学习
Golang有一段时间了,自己看着各种教程也码了些demo。其实接触了这么多语言,当因为工作、项目、兴趣所驱在短时间切换一门编程语言时,并不会太难上手,甚至会对了解一些很雷同的基础语法感到枯燥,但这是必经之路。对于一个技术爱好者而言,技术广度、技术深度、技术新特性等往往是最好的兴奋剂。今天这篇文章主要结合最近的资料学习,对Go语言的运行机制及Go程序的运作进行一些稍微深入的分析及总结,对Go的启动和执行流程建立简单的宏观认知~
为什么Go语言适合现代的后端编程环境?
- 服务类应用以API居多,IO密集型,且网络IO最多;
- 运行成本低,无VM。网络连接数不多的情况下内存占用低;
- 强类型语言,易上手,易维护;
为什么适合基础设施?
k8s、etcd、istio、docker已经证明了Go的能力
一、理解可执行文件
1. 基本实验环境准备
使用docker构建基础环境
FROM centos
RUN yum install golang -y \
&& yum install dlv -y \
&& yum install binutils -y \
&& yum install vim -y \
&& yum install gdb -y
# docker build -t test .
# docker run -it --rm test bash
2. Go语言的编译过程
Go程序的编译过程:文本 -> 编译 -> 二进制可执行文件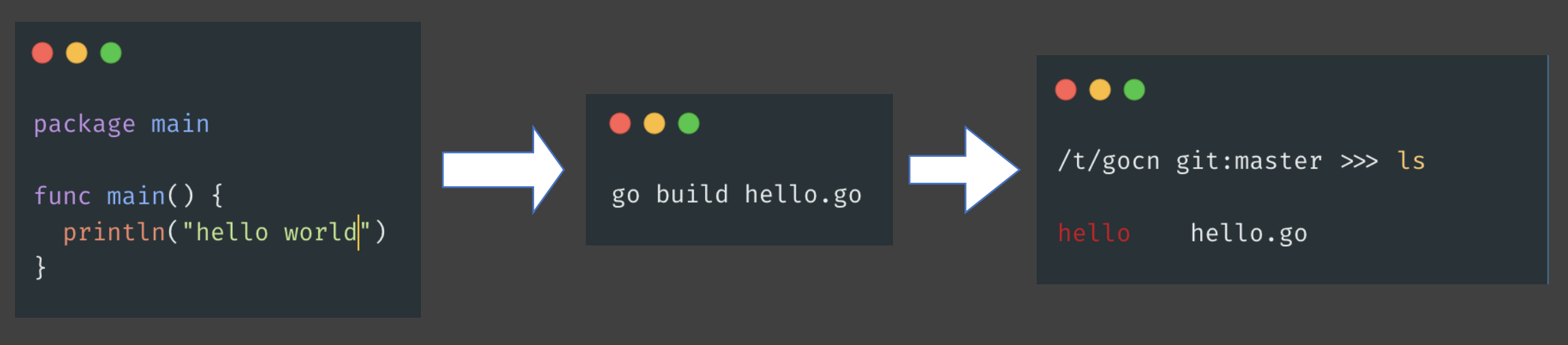
