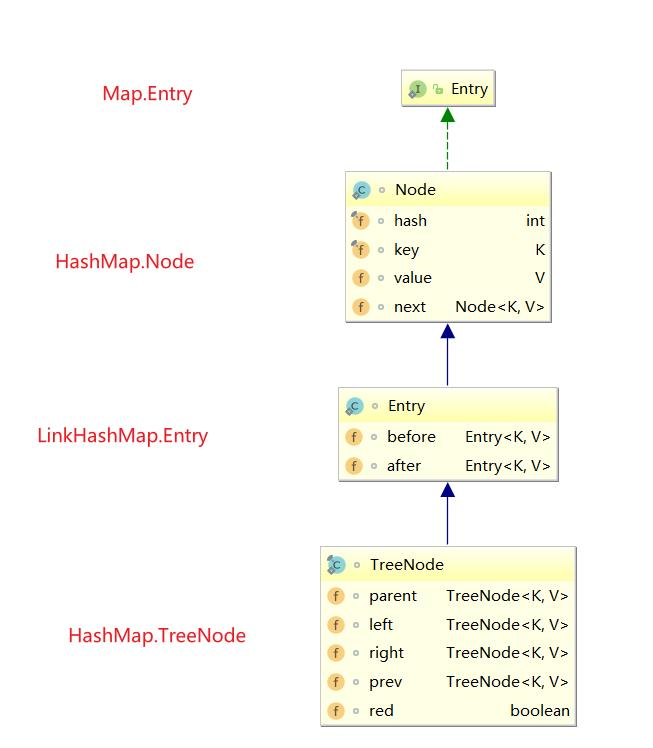
设想一下,正常情况下我们的LinkedHashMap 的TreeNode节点要想拥有前驱和后继节点的功能,这就要求TreeNode继承的Node必须有前驱和后继节点。相比前者设计,这种设计简直就是灾难。
Because TreeNodes are about twice the size of regular nodes, we
use them only when bins contain enough nodes to warrant use
(see TREEIFY_THRESHOLD). And when they become too small (due to
removal or resizing) they are converted back to plain bins. In
usages with well-distributed user hashCodes, tree bins are
rarely used.
设计者认为只要hash计算合理HashMap的每个桶的节点转红黑树的可能性不大,并且这种TreeNode也仅仅比普通的Node大2倍而已。
通过源码分析LinkedHashMap插入和查出节点的工作过程
插入节点
HashMap的put中的putVal
我们从HashMap的put方法的putVal源码入手可以看到有一个这样一段代码
tab[i] = newNode(hash, key, value, null);
源码位置如下图所示我们点进去,通过idea可以发现linkHashMap有对其进行重写:
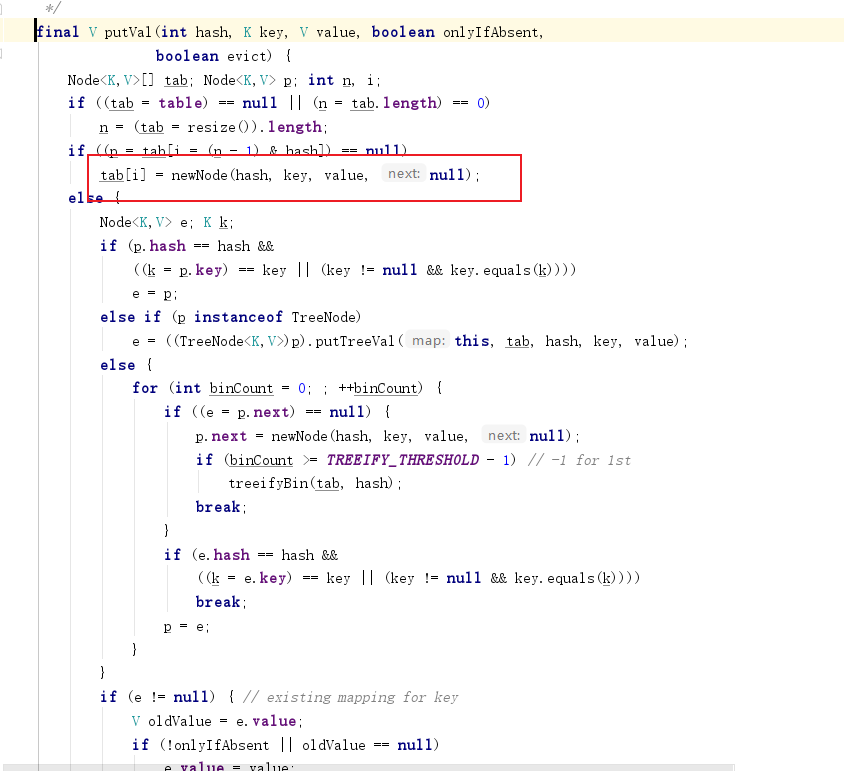
LinkHashMap重写TreeNode的newNode
源码如下所示,可以看到有一个linkNodeLast方法
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
LinkHashMap实现的linkNodeLast
这就是实现treeNode维护前驱后继节点关键所在
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
删除
HashMap的removeNode
可以看到节点删除后有这样一段代码
afterNodeRemoval(node);
位置如下图所示
linkHashMap对其实现
可以看到这段操作就是对双向链表节点的维护
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
通过源码分析LinkedHashMap 实现访问有序性的过程
代码如下所示,可以看到,最新访问过的元素会被存放最末尾。
@Test
public void linkHashMapGetTest() {
LinkedHashMap<String, String> linkedHashMap = new LinkedHashMap<>(15,0.75f,true);
for (int i = 0; i < 5; i++) {
linkedHashMap.put(String.valueOf(i),String.valueOf(i));
}
System.out.println(linkedHashMap.values());//[0, 1, 2, 3, 4]
linkedHashMap.get("2");
System.out.println(linkedHashMap.values());//[0, 1, 3, 4, 2]
}
通过源码我们不难发现,其实现访问顺序的方式很简单,每次get之后会调用一个afterNodeAccess方法
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
点进去看看详情,可以发现每个被访问过的的节点就会被存放到tail 尾节点上。
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
基于linkhashMap实现缓存代码示例
根据linkhashMap访问有序性的特点,我们完全可以继承这个类实现一个LRU缓存置换的缓存
package com.guide.collection;
import java.util.LinkedHashMap;
import java.util.Map;
public class SimpleCache<K, V> extends LinkedHashMap<K, V> {
private int limit;
public SimpleCache(int limit) {
super(limit, 0.75f, true);
this.limit = limit;
}
//当map的size超过最大容量时,淘汰很久没被访问过的key
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > limit;
}
}
测试代码
