文件名称: doc/chipo.csv
文件描述: 每列数据分别代表如下: 订单编号, 订单数量, 商品名称, 商品详细选择项, 商品总价格
需求1:
1). 从文件中读取所有的数据;
2). 获取数据中所有的商品名称;
3). 跟据商品的价格进行排序, 降序,
将价格最高的20件产品信息写入mosthighPrice.xlsx文件中;
需求2:
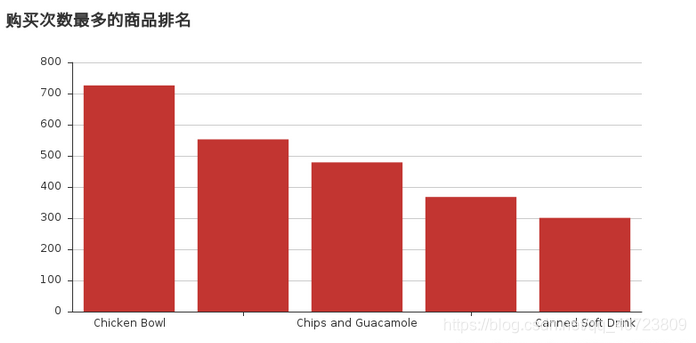
1). 统计列[item_name]中每种商品出现的频率,绘制柱状图
(购买次数最多的商品排名-绘制前5条记录)
2). 根据列 [odrder_id] 分组,求出每个订单花费的总金额。
3). 根据每笔订单的总金额和其商品的总数量画出散点图。
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
需求1:
3). 跟据商品的价格进行排序, 降序,
将价格最高的20件产品信息写入mosthighPrice.xlsx文件中;
重新赋值;
goodsInfo.item_price = goodsInfo.item_price.str.strip('$').astype(np.float)
highPriceData = goodsInfo.sort_values('item_price', ascending=False)
print(highPriceData.head(5))
filename = '/tmp/mostHighPrice.xlsx'
highPriceData.to_excel(filename)
print("保存成功.......")
需求2:
1). 统计列[item_name]中每种商品出现的频率,绘制柱状图
(购买次数最多的商品排名-绘制前5条记录)
goodsInfo = pd.read_csv('doc/chipo.csv')
# new_info会统计每个商品名出现的次数;其中 Unnamed: 0就是我们需要获取的商品出现频率;
newInfo = goodsInfo.groupby('item_name').count()
mostRaiseGoods = newInfo.sort_values('Unnamed: 0', ascending=False)['Unnamed: 0'].head(5)
# print(mostRaiseGoods, type(mostRaiseGoods)) # series对象;
# 获取对象中的商品名称;
x = mostRaiseGoods.index
# 获取商品出现的次数;
y = mostRaiseGoods.values
from pyecharts import Bar
bar = Bar("购买次数最多的商品排名")
bar.add("", x, y)
bar.render()

需求2:
2). 根据列 [odrder_id] 分组,求出每个订单花费的总金额======订单数量(quantity), 订单总价(item_price)。
3). 根据每笔订单的总金额和其商品的总数量画出散点图。
goodsInfo = pd.read_csv('doc/chipo.csv')
# 获取订单数量
quantity = goodsInfo.quantity
# 获取订单总价
item_price = goodsInfo.item_price \
= goodsInfo.item_price.str.strip('$').astype(np.float)
# 根据列 [odrder_id] 分组
order_group = goodsInfo.groupby("order_id")
# 每笔订单的总金额
x = order_group.item_price.sum()
# 商品的总数量
y = order_group.quantity.sum()
from pyecharts import EffectScatter
scatter = EffectScatter("每笔订单的总金额和其商品的总数量关系散点图")
scatter.add("", x, y)
scatter.render()

版权声明:本文为qq_40723809原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。