编译:文本代码 -> 目标文件(.o, .a)
链接:将目标文件合并为可执行文件
使用go build -x xxx.go可以观察这个过程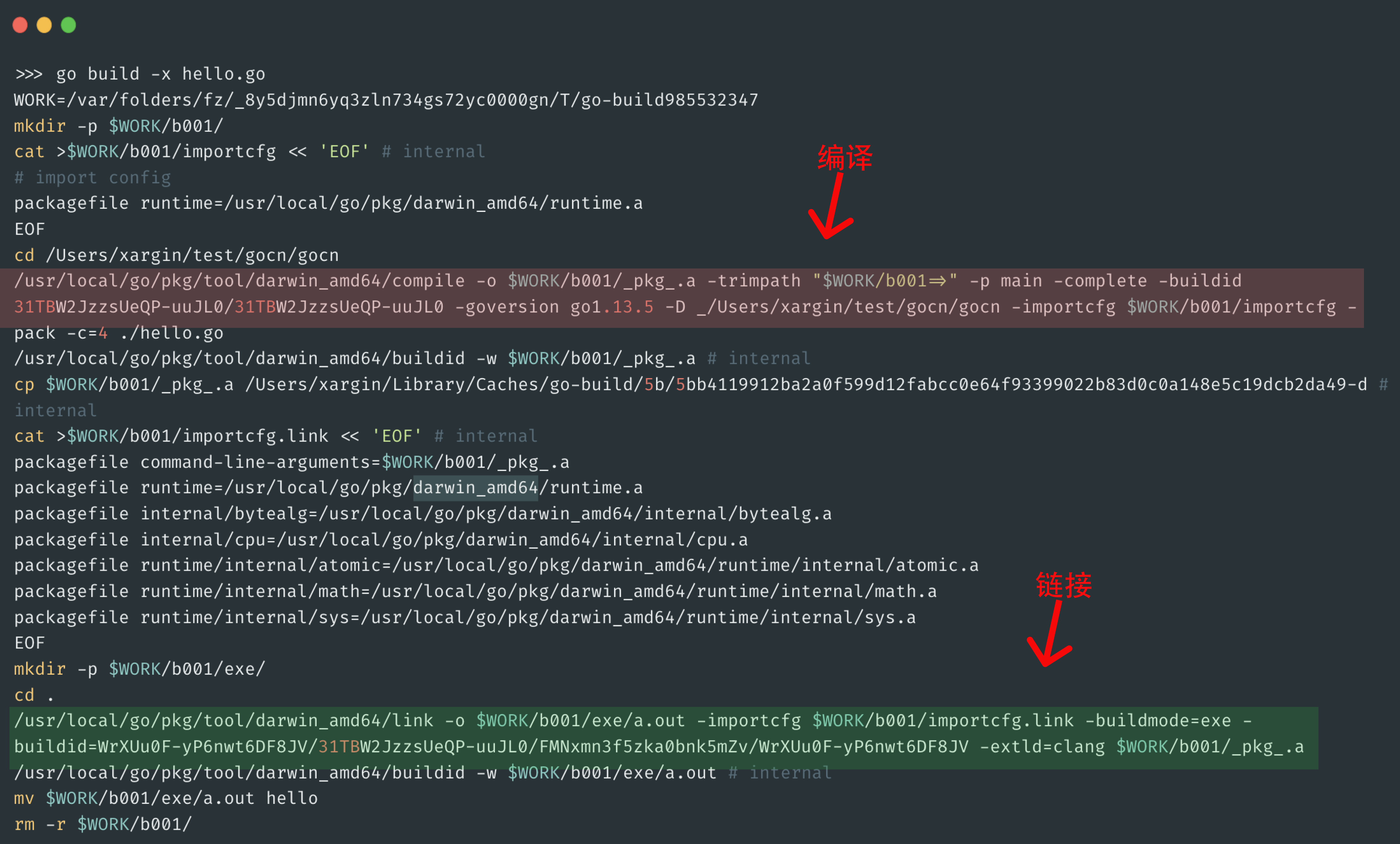
3. 不同系统的可执行文件规范
可执行文件在不同的操作系统规范不一样
以Linux的可执⾏⽂件ELF(Executable and Linkable Format) 为例,ELF 由⼏部分构成:
- ELF header
- Section header
- Sections
操作系统执行可执行文件的步骤(Linux为例):
4. 如何寻找Go进程的入口
通过entry point找到 Go进程的执⾏⼊⼝,使⽤readelf。进一步找到Go进程要从哪里启动了~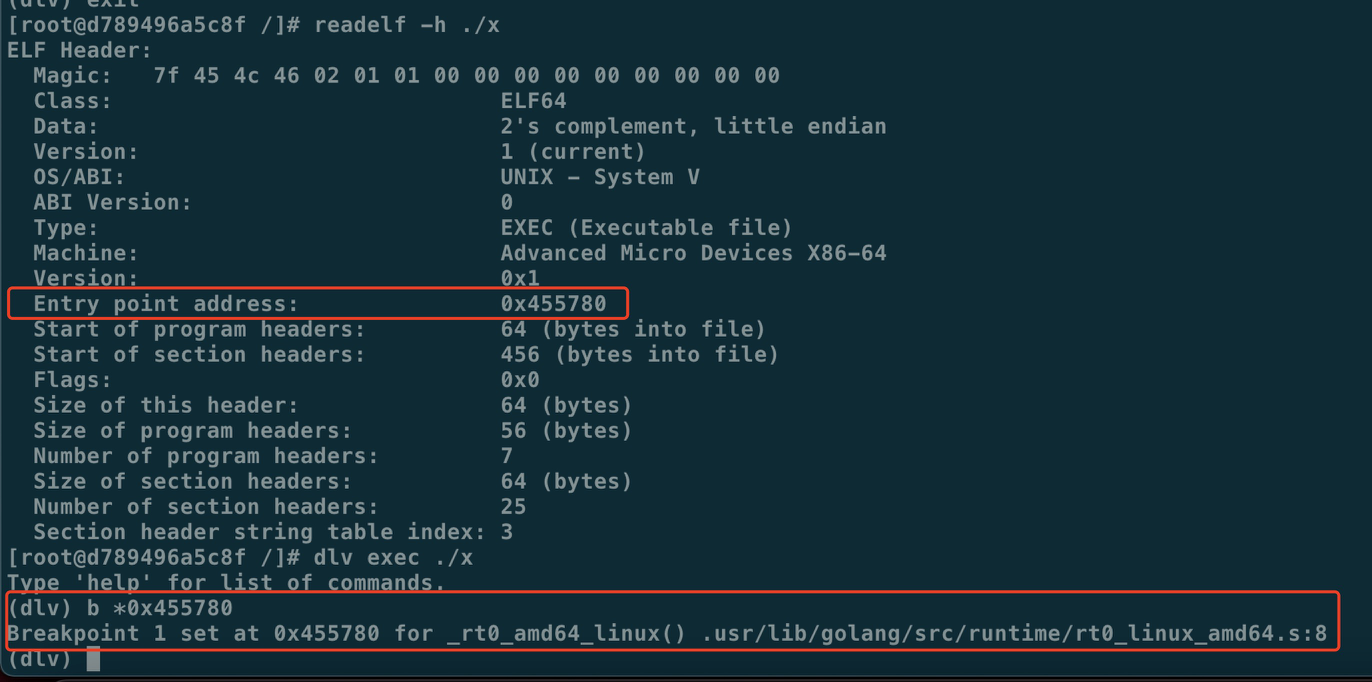
二、Go进程的启动与初始化
1. 计算机如何执⾏我们的程序

CPU⽆法理解⽂本,只能执⾏⼀条⼀条的⼆进制机器码指令,每次执⾏完⼀条指令,pc寄存器就指向下⼀条继续执⾏。
在 64 位平台上pc 寄存器 = rip。
计算机会自上而下,依次执行汇编指令: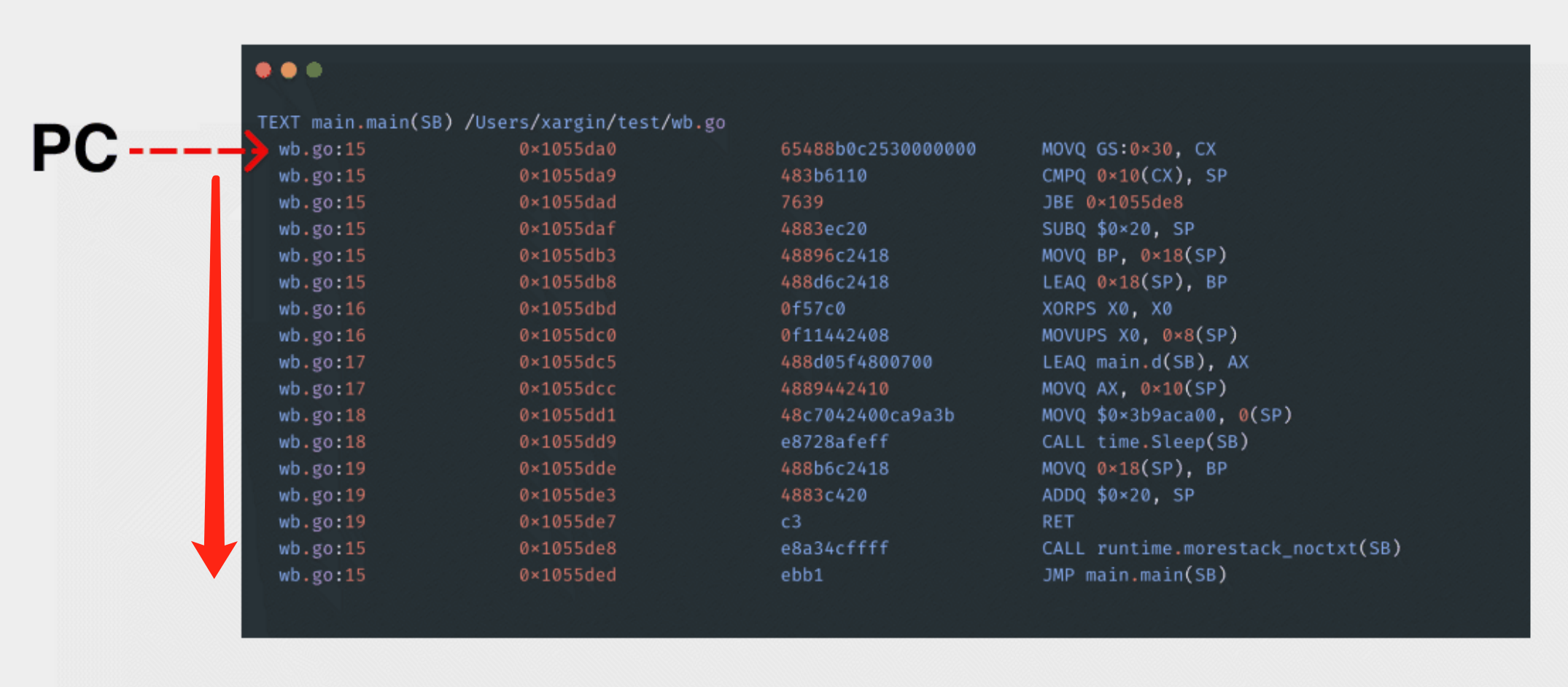
2. Runtime是什么&Go语言的Runtime
Go 语⾔是⼀⻔有runtime的语⾔,那么runtime是什么?