public static void main(String[] args) {
SimpleCache<String,String> simpleCache=new SimpleCache<>(3);
simpleCache.put("1","1");
simpleCache.put("2","2");
simpleCache.put("3","3");
System.out.println(simpleCache.values());//[1, 2, 3]
simpleCache.get("1");
System.out.println(simpleCache.values());//1最新被访问,放到链表尾 [2, 3, 1]
simpleCache.put("4","4");
System.out.println(simpleCache.values());//添加4,容量最大为3,所以对首的2被淘汰 [3, 1, 4]
}
LinkedHashMap和HashMap遍历性能比较
LinkedHashMap维护了一个双向链表来记录数据插入的顺序,因此在迭代遍历生成的迭代器的时候,是按照双向链表的路径进行遍历的。
通用代码
两者迭代器的具体执行代码都是下面这段
public final Map.Entry<K,V> next() { return nextNode(); }
HashMap迭代器
HashMap步入代码可以看到迭代器底层使用的是数组
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
//next 为空的情况下就遍历查找不为空的next
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
LinkedHashMap迭代器
而LinkedHashMap则是使用维护好顺序的链表,无论使用的空间还是访问效率都要高于前者
final LinkedHashMap.Entry<K,V> nextNode() {
LinkedHashMap.Entry<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after;
return e;
}
性能测试
测试代码
/**
* 1、分别给HashMap和LinkedHashMap以录入1百万数据,并循环遍历,观察耗时
* 2、都采用不带参的空构造方法
*/
public class TestLinkedHashMap {
public static void main(String[] args) {
int count = 1000000;
Map<String, String> map = new HashMap<String, String>();
Map<String, String> linkedHashMap = new LinkedHashMap<String, String>();
Long start, end;
start = System.currentTimeMillis();
for (int i = 0; i < count; i++) {
map.put(String.valueOf(i), "value");
}
end = System.currentTimeMillis();
System.out.println("map time putVal: " + (end - start));
start = System.currentTimeMillis();
for (int i = 0; i < count; i++) {
linkedHashMap.put(String.valueOf(i), "value");
}
end = System.currentTimeMillis();
System.out.println("linkedHashMap putVal time: " + (end - start));
start = System.currentTimeMillis();
for (String v : map.values()) {
}
end = System.currentTimeMillis();
System.out.println("map get time: " + (end - start));
start = System.currentTimeMillis();
for (String v : linkedHashMap.values()) {
}
end = System.currentTimeMillis();
System.out.println("linkedHashMap get time: " + (end - start));
}
输出结果
可以看到linkHashMap遍历速度远远高于HashMap
map time putVal: 559
linkedHashMap putVal time: 521
map get time: 23
linkedHashMap get time: 16