可以认为runtime是为了实现额外的功能,⽽在程序运⾏时⾃动加载/运⾏的⼀些模块。
Go语言中,运行时、操作系统和程序员定义代码之间的关系如下图:
在Go语言中,runtime主要包括:
Scheduler:调度器管理所有的 G,M,P,在后台执⾏调度循环Netpoll:⽹络轮询负责管理⽹络 FD 相关的读写、就绪事件Memory Management:当代码需要内存时,负责内存分配⼯作Garbage Collector:当内存不再需要时,负责回收内存
这些模块中,最核⼼的就是 Scheduler,它负责串联所有的runtime 流程。
通过 entry point 找到 Go 进程的执⾏⼊⼝:
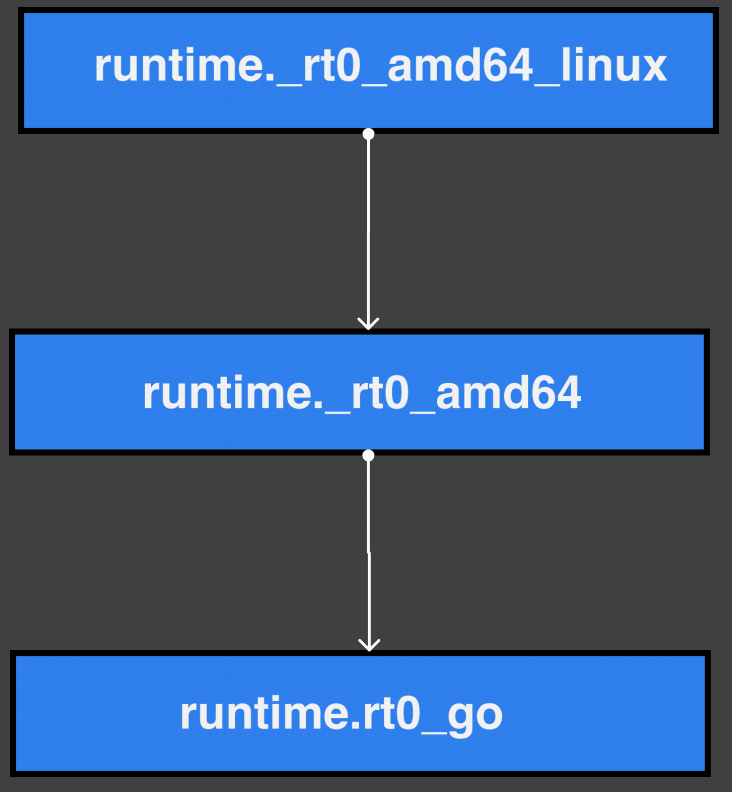
runtime.rt0_go的相关处理过程:
- 开始执行用户
main函数(从这里开始进入调度循环) - 初始化内置数据结构
- 获取CPU核心数
- 全局
m0、g0初始化 argc、argv处理
m0为Go程序启动后创建的第一个线程
三、调度组件与调度循环
1. Go的生产-消费流程概述
每当写下:
go func() {
println("hello alex")
}()
的时候,到底发生了什么?这里其实就是向runtime提交了一个计算任务,func里面所裹挟的代码,就是这个计算任务的基本内容~
Go的调度流程本质上就是一个生产-消费流程,下图为生产消费的概况流程:
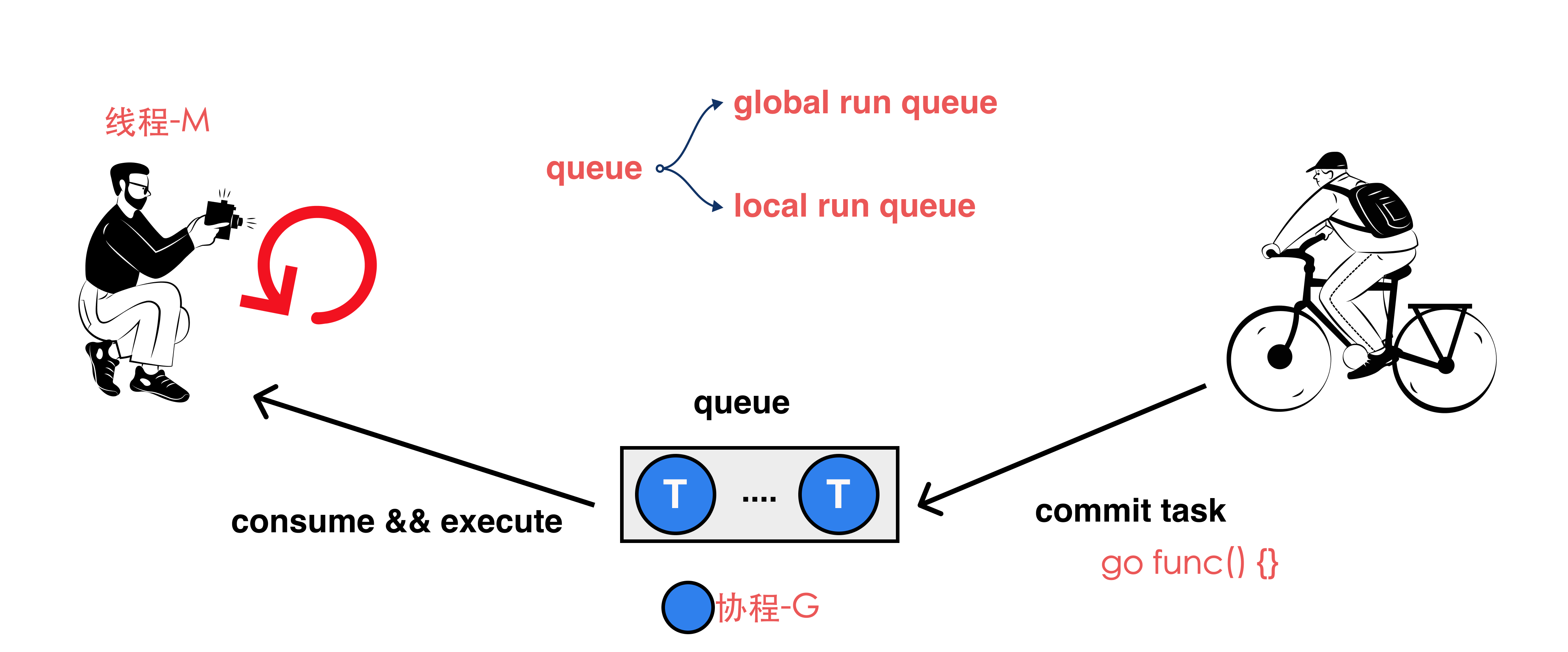
- 右边的生产者就是每次
go func() {}的时候提交的任务; - 中间的为队列,发送的任务会被打包成一个
协程G,即为goroutine; goroutine会进入到这个队列,而另一端进行消费的就是线程,线程是在循环里面执行消费的操作的;- 中间的队列主要会分为2部分,分别是
本地队列和全局队列
2. Go的调度组件P、G、M结构
先整体给P、G、M下一个定义:
- G:
goroutine,⼀个计算任务。由需要执⾏的代码和其上下⽂组成,上下⽂包括:当前代码位置,栈顶、栈底地址,状态等。 - M:
machine,系统线程,执⾏实体,想要在CPU上执⾏代码,必须有线程,与C 语⾔中的线程相同,通过系统调⽤clone来创建。 - P:
processor,虚拟处理器,M 必须获得 P 才能执⾏代码,否则必须陷⼊休眠(后台监控线程除外),你也可以将其理解为⼀种token,有这个token,才有在物理 CPU 核⼼上执⾏的权⼒。
本节的内容全部介绍完后回顾这几个概念,就会觉得相对好理解一些~
整体的结构图如下:
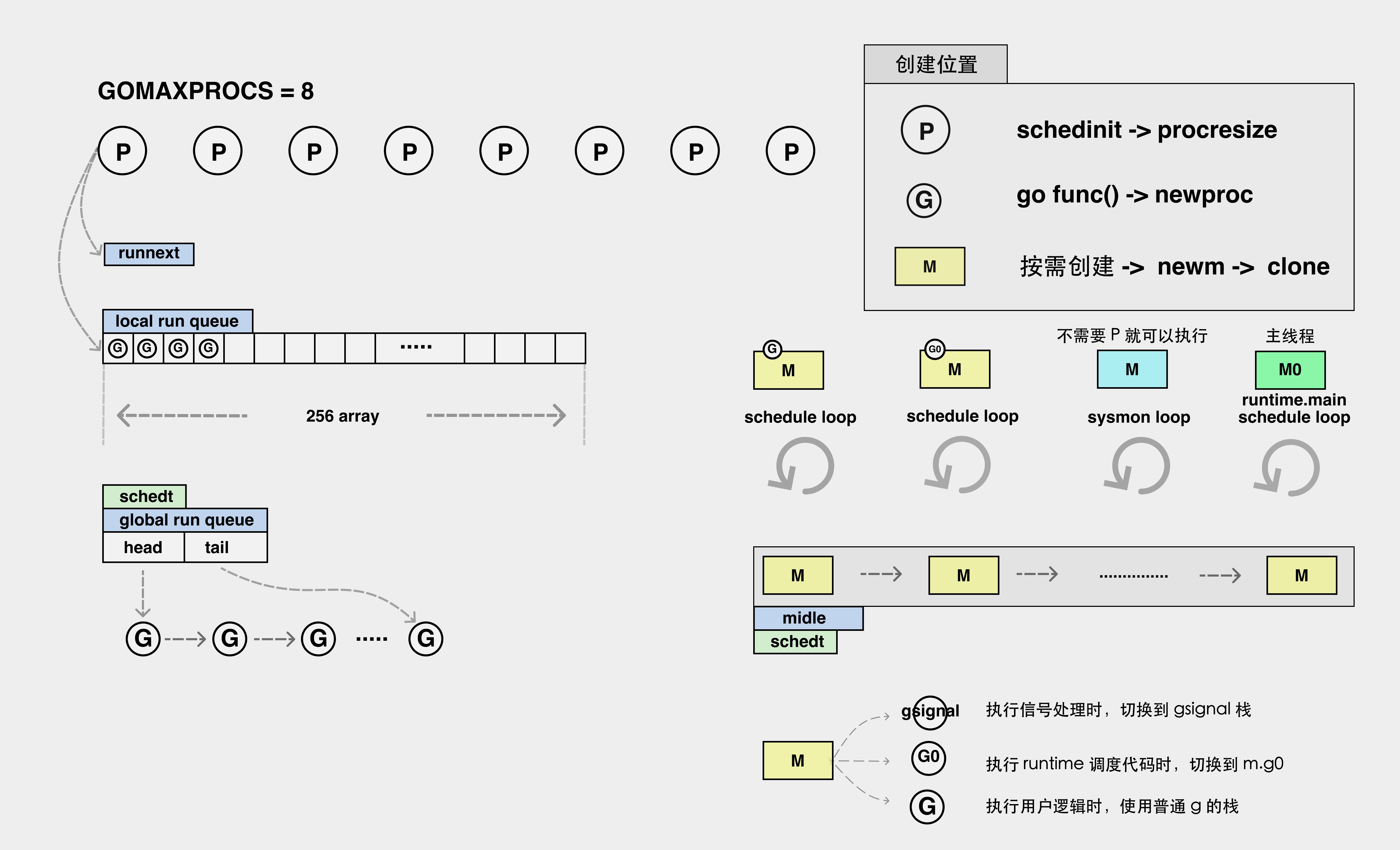
- 右边的蓝色、黄色、绿色的
M即为线程,大部分线程是一直在执行一个调度循环的,调度循环简单就是指线程要去左边的任务队列里(local run queue&global run queue)把任务拿出来然后执行的反复的操作; - 当然在整个过程中,线程是按需创建的,因此有一部分线程可能是空闲的,这些线程会被放在一个叫做
midle的队列中来进行管理,当没有可用的空闲线程时候就会在midle里面寻找使用; - 我们可以看到上图中,除了
local run queue(本地队列)和global run queue(全局队列),还有一个runnext的结构,而runnext与local run queue本质上都是为了解决程序的局部性问题**(程序的局部性原理:最近调用的一次代码很有很可能会马上被再一次调用,整体分为代码的局部性和数据的局部性)** ,我们一般不希望所有的生产都进入到全局的global run queue中; - 如果所有的线程消费的都是
global run queue的话,那么还需要进行额外加锁设计。这就是为什么会分为local run queue和global run queue的原因。
3. Go的生产-消费详解
goroutine的生产端(runnext、local run queue、global run queue的过程)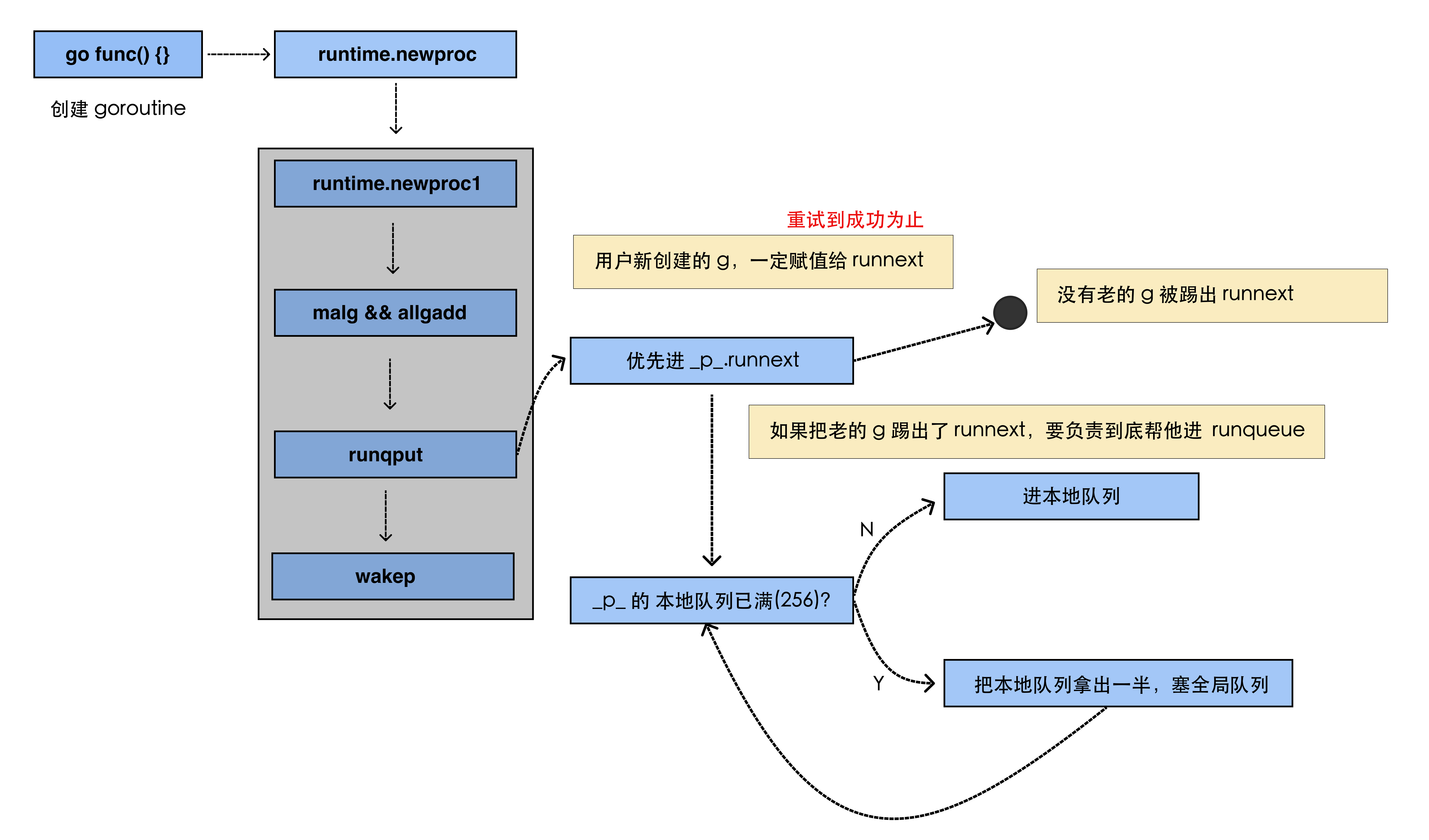
- 左上角会创建一个
goroutine,而这个goroutine会创建一个runtime,即通过runtime.newproc生成一个G; - 对于
G的队列而言,runnext的优先级是最高的,首先会进入到runnext中; - 但新的
G进去,有可能会导致老的G被挤出,此时需要进行善后工作,老的G会进入到本地队列,而如果本地队列也已经满了的话,就会把本地队列拿出一半,塞给全局队列,以此循环; - 注意:
runnext本质上并不是队列,而是一个含有一个元素的指针,为了方便理解,将其与另外的本地队列(本质上是一个数组,且只有256的长度)和全局队列(本质上是一个链表)叫法一致。
goroutine的消费端
- 消费端本质上就是多个线程在反复执行一个循环,这个循环是从队列里面取值,上图右边的蓝色块指的就是标准的
调度循环的流程,即runtime里面的4个函数:runtime.schedule、runtime.execute、runtime.goexit、runtime.gogo; - 图中红色的区域是
垃圾回收gc相关的逻辑,schedule左边的3个黄色框,都为获取G的函数,如果schedule左边的任意一个函数返回一个G给schedule,右边的循环就会一直执行; - 在这些函数中,
globalrunqget/61指的就是会定期61次执行,去全局队列里面检索获取一个G,防止在全局队列里面的G过度延迟; - 如果全局的G没有获取到,或者当前不需要获取全局的G,就会从
本地队列进行获取(优先获取runnext),而本地队列的获取就是通过runqget这个函数做到的; - 如果还是没有获取到G的话,就会去执行
findrunnable函数,这个函数整体分为上下两部分,分别叫top和stop。top部分的函数功能,主要就是再次尝试依次从本地队列->全局队列获取G,如果依然获取不到,就使用netpoll进行网络轮询情况的查看,如果在这里能找到G,就将G放在全局队列里面,如果依然获取不到,就使用runqsteal从其他的P中偷一半G回来,这个有点像Work stealing的原理(runqsteal -> runqgrab); - 如果执行完整个
top部分依然获取不到G,就说明M没有机会得到执行了,那么就开始执行stop部分,即线程的休眠流程,但在stopm执行之前,还是会再次检查一遍G的存在,确认无误后,就会将线程休眠。 - 需要注意的是:M 执⾏调度循环时,必须与⼀个 P 绑定;所有
global操作均需要加锁。
下面再单独将右边的调度循环过程摘出来描述一下:
- 在上面的
调度循环中,最重要的就是schedule,它可以从相关的语言中去寻找正在执行的任务; - 当
schedule获取到G后,就进行execute流程(执行go的代码),gogo会把拿到的G的现场回复出来,从PC寄存器开始继续执行,goexit会结束当前的一次流程,并缓存相关的G结构体资源,然后回到schedule继续执行循环; - 在调度循环的过程中,会存在一个
P.scheditick的字段,用来记录调度循环已经执行了多少次,用于globrunnqget/61等判定中。当执行到execute的时候,P.scheditick就会+1。
前面介绍的就是调度循环及调度组件的内容,但Go仅仅能够处理正常情况是不行的,如果程序中有阻塞的话,需要避免线程阻塞~
四、处理阻塞
1. Go语言中常见的阻塞情况
channel
time.Sleep
网络读
网络写
select语句
锁
以上的6种阻塞,阻塞调度循环,⽽是会把 goroutine 挂起所谓的挂起,其实让G 先进某个数据结构,待 ready 后再继续执⾏,不会占⽤线程。
这时候,线程会进⼊ schedule,继续消费队列,执⾏其它的 G
2. 各类阻塞中G是如何挂起的
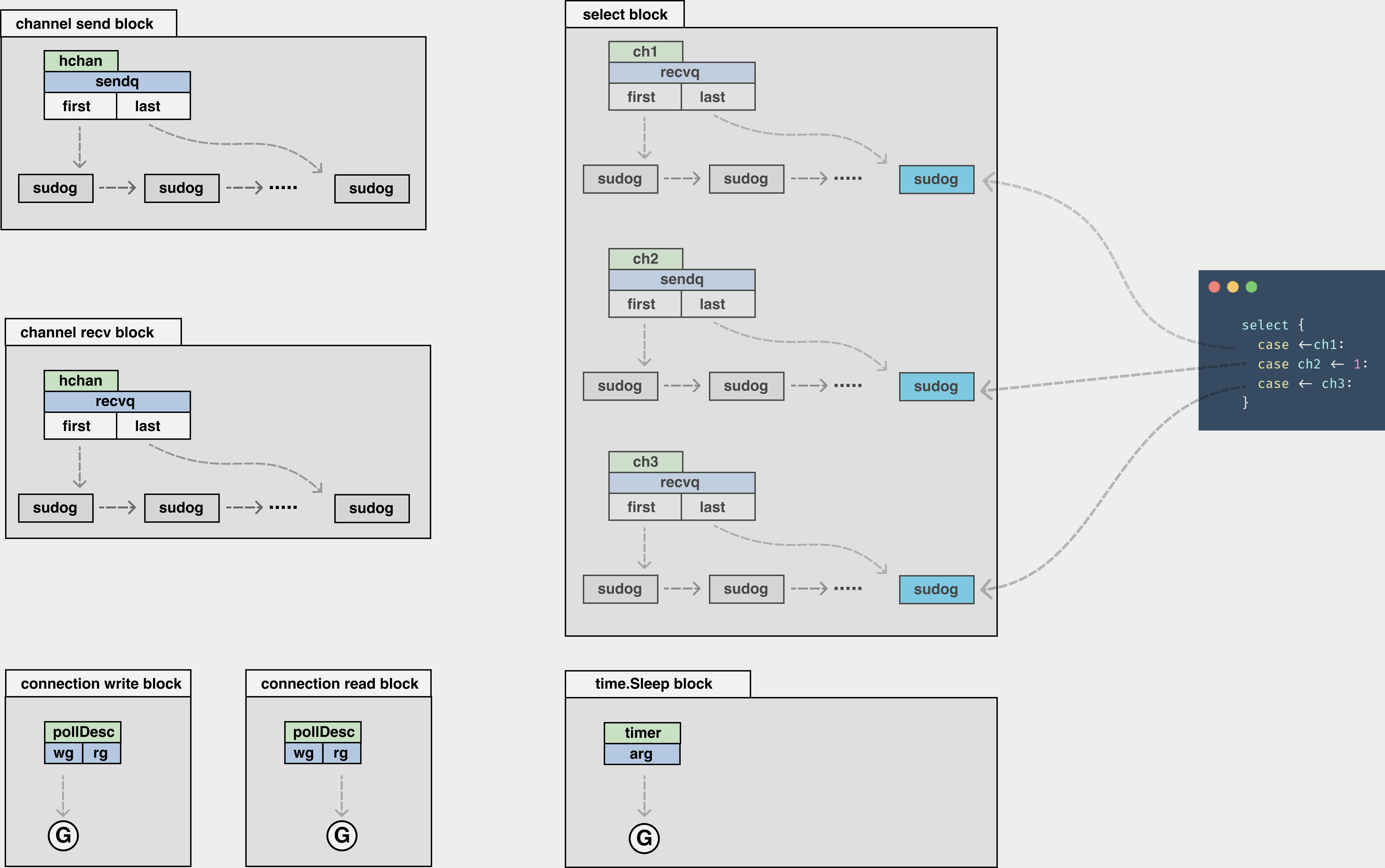
- channel发送:如果阻塞了,会有一个
sendq等待队列,将G打包为sudog的数据结构,塞在了等待结构中; - channel接收:如果阻塞了,会有一个
recvq等待队列,将G打包为sudog的数据结构,塞在了等待结构中; - 链接的写阻塞:G会挂在底层
pollDesc的wg中; - 链接的读阻塞:G会挂在底层
pollDesc的rg中; - select阻塞:以图中的3个channel为例,会有3个
sendq或者是recvq队列,G则打包为sudog挂在这些队列的尾部; - time.Sleep阻塞:将G挂在
timer结构的一个参数上。
由于锁的阻塞相对特殊,单独拿出来说。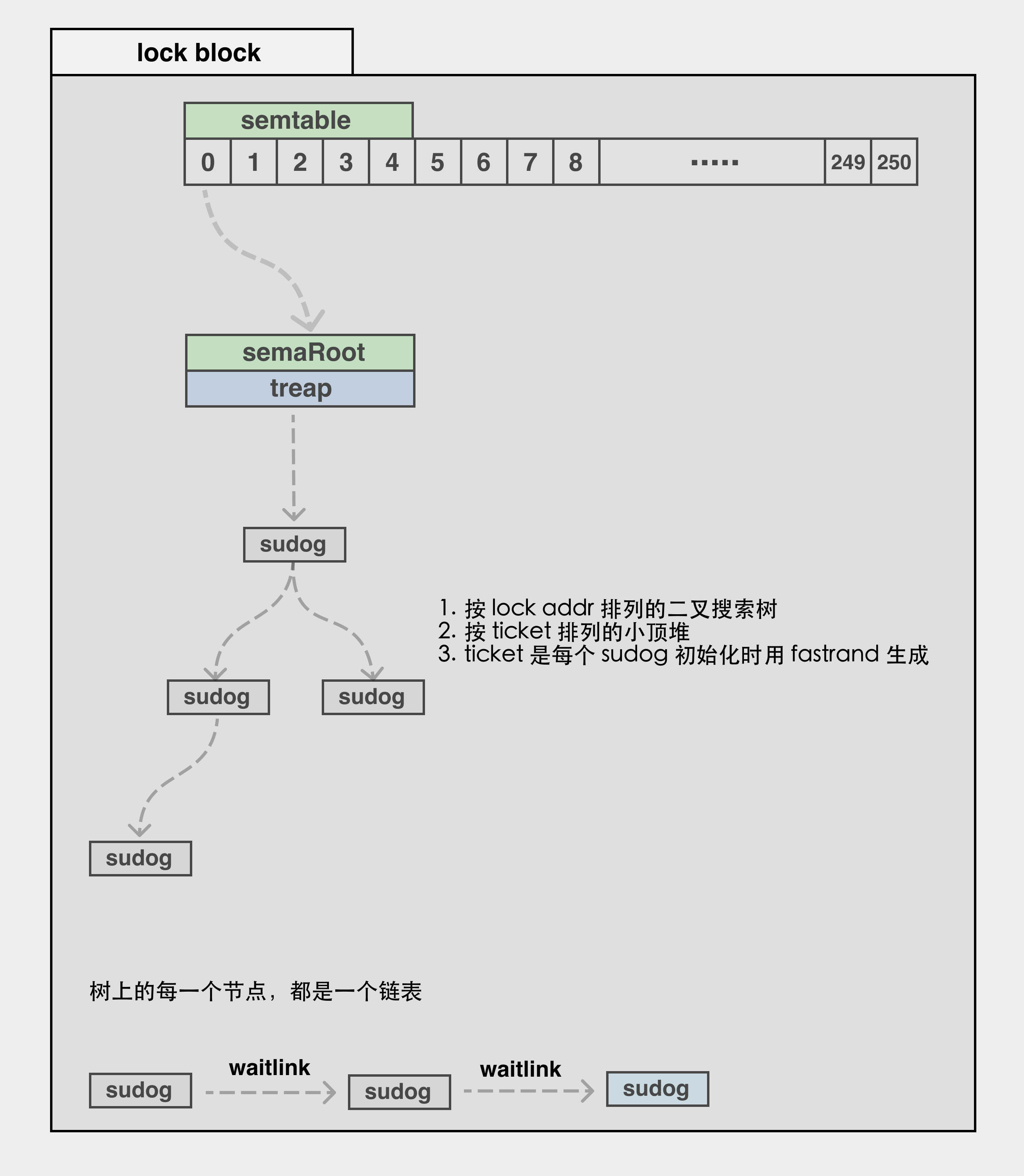
- 和前面的集中阻塞情况相似的是,锁的阻塞依然会将G打包为
sudog,会停留在树堆的结构中,树堆是一个二叉平衡树,且其中的每一个节点就是一个链表;
根据上面的介绍,我们可以看到,有些挂起等待结构是sudog而有些是G,为什么会这样呢?
因为,⼀个 G 可能对应多个 sudog,⽐如⼀个 G 会同时 select 多个channel,在runtime中有对这里解读的注释:

3. runtime无法处理的阻塞
CGO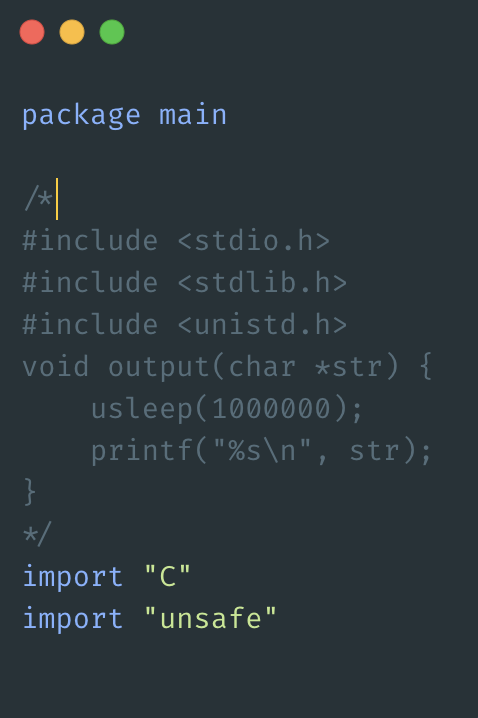
阻塞在syscall上
在执⾏ c 代码,或者阻塞在 syscall 上时,必须占⽤⼀个线程
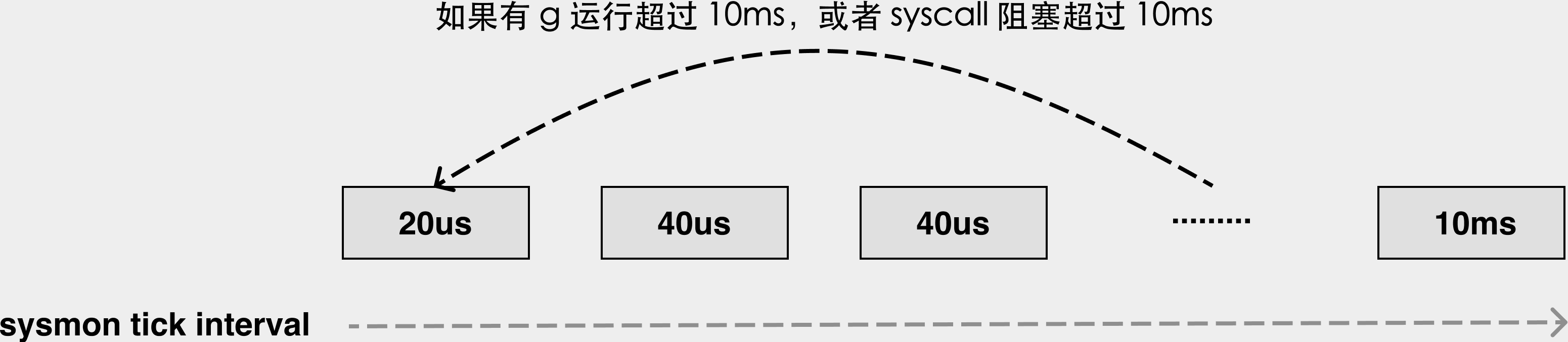
4. sysmon
sysmon: system monitor
sysmon在后台具有⾼优先级,在专有线程中执⾏,不需要绑定 P 就可以执⾏。
sysmon主要有3个作用:
checkdead—> 用于检查是否当前的所有线程都被阻塞住了,如果所有线程死锁,说明程序写的有问题,需要直接崩溃提示。对于网络应用而言,一般不会触发。常见的误解是:这个可以检查死锁;netpoll—> 将G插入到全局队列里面;retake—> 如果是syscall卡了很久,那就把P从M上剥离(handoffp);在go1.14以后,如果是⽤户 G 运⾏很久了,那么发信号抢占。
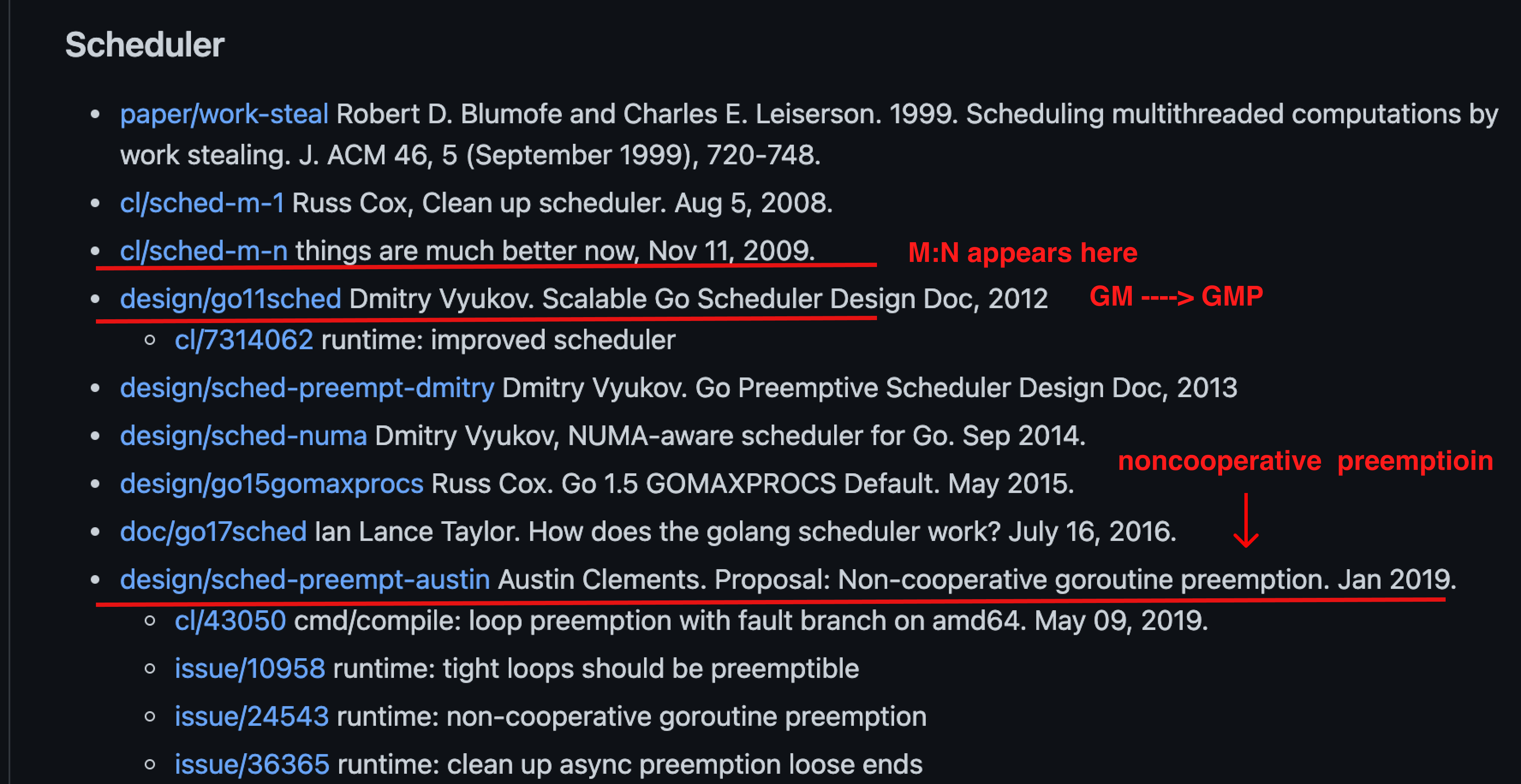
五、调度器的发展历史
六、知识点总结
1. 可执⾏⽂件 ELF:
- 使⽤
go build -x观察编译和链接过程 - 通过
readelf -H中的entry找到程序⼊⼝ - 在
dlv 调试器中b *entry_addr找到代码位置
2. 启动流程:
- 处理参数 -> 初始化内部数据结构 -> 主线程 -> 启动调度循环
3. Runtime 构成:
Scheduler、Netpoll、内存管理、垃圾回收
4. GMP:
- M,任务消费者;G,计算任务;P,可以使⽤
CPU的token
5. 队列:
- P 的本地
runnext字段 -> P 的local run queue->global run queue,多级队列减少锁竞争
6. 调度循环:
- 线程 M 在持有 P 的情况下不断消费运⾏队列中的 G 的过程。
7.处理阻塞:
- 可以接管的阻塞:
channel 收发,加锁,⽹络连接读/写,select - 不可接管的阻塞:
syscall,cgo,⻓时间运⾏需要剥离 P 执⾏
8. sysmon:
- ⼀个后台⾼优先级循环,执⾏时不需要绑定任何的 P ,负责:
- 检查是否已经没有活动线程,如果是,则崩溃;
- 轮询
netpoll; - 剥离在
syscall上阻塞的 M 的 P ; - 发信号,抢占已经执⾏时间过⻓的 G。